MySQL之分区功能
序言
随着业务发展,我们维护的项目数据库中的数据可能会越来越大,那么单张表的数据变多后,接口查询效率可能会变慢,那我们就直接照抄大厂常见的分库分表吗?—— 当然不是的,分库分表不是万能的。
分库分表会大大提高系统的复杂度,并且里面可能会踩不少坑:
- 分布式事务:比如进行了数据库表垂直拆分,那可能会涉及到分布式事务,可能就需要考虑2PC、3PC、Seata TCC、本地事务表等方案;
- 分布式ID:单表可能搞个自增主键就完事了,但是如果进行了分库分表,比如对数据库表进行了水平拆分,那你后续数据量变更多的时候,你需要再进行扩容,简单的自增主键可能会导致多张数据库表的主键重复且不唯一,那就得用到分布式Id,比如雪花算法(还需要考虑时间回拨、机器号管理问题)或美团的Leaf,相当于你可能需要专门搞个“发号器”服务;
- 分片查询:假设还是对数据库表进行了水平拆分,原来执行一句
select * from table where age > 25的SQL,现在需要跑遍所有分片,然后需要考虑把所有结果放在内存拼起来会不会让内存爆炸; - 数据备份/扩容:水平分库或者垂直分库后,数据库多了,运维时备份策略复杂到要画思维导图,扩容就像给高速行驶的汽车换轮胎——稍有不慎全村吃席;
真实案例:电商搞大促,本来分库分表是为了抗住流量,结果库存扣减因为跨库事务超时,30%订单直接失败。CTO 当场血压飙升:“这特么还不如不分!”
解决方案
-
- 索引优化:给数据库穿双跑鞋
别上来就搞分库分表,先看看你的索引是不是像老太太的裹脚布——又臭又长?
杀手锏:用EXPLAIN命令看SQL执行计划,把那些全表扫描(ALL)、临时表(Using temporary)的查询揪出来打;
口诀:联合索引遵循“最左匹配”,别建一堆单列索引占着茅坑不拉屎;
- 索引优化:给数据库穿双跑鞋
-
- 冷热分离:给数据分个「退休区」
3 年前的订单还天天查?不如把陈年老数据归档到history_orders表;
野路子:直接CREATE TABLE archive_table AS SELECT * FROM orders Where create_time < '2025-01-01'(记得加索引)
好处:主表瘦身成功,查询速度飞起;
- 冷热分离:给数据分个「退休区」
-
- 分区表:把大桌子切成抽屉
不用改代码!MySQL 自带分区功能,按月分、按 ID 分随你便;
- 分区表:把大桌子切成抽屉
-
- 读写分离:让小弟们干活
主库专心写数据,搞 10 个从库轮着查,用ShardingSphere这类工具自动分流;
注意:从库可能有延迟,重要操作(比如支付成功页)还是得查主库
- 读写分离:让小弟们干活
-
- 垂直拆分:把胖子表扒层皮
把大字段(比如商品详情、用户头像)单独存个表,主表只留核心字段
栗子:用户表拆成 (存 ID、姓名)和 (存地址、简介),减 少单行数据体积
- 垂直拆分:把胖子表扒层皮
-
- 氪金大法:加钱上 SSD!
别笑!很多公司用机械硬盘跑数据库,换 SSD 直接性能翻 10 倍
调参秘籍:
innodb_buffer_pool_size调到机器内存的 70%(别让数据库饿着)
innodb_flush_log_at_trx_commit=2适当牺牲点安全性换速度
- 氪金大法:加钱上 SSD!
-
- 找外援:NoSQL 来帮忙
搜索交给 ES:商品模糊查询别折腾数据库,Elasticsearch 专治各种不服;
缓存怼脸上:用 Redis 存库存、热门商品,读请求直接不碰数据库
日志存 Mongo:用户操作日志这种大 JSON,往 MongoDB一扔,省心省力;
- 找外援:NoSQL 来帮忙
什么情况必须分库分表?
