深度剖析Lua Table的运作方式
前言:本篇基于Lua-5.3.6源码并配合《Lua 解释器构建:从虚拟机到编译器》一书进行Table的运作解读。
一、Table数据结构
typedef struct Table {CommonHeader;lu_byte flags; /* 1<<p means tagmethod(p) is not present */lu_byte lsizenode; /* log2 of size of 'node' array */unsigned int sizearray; /* size of 'array' array */TValue *array; /* array part */Node *node;Node *lastfree; /* any free position is before this position */struct Table *metatable;GCObject *gclist;
} Table;如图:
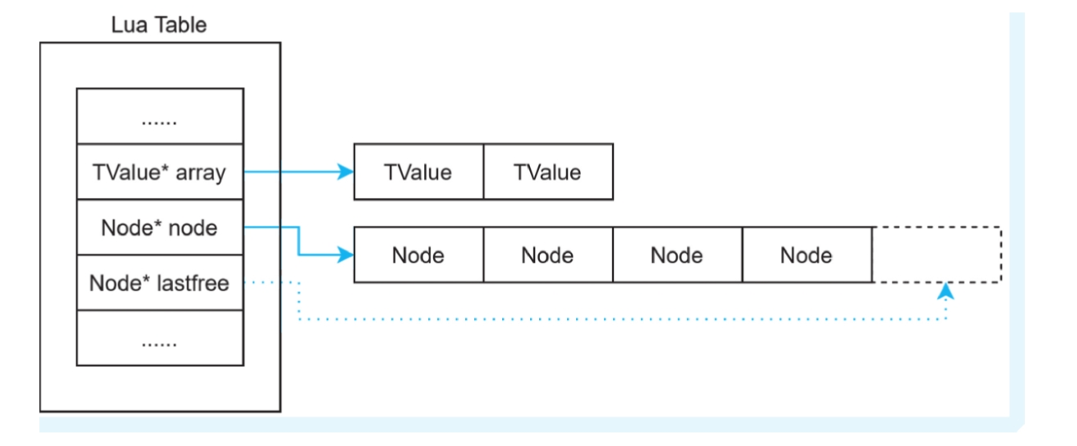
CommonHeader: GC的公共头部,标识是GC管理的对象,Table也是一个GC对象。
flags:标记缺失的元方法。比如:flags&(1<<TM_INDEX)为真表示缺少_index元方法。
lsizenode:哈希表大小的log2值,一来方便表示更大的存储容量,二来哈希表的扩容是成2倍增长的。
arraysize:数值的大小。
array:数组部分的指针。
node:哈希表部分的指针。
lastfree:哈希表空闲位置标记(指向最后一个空闲节点)
