【完整源码+数据集+部署教程】海洋垃圾与生物识别系统源码和数据集:改进yolo11-RVB
背景意义
研究背景与意义
随着全球经济的快速发展和人口的持续增长,海洋环境面临着前所未有的压力,尤其是海洋垃圾问题日益严重。根据联合国环境规划署的报告,全球每年有超过800万吨的塑料垃圾流入海洋,这不仅对海洋生态系统造成了巨大威胁,也对人类的生存环境产生了深远影响。海洋垃圾不仅影响海洋生物的生存和繁衍,还通过食物链影响人类健康。因此,开发有效的海洋垃圾监测与识别系统,成为了当今社会亟待解决的重要课题。
在这一背景下,基于改进YOLOv11的海洋垃圾与生物识别系统应运而生。YOLO(You Only Look Once)系列模型因其高效的实时目标检测能力而广泛应用于计算机视觉领域。通过对YOLOv11的改进,我们能够更精准地识别和分类海洋中的垃圾与生物,进而为海洋保护提供科学依据。我们的研究将使用一个包含7200张图像的多类别数据集,该数据集涵盖了22个类别,包括多种海洋生物(如螃蟹、鳗鱼、鱼类、海星等)和各种垃圾(如塑料袋、瓶子、衣物等)。这种多样性不仅有助于提高模型的泛化能力,也为实际应用提供了丰富的数据支持。
此外,海洋垃圾的种类繁多,且其分布情况复杂,因此,构建一个高效的识别系统不仅可以帮助科学家们更好地理解海洋生态系统的现状,还能为政策制定者提供数据支持,推动海洋保护政策的实施。通过本研究,我们希望能够为海洋环境保护贡献一份力量,促进可持续发展目标的实现。
图片效果
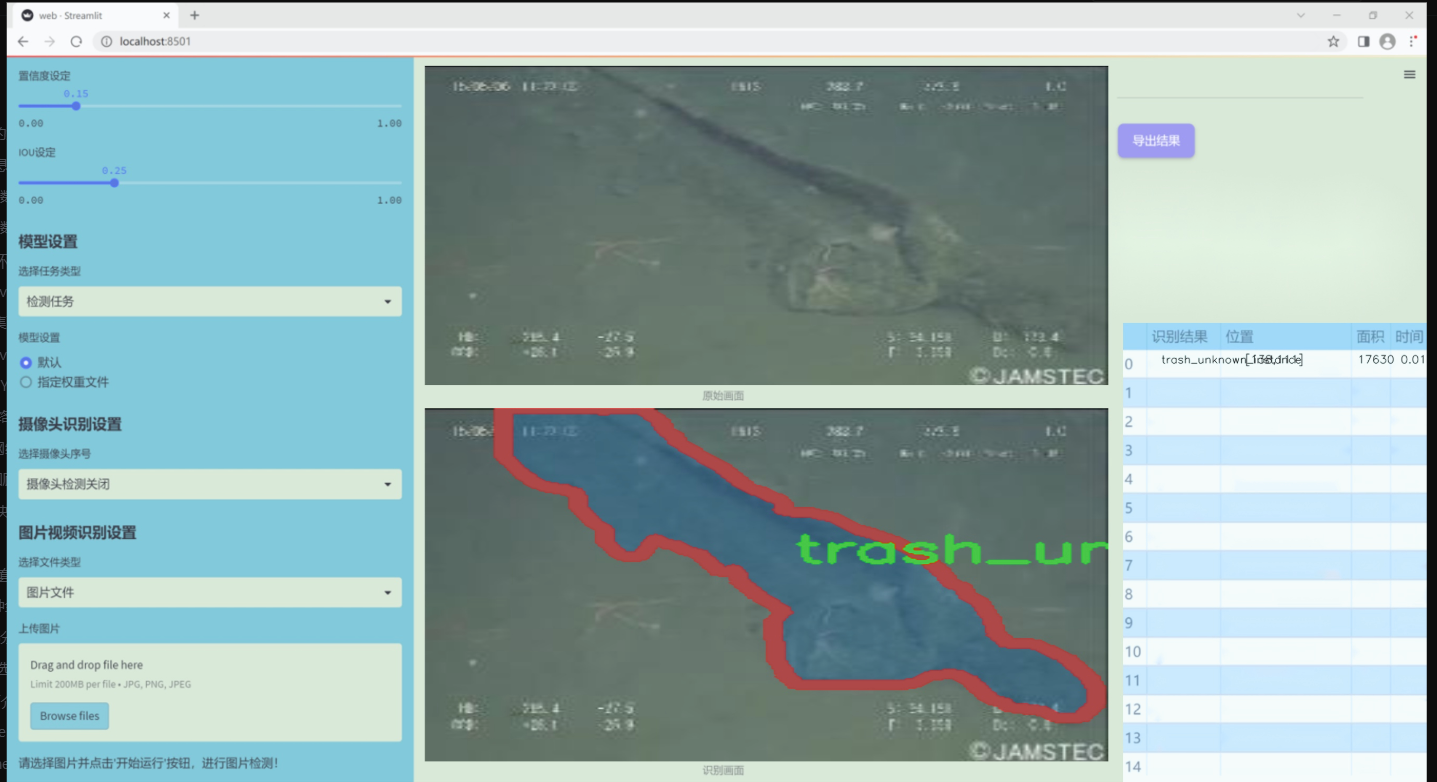
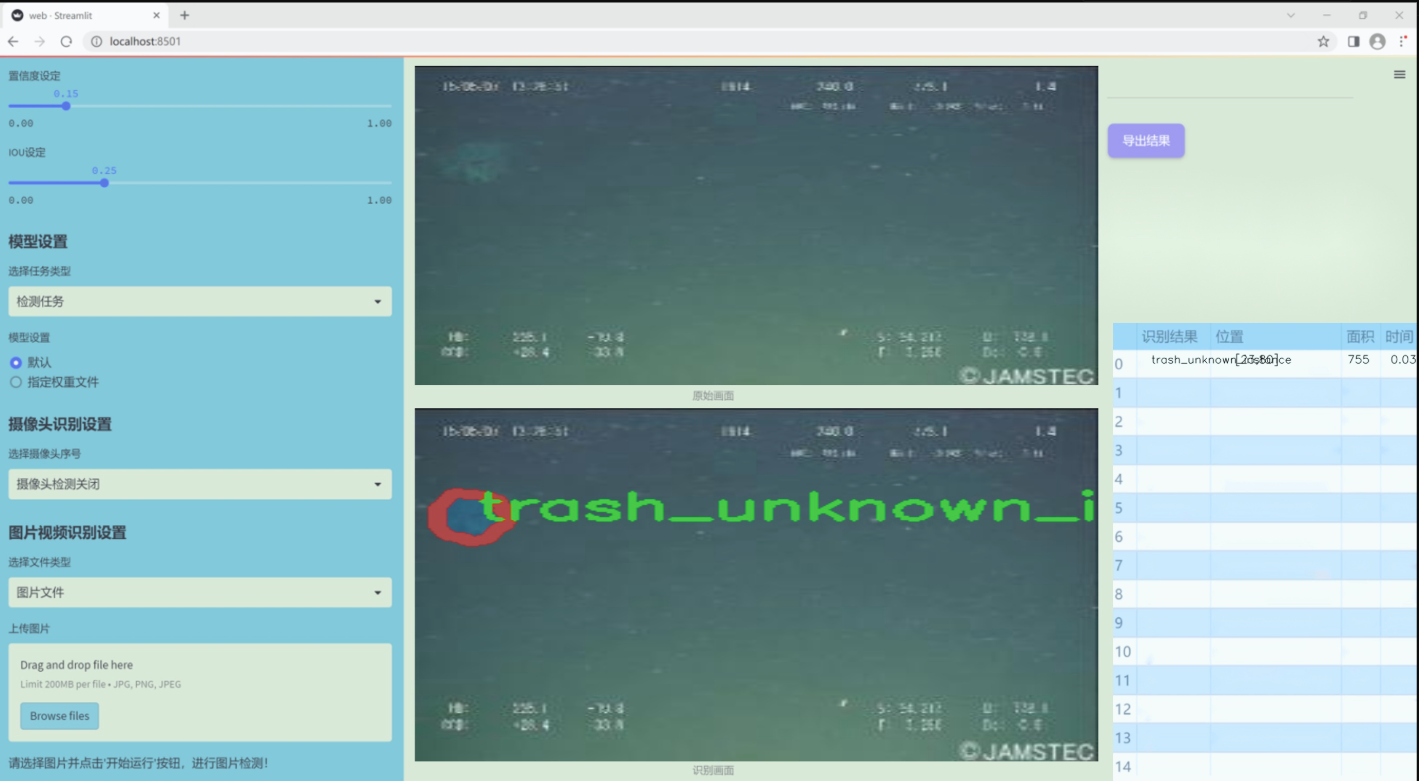
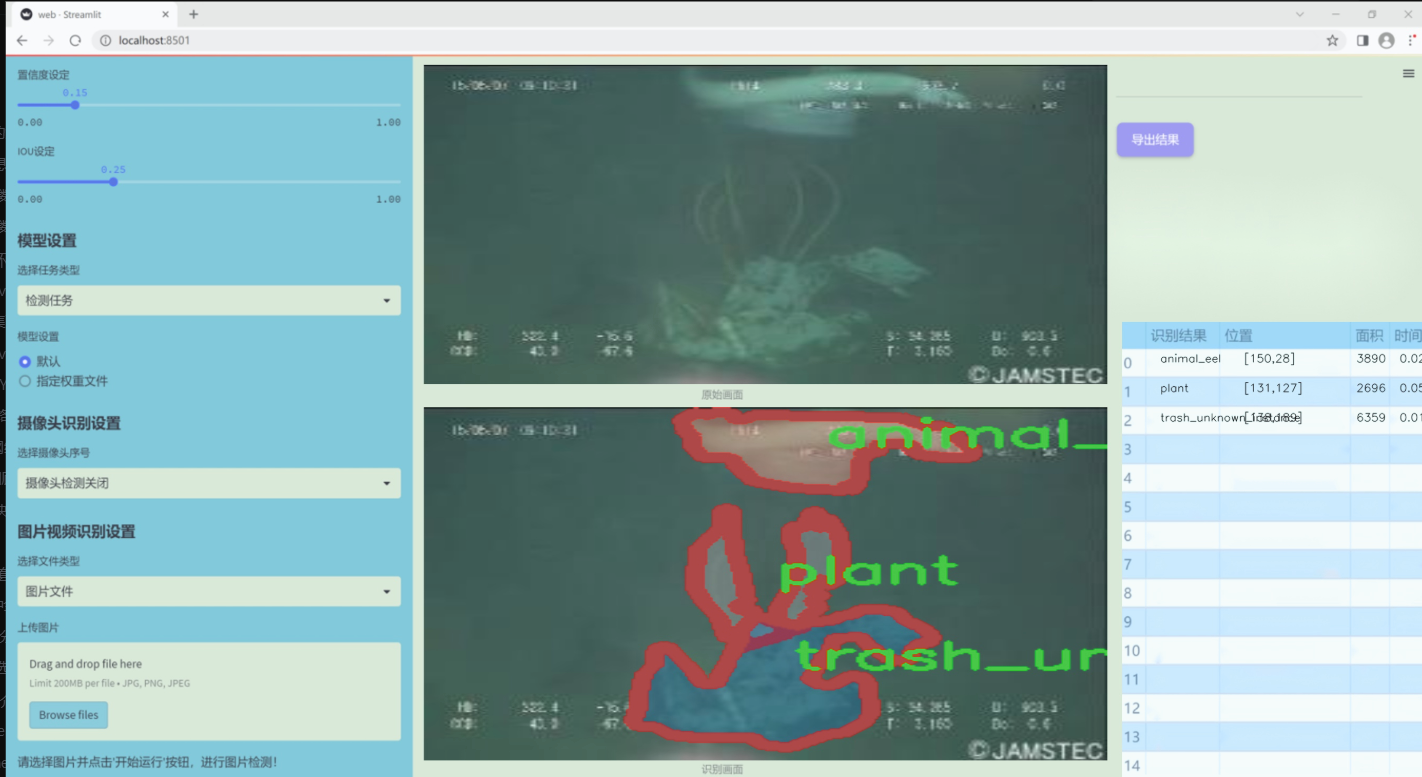
数据集信息
本项目数据集信息介绍
本项目旨在通过改进YOLOv11模型,构建一个高效的海洋垃圾与生物识别系统,以应对日益严重的海洋污染问题。为实现这一目标,我们收集并整理了一个丰富多样的数据集,该数据集包含22个类别,涵盖了海洋生物及各种垃圾类型,旨在提高模型在复杂环境下的识别能力。数据集中的类别包括七种海洋生物,如螃蟹、鳗鱼、鱼类、贝类和海星等,这些生物的多样性反映了海洋生态系统的丰富性与脆弱性。同时,数据集中还包含15种不同类型的海洋垃圾,如塑料袋、瓶子、树枝、衣物、容器、杯子、渔网、管道、绳索、零食包装、帆布、未知垃圾实例及残骸等。这些垃圾不仅对海洋生物构成威胁,也对生态环境造成了严重影响。
在数据集的构建过程中,我们特别注重数据的多样性和代表性,确保每个类别都能充分反映其在实际海洋环境中的出现频率和特征。通过精心标注和分类,我们希望为模型的训练提供一个全面的基础,使其能够在复杂的海洋环境中有效地识别和区分生物与垃圾。这一数据集的设计不仅有助于提高YOLOv11模型的识别精度,还将为未来的海洋保护和垃圾清理工作提供重要的技术支持和数据参考。通过不断优化和扩展该数据集,我们期望能够推动海洋垃圾监测和生物保护领域的研究进展,为实现可持续发展的海洋生态环境贡献力量。


核心代码
以下是代码中最核心的部分,并附上详细的中文注释:
import torch
import torch.nn as nn
import torch.nn.functional as F
