电商数据分析可视化预测系统
选用技术
爬虫技术:初期使用 DrissionPage 自动化采集技术,但因速度过慢更换。后期采用 request 技术,其请求响应快,能迅速获取数据。采集数据来源为京东平台。
模型:随机森林、逻辑回归模型。
前后端及可视化技术:
前端:html、css、js、echarts。
后端:python django。
数据库:mysql。
关键代码
模型预测代码:
import pandas as pd
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.ensemble import RandomForestClassifier
from sklearn.linear_model import LogisticRegression
from sklearn.preprocessing import LabelEncoder, StandardScaler, OneHotEncoder
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from sklearn.metrics import accuracy_score, classification_report
from joblib import dumpfrom sklearn.preprocessing import OneHotEncoder# 关键参数:handle_unknown='ignore'(忽略未知类别,避免报错)
# 确保categories自动推断,或手动指定(避免混合类型)
encoder = OneHotEncoder(handle_unknown='ignore', sparse_output=False)
# 1. 读取数据集
data = pd.read_csv("result3.csv")# 2. 定义销量区间(基于总评数)
sales_bins = [0, 1000, 5000, 10000, float('inf')]
sales_labels = ['低销量', '中等销量', '高销量', '超高销量']
data['sales_range'] = pd.cut(data['总评数'], bins=sales_bins, labels=sales_labels, right=False)# 3. 特征和目标变量
features = ["价格", "品牌", "好评率", "平均得分"]
target = "sales_range"
X = data[features]
y = data[target]# 4. 目标变量编码(保持不变)
target_encoder = LabelEncoder()
y_encoded = target_encoder.fit_transform(y)# 5. 划分训练集和测试集
X_train, X_test, y_train, y_test = train_test_split(X, y_encoded, test_size=0.2, random_state=42)# 6. 特征预处理管道(数值标准化+类别独热编码)
numeric_features = ["价格", "好评率", "平均得分"]
categorical_features = ["品牌"]preprocessor = ColumnTransformer(transformers=[('num', StandardScaler(), numeric_features),('cat', OneHotEncoder(handle_unknown='ignore'), categorical_features)])# 7. 随机森林模型(带超参数调优)
rf_pipeline = Pipeline([('preprocessor', preprocessor),('classifier', RandomForestClassifier(random_state=42))
])rf_param_grid = {'classifier__n_estimators': [100, 200],'classifier__max_depth': [None, 10, 20]
}rf_grid = GridSearchCV(rf_pipeline, rf_param_grid, cv=5, n_jobs=-1)
rf_grid.fit(X_train, y_train)
rf_model = rf_grid.best_estimator_# 8. 逻辑回归模型(解决收敛问题)