metatable:Table的元表,用来定义特定对象的元方法(如 __index、__newindex、__add 等)。
gclist:GC链表指针。
可以看到Table实际上是由两部分组成,数组部分和哈希表部分。
二、键值的哈希计算
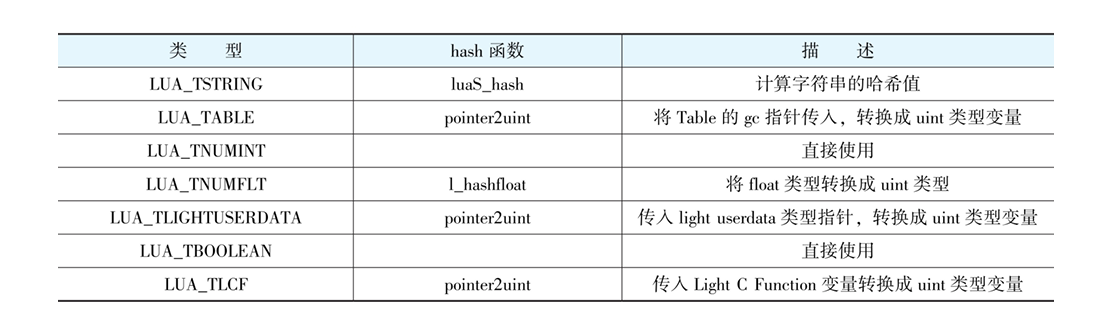
在完成了对key的哈希运算以后,就需要根据得到的哈希值,将其换算成表结构node数组的索 引值,计算的公式如下。
index=hash_value&()
这里-1是希望hash的低位全是1。
举例:假设有个字符串为"table",计算它在大小为8的哈希表的索引。
假设根据方法已经得到哈希值,01101011 00100100 10001101 00101100
lsizenode==3
那最终相与 只看后四位的结果 1100&0111=0100=4
key为“table"的node,将会被定位到hash[4]的位置上
三、Table查找元素
分两种情况,key值是int和非int
a.key是int
1)令被查找元素的key值为k,表array数组的⼤⼩为arraysize。
2)判断被查找元素的key值是否在数组范围内(即k≤arraysize是否成⽴)。
3)若key值在表的数组范围内,则返回array[k-1],流程终⽌。
4)若key值不在表的数组范围内,计算key值在哈希表中的位置,计算⽅式为
index=k&(),然后以hash[index]节点为起点,查找key值与k相等的node,如果没找到则返回nil。
b.key是非int
1)计算被查询元素的key值(记为k)的哈希值,记为key_hash。