- 数据量打不住:单表超过 5000 万行,眼瞅着要破亿(比如微信的消息表);
- 钱砸不动了:SSD 买顶配、内存加到 512G 还是卡成狗;
- 业务逼到墙角:每秒上万笔交易,不拆分明天就宕机;
分库分表两大流派:
- 垂直拆分:用户表、订单表、商品表各占一个库,适合业务复杂的中台系统;
- 水平拆分:
- 按用户 ID 取模:简单粗暴,但扩容得重新分片;
- 一致性哈希:扩容时只要迁移部分数据,互联网公司最爱;
- 按时间分片:适合日志类数据,直接按月分库;
分区表
上面的几种解决方案大多人多多少少都见过了,然后我们来看看分区表,下面就实战的看看分区表怎么玩?
由于MySQL天然支持分区操作,我们直接看看官网:mysql_doc_alter-table-partition-operations
先看我们展示的非分区表,表结构如下,
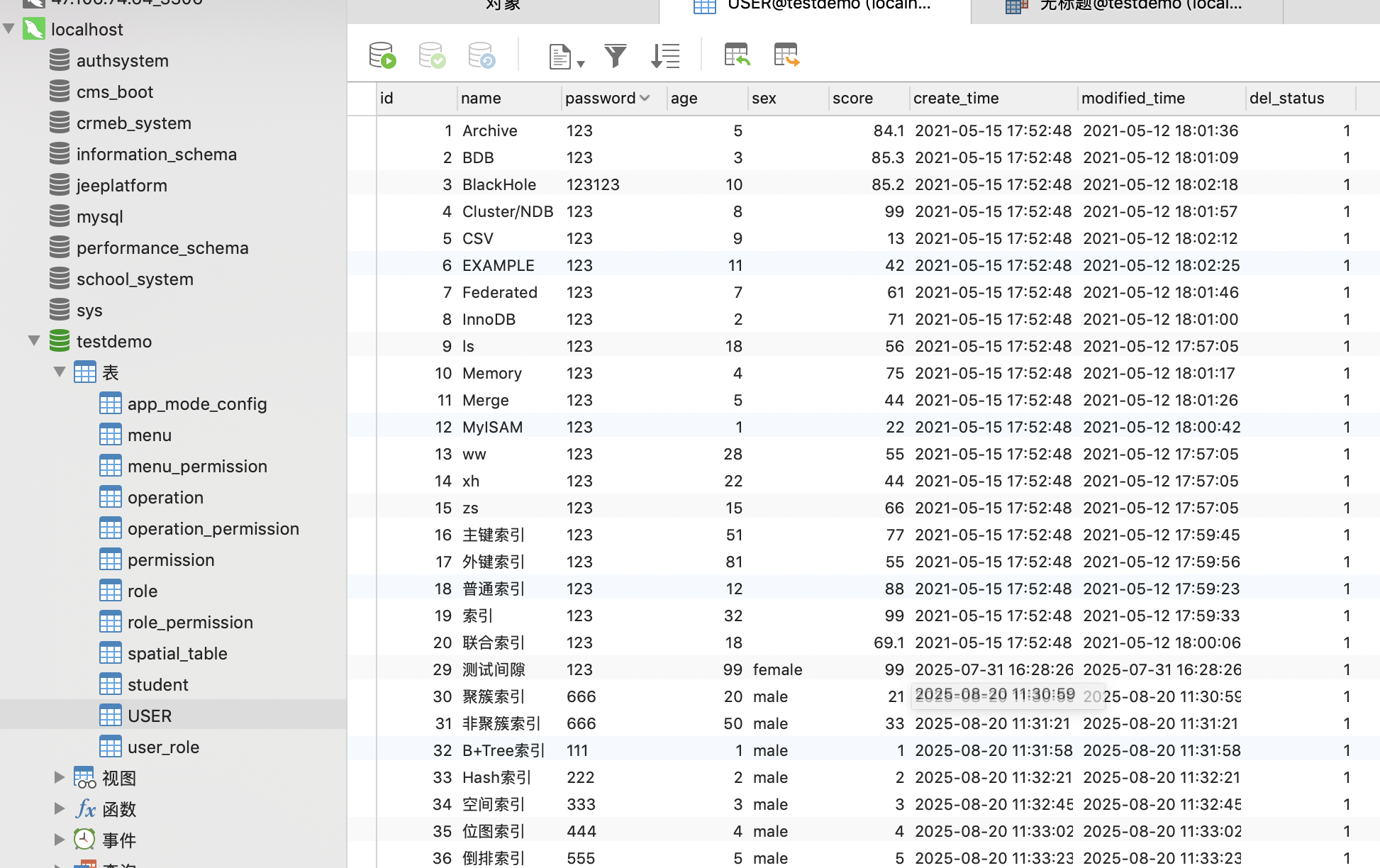
数据如下图所示,id为主键,
这里只是拿之前测试用的表做展示,表结构可以更加简化,这张表我们可以通过Hash主键id作为分区键,假设我们划分8个分区,执行下面的SQL指令,
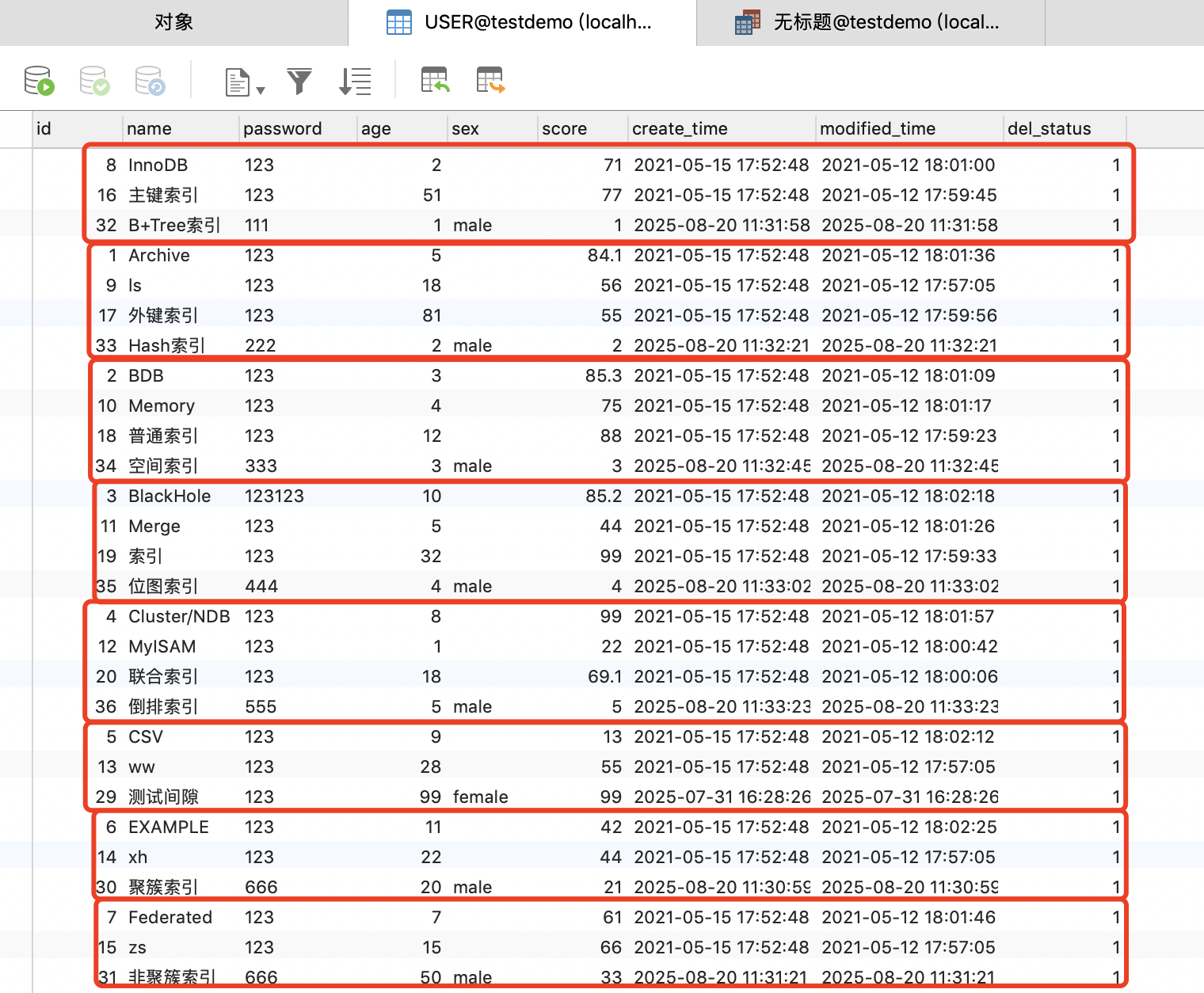
ALTER TABLE `USER`PARTITION BY HASH(id)PARTITIONS 8;
