网络数据包
LwIP 网络数据包(pbuf 与 ethernetif 驱动)详解与实践
本文系统梳理 LwIP 的 pbuf 数据包与以太网端口驱动接口 ethernetif(以 STM32 HAL 代码为例),结合内存管理(memp/mem)说明 pbuf 类型、内存来源、关键 API、典型数据流、零拷贝思路,以及常见问题与调优建议,提升可读性与可操作性。
1. 为什么 LwIP“模糊分层”(性能取舍)
- 标准 TCP/IP 栈严格分层,层间通过清晰 API 交互,通常导致多次内存拷贝与多线程切换,嵌入式环境成本高。
- LwIP 在“栈内部”允许跨层可见(例如 TCP 层直接读取 IP 首部信息),尽量复用同一块内存,降低拷贝与调度开销。
- 对“外部应用 API”仍保持清晰接口(RAW、NETCONN、Socket),方便移植与开发。
结论:LwIP 用 pbuf 将数据包在各层共享,减少拷贝;驱动层 ethernetif 负责将硬件收/发的数据搬运到/从 pbuf。
2. pbuf 概览:结构、类型、内存来源

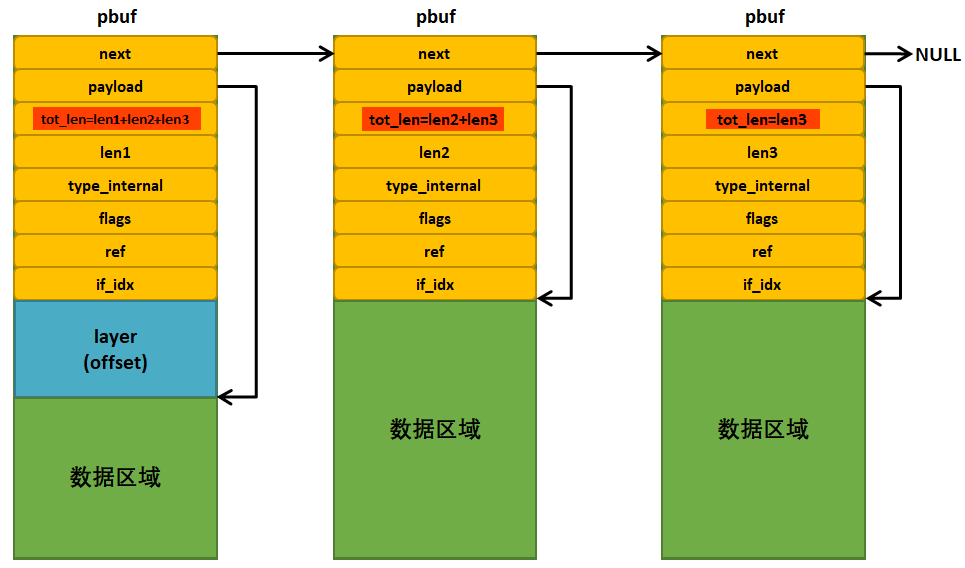
pbuf 是协议栈的数据包描述符,支持单个或链式。核心字段(简化):
- next:下一段 pbuf(链表)
- payload:指向有效数据的起始地址
- len:本 pbuf 段的有效负载长度
- tot_len:从本段开始到链尾的总长度
- ref:引用计数(>1 表示被多处引用)
- type_internal/flags:类型与标志位(含内存来源)
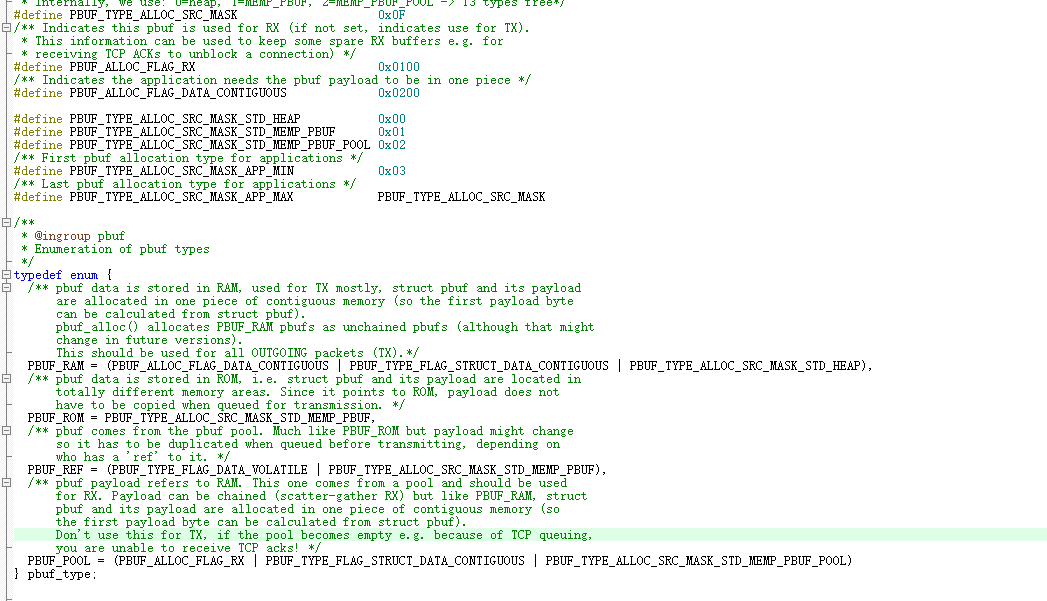
pbuf 的类型(按用途与内存来源):
- PBUF_RAM:在堆(mem_malloc)上分配一块连续内存,struct pbuf 与 payload 同块内存。常用于发送(TX)。
- PBUF_POOL:从“pbuf 池”(MEMP_PBUF_POOL)分配,struct pbuf 与 payload 同块内存,固定块大小。常用于接收(RX)。
- PBUF_ROM:仅分配 struct pbuf(MEMP_PBUF),payload 指向只读常量区(不拷贝数据)。
- PBUF_REF:仅分配 struct pbuf(MEMP_PBUF),payload 指向外部 RAM(数据可变,通常需要复制或谨慎管理生命周期)。
内存池对应关系: - MEMP_PBUF:仅存放 struct pbuf(供 PBUF_ROM/PBUF_REF 等使用)。
- MEMP_PBUF_POOL:存放“包含头部+数据区”的 pbuf(即 PBUF_POOL 类型)。
关键内存配置:
- PBUF_POOL_BUFSIZE:每个 PBUF_POOL 块大小,建议 ≥ MTU + 链路层头(以太网常用 1514/1520;1460+40+14=1514)。
- PBUF_POOL_SIZE:PBUF_POOL 块数量。
- MEMP_NUM_PBUF:struct pbuf 池数量(建议 ≥ PBUF_POOL_SIZE 再加裕量)。