class DWConv2d(nn.Module):
“”" 深度可分离卷积类 “”"
def init(self, dim, kernel_size, stride, padding):
super().init()
# 使用深度可分离卷积,groups=dim表示每个输入通道都有独立的卷积核
self.conv = nn.Conv2d(dim, dim, kernel_size, stride, padding, groups=dim)
def forward(self, x: torch.Tensor):'''x: 输入张量,形状为 (b, h, w, c)'''x = x.permute(0, 3, 1, 2) # 转换为 (b, c, h, w)x = self.conv(x) # 进行卷积操作x = x.permute(0, 2, 3, 1) # 转换回 (b, h, w, c)return x
class MaSA(nn.Module):
“”" 多头自注意力机制类 “”"
def init(self, embed_dim, num_heads, value_factor=1):
super().init()
self.factor = value_factor
self.embed_dim = embed_dim
self.num_heads = num_heads
self.head_dim = self.embed_dim * self.factor // num_heads # 每个头的维度
self.key_dim = self.embed_dim // num_heads # 键的维度
self.scaling = self.key_dim ** -0.5 # 缩放因子
# 定义线性变换层
self.q_proj = nn.Linear(embed_dim, embed_dim, bias=True)
self.k_proj = nn.Linear(embed_dim, embed_dim, bias=True)
self.v_proj = nn.Linear(embed_dim, embed_dim * self.factor, bias=True)
self.lepe = DWConv2d(embed_dim, 5, 1, 2) # 位置编码卷积
self.out_proj = nn.Linear(embed_dim * self.factor, embed_dim, bias=True) # 输出线性层
self.reset_parameters() # 初始化参数
def reset_parameters(self):# 使用Xavier初始化权重nn.init.xavier_normal_(self.q_proj.weight, gain=2 ** -2.5)nn.init.xavier_normal_(self.k_proj.weight, gain=2 ** -2.5)nn.init.xavier_normal_(self.v_proj.weight, gain=2 ** -2.5)nn.init.xavier_normal_(self.out_proj.weight)nn.init.constant_(self.out_proj.bias, 