RAG系统文本检索优化:Cross-Encoder与Bi-Encoder架构技术对比与选择指南
文本编码技术是现代搜索系统、推荐算法、语义相似度分析和检索增强生成(RAG)系统的基础核心。在众多文本编码策略中,Cross-Encoder和Bi-Encoder两种架构因其独特的设计理念和应用特性而被广泛采用。本文将深入分析这两种编码架构的技术原理、数学基础、实现流程以及各自的优势与局限性,并探讨混合架构的应用策略。
自然语言处理系统的核心任务之一是准确测量文本间的语义相似性。在语义搜索场景中,系统需要将用户查询与相关文档进行匹配;在问答系统中,需要比较问题与知识库条目的相关性;在推荐系统中,需要分析产品描述或用户评论之间的关联性。编码器架构的选择直接决定了系统在准确性、响应延迟和可扩展性方面的表现。
Cross-Encoder架构
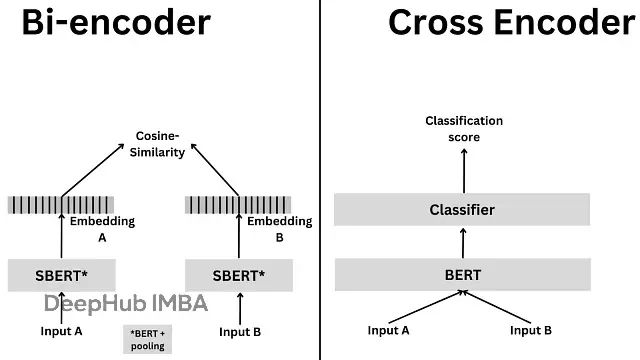
Cross-Encoder采用联合编码策略,将两个文本输入作为整体进行处理,从而能够捕获文本间的深层交互特征。
编码机制
Cross-Encoder的编码过程包含四个关键步骤。首先是输入拼接阶段,将两个待比较的文本(句子A和句子B)合并为单一输入序列,格式为:
[CLS] Sentence A [SEP] Sentence B [SEP]
随后进入联合编码阶段,拼接后的序列被输入到Transformer模型(如BERT或RoBERTa)中。Transformer的自注意力机制能够在每个编码层中建模句子A与句子B之间的交叉交互关系。
在表示提取阶段,系统提取[CLS]位置的输出向量或通过池化操作获得的综合表示作为文本对的联合特征。最终,通过全连接层或其他评分函数处理这些特征,生成相似度或相关性分数。
数学建模
设定输入文本对为A = "How to train a neural net?"和B = “Guidelines for neural network training.”,Cross-Encoder的数学表示如下:
首先进行文本拼接:
C = concat(A, B)
然后使用Transformer T进行联合编码:
H = T©
最后通过评分层计算相似度(例如前馈网络加sigmoid激活):
s = σ(WH[CLS] + b)
其中W为权重矩阵,b为偏置项,σ为激活函数,s为最终的相似度分数。
完整的相似度计算可表示为:
s = f(Transformer([CLS], A, [SEP], B, [SEP]))
其中f通常为小型神经网络或分类回归模块。
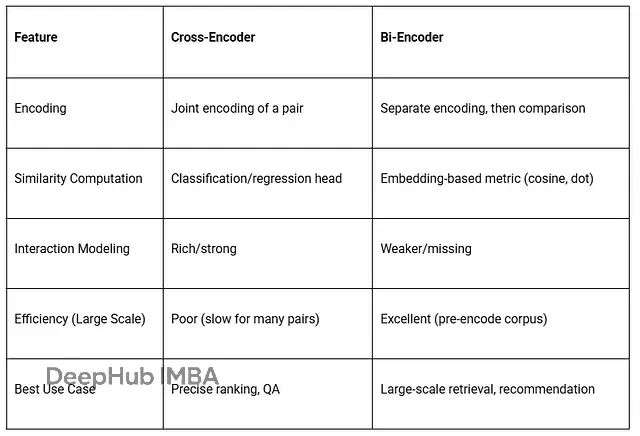
Cross-Encoder的主要优势在于其强大的跨文本交互建模能力。由于两个文本在编码过程中能够进行充分的信息交换,该架构在关系建模方面表现出色,能够捕获细微的语义差别。
然而,Cross-Encoder在大规模应用中面临显著的计算效率挑战。每个文本对都需要独立的前向传播过程,这使得在处理大量候选文档时计算成本急剧增加,难以满足实时检索的性能要求。
Bi-Encoder架构
Bi-Encoder采用独立编码策略,使用相同的模型参数分别对每个文本进行编码,生成固定维度的向量表示,然后通过向量运算计算相似度。
编码机制
Bi-Encoder的编码过程分为两个主要阶段。在独立编码阶段,句子A和句子B分别输入到Transformer编码器中,生成各自的向量表示:
HA = T(A)HB = T(B)
编码过程通常采用[CLS]标记的输出向量或跨token的均值池化操作来获得最终的句子嵌入表示。在相似度计算阶段,系统采用余弦相似度等度量方法比较两个向量:
s = cos(HA, HB) = HA · HB / (‖HA‖ ‖HB‖)
除余弦相似度外,点积或曼哈顿距离等度量方法也可用于相似度计算。
数学建模
对于相同的输入示例A = "How to train a neural net?"和B = “Guidelines for neural network training.”,Bi-Encoder的处理流程如下:
独立编码生成向量表示
HA = T(A)HB = T(B)
计算余弦相似度
s = HA · HB / (‖HA‖ ‖HB‖)
Bi-Encoder的核心优势体现在其优异的计算效率和可扩展性。由于文本可以预先编码并存储,查询时仅需编码查询文本并进行向量比较,大大提升了大规模检索的效率。这一特性使其成为实时搜索系统的理想选择。
然而,独立编码的设计限制了Bi-Encoder捕获文本间细粒度交互的能力。相比Cross-Encoder,其在处理复杂语义关系时可能出现精度损失,特别是在需要深度理解文本间关系的任务中表现相对有限。
混合架构策略
实际生产系统中,混合架构成为平衡效率与精度的有效解决方案。典型的混合策略采用两阶段处理模式:首先使用Bi-Encoder进行快速检索,从大规模候选集中筛选出top-K个最相关的候选项;随后采用Cross-Encoder对这些候选项进行精确重排序,获得最终的排序结果。
这种检索-重排序的流水线设计在Google、Bing等主流搜索引擎以及各类RAG系统中得到广泛应用,有效实现了速度与精度的最优平衡。
应用场景分析
Bi-Encoder架构特别适用于语义搜索、RAG检索、推荐系统和文本聚类等需要高效处理大规模数据的场景。其预编码特性使其能够支持实时查询响应。
Cross-Encoder架构则更适合重复内容检测、法律和医学文本分析、释义识别以及重排序等对精度要求极高的任务。其强大的交互建模能力能够准确捕获复杂的语义关系。
混合架构在搜索引擎、问答系统以及需要同时满足规模和精度要求的多智能体系统中发挥重要作用。
总结
Cross-Encoder与Bi-Encoder的选择本质上是一个技术权衡问题。当系统主要关注处理规模和响应速度时,Bi-Encoder是优先选择;当系统需要高精度和细粒度的语义理解时,应当考虑Cross-Encoder;当两种需求并存时,混合架构结合蒸馏技术能够提供最佳解决方案。
随着大型语言模型在实际应用中的普及,深入理解这些编码策略对于构建高效、准确且可扩展的AI系统具有重要意义。
https://avoid.overfit.cn/post/966ec92713eb421eb456b546d8c9a661