公式参考(以太网 TCP): - PBUF_POOL_BUFSIZE ≈ TCP_MSS + 40(IP+TCP) + PBUF_LINK_HLEN(14) + 可能的封装预留
- 536 MSS → 590(536+40+14),值得注意的是TCP头部不一定是固定20字节,最长可到60字节
- 1460 MSS → 1514(1460+40+14)
- 实践中常对齐至 1520 或 1536,以满足 DMA/Cache 对齐与 VLAN 头(+4B)的需要。
3. pbuf 分配的“层级”与预留头部
pbuf_alloc(layer, length, type) 的 layer 决定在 payload 前预留的协议首部空间:
- PBUF_TRANSPORT:预留 以太网+IP(20/40)+传输层(20) 头
- PBUF_IP:预留 以太网+IP 头
- PBUF_LINK:仅预留 以太网头
- PBUF_RAW_TX:预留链路层封装头(自定义封装)
- PBUF_RAW:不预留(驱动接收用)
配合 pbuf_header()/pbuf_add_header() 可以前后移动 payload 指针,便于各层“就地”填充/剥离协议头,避免拷贝。
4. pbuf 关键 API 与行为
- 分配与释放
- pbuf_alloc(layer, len, type):分配 pbuf/链
- pbuf_alloc_reference(payload,len,type):仅分配 struct pbuf,引用外部数据
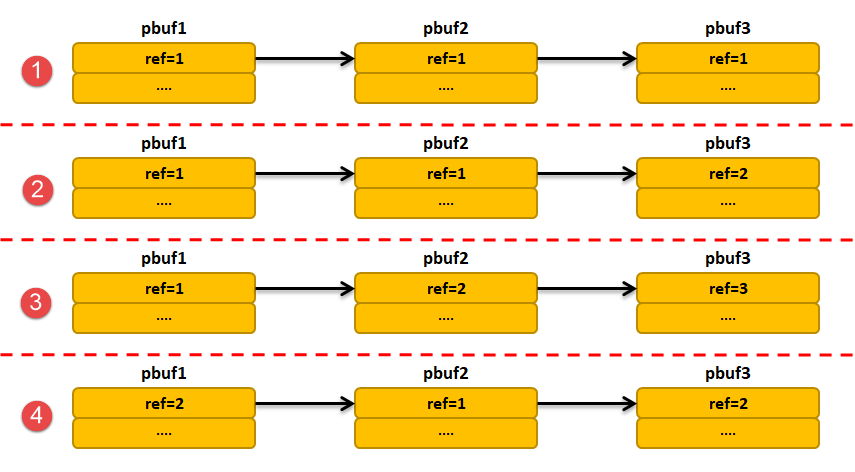
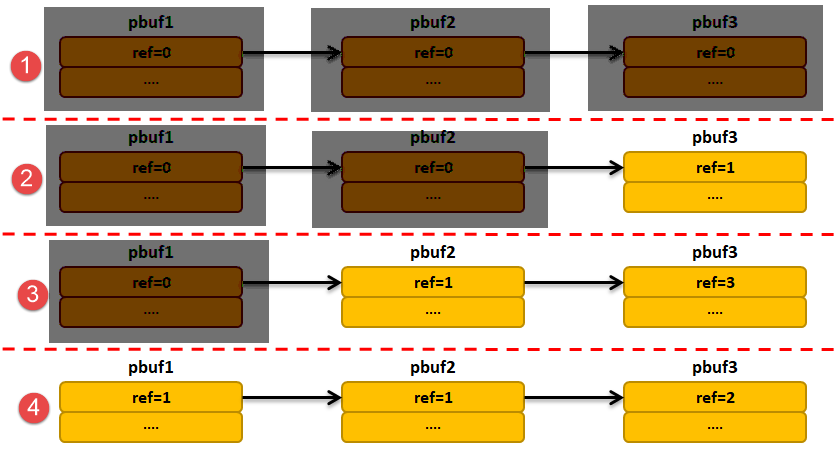
- pbuf_free§:按 ref 递减,ref 降为 0 时释放。注意必须从“链表头”释放;非头结点释放会残留严重内存泄漏或破坏链。
- 链接与复制
- pbuf_chain(head, tail):将两个链连接;tail 被 head 引用(ref++)
- pbuf_cat(head, tail):将 tail 直接挂到 head 尾(调用方不能再持有 tail 的引用)
- pbuf_copy(dst, src):把 src 数据拷贝到 dst(PBUF_RAM)
- pbuf_clone(layer, type, src):克隆到新 pbuf
- pbuf_coalesce(p, layer):合并链为单块(常用于发送)
- 长度与头部调整
- pbuf_realloc(p, new_len):裁剪链尾部长度(PBUF_RAM 可收缩堆块;其他类型只改字段)
- pbuf_header()/pbuf_add_header()/pbuf_remove_header():调整 payload 位置
- pbuf_free_header(q, size):移除链表头部若干字节,必要时释放头部 pbuf
- 数据访问
- pbuf_take(buf, dataptr, len) / pbuf_take_at(…, offset):将数据拷贝到 pbuf
- pbuf_copy_partial(p, dst, len, offset):从 pbuf 按偏移复制
- pbuf_get_contiguous(p, tmpbuf, tmpbufsize, len, offset):获取连续内存视图(零拷贝或拷贝到 tmpbuf)
