常见的对比学习的损失函数
在多模态任务中,为了让模型能更好地关联视觉信息与语言信息,需要衡量语言视觉特征的对齐程度,以下是一些常见的指标和损失函数:
常见损失函数:
对比损失(Contrastive Loss)
- 原理:对比损失旨在最大化正样本对(匹配的语言 - 视觉对)之间的相似性,同时最小化负样本对(不匹配的语言 - 视觉对)之间的相似性。通常使用余弦相似度等方式来衡量特征之间的相似性。
- 公式:
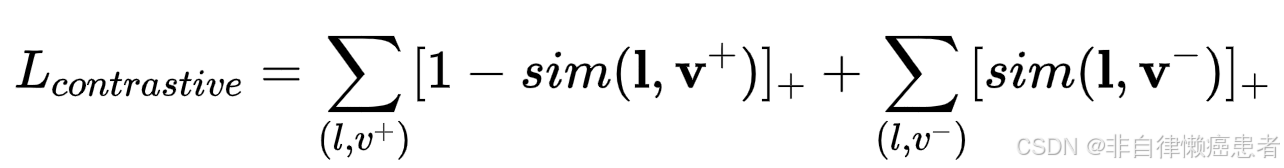
三元组损失(Triplet Loss)
- 原理:三元组由一个锚点(可以是语言或视觉样本)、一个正样本(与锚点匹配的另一种模态样本)和一个负样本(与锚点不匹配的另一种模态样本)组成。其目标是让锚点与正样本的距离小于锚点与负样本的距离,并且差距要大于一个预设的边界值(margin)。
- 公式:
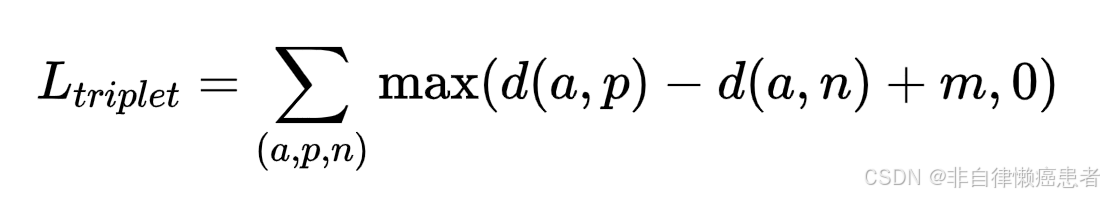
其中,a 是锚点,p 是正样本,n 是负样本,d(\cdot) 是距离函数(如欧氏距离),m 是边界值。
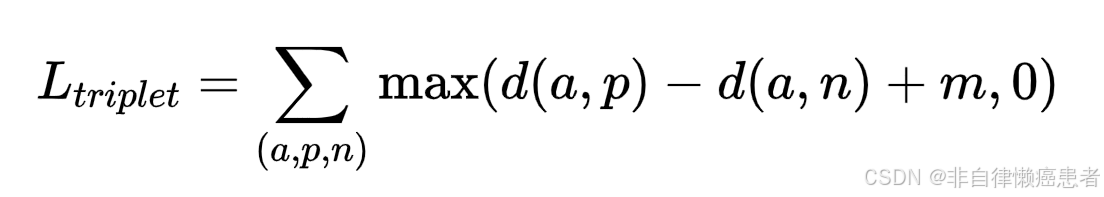
InfoNCE损失(Noise - Contrastive Estimation Loss)
- 原理:InfoNCE损失是对比学习中常用的损失函数,它通过在多个候选样本中区分出正样本,来最大化正样本对之间的互信息。在语言 - 视觉对齐中,它能有效引导模型从一组候选视觉特征中识别出与给定语言特征匹配的特征。
- 公式:
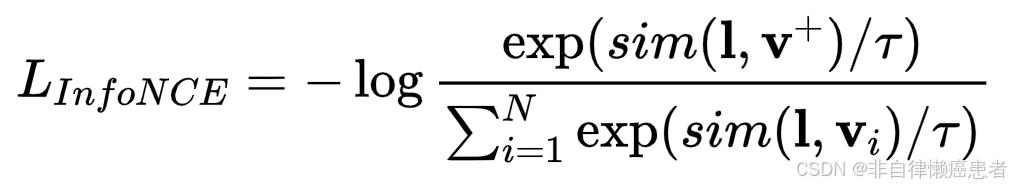
其中,l\mathbf{l}l 是语言特征向量,v+\mathbf{v}^+v+ 是正样本视觉特征向量,vi\mathbf{v}_ivi 表示包括正样本和负样本在内的所有候选视觉特征向量,N 是候选样本总数,τ\tauτ 是温度超参数,用于调整相似度得分的分布。