【GPT入门】第51课 将hf模型转换为GGUF
【GPT入门】第51课 将hf模型转换为GGUF
- 1. 概述
- 1.1 llama.cpp项目进行格式转换
- 1.2 执行转换
- 1.3 转换后的模型
- 2. ollama运行 GGUF
- 2.1 安装ollama
- 2.2 启动ollama
- 2.3 创建ModelFile
- 2.4 创建自定义模型
- 2.5 启动模型
1. 概述
下文把Lora微调后的模型转为gguf格式,目的是可以让模型在ollama支持的机器上运行,用到llamacpp项目做格式转换,并使用ollama运行模型测试
1.1 llama.cpp项目进行格式转换
git clone https://github.com/ggerganov/llama.cpp.gitpip install -r llama.cpp/requirements.txt
1.2 执行转换
python llama.cpp/convert_hf_to_gguf.py /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct-merged-rzb --outtype f16 --verbose --outfile /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct-merged-rzb-gguf.gguf
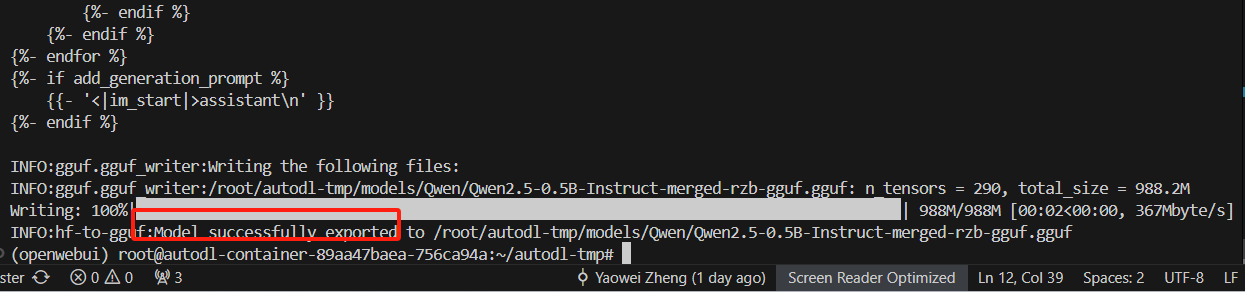
1.3 转换后的模型
2. ollama运行 GGUF
2.1 安装ollama
curl -fsSL https://ollama.com/install.sh | sh
2.2 启动ollama
ollama serve
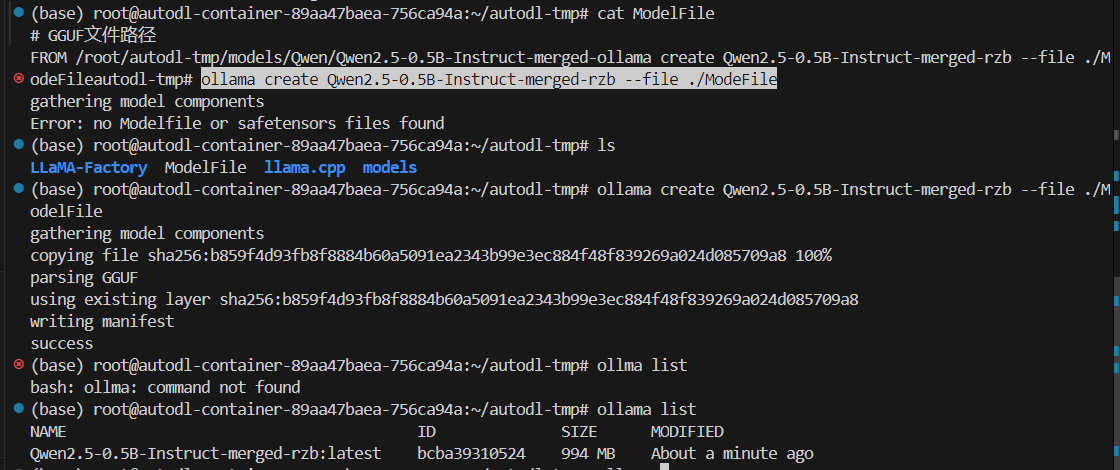
2.3 创建ModelFile
cat ModelFile
# GGUF文件路径
FROM /root/autodl-tmp/models/Qwen/Qwen2.5-0.5B-Instruct-merged-ollama create Qwen2.5-0.5B-Instruct-merged-rzb --file ./ModelFile
2.4 创建自定义模型
ollama create Qwen2.5-0.5B-Instruct-merged-rzb --file ./ModeFile
2.5 启动模型
(base) root@autodl-container-89aa47baea-756ca94a:~/autodl-tmp# ollama list
NAME ID SIZE MODIFIED
Qwen2.5-0.5B-Instruct-merged-rzb:latest bcba39310524 994 MB About a minute ago
(base) root@autodl-container-89aa47baea-756ca94a:~/autodl-tmp# ollama run Qwen2.5-0.5B-Instruct-merged-rzb:latest