LLMs之RL之GSPO:《Group Sequence Policy Optimization》翻译与解读
LLMs之RL之GSPO:《Group Sequence Policy Optimization》翻译与解读
导读:本文提出了Group Sequence Policy Optimization (GSPO)算法,旨在解决大型语言模型RL训练中GRPO算法存在的不稳定性和低效性问题。GSPO通过采用序列级别的重要性比率、组优势估计和长度归一化等方法,实现了更稳定、高效的训练,并特别适用于MoE模型的训练,同时还有潜力简化RL基础设施。实验结果表明,GSPO在训练稳定性、效率和性能方面均优于GRPO,为大型语言模型的持续发展奠定了基础。
>> 背景痛点:
● 大型语言模型RL训练的不稳定性:现有RL算法(如GRPO)在训练大型语言模型时存在严重的稳定性问题,容易导致模型崩溃,阻碍模型能力的提升.
● GRPO算法的局限性:GRPO算法在设计上存在对重要性采样权重的不当应用和失效,引入高方差的训练噪声,并被裁剪机制放大,最终导致模型崩溃.
● MoE模型训练的挑战:MoE模型的稀疏激活特性给RL训练带来独特的稳定性挑战,专家激活的波动性会阻碍RL训练的正常收敛.
>> 具体的解决方案:
● 提出GSPO算法:论文提出了Group Sequence Policy Optimization (GSPO)算法,用于训练大型语言模型.
● 序列级别的重要性比率:GSPO基于序列可能性定义重要性比率,并执行序列级别的裁剪、奖励和优化.
● 序列级别的奖励和优化对齐:GSPO计算归一化的奖励作为查询的多个响应的优势,确保序列级别奖励和优化之间的对齐.
>> 核心思路步骤:
● 序列级别重要性权重:GSPO使用序列级别的重要性权重 πθ(y|x) / πθold(y|x),反映了从旧策略 πθold(·|x) 采样的响应 y 与新策略 πθ(·|x) 的偏差程度.
● 优势估计:采用基于组的优势估计,计算公式为 Ab_i = (r(x, yi) - mean({r(x, yi)}_i=1^G)) / std({r(x, yi)}_i=1^G).
● 长度归一化:在计算重要性比率时,采用长度归一化,以减少方差并控制重要性比率在统一的数值范围内.
● GSPO-token变体:为了实现更细粒度的优势调整,论文还提出了GSPO-token,允许token级别的优势定制.
>> 优势:
● 训练稳定性:GSPO在训练稳定性方面优于GRPO,能够解决MoE模型RL训练中的稳定性挑战.
● 训练效率:GSPO比GRPO具有更高的训练效率,在相同的训练计算量和查询消耗下,能够实现更好的训练准确性和基准性能.
● 简化RL基础设施:GSPO有潜力简化RL基础设施,例如,可以避免使用训练引擎重新计算旧策略下的可能性.
● 解决了MoE模型专家激活波动问题:GSPO从根本上解决了MoE模型中的专家激活波动问题,无需复杂的变通方法,如Routing Replay.
>> 结论和观点:
● Token级别的重要性权重问题:GRPO的token级别的重要性权重存在问题,因为它是基于来自每个下一个token分布的单个样本,不能执行预期的分布校正,反而引入高方差噪声.
● 优化目标与奖励单位对齐:优化目标的单位应与奖励单位匹配。由于奖励是授予整个序列的,因此在token级别应用off-policy校正可能存在问题.
● GSPO对MoE模型的好处:GSPO仅关注序列可能性,对单个token可能性不敏感,因此能够解决MoE模型中的专家激活波动问题,简化训练过程.
● GSPO对RL基础设施的好处:GSPO仅使用序列级别的可能性进行优化,对精度差异的容忍度更高,因此可以直接使用推理引擎返回的可能性进行优化,避免使用训练引擎重新计算.