- pbuf_get_at/pbuf_put_at/pbuf_memcmp/pbuf_memfind/pbuf_strstr:按偏移读取/写入/比较
调试/辅助:
- PBUF_NEEDS_COPY§:宏判断是否需要复制(默认:非 ROM 的链表要复制)
- PBUF_POOL_FREE_OOSEQ:当 PBUF_POOL 耗尽会尝试释放 TCP 乱序队列中的 pbuf,缓解 RX 饥饿
常见陷阱:
- 释放非链表头:导致泄漏或破坏链
- 忘记 pbuf_ref:多处共享同一 pbuf 却未增加引用,会过早释放
- 使用 PBUF_RAM 做零拷贝发送:若堆不在 DMA 区或 Cache 未清,可能 DMA 读不到数据
- 长时间持有 PBUF_POOL 用于 TX:会饿死 RX(尤其高吞吐 TCP)
5. PBUF_POOL 与 MEMP_PBUF/MEMP_PBUF_POOL 的区别与联动
- MEMP_PBUF:仅“pbuf 头”的池(struct pbuf),服务于 PBUF_ROM/PBUF_REF(引用外部数据)和某些场景的头结点。
- MEMP_PBUF_POOL:完整“头+payload”的固定块池,服务于 PBUF_POOL(RX 最佳)。
分配逻辑(简化):
- pbuf_alloc(PBUF_POOL):使用 memp_malloc(MEMP_PBUF_POOL),按 PBUF_POOL_BUFSIZE 切段组链。
- pbuf_alloc_reference(…, PBUF_REF/PBUF_ROM):使用 memp_malloc(MEMP_PBUF) 分配结构体,payload 指向外部/常量区。
- pbuf_alloc(PBUF_RAM):使用 mem_malloc 在堆上分配一块连续内存(头+payload)。
配置建议:
- PBUF_POOL_BUFSIZE ≥ MTU + 头部预留;以太网通常 1514/1520;考虑 VLAN、对齐、DMA。
- PBUF_POOL_SIZE ≥ RX 描述符数量 × 2~4 + 应用峰值冗余。
- MEMP_NUM_PBUF ≥ PBUF_POOL_SIZE + 额外裕量(例如 +16)。
6. ethernetif 端口(STM32 HAL)详解
以你提供的 ethernetif.c 为例,驱动层职责是“把硬件收上来的帧填入 pbuf 并上送栈;把栈要发的 pbuf 复制到 DMA TX 缓冲并启动发送”。
6.1 low_level_init(netif)
- 设置 MAC 地址、MTU、NETIF_FLAG_ETHARP/NETIF_FLAG_BROADCAST/NETIF_FLAG_LINK_UP
- 创建信号量/邮箱/线程(示例:s_xSemaphore、tx_sem、eth_tx_mb、ethernetif_input 线程)
- 使能中断、时钟,启动 HAL_ETH_Start
- 注意:
- 若 LWIP_ARP=1:建议 netif->output = etharp_output;netif->linkoutput = low_level_output