执行结果如下图,可以看到Partitioning Hash算法执行完后数据分布相对均匀,其实是因为在MySQL 8.4版本支持的线性Hash算法
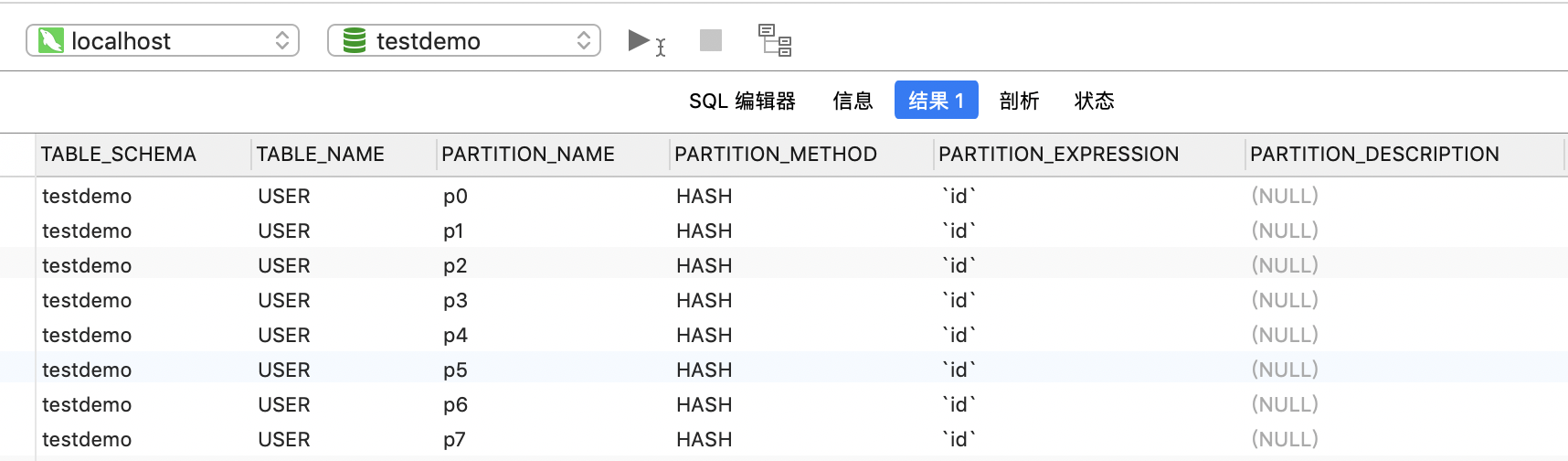
执行下面SQL命令,我们可以查看当前数据库表的分区情况
SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, PARTITION_METHOD, PARTITION_EXPRESSION, PARTITION_DESCRIPTION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA = 'testdemo' AND TABLE_NAME = 'USER';
结果如下图所示,数据库、表名、分区名、分区方法等一目了然,
理论上,执行ALTER TABLE USER DROP PARTITION p0,p1,p2,p3,p4,p5,p6,p7;是可以删除分区的,但是由于DROP PARTITION语句只能用于删除范围(RANGE)分区或列表(LIST)分区中的分区。这两种分区类型允许你基于连续的值范围或特定的值列表来组织数据。哈希(HASH)分区和键(KEY)分区是基于算法而非明确的值范围或列表进行分区的,因此不支持使用 DROP PARTITION 语句。

针对Hash分区和Key分区,我们可以执行下面命令还原成1个分区,但本质上和初始情况还是有一点差别,初始情况是没有分区的,而当前进行了一次分区,
ALTER TABLE `USER`PARTITION BY HASH(id)PARTITIONS 1;
ALTER TABLE … PARTITION BY使用规格必须和CREATE TABLE … PARTITION BY的一样,分区表的分区表达式中使用的所有列都必须是该表可能具有的每个唯一键的一部分
ALTER TABLE … PARTITION BY statement must follow the same rules as one created using CREATE TABLE … PARTITION BY
In other words, every unique key on the table must use every column in the table’s partitioning expression. (This also includes the table’s primary key, since it is by definition a unique key. This particular case is discussed later in this section.)