0.0)def forward(self, x: torch.Tensor, rel_pos):'''x: 输入张量,形状为 (b, h, w, c)rel_pos: 位置关系张量'''bsz, h, w, _ = x.size() # 获取输入的批量大小和高度宽度# 计算查询、键、值q = self.q_proj(x)k = self.k_proj(x)v = self.v_proj(x)lepe = self.lepe(v) # 位置编码k *= self.scaling # 应用缩放因子# 重新排列张量以适应多头注意力qr = q.view(bsz, h, w, self.num_heads, -1).permute(0, 3, 1, 2, 4) # (b, n, h, w, d1)kr = k.view(bsz, h, w, self.num_heads, -1).permute(0, 3, 1, 2, 4) # (b, n, h, w, d1)# 计算注意力矩阵qk_mat = qr @ kr.transpose(-1, -2) + rel_pos # (b, n, h, w, w)qk_mat = torch.softmax(qk_mat, -1) # 归一化output = torch.matmul(qk_mat, v) # (b, n, h, w, d2)output = output.permute(0, 3, 1, 2, 4).flatten(-2, -1) # (b, h, w, n*d2)output = output + lepe # 加上位置编码output = self.out_proj(output) # 输出return output
class FeedForwardNetwork(nn.Module):
“”" 前馈神经网络类 “”"
def init(self, embed_dim, ffn_dim, activation_fn=F.gelu, dropout=0.0):
super().init()
self.fc1 = nn.Linear(embed_dim, ffn_dim) # 第一层线性变换
self.fc2 = nn.Linear(ffn_dim, embed_dim) # 第二层线性变换
self.activation_fn = activation_fn # 激活函数
self.dropout_module = nn.Dropout(dropout) # dropout层
def forward(self, x: torch.Tensor):'''x: 输入张量,形状为 (b, h, w, c)'''x = self.fc1(x) # 第一层x = self.activation_fn(x) # 激活x = self.dropout_module(x) # dropoutx = self.fc2(x) # 第二层x = self.dropout_module(x) # dropoutreturn x
class VisRetNet(nn.Module):
“”" 视觉回归网络类 “”"