- NO_SYS=0(有 RTOS)时,低层接收一般放线程里,或在中断里给信号量
6.2 low_level_output(netif, p)
- 从 pbuf 链复制到一个或多个 DMA TX 缓冲(ETH_TX_BUF_SIZE 粒度),计算 framelength
- 描述符忙时返回 ERR_USE(注意:上层通常不会重试 UDP,TCP 会因定时器重发)
- 关键点:
- 确保 TX 描述符环足够大,并正确遍历 Buffer2NextDescAddr
- Cache 一致性:发送前对 TX 缓冲做 DCache Clean(若启用 Cache)
- 避免长时间持有互斥/临界区,减少阻塞
- 硬件支持散点聚集可减少 memcpy(高级 MAC/DMAs)
建议优化:
- 用 TX 环管理“队列满”:阻塞等待/排队,或返回 ERR_USE 让上层有机会恢复
- 避免在临界区内做大块 memcpy
- 统计 TX 丢包/拥塞,指导 ETH_TX_BUF_NUM 调整
6.3 low_level_input(netif)
- HAL_ETH_GetReceivedFrame 得到帧长与首个缓冲指针
- p = pbuf_alloc(PBUF_RAW, len, PBUF_POOL) 分配 pbuf 链
- 将 RX 缓冲的数据复制到 p->payload 链(分页复制)
- 释放所有使用过的 RX 描述符(置 OWN),清 RBUS,恢复接收
- 注意:
- RX DMA 缓冲需 DCache Invalidate(从内存读前)
- ETH_RX_BUF_SIZE 要与 DMA 配置匹配;pbuf 分段复制时注意偏移
- PBUF_POOL 耗尽时 p==NULL:可能触发 PBUF_POOL_FREE_OOSEQ 或丢包,需打点统计
6.4 ethernetif_input 线程
- 等待 s_xSemaphore(通常在 ETH 中断服务中释放)
- 循环调用 low_level_input 获取 pbuf,调用 netif->input(p, netif) 交给栈(tcpip_thread)
- 失败时 pbuf_free§
- 建议:
- netif->input 可能切到 tcpip 线程,避免在临界区内调用
- 批量处理(你的 goto TRY_GET_NEXT_FRAGMENT 思路):减少线程切换开销
- 线程优先级要高,避免丢包;栈与驱动之间 mbox 大小要足够(TCPIP_MBOX_SIZE)
6.5 链路回调与协商
- ethernetif_update_config:链路 up/down、自动协商、重启 MAC
- 建议结合 LWIP_NETIF_LINK_CALLBACK/LWIP_NETIF_STATUS_CALLBACK 上报
7. 零拷贝思路(进阶)
- RX 零拷贝:将 DMA RX 缓冲封装为“自定义 pbuf”(LWIP_SUPPORT_CUSTOM_PBUF=1),把“释放函数”写成归还 DMA 缓冲。要点:
- pbuf_alloced_custom 填充 pbuf_custom,payload 指向 DMA 缓冲;设置 custom_free_function
- NO_SYS=0 时,跨线程共享要管理好生命周期/引用计数
