比特分割 + 尖峰保留:FlashCommunication V2 实现任意比特通信与 3.2× 加速
内容源自【计算机sci发表记】gongzhonghao
随着LLMs参数规模向万亿级别迈进,分布式训练与部署中的通信瓶颈已成为制约模型效率的关键因素。以DeepSeekV3、KimiK2为代表的混合专家模型架构的兴起,对跨GPU通信系统提出了前所未有的挑战。
这种背景下,亟需突破性的通信优化方案来解决相关问题。

论文标题:FlashCommunication V2: Bit Splitting and Spike Reserving for Any Bit Communication
论文链接:https://arxiv.org/abs/2508.03760
作者单位:美团、英伟达
ONE 研究背景与核心挑战
在大语言模型(LLMs)向万亿参数规模演进的过程中,分布式训练与部署面临的通信瓶颈日益凸显。以DeepSeekV3(671B参数)、KimiK2(1T参数)为代表的混合专家模型(MoE)架构,对跨GPU通信提出了三大严苛要求:
1.带宽压力:单次训练迭代产生的梯度/激活值数据量可达TB级,现有NVLink/PCle带宽难以满足实时需求
2.量化困境:传统低比特量化(如INT8/INT4)面临两大难题:
(1)非常规比特宽度(如INT5/INT6)缺乏硬件支持
(2)数值异常值(尖峰)导致低比特量化时精度暴跌(INT2量化困惑度可达1e3量级)
3.架构差异:NVLink与PCle等不同硬件架构的通信机制差异显著,通用优化方案难以兼顾
现有解决方案如FlashCommunication V1、ZeRO++等在特定场景下有效,但无法突破上述根本性限制。这促使美团与NVIDIA联合团队提出第二代技术方案。
TWO 核心技术突破
1. 比特分割(Bit Splitting):硬件友好的任意比特传输

创新性地将非常规定长数据(如INT5)分解为:
规整部分(4比特):采用FlashCommunication V1的高效打包策略