def init(self, in_chans=3, num_classes=1000, embed_dims=[96, 192, 384, 768], depths=[2, 2, 6, 2], num_heads=[3, 6, 12, 24]):
super().init()
self.patch_embed = PatchEmbed(in_chans=in_chans, embed_dim=embed_dims[0]) # 图像到补丁的嵌入
self.layers = nn.ModuleList() # 存储各层
for i_layer in range(len(depths)):
layer = BasicLayer(embed_dim=embed_dims[i_layer], depth=depths[i_layer], num_heads=num_heads[i_layer])
self.layers.append(layer) # 添加层
def forward(self, x):x = self.patch_embed(x) # 嵌入for layer in self.layers:x = layer(x) # 逐层前向传播return x
定义模型的构造函数
def RMT_T():
model = VisRetNet(
embed_dims=[64, 128, 256, 512],
depths=[2, 2, 8, 2],
num_heads=[4, 4, 8, 16]
)
return model
if name == ‘main’:
model = RMT_T() # 创建模型
inputs = torch.randn((1, 3, 640, 640)) # 创建输入张量
res = model(inputs) # 前向传播
for i in res:
print(i.size()) # 输出每层的形状
代码核心部分说明:
DWConv2d: 实现了深度可分离卷积,用于特征提取。
MaSA: 实现了多头自注意力机制,能够捕捉输入特征之间的关系。
FeedForwardNetwork: 实现了前馈神经网络,包含两个线性层和激活函数。
VisRetNet: 视觉回归网络的主类,负责构建整个网络结构,包括补丁嵌入和各层的堆叠。
RMT_T: 模型构造函数,创建一个特定配置的视觉回归网络。
这些核心部分共同构成了一个用于图像处理的深度学习模型。
这个程序文件 rmt.py 实现了一个视觉变换器(Vision Transformer)模型,名为 VisRetNet,并提供了不同规模的模型构造函数(如 RMT_T, RMT_S, RMT_B, RMT_L)。该模型的设计旨在处理图像数据,使用了一系列的深度学习模块,包括卷积层、注意力机制、前馈网络等。
首先,文件导入了必要的库,包括 PyTorch 和一些用于构建神经网络的模块。接着,定义了一些基础组件,例如 DWConv2d 类实现了深度可分离卷积,RelPos2d 类用于生成相对位置编码,MaSAd 和 MaSA 类实现了不同的多头自注意力机制。
FeedForwardNetwork 类定义了前馈神经网络结构,包含两个线性层和激活函数。RetBlock 类是一个包含注意力机制和前馈网络的基本块,可以选择使用层归一化和层缩放。PatchMerging 类用于将特征图进行下采样,BasicLayer 类则构建了一个基本的层结构,包含多个 RetBlock。