- Cache:RX 前 Invalidate,TX 前 Clean
- TX 零拷贝:直接让 MAC 发送 pbuf 链 payload(硬件支持散点聚集+DMA 可直接访问),并在发送完成回调里 pbuf_free
- 保证 pbuf 生命周期覆盖 DMA 发送窗口(不要提前 free)
- 避免使用 PBUF_POOL 进行 TX 长时间排队(饿死 RX)
8. 典型数据流(发送与接收)
发送(应用→栈→驱动→MAC):
- 应用构造数据(可能在 PBUF_RAM),协议层用 pbuf_header 预留/填充头
- netif->linkoutput 指向 low_level_output,驱动将 pbuf 链拷贝至 DMA TX 缓冲
- HAL_ETH_TransmitFrame 启动 DMA
接收(MAC→驱动→栈→应用):
- 中断/轮询检测到帧,low_level_input 读取 DMA RX 缓冲
- 分配 PBUF_POOL 链,复制数据
- netif->input(p, netif) 上送到 tcpip_thread;上层解析并递交给套接字/回调
注意:PBUF_POOL 链在驱动与栈共享,尽量避免额外拷贝;释放时只调用 pbuf_free。
9. 配置与调优建议(lwipopts.h 相关)
必须关注:
- 内存与对齐
- MEM_ALIGNMENT:大多平台设为 4 或 8。DMA/Cache 平台不要设 1
- PBUF_POOL_BUFSIZE:建议 ≥ MTU + 头部(1514/1520),可向上对齐
- PBUF_POOL_SIZE:≥ RX 描述符 × 2~4 + 峰值
- MEMP_NUM_PBUF:≥ PBUF_POOL_SIZE + 余量(8~16)
- MEM_SIZE:堆大小(服务 PBUF_RAM/控制结构),TCP 推荐从 16KB 起步按需调整
- 线程/并发
- NO_SYS=0,SYS_LIGHTWEIGHT_PROT=1,确保 sys_arch* 实现正确
- LWIP_TCPIP_CORE_LOCKING 可用但要有正确的 tcpip 线程与 mbox 尺寸
- 协议相关
- TCP_MSS:以太网通常 1460
- TCP_WND/TCP_SND_BUF/TCP_SND_QUEUELEN:与吞吐/内存成正比
- CHECKSUM_GEN_* / CHECKSUM_CHECK_*:是否由硬件完成(硬件校验则禁用软件重复计算)
- 调试
- LWIP_STATS/MEM_STATS/MEMP_STATS 打开,观察池/堆使用率、失败计数
- MEM_SANITY_CHECK/MEMP_SANITY_CHECK/MEM_OVERFLOW_CHECK:开发阶段建议开启
示例(以太网、MSS=1460):
- PBUF_LINK_HLEN 14,PBUF_IP_HLEN 20,PBUF_TRANSPORT_HLEN 20
- PBUF_POOL_BUFSIZE = LWIP_MEM_ALIGN_SIZE(1460+40+14) ≈ 1514(可对齐至 1520/1536)
10. 常见问题与排查
- 接收丢包 / pbuf_alloc(PBUF_POOL) 返回 NULL
