数据库架构开发知识库体系
摘要
面向初创与企业团队,系统梳理数据库与数据平台从采集、传输、存储、处理、服务化到治理与安全的全链路。覆盖 OLTP/OLAP/HTAP、湖仓一体与实时数据栈,结合国内外工具与方法论,给出架构选型、性能优化、可靠性与合规要点,以及可落地的命令清单与实施检查表。文末附 PlantUML 思维导图。
1. 架构总览与数据流转
典型分层
采集层:日志/业务数据库/物联网数据 → CDC/Agent/Kafka
传输层:消息队列与传输协议(Kafka、Pulsar、RocketMQ、REST、gRPC)
计算层:批处理(Spark、Hive、Trino)、流处理(Flink、Kafka Streams)、批流一体(Flink、Spark Structured Streaming)
存储层:行存 OLTP(MySQL、PostgreSQL、TiDB、OceanBase)、列存 OLAP(ClickHouse、StarRocks、Doris、Snowflake、BigQuery、Redshift)、数据湖与湖仓(S3/OSS/OBS+Iceberg/Hudi/Delta Lake)、时序库(TimescaleDB、InfluxDB、TDengine)、图数据库(Neo4j、JanusGraph、Nebula Graph)、搜索与向量(Elasticsearch/OpenSearch、Milvus、Qdrant、pgvector、ClickHouse 向量)
服务与语义层:API Gateway、数据服务化、中台数据产品、语义模型/数据集(dbt、Cube、Semantic Layer)
可视化与应用:BI/报表/运营大屏、内外部 API
参考架构范式
数据仓库与数据集市(Kimball 维度建模、Inmon 企业模型)
Lambda/Kappa/湖仓一体(ELT 主导,存算分离)
Medallion 分层:Bronze 原始、Silver 清洗、Gold 主题与指标
Data Mesh:面向域的数据产品与数据契约
2. 存储与引擎选型
OLTP
单体与读写分离:MySQL、PostgreSQL;代理与分片:ProxySQL、Vitess、ShardingSphere、MyCAT
分布式 HTAP/金融级:TiDB、OceanBase、openGauss/GaussDB、PolarDB
OLAP 与近实时
列存与向量化:ClickHouse、StarRocks、Apache Doris、Apache Druid、Trino/Presto
云原生仓库:Snowflake、BigQuery、Redshift、AnalyticDB、Hologres
数据湖与湖仓
元数据目录:Glue Catalog、Hive Metastore、Unity Catalog、Lake Formation
表格式与 ACID:Iceberg、Hudi、Delta Lake;文件格式:Parquet、ORC、Avro
批流一体读写:Flink+Iceberg/Hudi、Spark+Delta
特种库
时序:TimescaleDB、InfluxDB、TDengine
图:Neo4j、JanusGraph、Nebula Graph