举个例子,执行下面的分区SQL就是无效的,
ALTER TABLE `USER`PARTITION BY HASH(age)PARTITIONS 5;

执行CREATE TABLE ... PARTITION BY对表t1和t2进行分区时,下面这种也是无效的,
CREATE TABLE t1 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1, col2)
)
PARTITION BY HASH(col3)
PARTITIONS 4;CREATE TABLE t2 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1),UNIQUE KEY (col3)
)
PARTITION BY HASH(col1 + col3)
PARTITIONS 4;
如果要进行分区,建议表中至少有一个唯一键,该键不包括分区表达式中使用的所有列,比如下面SQL就是有效的,
CREATE TABLE t1 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1, col2, col3)
)
PARTITION BY HASH(col3)
PARTITIONS 4;CREATE TABLE t2 (col1 INT NOT NULL,col2 DATE NOT NULL,col3 INT NOT NULL,col4 INT NOT NULL,UNIQUE KEY (col1, col3)
)
PARTITION BY HASH(col1 + col3)
PARTITIONS 4;
PARTITION BY的规则就不一一细说了,官网上有明确的解释,接下来我们看看官网PARTITION BY RANGE的规则和用法,如果没有唯一键(包括没有主键),上述规则就不适用了,可以使用任意列进行分区,如下示例,
CREATE TABLE t_no_pk (c1 INT, c2 INT)
PARTITION BY RANGE(c1) (
PARTITION p0 VALUES LESS THAN (10),
PARTITION p1 VALUES LESS THAN (20),
PARTITION p2 VALUES LESS THAN (30),
PARTITION p3 VALUES LESS THAN (40)
);
没有主键的t_no_pk表基本上很少见,这里可以忽略这种规则,如果有需要再来研究,

正常场景,分区使用主键,比如下面建了一个订单表,订单id和订单的创建时间作为联合主键,然后再根据创建时间进行按月分区,
CREATE TABLE orders (id BIGINT NOT NULL,user_id BIGINT NOT NULL,order_status VARCHAR(20) NOT NULL,create_time DATETIME NOT NULL,PRIMARY KEY (id, create_time)
)
PARTITION BY RANGE(YEAR(create_time)*100 + MONTH(create_time)) (
PARTITION p202501 VALUES LESS THAN (202501),
PARTITION p202502 VALUES LESS THAN (202502),
PARTITION p202503 VALUES LESS THAN (202503),
PARTITION p202504 VALUES LESS THAN (202504)
)
;
创建完后,可以执行下面SQL命令查看分区信息,
SELECT TABLE_SCHEMA, TABLE_NAME, PARTITION_NAME, PARTITION_METHOD, PARTITION_EXPRESSION, PARTITION_DESCRIPTION
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA = 'testdemo' AND TABLE_NAME = 'orders';

Mock数据,可以发现当我们插入了不在分区范围内的数据时会报错,
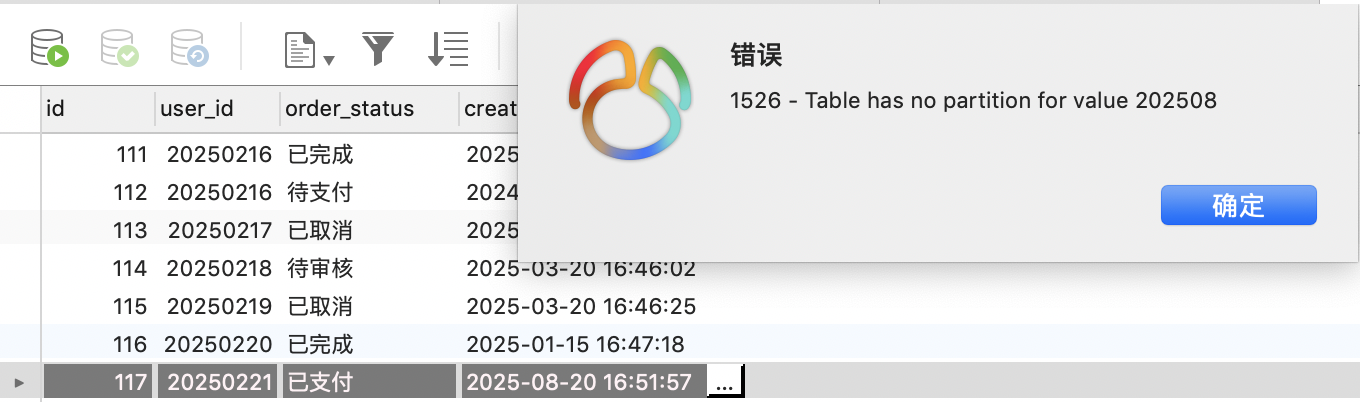
所以需要知行合一,你给数据库分区了之后超过你分区范围的数据都插不了数据库那不是线上大问题?
