高校数字化转型实战:破解数据孤岛、构建智能指标体系与AI落地路径
在"双一流"建设和教育现代化2035背景下,中国高校正面临数字化转型的关键时期。然而现实情况却是:
- 数据沉睡严重:据教育部2022年统计,高校平均每日产生2.3TB数据,但利用率不足10%
- 管理决策滞后:超过70%的高校仍采用经验决策模式,学科评估常陷入"拍脑袋"困境
- 技术应用肤浅:虽然85%的高校已部署大数据平台,但实际应用多停留在"报表电子化"层面
本文将结合《指标+AI数智应用白皮书》和实际案例,深度解析高校数字化转型的实战路径。
一、高校数据治理三大痛点与破解之道
1.1 数据孤岛:从"聚而不通"到"全域流通"
典型案例:某985高校教务与科研系统独立运行,导致教师工作量评估出现"教学科研两张皮"现象。
技术根源:
- 缺乏统一数据标准(如教师ID在不同系统中编码规则不一致)
- 数据血缘关系不清晰,无法追踪数据流转过程
解决方案:
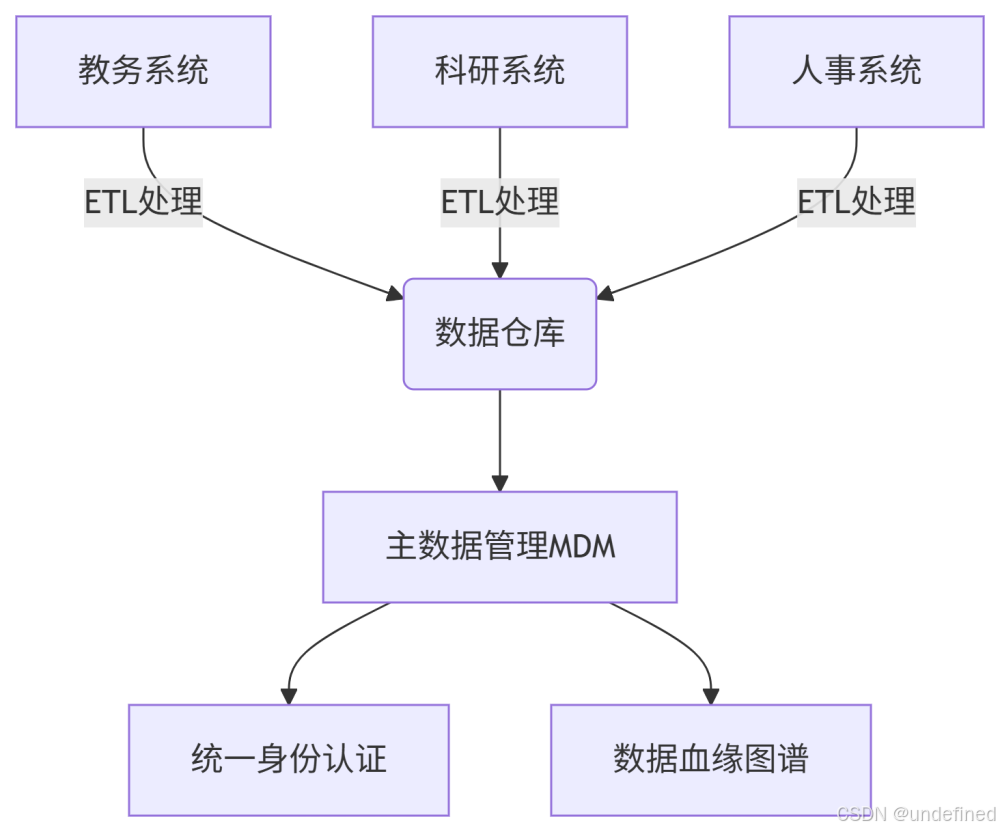
关键技术:
- 主数据管理(MDM):构建"人、财、物"核心实体的唯一标识体系
- 数据血缘追踪:使用Apache Atlas等工具实现元数据管理
- 数据中台建设:基于Hadoop生态构建统一数据服务平台
1.2 指标体系:从模糊评价到量化决策
常见误区:
- 过度依赖"论文数"、"项目经费"等结果性指标
- 缺乏过程性监测指标(如"师均指导学生质量")
三级指标体系构建方法:
| 层级 | 受众 | 示例指标 | 数据来源 |
| 战略层 | 校领导 | 学科国际影响力指数 | QS排名、高被引学者数据 |
| 管理层 | 职能部门 | 大型设备使用效率 | 物联网传感器、预约系统 |
| 业务层 | 院系 | 课程满意度预警指标 | 评教系统、考勤数据 |
动态权重算法示例:
def calculate_composite_score(indicators, weights):
# 指标归一化处理
normalized = [ (i-min_val)/(max_val-min_val) for i in indicators ]
# 动态权重调整
adjusted_weights = adjust_weights_based_on_policy(weights)
return sum(n*w for n,w in zip(normalized, adjusted_weights))
def adjust_weights_based_on_policy(original_weights):
# 根据"破五唯"等政策动态调整权重
if policy_change_detected():
return [w*0.7 if 'paper' in tag else w for w,tag in original_weights]
return original_weights
1.3 技术悬浮:AI落地的务实路径
失败案例:某高校直接部署GPT-3分析学生行为,因数据未清洗导致分析结果完全失真。
正确实施路径:
- 数据质量先行:完整性>95%,准确性>90%再部署AI
- 场景驱动:从"智能问答"等具体需求切入
- 渐进式推进:先规则引擎,后机器学习
二、技术落地:从数据治理到AI赋能
2.1 数据治理四步法实战
步骤1:多源采集
- 结构化数据:MySQL/Oracle数据库
- 非结构化数据:评教文本、学术论文PDF
- 时序数据:教室IoT传感器数据
步骤2:标准化清洗
UPDATE department
SET name = CASE
WHEN name LIKE '%计算机系%' THEN '计算机学院'
WHEN name LIKE '%计科%' THEN '计算机学院'