向量与检索:Milvus、Qdrant、Weaviate、Elasticsearch/OpenSearch 向量、pgvector、ClickHouse 向量
3. 数据采集与传输
CDC 与日志
Binlog/Redo 日志:Debezium、Flink CDC、Canal、GoldenGate
触发器或定期快照:DataX、Sqoop(存量迁移),谨慎用于增量
消息与总线
Kafka、Pulsar、RocketMQ、RabbitMQ;顺序、分区、幂等、Exactly-once 语义
协议与序列化:Avro/Protobuf/JSON、Schema Registry、演进与兼容策略
IoT 与边缘
MQTT/CoAP、网关汇聚、边缘聚合与降采样、离线补传
4. 数据建模与处理方法
事务与一致性
ACID 与 MVCC、隔离级别、分布式事务(两阶段提交、Percolator、TCC/Saga)
CAP 与 PACELC 取舍:可用性/一致性/延迟的业务权衡
维度建模与数据契约
事实表与维度表、星型/雪花、SCD Type 1/2、主键策略与代理键
数据契约与语义层:指标定义、口径管理、数据产品接口
流批一体
事件时间与水位线、迟到与乱序、状态一致性、窗口(滚动/滑动/会话)
批处理回填与重算、幂等写入与去重键
质量与可观察性
维度:完整性、唯一性、有效性、一致性、及时性、准确性
校验与监控:Great Expectations、Soda Core、Deequ;血缘:Amundsen、DataHub、Atlas、Spline
5. 工程化与平台能力
任务编排与调度
Airflow、Dagster、Prefect、Azkaban、DolphinScheduler、DataWorks(阿里)
依赖与优先级、重试与补偿、事件驱动与日历窗口
元数据与治理
数据目录、血缘、数据地图、敏感分级与标签、数据资产评估
访问治理:Ranger、Sentry、Lake Formation、Unity Catalog、Apache Knox
安全与合规
传输与静态加密、行列级权限、动态脱敏、令牌化、密钥管理(KMS/HSM)
隐私与法规:GDPR、CCPA、PIPL、等保 2.0;跨境与本地化
可观测性与容量
指标/日志/追踪:Prometheus、Grafana、OpenTelemetry、ELK
SLO:查询时延、吞吐、错误率、资源水位;自动扩缩容与配额
6. 性能优化要点
OLTP
索引与统计信息(BTree/Hash、GIN/GiST)、覆盖索引、冷热分离
分区/分表与路由键、连接池、慢查询画像与执行计划分析
OLAP/湖仓
列式压缩与编码(字典、RLE)、分区与分桶、Z-Order/Cluster Key、Bloom Filter
物化视图与聚合表、冷热分层、查询下推与向量化执行
流处理
反压与水位线、状态大小与 RocksDB、Checkpoint 与 Savepoint、Exactly-once Sink
7. 架构选型指南(速查)
高并发交易系统:OLTP 分布式(TiDB/OceanBase)或 PostgreSQL+读写分离
近实时分析与报表:StarRocks/ClickHouse+Doris/Trino;行转列与聚合表
大数据湖仓:S3/OSS/OBS+Iceberg/Hudi/Delta + Spark/Trino/Flink