目录
《Group Sequence Policy Optimization》翻译与解读
Abstract
1、Introduction
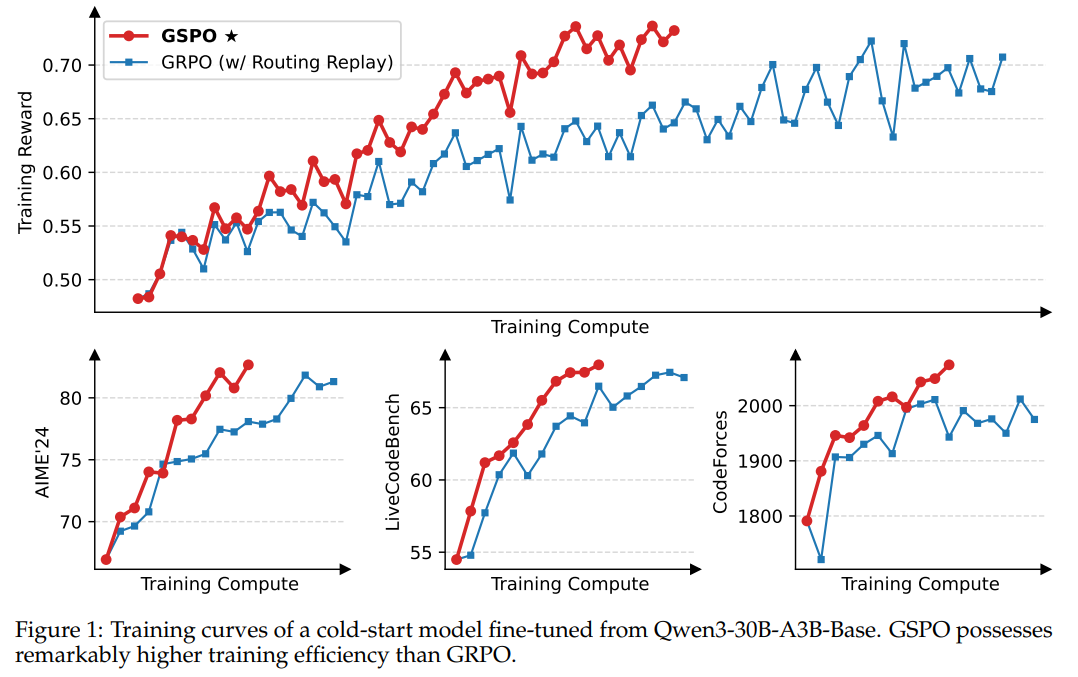
Figure 1: Training curves of a cold-start model fine-tuned from Qwen3-30B-A3B-Base. GSPO possesses remarkably higher training efficiency than GRPO.图1:Qwen3-30B-A3B-Base微调冷启动模型的训练曲线。GSPO的训练效率显著高于GRPO。
Conclusion
《Group Sequence Policy Optimization》翻译与解读
| 地址 | 地址:[2507.18071] Group Sequence Policy Optimization |
| 时间 | 2025年7月24日 最新2025年7月28日 |
| 作者 | Qwen Team, Alibaba Inc. |
Abstract
| This paper introduces Group Sequence Policy Optimization (GSPO), our stable, efficient, and performant reinforcement learning algorithm for training large language models. Unlike previous algorithms that adopt token-level importance ratios, GSPO defines the importance ratio based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. We demonstrate that GSPO achieves superior training efficiency and performance compared to the GRPO algorithm, notably stabilizes Mixture-of-Experts (MoE) RL training, and has the potential for simplifying the design of RL infrastructure. These merits of GSPO have contributed to the remarkable improvements in the latest Qwen3 models. | 本文介绍了组序列策略优化(GSPO),这是我们在训练大型语言模型时所采用的一种稳定、高效且性能出色的强化学习算法。与以往采用标记重要性比率的算法不同,GSPO 基于序列可能性定义重要性比率,并执行序列级裁剪、奖励和优化。我们证明,与 GRPO 算法相比,GSPO 在训练效率和性能方面表现更优,尤其能稳定混合专家(MoE)强化学习训练,并有可能简化强化学习基础设施的设计。GSPO 的这些优点为最新的 Qwen3 模型带来了显著的改进。 |
1、Introduction
| Reinforcement learning (RL) has emerged as a pivotal paradigm for scaling language models (OpenAI, 2024; DeepSeek-AI, 2025; Qwen, 2025b;a). Through large-scale RL, language models develop the capa-bility to tackle sophisticated problems, such as competition-level mathematics and programming, by undertaking deeper and longer reasoning processes. To successfully scale RL with greater computational investment, the foremost prerequisite is maintaining stable and robust training dynamics. However, current state-of-the-art RL algorithms, exemplified by GRPO (Shao et al., 2024), exhibit severe stability issues when training gigantic language models, often resulting in catastrophic and irreversible model collapse (Qwen, 2025a; MiniMax, 2025). This instability hinders efforts to push the capability boundaries of language models through continued RL training. In this paper, we identify that the instability of GRPO stems from the fundamental misapplication and invalidation of importance sampling weights in its algorithmic design. This introduces high-variance training noise that progressively accumulates with increased response length and is further amplified by the clipping mechanism, ultimately precipitating model collapse. To address these core limitations, we propose Group Sequence Policy Optimization (GSPO), a new RL algorithm for training large language models. The key innovation of GSPO lies in its theoretically grounded definition of importance