- PBUF_POOL_SIZE 太小;PBUF_POOL 被 TX 长时间占用;统计 pbuf_pool 空闲/失败数
- 开启 PBUF_POOL_FREE_OOSEQ(TCP 场景)以回收乱序缓冲
- 发送返回 ERR_USE
- TX 描述符不足/队列满;阻塞等待或扩展环大小;统计并调参 ETH_TX_BUF_NUM
- “释放崩溃 / double free”
- 非头结点传给 pbuf_free;多处共享但未 pbuf_ref;开启 SANITY 与 OVERFLOW_CHECK
- 数据错乱 / 校验错
- Cache 未 Clean/Invalidate;堆或池未对齐;硬件校验配置与宏不一致
- 吞吐低
- PBUF_POOL_BUFSIZE 太小导致链式过多;MSS/WND 太小;线程/mbox 过小;频繁 memcpy
11. 进阶:自定义 pbuf(零拷贝 RX 示例片段)
/* 简要示例:将 DMA RX 缓冲封装为自定义 pbuf(释放时归还 DMA 缓冲) */
struct my_rx_buf { uint8_t *dma; uint16_t len; /* ... */ };
static void my_pbuf_free(struct pbuf *p) {struct pbuf_custom *pc = (struct pbuf_custom*)p;struct my_rx_buf *rx = (struct my_rx_buf*)pc->pbuf.payload /* or pc user field */;/* 归还 rx->dma 给 RX 环,并置 OWN 给 DMA *//* ... */
}struct pbuf_custom pc;
pbuf_alloced_custom(PBUF_RAW, rx->len, PBUF_POOL /*标记用途*/, &pc,rx->dma /*payload_mem*/, rx->len /*payload_mem_len*/);
pc.custom_free_function = my_pbuf_free;
/* 上送栈:netif->input(&pc.pbuf, netif); */
要点:
- payload_mem 必须满足对齐要求
- 自定义 pbuf 释放后不可再访问 DMA 缓冲
- Cache 一致性要处理到位
12. 结语与建议
- RX 首选 PBUF_POOL(固定块,低碎片,确定性);TX 可用 PBUF_RAM 或硬件支持下的零拷贝。
- 池与堆“混用”是常态,但不要跨 API 释放(pbuf_free/memp_free/mem_free 不要混用)。
- 带上统计数据做调参,优先保证 RX 不饥饿(PBUF_POOL 充足、线程优先级合理、mbox 足够)。
- 硬件 DMA/Cache 平台优先考虑对齐与缓存一致性,必要时牺牲少量内存换更稳定吞吐。
- 结合你的目标硬件(RX/TX 描述符数、Cache 情况)与 lwipopts.h,确定 PBUF_POOL_*、MEMP_NUM_PBUF、MEM_ALIGNMENT、MEM_SIZE 的初值,并用 LWIP_STATS 验证运行期水位后收敛。