额外比特(1比特):独立存储并通过紧凑编码压缩
实测显示,4096个BF16数据(8192字节)经INT5分割后仅需2688字节,通信量减少67%。该技术成功突破硬件对量化精度的限制,实现INT2-INT8全范围自适应。
2. 尖峰保留(Spike Reserving):低比特量化的精度救赎
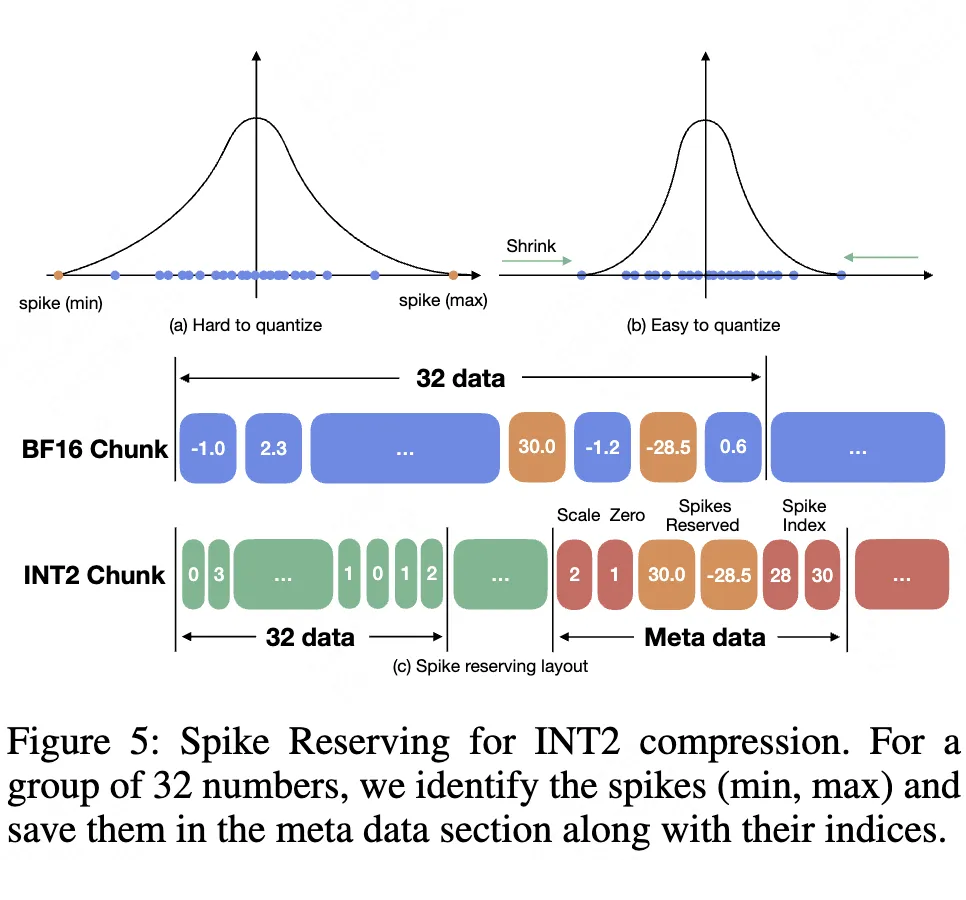
核心创新在于:
(1)动态范围压缩:每组32个数据中分离存储最大值/最小值(浮点格式)
(2)元数据优化:尖峰索引采用INT8存储,尺度参数整数化(scale_int=floor(log2(scale)*8))
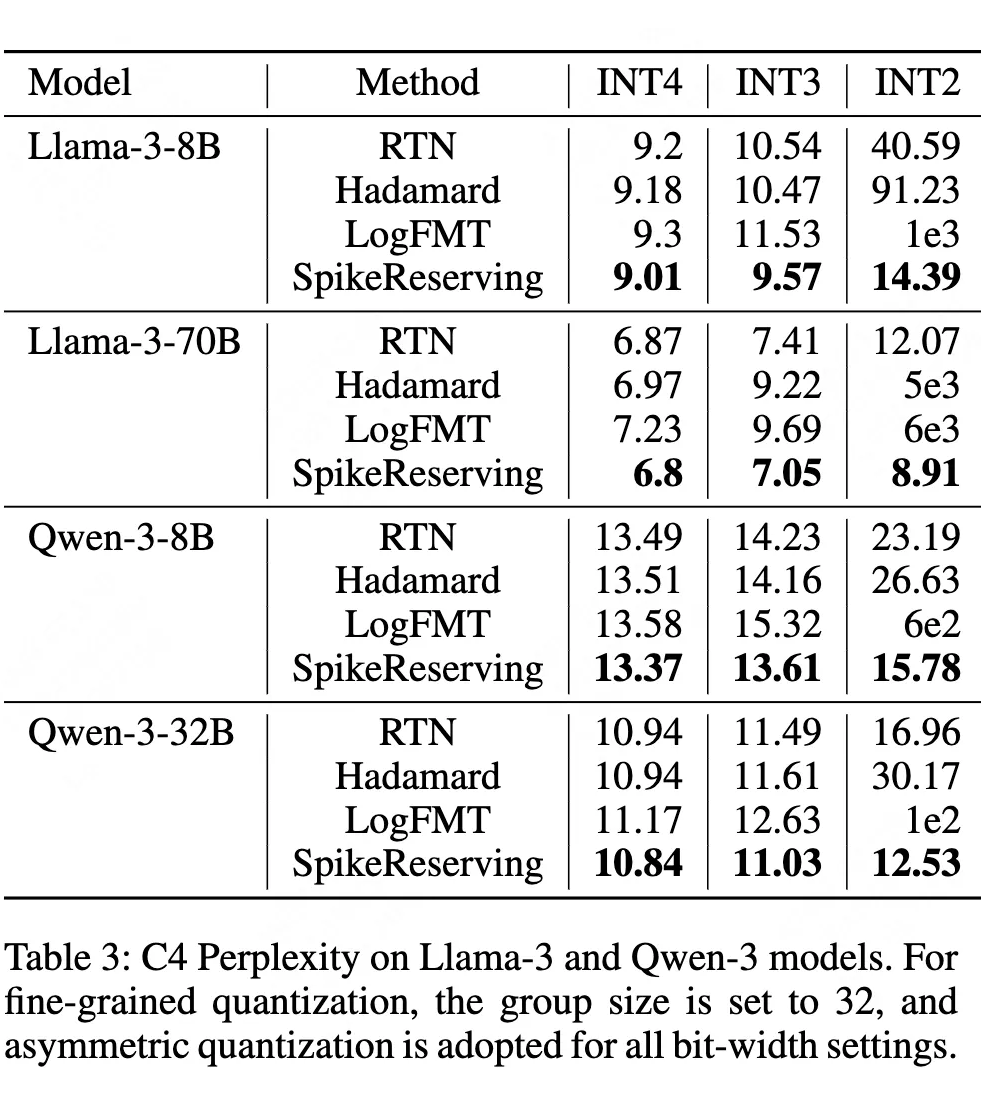
实验表明,该技术使Llama-3-8B在INT2量化时的困惑度从40.59降至14.39,精度损失控制在实用范围内:
THREE 系统级优化策略
1. 层次化通信架构
