Day13_【DataFrame数据组合join合并】【案例】
join默认左连接
演示案例
1.加载数据
stocks_2016 = pd.read_csv(r"C:\Users\24251\Desktop\employment\02-数据处理和统计分析\数据集\stocks_2016.csv")
stocks_2017 = pd.read_csv(r"C:\Users\24251\Desktop\employment\02-数据处理和统计分析\数据集\stocks_2017.csv")
stocks_2018 = pd.read_csv(r"C:\Users\24251\Desktop\employment\02-数据处理和统计分析\数据集\stocks_2018.csv")
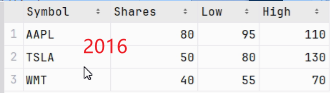
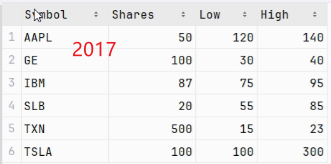
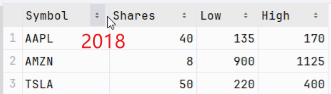
可以看到2016与2017表的行数不同,这就关乎到下面连接方法的最佳选择。
2.(不可取,仅演示)依据两个DataFrame(stocks_2016与stocks_2017)的行索引(0,1,2...)
如果合并的两个数据有相同的列名,需要通过lsuffix,和rsuffix,指定合并后的列名的后缀
df1 = stocks_2016.join(stocks_2017,lsuffix="_2016",rsuffix="_2017"
)
print(df1.head())
不难发现合并的结果是不正确的。
2.1使用 外连接(Outer Join)的含义:保留两个 DataFrame 中所有行索引的并集
关键字:how="outer"
df2 = stocks_2016.join(stocks_2017,lsuffix="_2016",rsuffix="_2017",how="outer"
)
print(df2.head())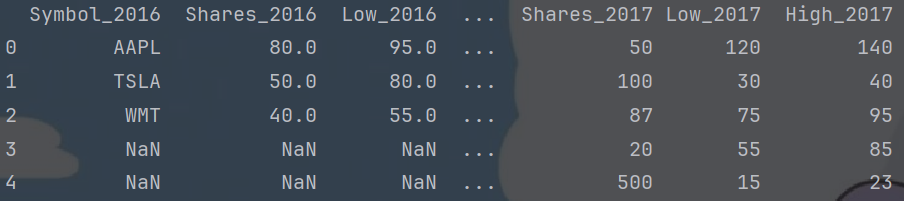
不难发现合并的结果也是不可取的。
3.(可取)将两个DataFrame的Symbol设置为行索引,再次join数据
df3 = stocks_2016.set_index("Symbol").join(stocks_2017.set_index("Symbol"),lsuffix="_2016",rsuffix="_2017"
)
print(df3.head())
可见结果是正确的
4.(可取)将一个DataFrame的Symbol列设置为行索引,与另一个DataFrame的Symbol列进行join
df4 = stocks_2016.join(stocks_2017.set_index('Symbol'),lsuffix='_2016',rsuffix='_2018',on='Symbol'
)
print(df4.head())
可见结果是正确的