实时链路:Kafka→Flink→Iceberg/ClickHouse→API/BI
时序监控:Kafka→Flink→TimescaleDB/TDengine→Grafana
图谱与推荐:OLTP+CDC→图数据库/向量检索→在线召回/排序
8. 研发流程与环境
开发到生产
本地开发容器化与 Compose(数据库/消息/计算镜像)
Dev/Stage/Prod 三环境、蓝绿与灰度、数据回放与影子流量
迁移与变更
Online Schema Change:gh-ost、pt-online-schema-change、Liquibase/Flyway
数据回填与校验、双写与校验、回滚预案(PITR、冗余快照)
9. 常用命令与最小示例
Kafka
创建主题:
kafka-topics.sh --create --topic events --partitions 8 --replication-factor 3 --bootstrap-server localhost:9092控制台生产/消费:
kafka-console-producer.sh ...、kafka-console-consumer.sh --from-beginning ...Flink
提交作业:
flink run -m yarn-cluster -c com.demo.Job target/job.jarSavepoint:
flink savepoint <jobId> file:///checkpoints/spdbt
初始化与运行:
dbt init,dbt run,dbt test,dbt docs generate && dbt docs serveClickHouse
建表与分区
CREATE TABLE t
( id UInt64, dt Date, x Float64 )
ENGINE = MergeTree PARTITION BY toYYYYMM(dt) ORDER BY (dt,id);
物化视图
CREATE MATERIALIZED VIEW mv AS
SELECT toDate(time) d, count() c FROM src GROUP BY d;
PostgreSQL
分区表
CREATE TABLE sales (id bigserial, d date, amt numeric) PARTITION BY RANGE (d);
CREATE TABLE sales_2025m08 PARTITION OF sales FOR VALUES FROM ('2025-08-01') TO ('2025-09-01');
并行与计划:
EXPLAIN (ANALYZE, BUFFERS)
Iceberg 表创建(Spark SQL)
CREATE TABLE lake.sales (id BIGINT, ts TIMESTAMP, amt DECIMAL(12,2))
USING iceberg PARTITIONED BY (days(ts));
10. 实施检查表(浓缩)
需求与SLO:吞吐、时延、可用性、成本上限
数据契约:字段口径、变更策略、兼容级别、Schema Registry
安全与治理:分级分类、RLS/CLS、密钥与审计、血缘与质量门禁
架构与选型:OLTP/OLAP/湖仓与实时路径、冷热分层与成本测算