LayerNorm2d 和 PatchEmbed 类分别实现了二维层归一化和图像到补丁的嵌入转换。最后,VisRetNet 类是整个模型的核心,负责将输入图像分割成补丁并通过多个层进行处理。该类的构造函数允许用户设置不同的超参数,例如嵌入维度、层数、头数等。
在文件的最后部分,定义了四个不同规模的模型构造函数,分别为 RMT_T, RMT_S, RMT_B, RMT_L,这些函数根据不同的参数配置创建相应的 VisRetNet 实例。
在 main 部分,代码示例展示了如何实例化一个小型模型 RMT_T 并对随机生成的输入进行前向传播,输出各层的特征图大小。
总体来说,这个文件实现了一个复杂的视觉变换器架构,适用于图像分类等任务,充分利用了现代深度学习中的注意力机制和卷积操作。
10.4 VanillaNet.py
以下是经过简化并添加详细中文注释的核心代码部分:
import torch
import torch.nn as nn
import torch.nn.functional as F
from timm.layers import weight_init
定义激活函数类
class Activation(nn.ReLU):
def init(self, dim, act_num=3, deploy=False):
super(Activation, self).init()
self.deploy = deploy # 是否处于部署模式
# 初始化权重和偏置
self.weight = torch.nn.Parameter(torch.randn(dim, 1, act_num * 2 + 1, act_num * 2 + 1))
self.bias = None
self.bn = nn.BatchNorm2d(dim, eps=1e-6) # 批归一化
self.dim = dim
self.act_num = act_num
weight_init.trunc_normal_(self.weight, std=.02) # 权重初始化
def forward(self, x):# 前向传播if self.deploy:return F.conv2d(super(Activation, self).forward(x), self.weight, self.bias, padding=(self.act_num * 2 + 1) // 2, groups=self.dim)else:return self.bn(F.conv2d(super(Activation, self).forward(x),self.weight, padding=self.act_num, groups=self.dim))def switch_to_deploy(self):# 切换到部署模式,融合批归一化if not self.deploy:kernel, bias = self._fuse_bn_tensor(self.weight, self.bn)self.weight.data = kernelself.bias = torch.nn.Parameter(torch.zeros(self.dim))self.bias.data = biasself.