虚拟机部署HDFS集群
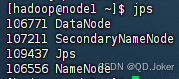
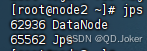
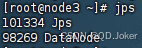
提示:虚拟机部署HDFS集群,一个 NameNode 角色,三个 DataNode 角色,一个 SecondaryNameNode 角色
文章目录
- 前言
- 部署集群
前言
- HDFS组件:分布式存储组件,可以构建分布式文件系统用于数据存储。
- 基础架构
- 主角色:NameNode(独立进程,负责管理HDFS整个文件系统,负责管理DataNode)
- 从角色:DataNode (独立进程,负责存储和取出数据)
- 主角色辅助角色:SecondaryNameNode (NameNode的辅助,独立进程,主要帮助 NameNode 完成元数据整理工作)
- 准备工作:
- 虚拟机中服务器创建三台服务器,修改名称为node1(8G),node2(4G),node3(4G)
- 将三台服务器固定IP
- 分别创建一个名称为 hadoop 的用户
- 关闭防火墙
- 设置ssh免密(注意 node1 对 node1 自身也要设置免密)
- 分别部署JDK
部署集群
-
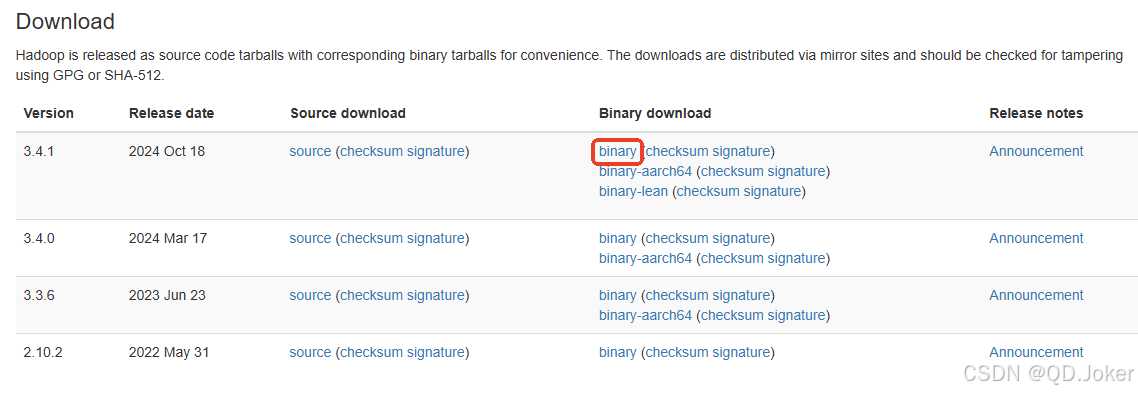
官网下载 二进制安装包
-
上传 hadoop 安装包到 node1 节点(能找到的目录即可)
-
新建 /export/server/ 目录,解压安装包到此目录中:tar -zxvf hadoop-3.4.1.tar.gz -C /export/server
-
构建软链接:/export/server 目录下执行:ln -s /export/server/hadoop-3.4.1 hadoop
-
配置HDFS集群,进入 /export/server/hadoop/etc/hadoop 目录下
1. vim workers :填入以下内容(删除文件中 localhost)node1node2node3 2. vim hadoop-env.sh:配置 hadoop 相关环境变量export JAVA_HOME=/export/server/jdkexport HADOOP_HOME=/export/server/hadoopexport HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoopexport HADOOP_LOG_DIR=$HADOOP_HOME/logs 3. vim core-site.xml : hadoop 核心配置文件,在文件中填入 如下内容<configuration><property><name>fs.defaultFS</name><value>hdfs://node1:8020</value></property><property><name>io.file.buffer.size</name><value>131072</value></property></configuration>PS:fs.defaultFS 含义:HDFS文件系统的网络通讯路径,值:hdfs://node1:8020 表明DataNode 将和 node1 的 8020 端口通讯,node1 是 NameNode 所在的机器io操作文件缓存区大小 131072bit 4. vim hdfs-site.xml :HDFS核心配置文件<configuration><property><name>dfs.datanode.data.dir.perm</name><value>700</value></property><property><name>dfs.namenode.name.dir</name><value>/data/nn</value></property><property><name>dfs.namenode.hosts</name><value>node1,node2,node3</value></property><property><name>dfs.blocksize</name><value>268435456</value></property><property><name>dfs.namenode.handler.count</name><value>100</value></property><property><name>dfs.datanode.data.dir</name><value>/data/dn</value></property></configuration>PS:dfs.datanode.data.dir.perm :hdfs 文件系统 默认创建的文件权限 700 rwx---dfs.namenode.name.dir :NameNode 元数据的存储位置 在node1 节点的 /data/nn 目录下dfs.namenode.hosts NameNode 允许哪几个节点的DataNode连接dfs.blocksize :hdfs 默认块大小 256Mdfs.namenode.handler.count 并发线程数dfs.datanode.data.dir 从节点 DataNode的数据存放目录 -
在node1 节点: mkdir -p /data/nn mkdir /data/dn
-
在node2,node3节点:mkdir -p /data/dn
-
将node1 的hadoop 复制到 node2 和 node3
1. 在node1 执行cd /export/serverscp -r hadoop-3.4.1 node2:`pwd`/ scp -r hadoop-3.4.1 node3:`pwd`/ 2. 为node2 和 node 3 配置软链接 :ln -s /export/server/hadoop-3.4.1 hadoop -
配置环境变量 (node1,node2,node3都操作)
vim /etc/profile export HADOOP_HOME=/export/server/hadoop export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin source /etc/profile -
授权 hadoop 用户 (node1,node2,node3都操作,以root身份执行)
chown -R hadoop:hadoop /data chown -R hadoop:hadoop /export -
格式化namenode:只在node1执行
su - hadoop hadoop namenode -format -
启动
start-dfs.sh stop-dfs.sh 关闭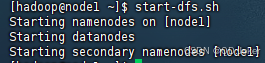
-
查看启动界面 可以看到有三个datanode
https://node1:9870 (node1替换为对应IP)
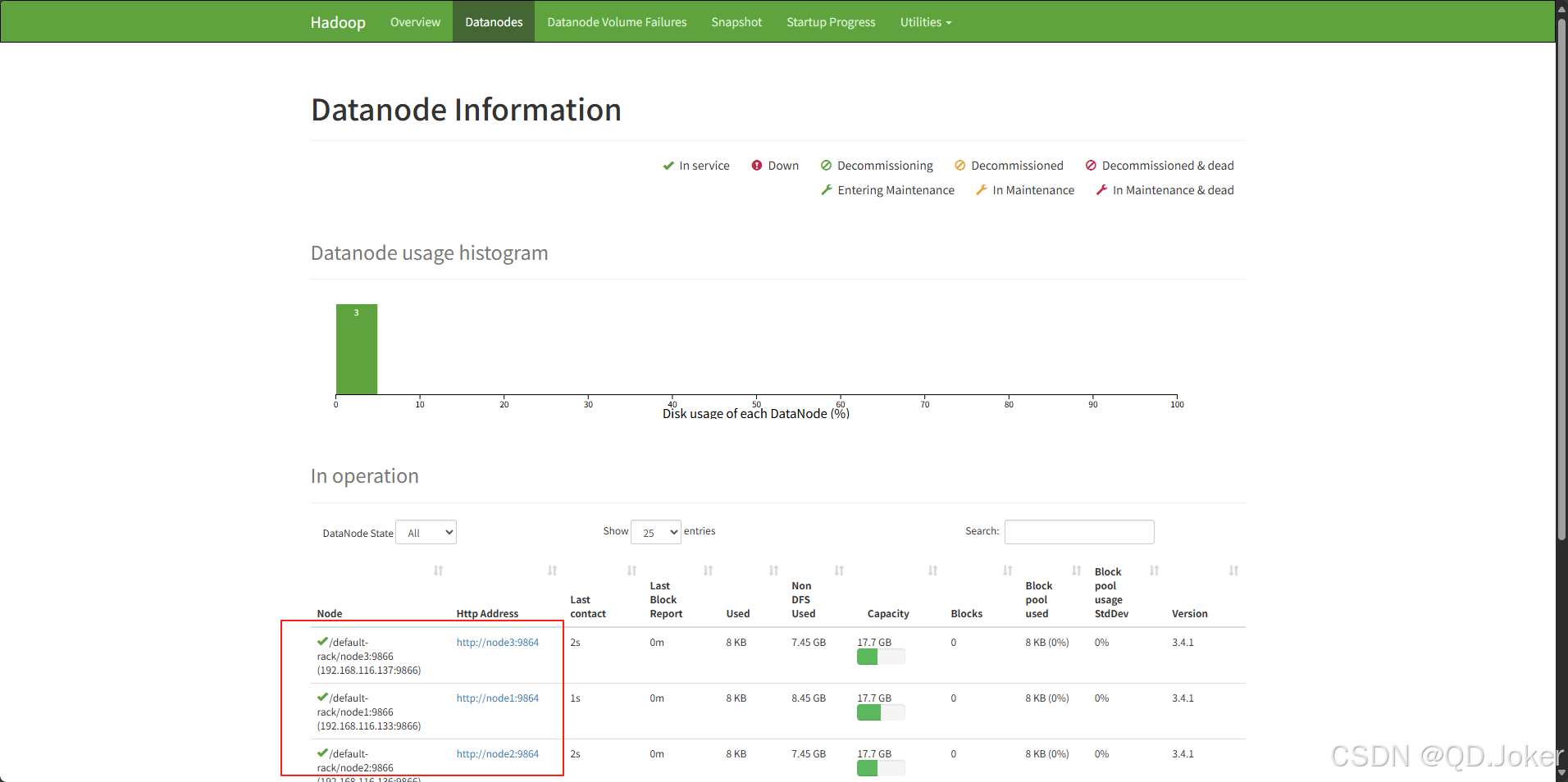
PS:通过 jps 命令可查看运行的服务