ratio based on sequence likelihood (Zheng et al., 2023), aligning with the basic principle of importance sampling. Additionally, GSPO computes the normalized rewards as the advantages of multiple responses to a query, ensuring the alignment between sequence-level rewarding and optimization. Our empirical evaluation demonstrates the significant superiority of GSPO over GRPO in training stability, efficiency, and performance. Critically, GSPO has inherently resolved the stability challenges in the RL training of large Mixture-of-Experts (MoE) models, eliminating the need for complex stabilization strategies, and shows the potential for simplifying RL infrastructure. These merits of GSPO ultimately contributed to the exceptional performance improvements in the latest Qwen3 models. We envision GSPO as a robust and scalable algorithmic foundation that will enable the continued advancement of large-scale RL training with language models. | 强化学习(RL)已成为扩展语言模型能力的关键范式(OpenAI,2024;DeepSeek-AI,2025;Qwen,2025b;a)。通过大规模强化学习,语言模型能够通过更深入、更长时间的推理过程来解决复杂问题,例如竞赛级别的数学和编程。 为了在更大的计算投入下成功扩展强化学习,首要前提是保持稳定且稳健的训练动态。然而,当前最先进的强化学习算法,以 GRPO(Shao 等人,2024)为例,在训练大型语言模型时表现出严重的稳定性问题,常常导致灾难性的且不可逆转的模型崩溃(Qwen,2025a;MiniMax,2025)。这种不稳定性阻碍了通过持续强化学习训练来拓展语言模型能力的努力。 在本文中,我们发现 GRPO 的不稳定性源于其算法设计中对重要性采样权重的根本误用和失效。这引入了高方差的训练噪声,随着响应长度的增加而逐渐累积,并且由于裁剪机制而进一步放大,最终导致模型崩溃。 为了解决这些核心限制,我们提出了组序列策略优化(GSPO),这是一种用于训练大型语言模型的新强化学习算法。GSPO 的关键创新在于其基于序列似然(Zheng 等人,2023 年)的理论上定义的重要性比率,这与重要性采样的基本原理相一致。此外,GSPO 将归一化奖励计算为对查询的多个响应的优势,确保了序列级奖励与优化的一致性。 我们的实证评估表明,GSPO 在训练稳定性、效率和性能方面明显优于 GRPO。关键的是,GSPO 从根本上解决了大型专家混合(MoE)模型强化学习训练中的稳定性挑战,无需复杂的稳定策略,并显示出简化强化学习基础设施的潜力。GSPO 的这些优点最终促成了最新 Qwen3 模型的卓越性能提升。我们期望 GSPO 成为一个强大且可扩展的算法基础,从而推动语言模型的大规模强化学习训练不断取得进步。 |
Figure 1: Training curves of a cold-start model fine-tuned from Qwen3-30B-A3B-Base. GSPO possesses remarkably higher training efficiency than GRPO.图1:Qwen3-30B-A3B-Base微调冷启动模型的训练曲线。GSPO的训练效率显著高于GRPO。
Conclusion
| We propose Group Sequence Policy Optimization (GSPO), a new reinforcement learning algorithm for training large language models. Following the basic principle of importance sampling, GSPO defines importance ratios based on sequence likelihood and performs sequence-level clipping, rewarding, and optimization. GSPO demonstrates notably superior training stability, efficiency, and performance compared to GRPO and exhibits particular efficacy for the large-scale RL training of MoE models, laying the foundation for the exceptional improvements in the latest Qwen3 models. With GSPO as a scalable algorithmic cornerstone, we will continue to scale RL and look forward to the resulting fundamental advances in intelligence. | 我们提出了组序列策略优化(GSPO),这是一种用于训练大型语言模型的新强化学习算法。遵循重要性采样的基本原理,GSPO 基于序列似然性定义重要性比率,并执行序列级裁剪、奖励和优化。与 GRPO 相比,GSPO 显示出显著更优的训练稳定性、效率和性能,并且对于大规模 RL 训练的 MoE 模型表现出特别的效能,为最新 Qwen3 模型的卓越改进奠定了基础。以 GSPO 作为可扩展的算法基石,我们将继续扩展 RL,并期待由此带来的智能领域的根本性进步。 |