__delattr__('bn') # 删除bn属性self.deploy = Truedef _fuse_bn_tensor(self, weight, bn):# 融合权重和批归一化的参数kernel = weightrunning_mean = bn.running_meanrunning_var = bn.running_vargamma = bn.weightbeta = bn.biaseps = bn.epsstd = (running_var + eps).sqrt()t = (gamma / std).reshape(-1, 1, 1, 1)return kernel * t, beta + (0 - running_mean) * gamma / std
定义基本模块Block
class Block(nn.Module):
def init(self, dim, dim_out, act_num=3, stride=2, deploy=False):
super().init()
self.deploy = deploy
# 根据是否部署选择不同的卷积结构
if self.deploy:
self.conv = nn.Conv2d(dim, dim_out, kernel_size=1)
else:
self.conv1 = nn.Sequential(
nn.Conv2d(dim, dim, kernel_size=1),
nn.BatchNorm2d(dim, eps=1e-6),
)
self.conv2 = nn.Sequential(
nn.Conv2d(dim, dim_out, kernel_size=1),
nn.BatchNorm2d(dim_out, eps=1e-6)
)
# 池化层
self.pool = nn.MaxPool2d(stride) if stride != 1 else nn.Identity()
self.act = Activation(dim_out, act_num) # 激活函数
def forward(self, x):# 前向传播if self.deploy:x = self.conv(x)else:x = self.conv1(x)x = F.leaky_relu(x, negative_slope=1) # 使用Leaky ReLU激活x = self.conv2(x)x = self.pool(x) # 池化x = self.act(x) # 激活return x
定义VanillaNet模型
class VanillaNet(nn.Module):
def init(self, in_chans=3, num_classes=1000, dims=[96, 192, 384, 768], strides=[2, 2, 2, 1], deploy=False):
super().init()
self.deploy = deploy
# 定义输入层
if self.deploy:
