医学统计学常用方法汇总,差异性/相关回归/生存分析/一致性检验
在现代医学研究中,统计方法已成为不可或缺的分析工具。从课题设计到数据采集,从结果阐释到成果发表,统计思维贯穿科研全流程。本文将系统梳理医学研究中常用的统计分析方法,包括差异性分析、相关回归分析、生存分析、一致性检验等方法。
一、差异性分析
差异性分析用于比较不同组间某个指标的差异是否有统计学意义。简单可以分为研究单样本、两样本、多样本资料之间均数的差异性比较以及定类数据之间差异性比较;分类说明如下:
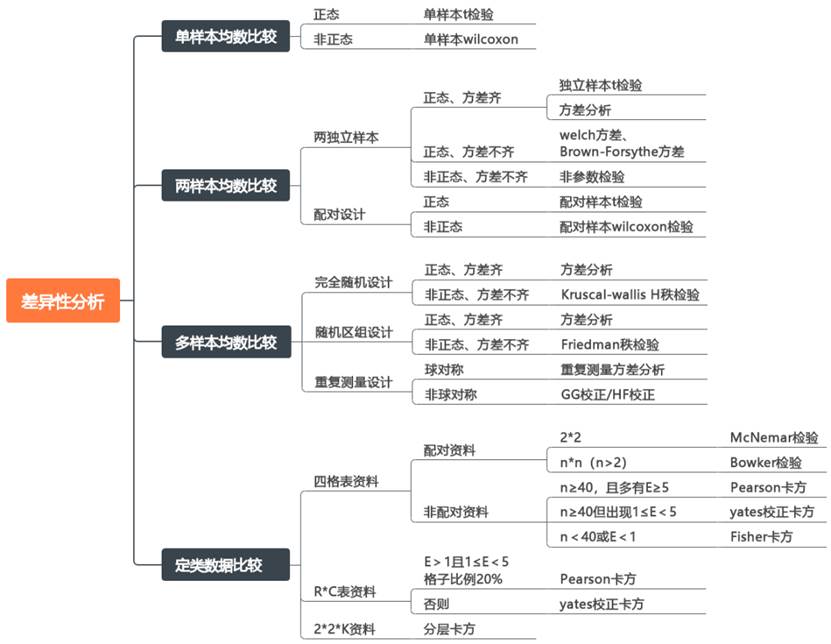
1、单样本均数比较
单样本均数比较主要用于比较一个样本的均数与已知总体均数之间的差异。根据数据是否服从正态分布,可以选择不同的检验方法: 例如研究40名同学数学成绩与优秀分80分之间的差异:
例如研究40名同学数学成绩与优秀分80分之间的差异:
- 当数据满足正态性时,可以使用单样本t检验方法进行研究;
- 当数据不满足正态性时,可以使用单样本wilcoxon检验进行研究。
点击下方链接可以跳转至SPSSAU方法帮助手册:
- 单样本t检验
- 单样本wilcoxon检验
2、两样本均数比较
两样本均数比较用于比较两个独立样本或配对样本的均数差异。根据样本的设计和数据分布特性,可以选择不同的检验方法: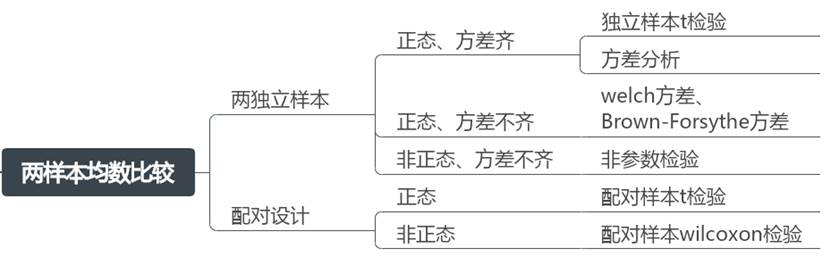
例如研究两类不同药品的降血压效果是否有差异;而两样本设计又可以分为两独立样本和两配对样本。
(1)两独立样本
- 当两样本数据都满足正态性和方差齐性,则可以使用独立样本t检验或者单因素方差分析进行研究;
- 当数据呈正态但方差不齐时,可以使用welch方差、Brown-Forsythe方差进行研究;
- 当数据非正态且方差不齐时,应该使用非参数检验法,具体两组数据差异性使用MannWhitney统计量。
(2)配对设计
当两配对数据的差值满足正态性,使用配对样本t检验进行研究;
当差值不满足正态性时,使用配对样本wilcoxon检验进行分析。
点击下方链接可以跳转至SPSSAU方法帮助手册:
- 独立样本t检验