lr_pipeline = Pipeline([('preprocessor', preprocessor),('classifier', LogisticRegression(solver='saga', # 适合高维数据和正则化max_iter=200, # 增加迭代次数C=0.1, # 正则化强度(可调优)random_state=42))
])
lr_pipeline.fit(X_train, y_train)# 9. 模型评估
# 随机森林
rf_predictions = rf_model.predict(X_test)
rf_accuracy = accuracy_score(y_test, rf_predictions)
print("随机森林模型的准确率:", rf_accuracy)
print("随机森林分类报告:\n", classification_report(y_test, rf_predictions, target_names=sales_labels))# 逻辑回归
lr_predictions = lr_pipeline.predict(X_test)
lr_accuracy = accuracy_score(y_test, lr_predictions)
print("逻辑回归模型的准确率:", lr_accuracy)
print("逻辑回归分类报告:\n", classification_report(y_test, lr_predictions, target_names=sales_labels))# 10. 保存模型和预处理工具
dump(rf_model, "rf_sales_model.joblib")
dump(lr_pipeline, "lr_sales_model.joblib")
dump(target_encoder, "target_encoder.joblib")系统展示
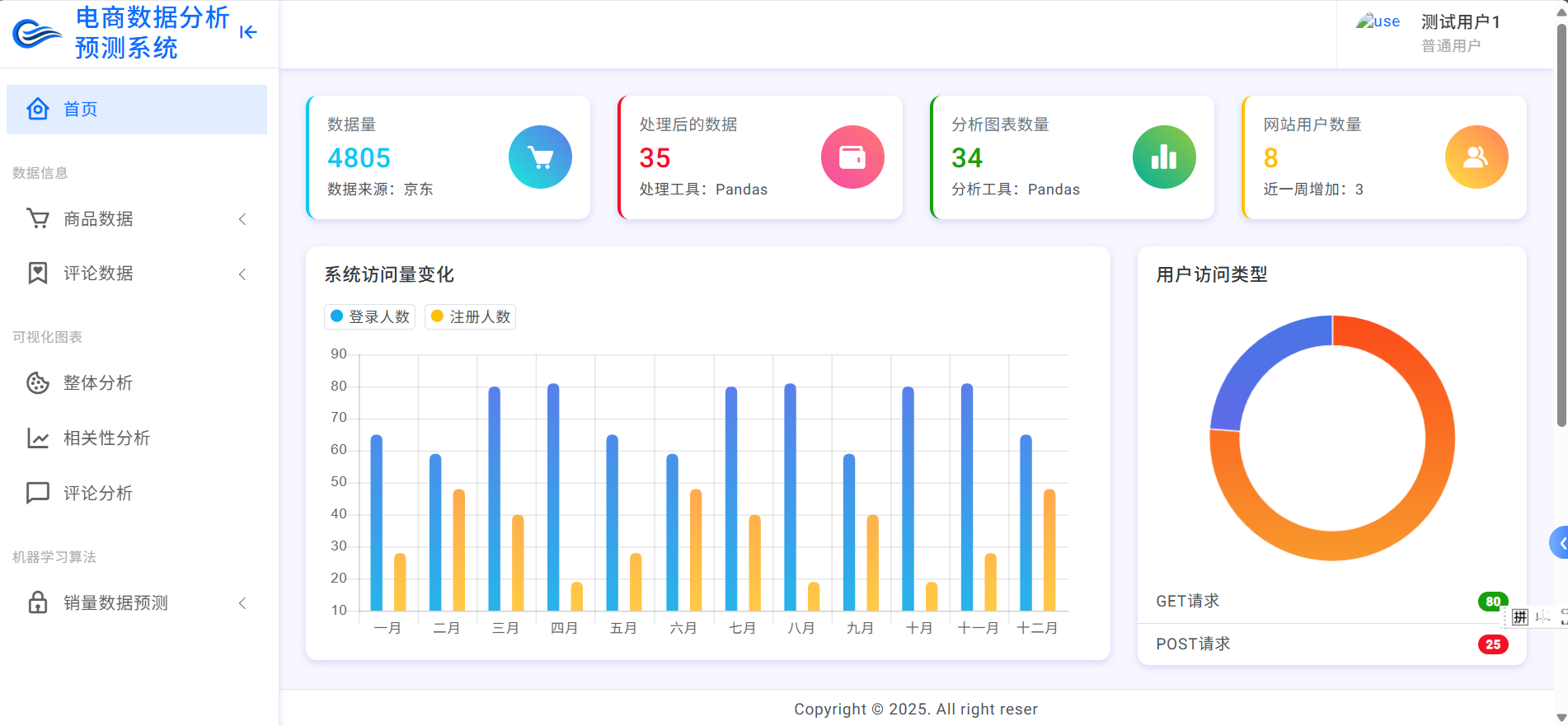
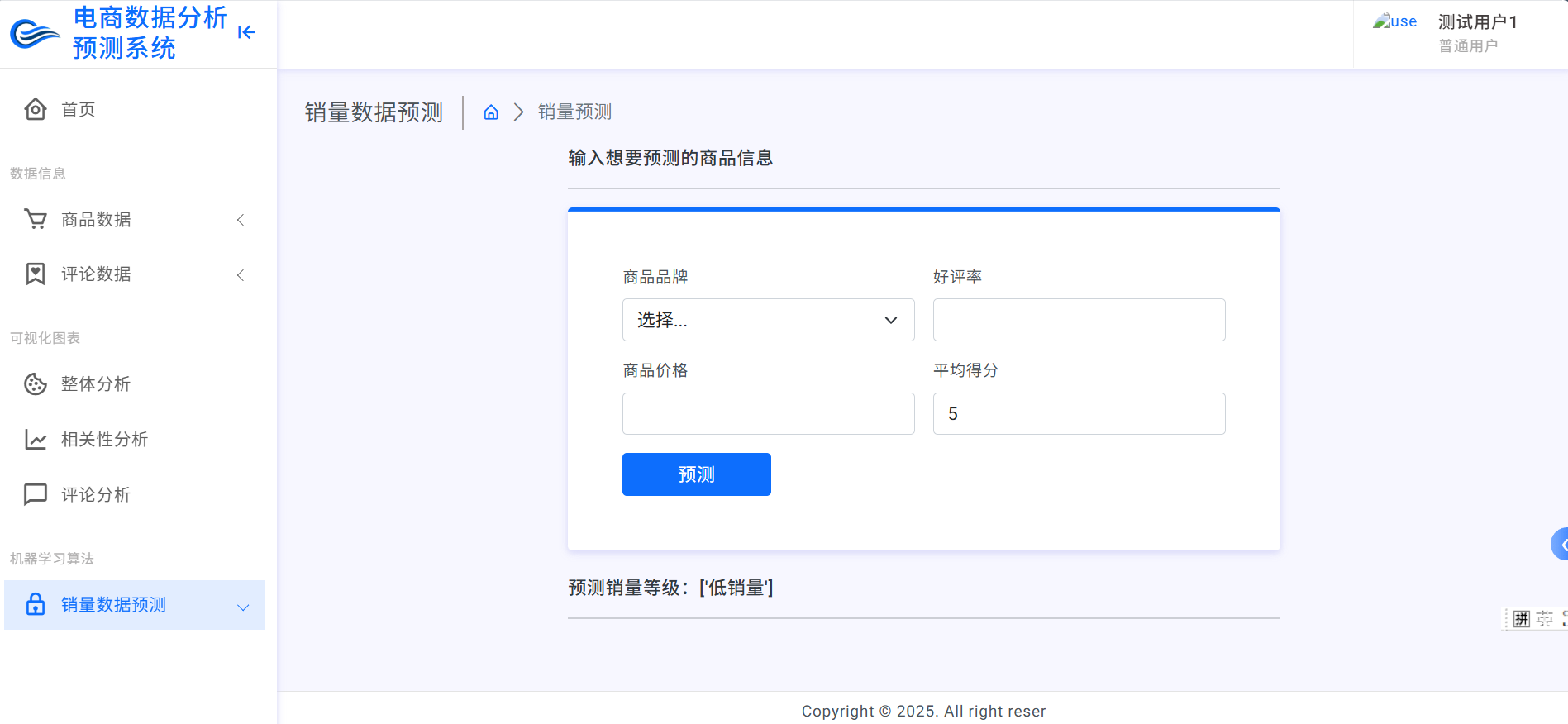
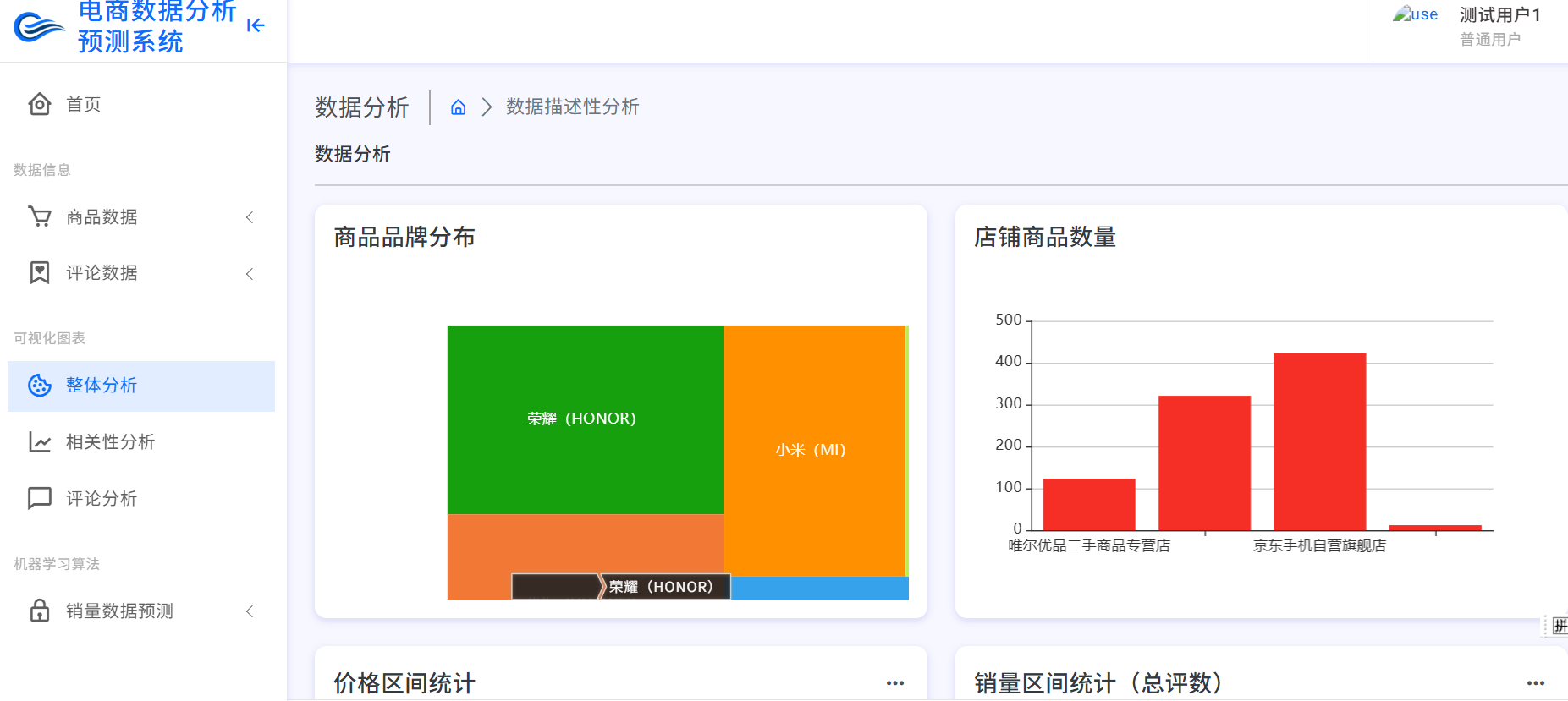
资料获取
私信老师