BM25 系列检索算法
我来系统科普一下 BM25 系列检索算法。这些算法都属于 基于词频统计的经典信息检索模型,常用于搜索引擎、文本匹配、向量数据库的倒排索引部分。
1. BM25
BM25 (Best Matching 25) 是目前最常用的 词袋模型检索函数,基于 TF-IDF 改进。
核心思想:
TF 部分(词频饱和): 对词频采用饱和函数,而不是简单计数,避免长文档因为词重复而被过度加权。
IDF 部分(逆文档频率): 罕见词权重大,常见词(如“的”“是”)权重小。
文档长度归一化: 引入参数调节长文档惩罚。
公式(简化版):
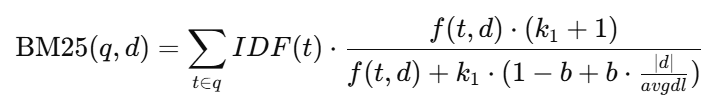
f(t,d):词 ttt 在文档 ddd 中的词频
∣d∣:文档长度
avgdl:平均文档长度
k1:词频饱和参数(一般 1.2–2.0)
b:文档长度惩罚系数(0–1,常取 0.75)
特点:相对稳健,效果好,是搜索引擎的基线模型。
2. BM25L
BM25L 是 BM25 的一个变种,主要针对 长文档惩罚过度 的问题。
在 BM25 中,长文档往往被压低分数,而 BM25L 通过 线性调整 缓解了这个问题。
公式(直观差别):
在 BM25 的分母中加上一个 常数 δ,确保长文档的词频贡献不会被过度稀释。
特点:对长文本更友好,减少 BM25 对长文档的“歧视”。
3. BM25+
BM25+ 是 BM25 的另一改进版,主要解决 短文档得分过低 的问题。
在 BM25 中,如果文档很短,即使包含查询词,得分也可能偏低。
BM25+ 在公式中加上 一个常数补偿项 ε,保证至少有一个“基线分数”。
特点:
对短文档更友好
使得得分分布更加平衡
🔹 4. BM25Okapi(或 BM25-Okapi)
BM25Okapi 本质上就是 BM25 的标准实现版本。
名字来源于 Okapi 信息检索系统,这是最早实现 BM25 的系统,因此很多库里会写 BM25Okapi 来区分。
特点:和 BM25 等价,不是新的变体。
(例如 rank_bm25 Python 库里就是 BM25Okapi 类)。
总结对比
| 算法 | 主要改进点 | 适用场景 |
|---|---|---|
| BM25 | 词频饱和 + 文档长度归一化 | 通用搜索,稳健的基线 |
| BM25Okapi | 标准 BM25 实现 | 工程应用中常见的名字 |
| BM25L | 缓解长文档惩罚 | 长文本检索(如维基百科文章) |
| BM25+ | 提升短文档得分 | 短文本检索(如新闻标题、问答场景) |
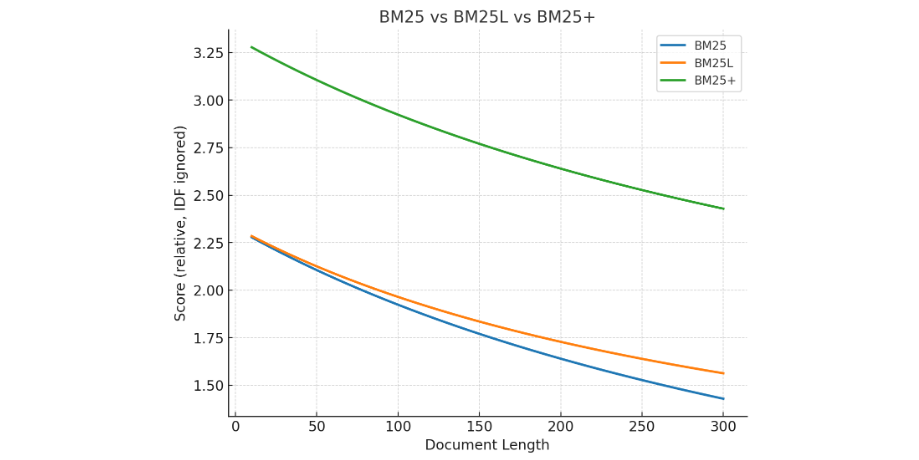
这张图展示了 BM25、BM25L、BM25+ 在文档长度变化时的打分趋势差异:
BM25(蓝线):随着文档变长,分数明显下降。
BM25L(橙线):下降趋势更平缓,减轻了长文档惩罚。
BM25+(绿线):整体曲线比 BM25 高,尤其在短文档时更友好。