- 单因素方差分析
- 非参数检验
- 配对样本t检验
- 配对样本wilcoxon检验
3、多样本均数比较
多样本均数比较用于比较三个或更多样本的均数差异。根据实验设计和数据分布特性,可以选择不同的检验方法:
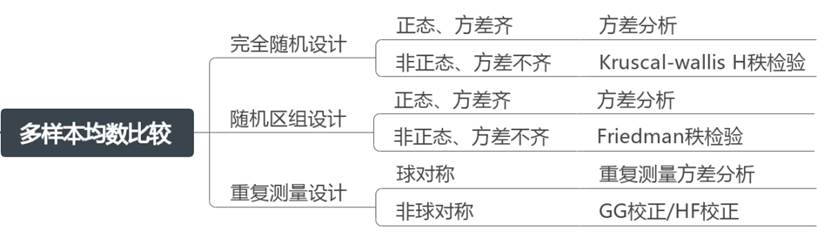
例如研究某种药物不同剂量下小鼠的存活时间;而多样本设计又可分为完全随机设计、随机区组设计、重复测量设计。
(1)完全随机设计
要将研究对象按照某个处理因素随机分配为多个处理组(也称为处理因素的水平),每组接受一种处理,最后判断多个处理组之间有无差别。
- 当数据满足正态性和方差齐性时,使用方差分析进行研究;
- 数据不满足时,可以使用Kruskal-wallis H秩和检验进行分析。
(2)随机区组设计
是配对设计的扩展。具体做法是:先按影响实验结果的非处理因素(如性别、体重、病情、病程等)将实验对象配成区组(block),再分别将各区组内的实验对象随机分配到各处理组或对照组。
- 当数据满足正态和方差齐时,使用方差分析进行研究;
- 数据不满足时,可以使用Friedman检验进行分析。
(3)重复测量设计
当前后测量设计的重复测量次数m≥3时,称重复测量设计或重复测量数据。重复测量数据进行组内项差异分析时,需要进行球对称假设,当满足时,直接使用重复测量方差分析结果;当不满足时,采用Greenhouse-Geisser校正或者Huynh-Feldt校正结果分析。
点击下方链接可以跳转至SPSSAU方法帮助手册:
- 单因素方差分析
- Kruskal-wallis H秩检验
- 多样本Friedman检验重复测量方差分析
4、定类数据比较
定类数据比较用于比较分类变量之间的关系,主要使用卡方检验进行分析。根据数据类型和样本量大小,可以选择不同的检验方法: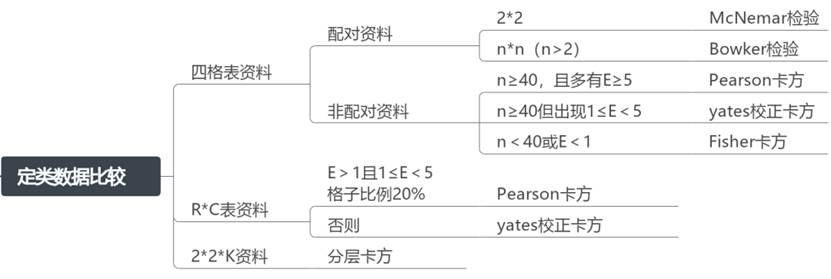
例如研究不同性别是否吸烟之间是否有差异;可以将定类数据资料分为四格表资料、R*C资料、2*2*K资料三类。
(1)四格表资料
只有两行两列。又可以分为配对资料和非配对资料两种。
配对资料:例如分别使用方法A和方法B对同一批样本检验是否患有某传染病。
