多肽修饰——胆固醇(chol)
胆固醇分子上通常用于连接的基团是3-位的羟基,
连接键的类型:
- 通过胆固醇氯甲酸酯连接会形成氨基甲酸酯键:胆固醇的羟基与光气或其衍生物反应生成。氯甲酸酯基团非常活泼,很容易与N端的氨基反应形成氨基甲酸酯键。。
- 通过胆固醇半琥珀酸酯连接会形成酰胺键:胆固醇的羟基与琥珀酸酐反应,生成一端是胆固醇酯、另一端是游离羧基的化合物。这个游离羧基可以通过碳二亚胺类缩合剂(如EDC)活化,然后与N端的氨基反应形成酰胺键。
- 这两种键在生理条件下都比较稳定。
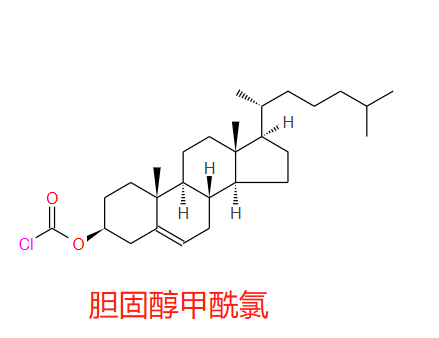
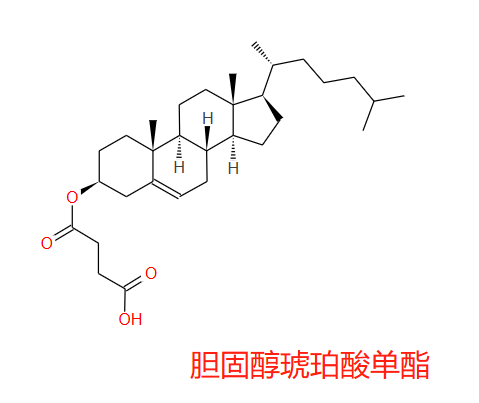
多肽修饰——胆固醇(chol),能够:
增强细胞膜穿透性: 胆固醇具有亲脂性,能够插入细胞膜。将其连接到多肽上(形成所谓的“胆固醇化多肽”或“脂肽”),可以显著提高多肽穿过细胞膜进入细胞的能力,这对于需要作用于细胞内的多肽药物(如抗癌肽、抗病毒肽)至关重要。
延长血液循环半衰期: 胆固醇化可以使多肽更容易与血液中的脂蛋白(如HDL、LDL)结合,从而减少肾脏清除,延长其在体内的作用时间。
改善药代动力学性质: 综合提升吸收、分布和稳定性。
靶向递送: 利用脂蛋白受体介导的胞吞作用,可以将胆固醇化多肽靶向递送到表达特定脂蛋白受体的细胞或组织。
连接位点选择N端:
易于定位和修饰: N端在多肽中是独特的(只有一个),不像侧链基团(如Lys的ε-氨基)可能有多个且性质类似,修饰时选择性较差。这简化了合成和纯化过程。
空间位阻相对较小: 相对于侧链基团,N端氨基通常位于多肽链的末端,空间位阻相对较小,更容易被修饰试剂接近。
避免干扰功能性侧链: 如果多肽的关键功能依赖于特定的侧链(如活性位点的His、Ser、Asp等),将胆固醇连在远离这些位点的N端可以减少对其功能的干扰。
其他连接位点:
C端: 也可以通过类似原理连接到C端的羧基上(通常需要活化羧基,如形成活性酯)。
侧链: 可以连接到含有反应性侧链基团的氨基酸上,最常见的是赖氨酸的ε-氨基。这通常需要保护N端α-氨基,或者在合成时选择性地修饰特定位置的Lys。连接方式与N端类似(活化胆固醇后形成氨基甲酸酯键或酰胺键)。
选择N端、C端还是侧链取决于具体的多肽序列、功能需求以及合成策略。