2)计算key值在哈希表中的位置,计算⽅式为index=k&(),然后以 hash[index]节点为起点,查询key值与k相等的node,如果没找到则返回nil。
四、Table更新和插入
1)假设要新建的key值为k,计算k的哈希(hash)值,记为k_hash
2)计算key值在哈希表的索引,计算⽅式为index=k_hash &(2lsizenode-1)。
3)如果hash[index]的value值为nil,将其的key值设置为k的值,并返回value_对象指针,供调 ⽤者设置。
4)如果hash[index]的value值不为nil,需要分以下两种情况处理。
a. 计算node key的hash值,重新计算它的索引值。如果计算出来的索引位置不是hash[index], 那么lastfree不断左移,直⾄找到⼀个空闲的节点。将其移动到这⾥,修改链表关系,令其上⼀ 个与⾃⼰索引值相同节点的next值指向⾃⼰(如果存在的话)。新插⼊的key和value设置到 hash[index]节点上。
b. 计算node key的hash值,重新计算它的索引值,如果计算出来的索引位置就是hash[index], 那么lastfree不断左移,直⾄找到⼀个空闲的节点。将新插⼊的key和value值设置到这个节点 上,并调整链表关系,将hash[index]的key值的next值指向新插⼊的节点。
举例:
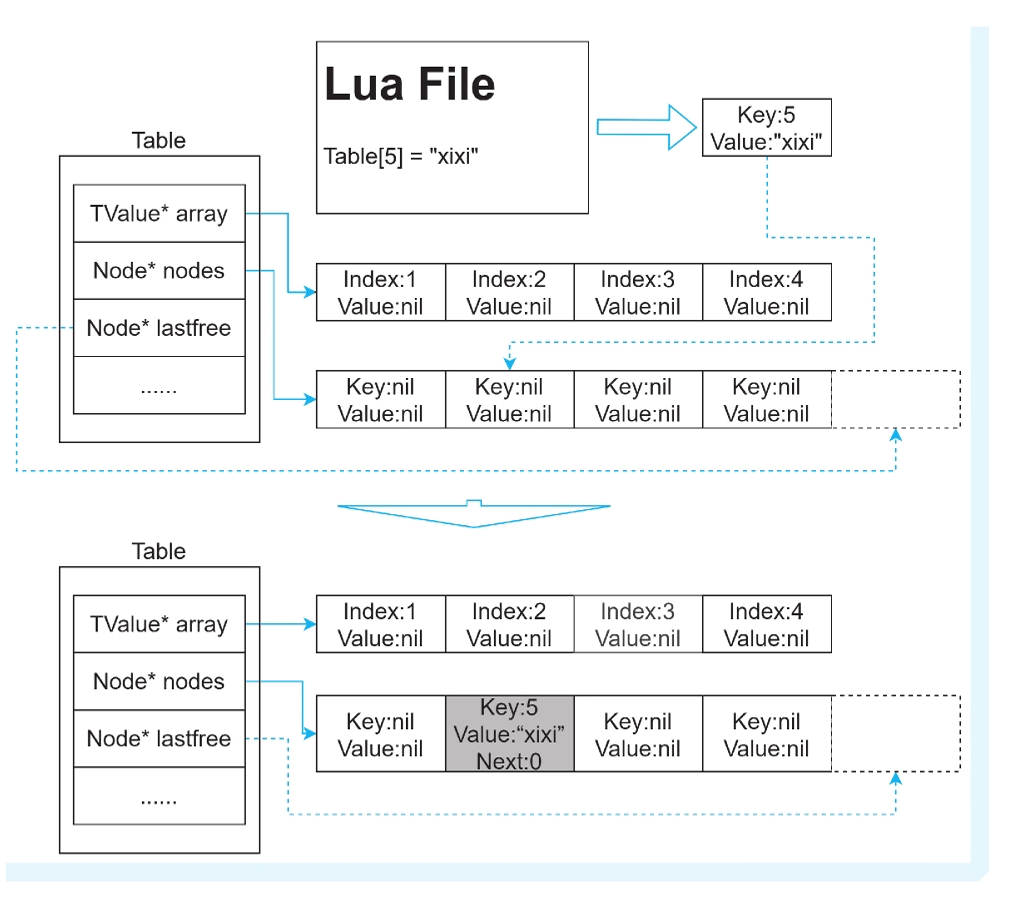
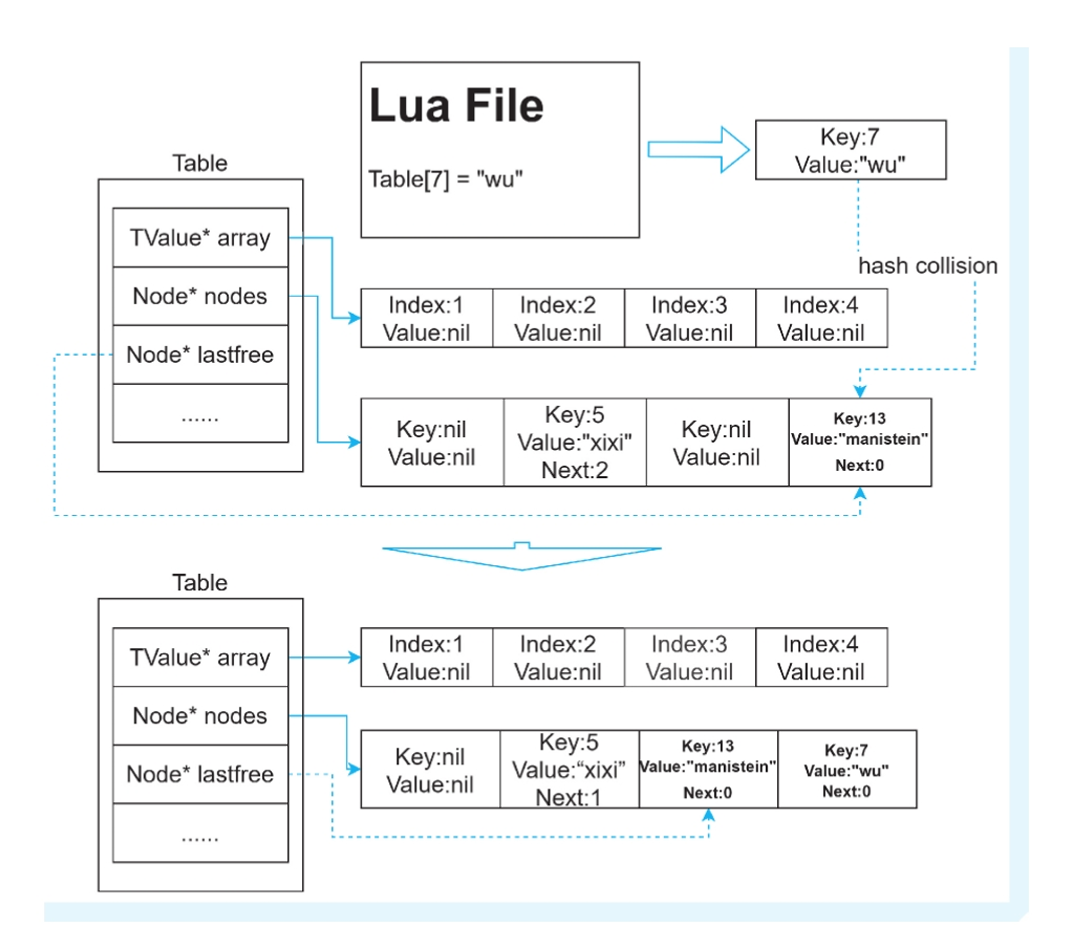
向表插⼊⼀个 key值为5、value值为“xixi”的元素。