- 当为2*2配对设计时,采用McNemar检验;
- 当为n*n配对设计时,采用Bowker检验。
非配对资料:
- 当总样本量n≥40,且期望频率E≥5时,使用Pearson卡方;
- 当n≥40但其中一个格子出现1≤E<5时,使用yates校正卡方;
- 当n<40或者E<1时,使用Fisher卡方进行分析(这一过程SPSSAU卡方检验将自动选择)。
(2)R*C表资料
当行和列中任意一个大于等于2时,称为R*C表资料。
当E全部>1 且 1 ≤E<5格子的比例小于20% 则使用Pearson卡方;
否则使用yates校正卡方(SPSSAU卡方检验将自动选择)。
(3)2*2*K资料
卡方检验研究X和Y的差异,X和Y均是类别数据,当前需要进一步考虑另一个干扰因素分层项时;比如是否吸烟(X)与是否得肺癌(Y)的关系时,将性别纳入考虑范畴此时应该使用分层卡方进行分析。
补充:除此之外,常用的卡方检验还有卡方拟合优度检验,用于检验观测数据的分类频数分布是否与某个理论分布一致。例如某公司推出5种口味饮料,理论预期各口味偏好比例为1:1:1:1:1,实际调查200名消费者后统计各口味选择频数。
点击下方链接可以跳转至SPSSAU方法帮助手册:
- 交叉(卡方)
- 卡方检验
- 配对卡方
- 分层卡方
- 卡方拟合优度
二、相关回归分析
研究数据之间的相关性,主要可以使用Pearson相关系数和Spearman相关系数。
1、相关分析
相关分析是用来衡量两个或多个变量之间线性关系强度和方向的统计方法。常用有三类相关系数:Pearson 相关系数、 Spearman 相关系数、Kendall 相关系数,可依据变量数据类型及正态分布条件进行选择,如下图: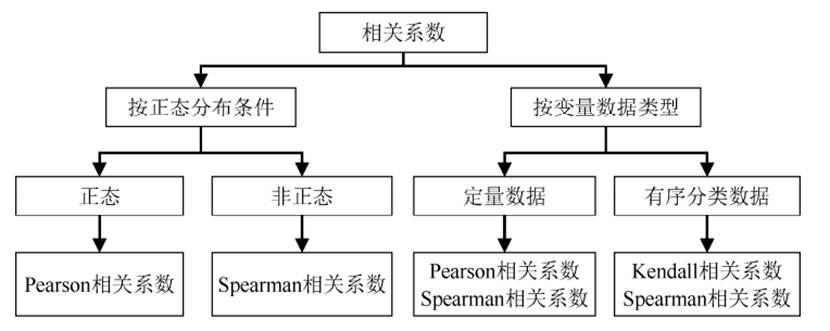
- Pearson 相关系数:适用于变量均为定量数据的情况,要求数据服从正态分布,并且无明显异常值,多数情况下结果较稳健。
- Spearman 相关系数:适用于定量数据或等级(有序分类)数据,用两个变量的秩次大小做相关分析。其对数据分布没有明确要求,属于非参数方法。在进行相关分析时,当Pearson相关系数不满足正态分布条件时,Spearman相关系数可用作Pearson相关系数的非参数替代。