可以在时间分区后面加一个兜底PARTITION p299912 VALUES LESS THAN (300001),避免出现这种情况,至少你百年去世后这个数据插入也不会有问题。
那么分区之后有什么好处呢?
- 提升查询效率;
- 简化表维护;
假设数据如下,
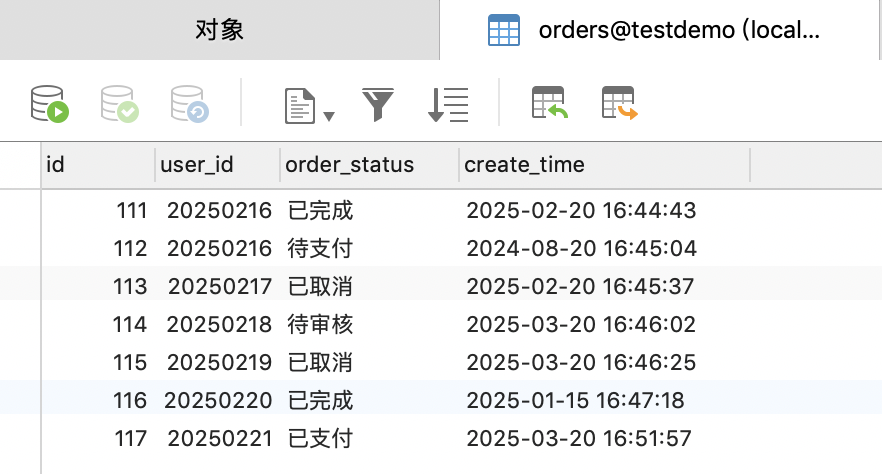
1、查询特定分区数据;
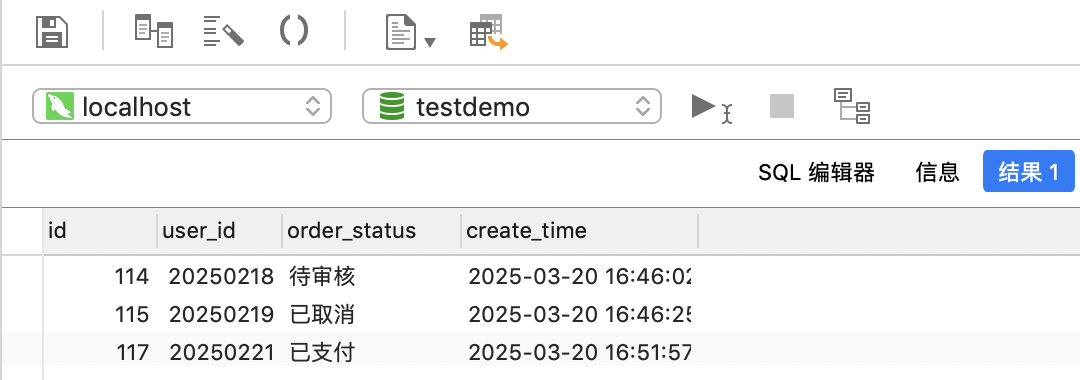
SELECT * FROM orders PARTITION (p202504);
如下图,我们查到的是大于2025年2月且小于2025年4月,即2025年3月份的数据,
2、使用了分区裁剪(Partition Pruning),当你在WHERE子句中指定了分区键的条件时,MySQL会自动利用分区裁剪来优化查询。例如,
SELECT * FROM orders WHERE create_time = '2025-02-20 16:45:37';
使用EXPLAIN该SQL语句可以看到select_type = SIMPLE(即不需要使用union或子查询的简单select查询),type = ALL即进行了全表扫描,但是走了partitions = p202503的分区,该分区的行数为2条记录(rows = 2)

3、删除旧数据比DELETE快10倍;
ALTER TABLE orders TRUNCATE PARTITION p202502;