由于key值5超出了数组的⼤⼩范围,那么程序⾸先会尝试 去哈希表中查找,可以得到最终index的值为1。hash[1]的key值为nil,与要更新元素的key值不 相等,于是触发了插⼊操作。由于hash[1]的key和value值均是nil,因此可以将该元素直接设置 到这⾥。
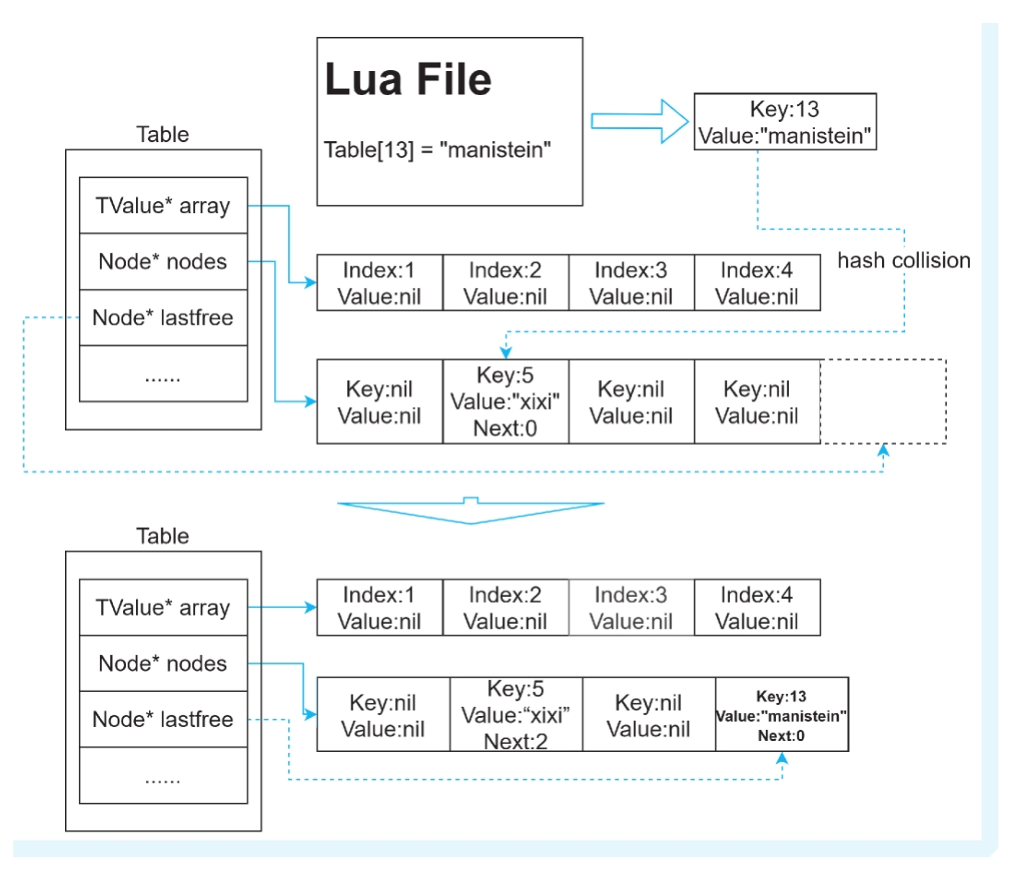
向表插⼊⼀个 key值为13、value值为“manistein”的元素。
根据公式算出index为1,因为hash[1]的value 域的值为“xixi”、key值为5,与k值13并不相等,于是便发⽣了哈希碰撞。key值5经过转换运算 得到的哈希表index的值为1,此时它就在这个位置上,因此key值为13的新元素需要被移⾛。 lastfree指针向左移动,并且将key值为13、value值为“manistein”的元素赋值到lastfree指向的位置上(即hash[3]的位置上),并且将hash[1]的key的next指向lastfree指针所指的位置。
注意:这里的next值指的是与当前index相隔的距离,而不是下一个节点的index值,因为这里的哈希表本身是个链表,存index值没有意义
向表插⼊⼀个 key值为7、value值为“wu”的元素。
经过计算得到其对应的hash表 index值为3,此时hash[3]已经被占⽤。此时需要计算占据在这⾥的元素的key值,其真实对应 的hash表index其实是1,因为hash[1]被占⽤才被移动到这⾥。因为这个元素计算得到的index 与当前位置并不匹配,因此lastfree指针需要继续向左移动,并将key值为13的元素迁移到这 ⾥,并更新其前置节点的next域。最后将key值为7的元素,赋值到hash[3]的位置上.