针对PCIe等低带宽场景,创新性采用三级通信流水线:(1)NUMA组内Reduce;(2)跨NUMA桥归约;(3)NUMA AllGather。
如下图所示,跨NUMA通信量从7M降至1M,降幅达85%。

2. 流水线并行优化
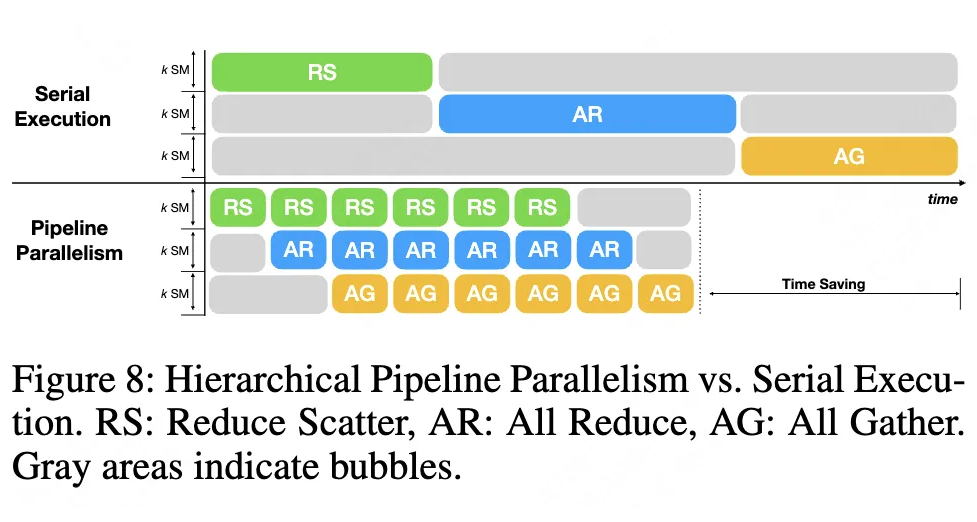
通过将通信任务拆分为微块,实现:
(1)ReduceScatter与AllGather阶段重叠执行
(2)消除带宽空闲时间
实测最高可节省20%通信耗时,特别适合MoE模型的专家并行场景。
FOUR 实验验证与性能表现
1. 量化精度突破
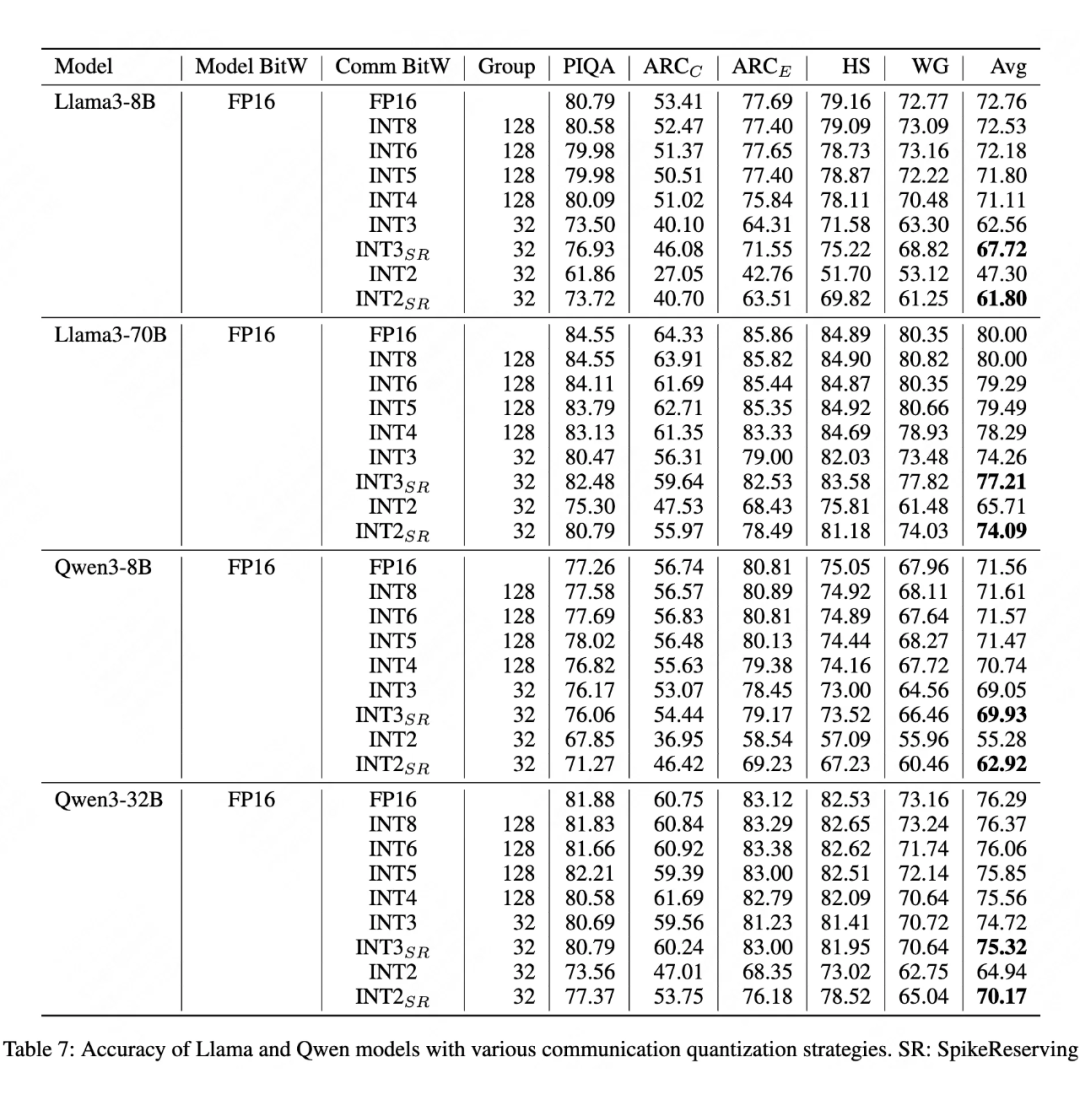
如上表所示,尖峰保留技术显著提升低比特量化下的模型精度:
(1)Llama-3-70B的INT2平均精度从65.71→74.09(+8.38%)
(2)Qwen-3-32B的INT2精度提升14.5个百分点
即使在INT2极端量化下,模型仍保持实用性能水平。
2. 通信效率飞跃