运维与可观测:指标阈值、告警路由、容量与备份/演练
发布与回滚:蓝绿/灰度、双写校验、PITR、应急剧本
11. 学习路径与资料
基础与范式:数据库系统概念、Designing Data-Intensive Applications、The Data Warehouse Toolkit
工具与实践:Flink/Spark 官方教程、Iceberg/Hudi/Delta 文档、ClickHouse/StarRocks/Trino 文档、Airflow/Dagster/Prefect 实战
国内生态:阿里 DataWorks、华为云 ROMA/数据治理、腾讯 TBDS、开源 TiDB/TiFlash、OceanBase、Doris/StarRocks、TDengine、Nebula Graph
PlantUML 思维导图
@startmindmap
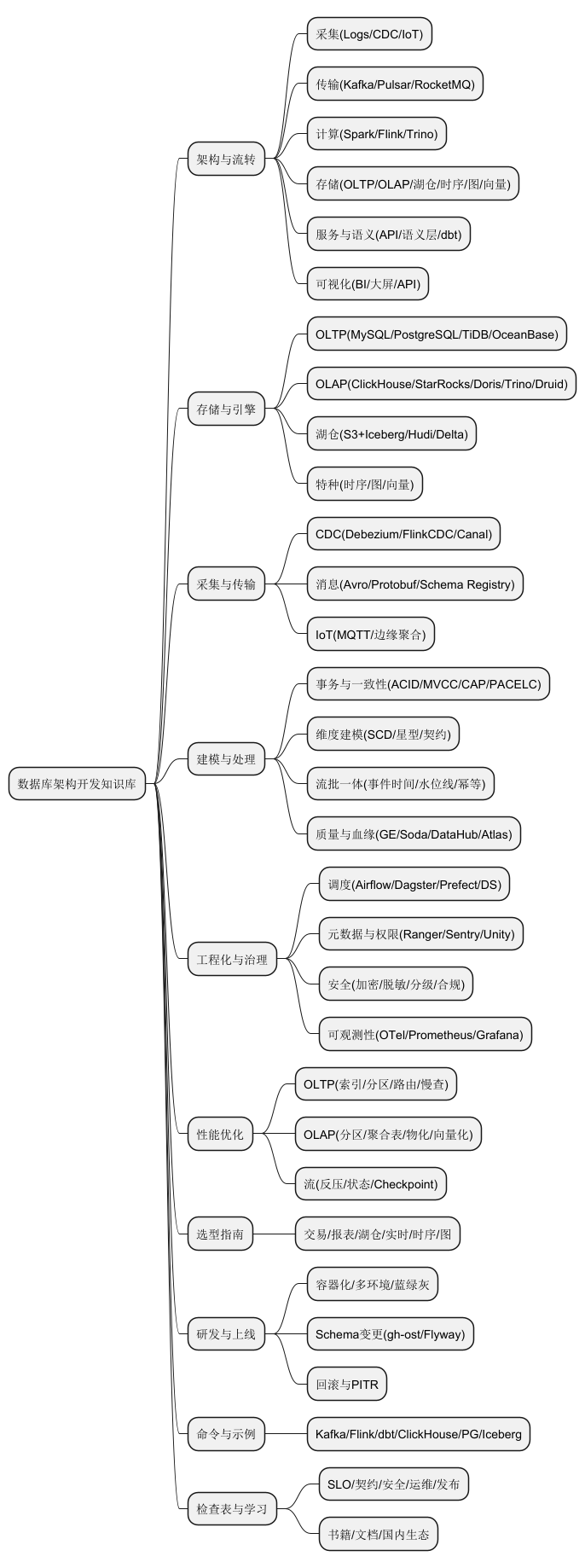
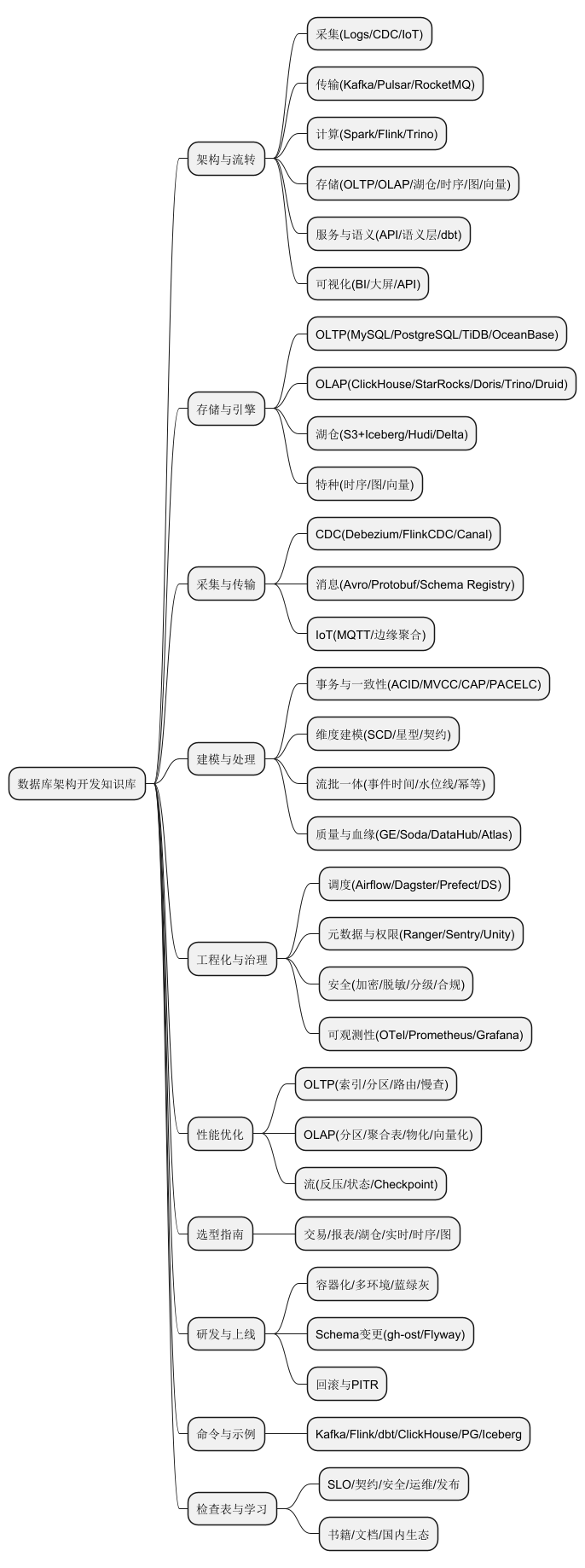
* 数据库架构开发知识库
** 架构与流转
*** 采集(Logs/CDC/IoT)
*** 传输(Kafka/Pulsar/RocketMQ)
*** 计算(Spark/Flink/Trino)
*** 存储(OLTP/OLAP/湖仓/时序/图/向量)
*** 服务与语义(API/语义层/dbt)
*** 可视化(BI/大屏/API)
** 存储与引擎
*** OLTP(MySQL/PostgreSQL/TiDB/OceanBase)
*** OLAP(ClickHouse/StarRocks/Doris/Trino/Druid)
*** 湖仓(S3+Iceberg/Hudi/Delta)
*** 特种(时序/图/向量)
** 采集与传输
*** CDC(Debezium/FlinkCDC/Canal)
*** 消息(Avro/Protobuf/Schema Registry)
*** IoT(MQTT/边缘聚合)
** 建模与处理
*** 事务与一致性(ACID/MVCC/CAP/PACELC)
*** 维度建模(SCD/星型/契约)
*** 流批一体(事件时间/水位线/幂等)
*** 质量与血缘(GE/Soda/DataHub/Atlas)
** 工程化与治理
*** 调度(Airflow/Dagster/Prefect/DS)
*** 元数据与权限(Ranger/Sentry/Unity)
*** 安全(加密/脱敏/分级/合规)
*** 可观测性(OTel/Prometheus/Grafana)
** 性能优化
*** OLTP(索引/分区/路由/慢查)
*** OLAP(分区/聚合表/物化/向量化)
*** 流(反压/状态/Checkpoint)
** 选型指南
*** 交易/报表/湖仓/实时/时序/图
** 研发与上线
*** 容器化/多环境/蓝绿灰
*** Schema变更(gh-ost/Flyway)
*** 回滚与PITR
** 命令与示例
*** Kafka/Flink/dbt/ClickHouse/PG/Iceberg
** 检查表与学习
*** SLO/契约/安全/运维/发布
*** 书籍/文档/国内生态
@endmindmap