五、Table扩容机制
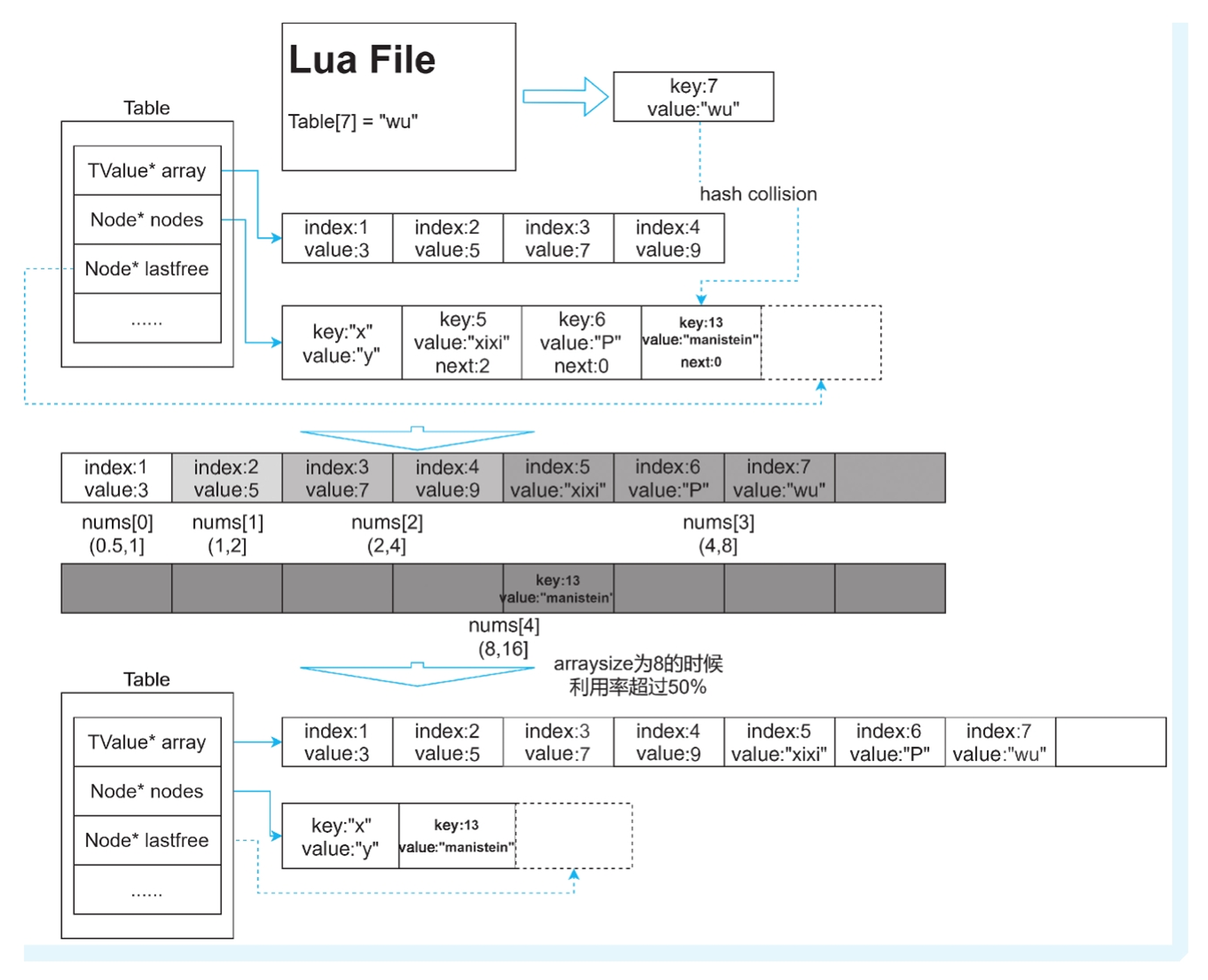
更新和插⼊的操作,均是在哈希表空间充⾜的情况下进⾏的,当哈希表 已满,且⼜有新的元素要插⼊哈希表时,将触发表的resize操作。首先调整的是数组的大小
1)统计要调整⼤⼩的Lua表、数组和哈希表中的有效元素(值类型不为nil的元素)的总数
2)创建⼀个int类型的数组,它的⼤⼩为32,将其命名为nums。nums [i]表示的信息量⽐较 ⼤。⾸先i表示⼀个数值区间,这个区间是(,
]
3)统计数组的分布情况,假设arraysize是66,且每个Value都不为空,那么此时它的分布情况是

即
4)统计哈希表元素在nums [32]中不同区间的分布情况,伪代码如下
//lsizenode是Table数据结构中衡量哈希表长度的变量
for(int i=0;i<pow(2,lsizenode);i++){if(hash[i].key!=null&&isInt(hash[i].key)){int k=ceillog2(hash[i].key);nums[k]++;}
}//找到hash key值在Nums数组中的下标
void ceillog2(int hashKey){for(int i=0;i<32;i++){if(pow(2,i)>=hash.key){return i;}}
}5)判断新插⼊元素new_element的key值是否为整类型,如果是则令
nums [FindIndex (new_element.key)]++。
6)完成数组nums的统计之后,根据nums计算新的数组⼤⼩。在数组⼤⼩范围内,值不为nil的 元素要超过数组⼤⼩的⼀半,其计算公式如下。
int asize=0;
for(int i=0;i<32;i++){asize+=nums[i];if(asize>pow(2,i)/2){sizearray=pow(2,i); //sizearray是Table中衡量数组大小的变量}
}7)计算在数组⼤⼩范围内有效元素的个数,记为array_used_num。
8)当数组⼤⼩⽐原来⼤时,扩展原来的数组到新的⼤⼩,并将哈希表中key值≤arraysize,且 >0的元素转移到数组中,并将哈希表⼤⼩调整为ceillog2(total_element-array_used_num), 同时对每个node进⾏重新定位位置。
数组扩大的简单理解:数组部分加入哈希表里面可以转移到数组里的键值对,此时数组部分超过一半都是不为nil。
示例:
9)当数组⼤⼩⽐原来⼩时,缩⼩原来的数组到新的⼤⼩,并将数组中key值超过数组⼤⼩的元 素转移到哈希表中。此时哈希表⼤⼩调整为ceillog2(total_element-array_used_num),同时 对每个node进⾏重新定位位置。
数组缩小的简单理解:数组不连续的key转移到哈希表,此时数组超过一半都是nil。
基于8-9至此我们可以推理到一个二级结论:
哈希表里最新的int的类型key值一定大于数组长度(sizearray)。
这个结论对于后续Table的遍历起到了一定的理论依据。
六、Table遍历
Lua提供了luaH_next函数来进⾏迭代操作,函数申明如下