- Kendall 相关系数:同样是用秩次进行相关分析的,也属于非参数方法,适用于等级(有序分类)数据,常用于一致性研究。
SPSSAU【通用方法】模块“相关”分析可选择三类相关系数进行分析:
点击下方链接可以跳转至SPSSAU方法帮助手册:
相关分析
2、回归分析
回归分析用于研究自变量X对因变量Y的影响,按照因变量数据类型的不同,常用的回归方法有以下几类:
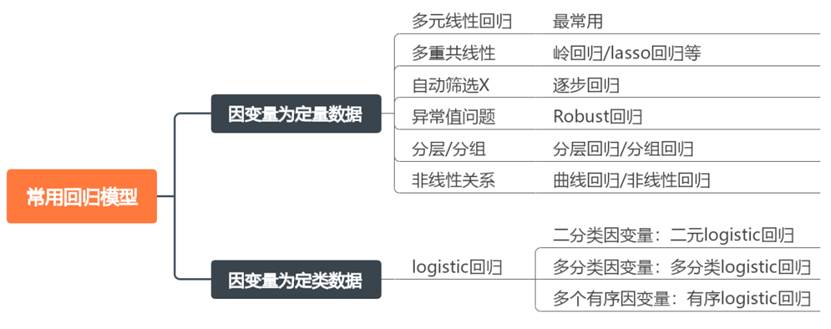
(1)因变量为定量数据
- 多元线性回归:最常用的回归模型,有很多需要满足的前提条件(如线性、残差独立性、残差正态性、残差方差齐、无多重共线性)。
- 岭回归、lasso回归:适用于自变量间出现多重共线性问题(VIF值大于10)。
- 逐步回归:如果X个数非常多,想要模型自动找出对Y有影响的X,可以使用逐步回归。
- Robust回归:适用于解决异常数据(或极端数据)时的回归估计。
- 分层/分组回归:如果要对X进行分层或者分组,则使用对应的分层回归或者分组回归。
- 非线性关系:若研究的数据不满足线性关系,则选择对应的非线性回归模型,如SPSSAU中提供的曲线回归和非线性回归方法中提供60多种非线性关系模型。
(2)因变量为定类数据
- 二元logistic回归:Y为二分类变量使用,如“是否患病”。
- 多分类logistic回归:Y为多分类变量使用,如“华为、小米、苹果”。
- 有序logistic回归:Y为有序多分类变量使用,如“无效、好转、痊愈”。
点击下方链接可以跳转至SPSSAU方法帮助手册:
- 线性回归
- 二元logistic回归
- 条件logistic回归
- 多分类logistic回归
- 有序logistic回归
三、生存分析
在医学研究中,生存分析是一种评估个体或群体在特定时间内经历某一事件(如死亡、疾病复发等)的概率的方法。Kaplan-Meier法和Cox回归是生存分析中两种常用的统计方法。
(1)Kaplan-Meier法