特别在All2All通信场景(MoE核心操作),H800实现341.87GB/s的算法带宽,较BF16基准提升2.01倍。

3.用户体验优化
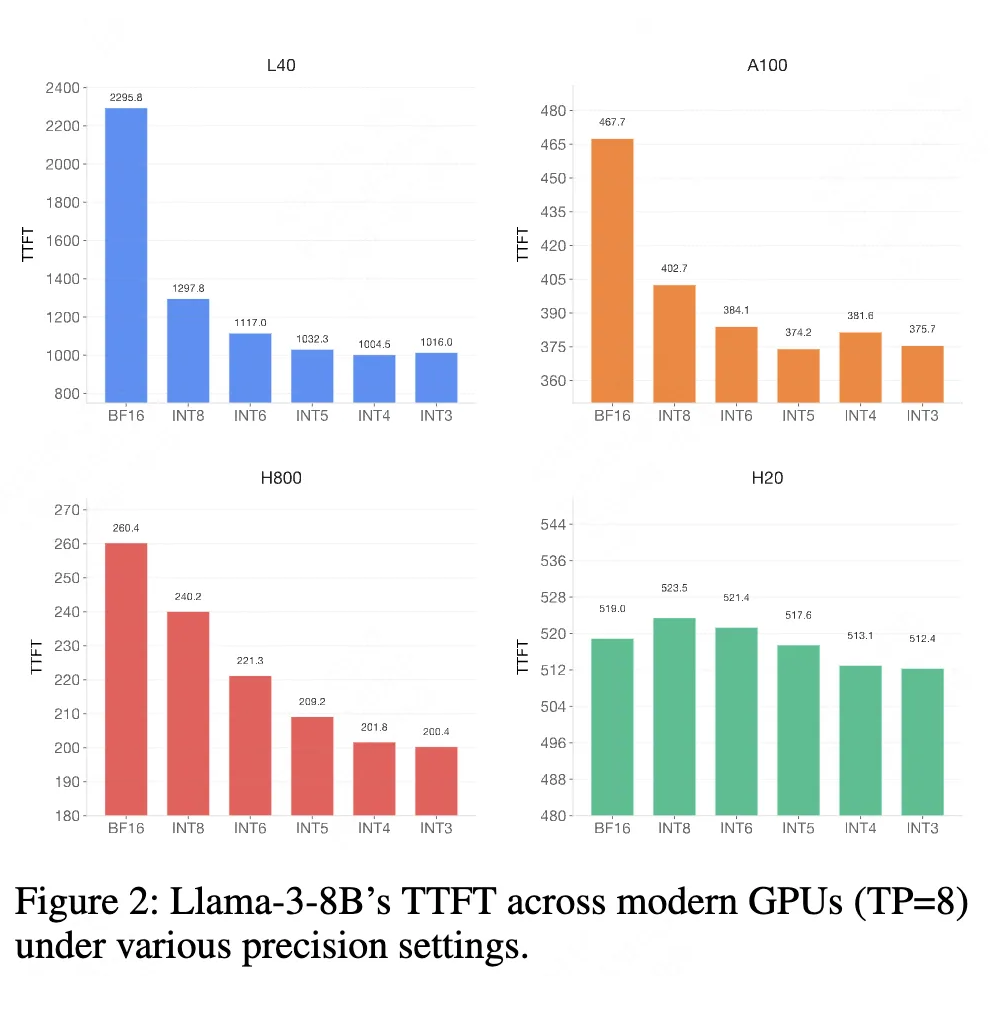
低比特量化使Llama-3-8B的首token时间(TTFT)显著降低:
(1)L40平台:2.28倍加速
(2)H800平台:1.3倍加速
大幅提升实时交互体验。
FIVE 技术影响与未来展望
FlashCommunication V2的三大核心价值:
1.灵活性:支持动态调整量化策略(如MoE专家通信可采用INT4,其他部分使用INT2)
2.高效性:通信量减少75%以上,使万亿模型训练成本降低约40%
3.普适性:兼容从消费级GPU到超算集群的各类硬件环境
未来研究方向包括:
万卡级集群的扩展验证
专用硬件加速单元设计
动态量化策略的在线优化
该技术为LLM向更大规模发展扫清了通信瓶颈,推动AI基础设施进入“比特级优化”新时代。