方法中关键调用是findIndex方法,5.3源码如下
/*
** returns the index of a 'key' for table traversals. First goes all
** elements in the array part, then elements in the hash part. The
** beginning of a traversal is signaled by 0.
*/
static unsigned int findindex (lua_State *L, Table *t, StkId key) {unsigned int i;if (ttisnil(key)) return 0; /* first iteration */i = arrayindex(key);if (i != 0 && i <= t->sizearray) /* is 'key' inside array part? */return i; /* yes; that's the index */else {int nx;Node *n = mainposition(t, key);for (;;) { /* check whether 'key' is somewhere in the chain *//* key may be dead already, but it is ok to use it in 'next' */if (luaV_rawequalobj(gkey(n), key) ||(ttisdeadkey(gkey(n)) && iscollectable(key) &&deadvalue(gkey(n)) == gcvalue(key))) {i = cast_int(n - gnode(t, 0)); /* key index in hash table *//* hash elements are numbered after array ones */return (i + 1) + t->sizearray;}nx = gnext(n);if (nx == 0)luaG_runerror(L, "invalid key to 'next'"); /* key not found */else n += nx;}}
}细分key值四种情况:
情况一:key=nil
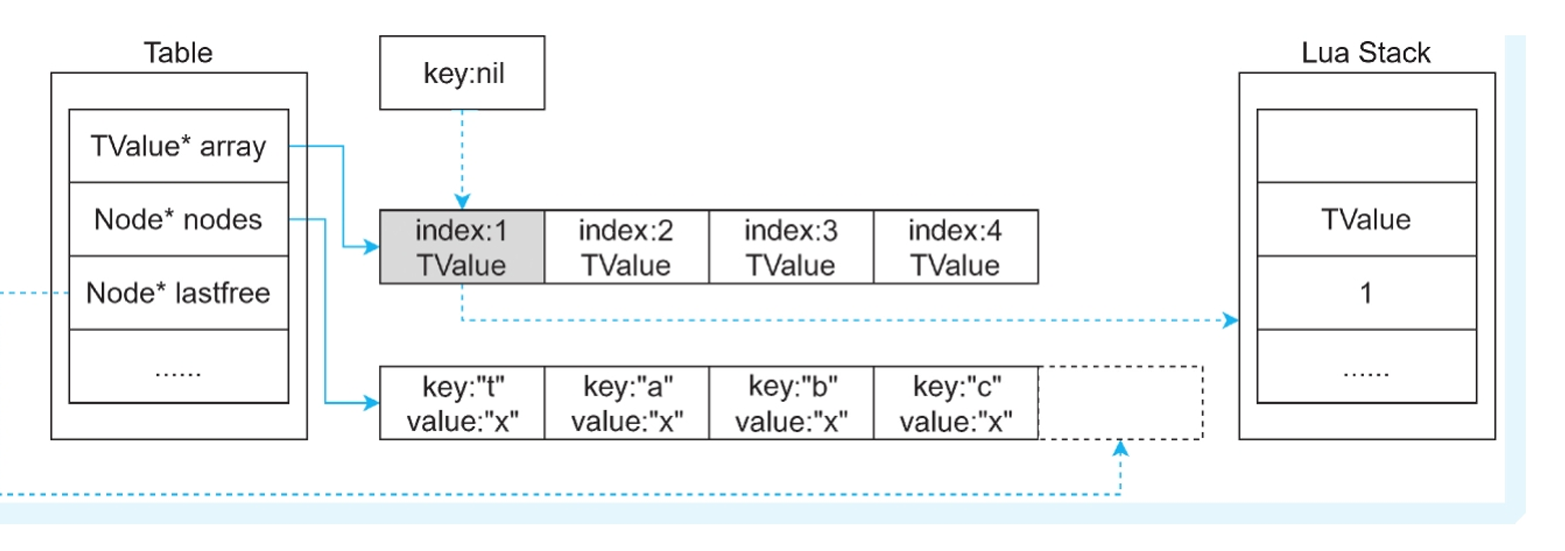
返回数组的第一个元素。
情况二:key=整型&&key<sizearray
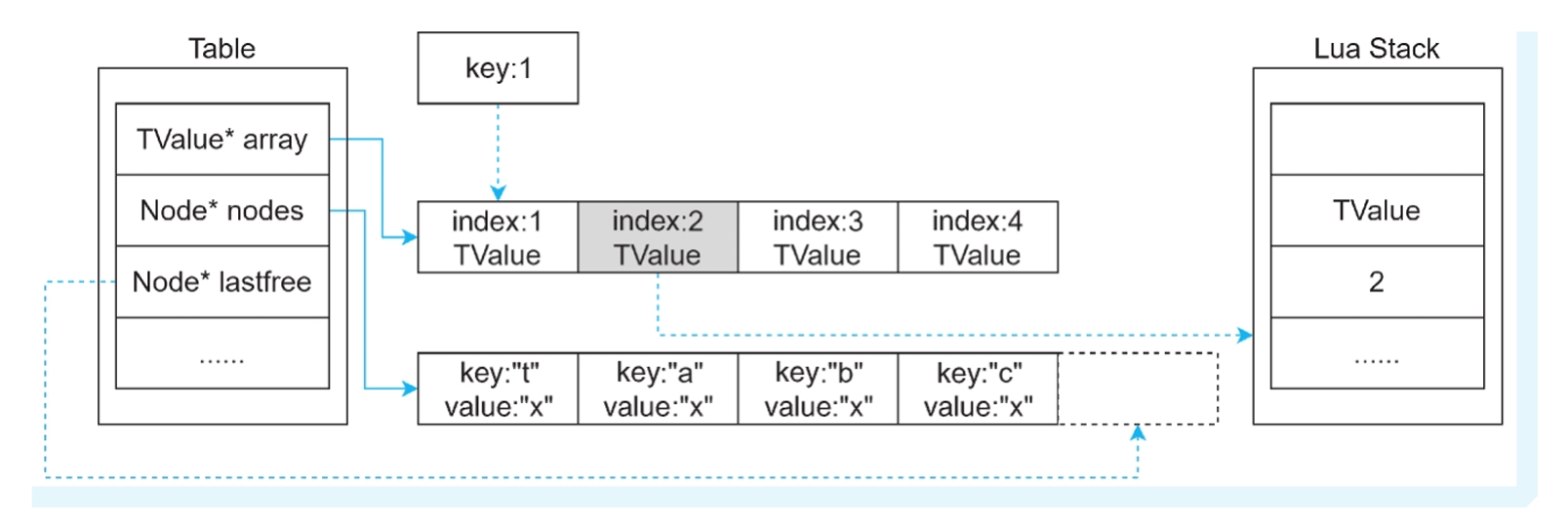
返回数组的下一个元素。
情况三:key=整型&&key==sizearray
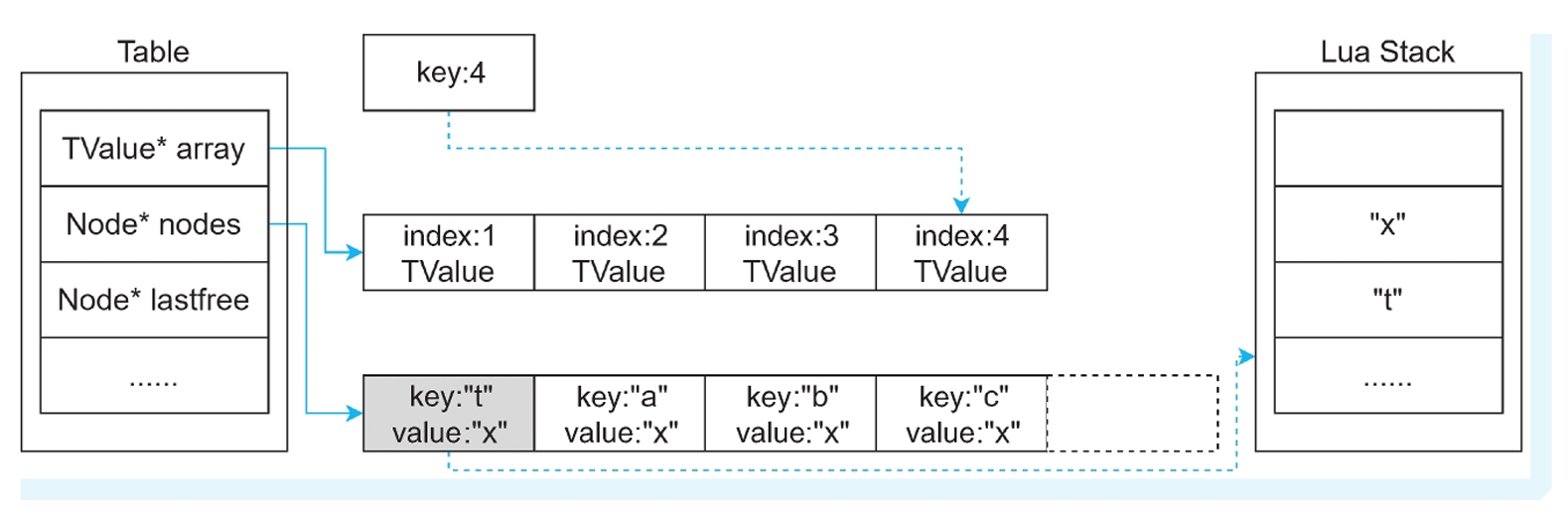
返回哈希表的第一个元素。
情况四:key!=整型
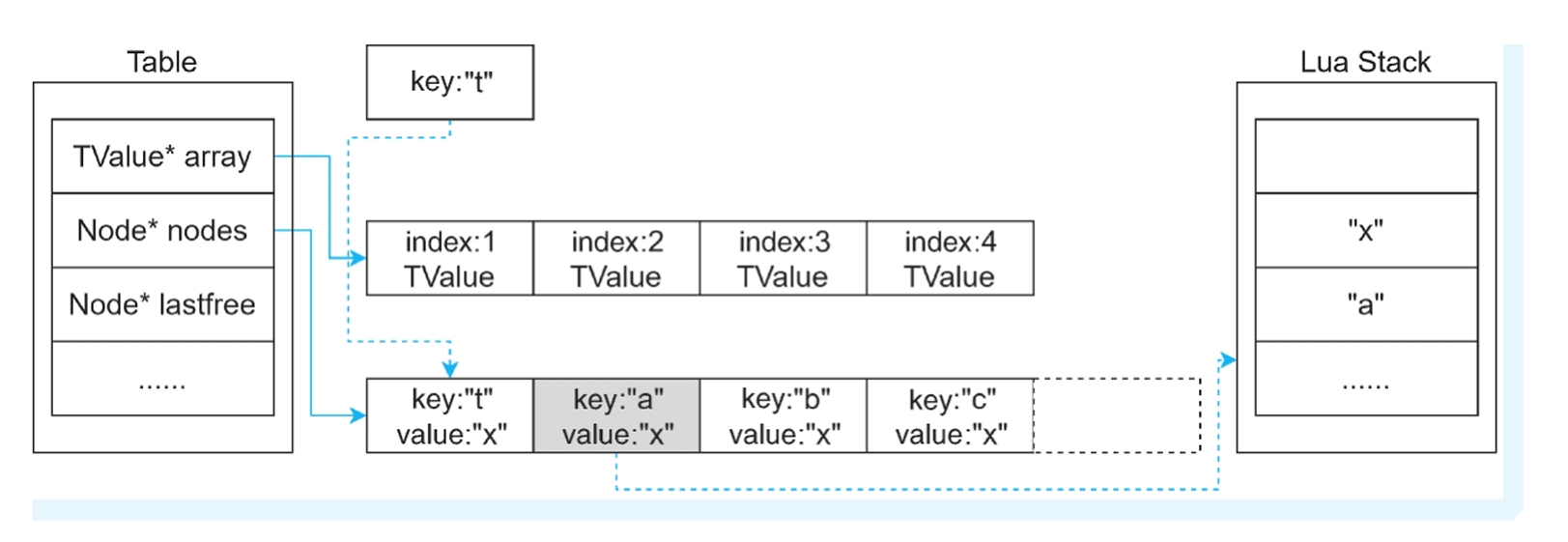
返回哈希表的下一个元素。
七、解读和Table相关的接口
1)pairs和ipairs
- pairs(t):用于遍历表中所有键值对(无序),默认使用内建的 next 函数遍历所有键。顺序不保证,对稀疏表或散列部分都能遍历到。
- ipairs(t):用于按整数索引从 1 开始顺序遍历,直到遇到第一个 nil 为止。常用于“数组风格”的连续整数索引。
注意:ipairs并不仅仅遍历array部分,hash部分也会遍历,因为由前文可得,hash部分也会存在连续的整型key。