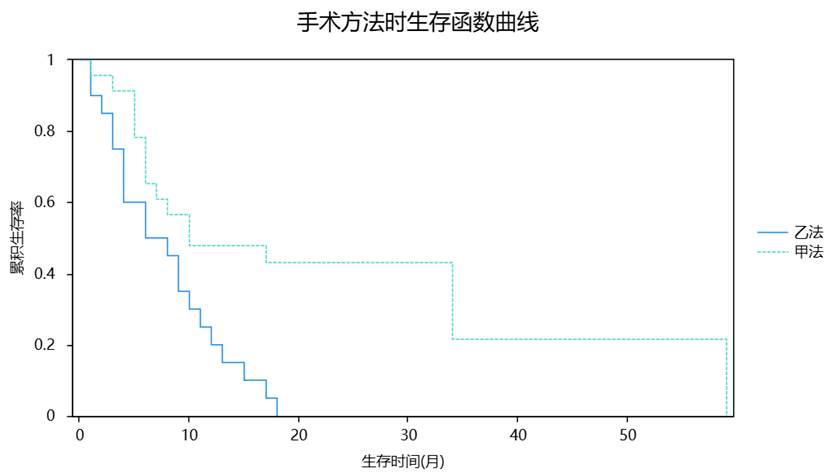
K-M法也叫乘积极限法(有时也称单因素生存分析),是生存分析中最常用的非参数方法,主要用于估计患者生存率和绘制生存曲线。由于生存时间数据的特殊性,因而此模型的因变量会涉及两项,分别是生存时间和生存状态;并且生存状态只能使用数字1或者数字0表示(1表示死亡,0表示生存)。
SPSSAU进行Kaplan-Meier法得到生存函数曲线如下:
(2)Cox回归
Cox回归是生存分析中最重要的半参数方法,又称“比例风险回归模型”。该模型以生存结局和生存时间为因变量,可同时分析多个因素对生存时间的影响,且不要求特定的数据分布类型。
Kaplan-Meier法和Cox回归分析的对比如下:
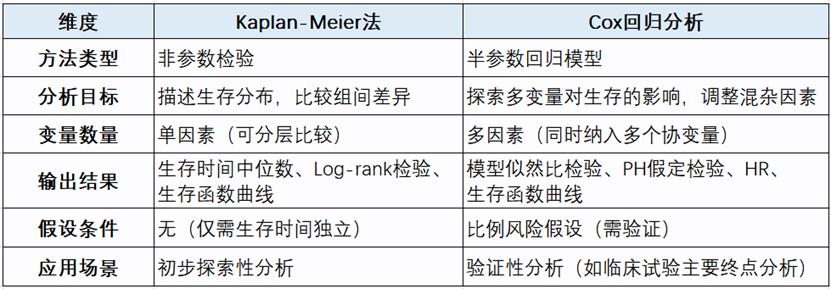
点击下方链接可以跳转至SPSSAU方法帮助手册:
- Kaplan-Meier法
- Cox回归
四、一致性检验
在医学研究中,一致性检验用于评估两种测量方法、不同观察者或同一观察者重复测量的结果是否可靠一致。典型场景包括:
- 两种诊断方法(如金标准与新方法)的结果一致性评价;
- 不同医生对同一组患者的诊断或评分一致性;
- 同一仪器或观察者重复测量的稳定性验证。
常见的一致性检验方法包括Kappa一致性检验、Kendall协调系数、ICC组内相关系数、组内评分者信度rwg、Bland-Altman图等。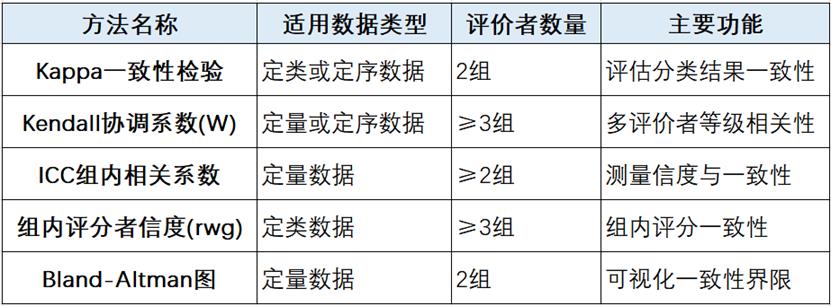 点击下方链接可以跳转至SPSSAU方法帮助手册:
点击下方链接可以跳转至SPSSAU方法帮助手册:
- Kappa一致性检验
- Kendall协调系数(W)
- ICC组内相关系数
- 组内评分者信度rwg
- Bland-Altman图
以上就是今天的全部内容,主要讲了医学统计学比较常用的差异性分析、相关回归分析、生存分析及一致性检验。还想看什么其他内容,请留言告诉我哦~
参考文献:
[1]孙振球,徐勇勇.医学统计学.第4版[M].人民卫生出版社,2014
[2]周俊,马世澎. SPSSAU科研数据分析方法与应用.第1版[M]. 电子工业出版社,2024.