ELSE name
END;
步骤3:资产化管理
- 将数据包装为RESTful API
- 使用Swagger进行API文档管理
步骤4:质量监控
- 使用Great Expectations等工具定义数据质量规则
- 实时监控数据异常
2.2 智能问数系统架构
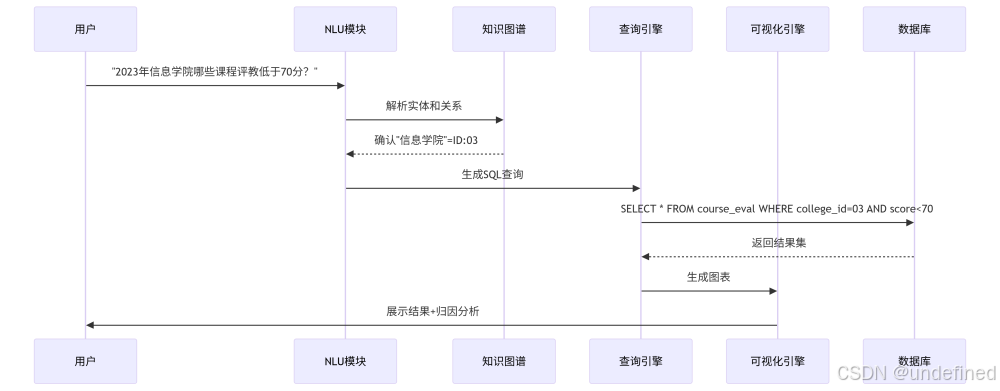
关键技术栈:
- 知识图谱:Neo4j + Apache Jena
- NLU:BERT + 领域词典
- 查询转换:SQLGlot库
- 可视化:Apache ECharts
2.3 生源预测模型构建
特征工程:
from sklearn.pipeline import Pipeline
from sklearn.impute import SimpleImputer
from sklearn.preprocessing import StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
numeric_features = ['past_admission', 'gdp_per_capita']
numeric_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='median')),
('scaler', StandardScaler())])
categorical_features = ['province', 'policy_zone']
categorical_transformer = Pipeline(steps=[
('imputer', SimpleImputer(strategy='constant', fill_value='missing')),
('onehot', OneHotEncoder(handle_unknown='ignore'))])
preprocessor = ColumnTransformer(
transformers=[
('num', numeric_transformer, numeric_features),
('cat', categorical_transformer, categorical_features)])
模型训练:
from sklearn.ensemble import RandomForestRegressor
from sklearn.model_selection import train_test_split
rf = Pipeline(steps=[('preprocessor', preprocessor),
('classifier', RandomForestRegressor(n_estimators=100))])
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
rf.fit(X_train, y_train)
三、未来展望:数据驱动的高教新生态
3.1 个性化教育实践
- 学习路径推荐:基于知识图谱的个性化课程推荐
- 早期预警系统:使用LSTM预测学生学业风险
3.2 科研范式革新
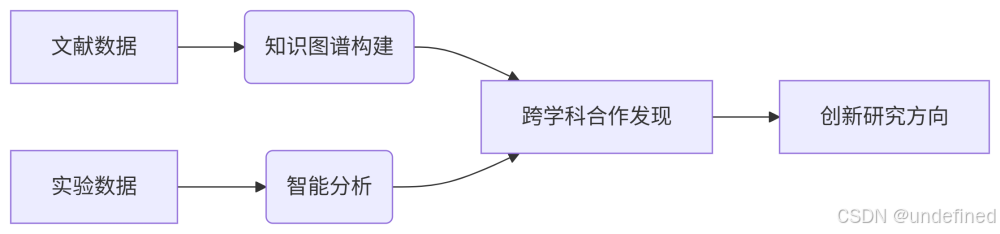
3.3 治理现代化
- 数字孪生校园:整合物理空间与数字空间
- 风险预警模型:
def early_warning(finance_data, hr_data):
risk_score = 0.4*finance_stress(finance_data) + 0.6*turnover_risk(hr_data)
return risk_score > threshold