self.stem = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
Activation(dims[0])
)
else:
self.stem1 = nn.Sequential(
nn.Conv2d(in_chans, dims[0], kernel_size=4, stride=4),
nn.BatchNorm2d(dims[0], eps=1e-6),
)
self.stem2 = nn.Sequential(
nn.Conv2d(dims[0], dims[0], kernel_size=1, stride=1),
nn.BatchNorm2d(dims[0], eps=1e-6),
Activation(dims[0])
)
self.stages = nn.ModuleList()for i in range(len(strides)):stage = Block(dim=dims[i], dim_out=dims[i + 1], stride=strides[i], deploy=deploy)self.stages.append(stage) # 添加Block到模型中def forward(self, x):# 前向传播if self.deploy:x = self.stem(x)else:x = self.stem1(x)x = F.leaky_relu(x, negative_slope=1)x = self.stem2(x)for stage in self.stages:x = stage(x) # 依次通过每个Blockreturn x
测试模型
if name == ‘main’:
inputs = torch.randn((1, 3, 640, 640)) # 随机输入
model = VanillaNet() # 创建模型
pred = model(inputs) # 前向传播
print(pred.size()) # 输出预测结果的尺寸
代码说明:
Activation类:定义了一个自定义的激活函数类,包含了权重初始化、前向传播和批归一化的融合功能。
Block类:定义了一个基本的网络模块,包含卷积层、池化层和激活函数。根据是否处于部署模式选择不同的结构。
VanillaNet类:定义了整个网络结构,包括输入层和多个Block的堆叠。支持部署模式和训练模式的切换。
主函数:创建一个随机输入并通过模型进行前向传播,输出结果的尺寸。
这个程序文件 VanillaNet.py 实现了一个名为 VanillaNet 的深度学习模型,主要用于图像处理任务。该模型的设计灵感来源于卷积神经网络(CNN),并包含了一些特定的结构和功能,以提高其性能和灵活性。
首先,文件开头包含版权信息和许可证声明,说明该程序是开源的,可以在 MIT 许可证下进行修改和再分发。
接下来,程序导入了必要的库,包括 PyTorch 和一些用于初始化权重的工具。然后定义了一个名为 activation 的类,继承自 nn.ReLU,用于实现一种自定义的激活函数。这个类在初始化时会创建一个权重参数,并使用批量归一化(Batch Normalization)来稳定训练过程。其 forward 方法根据是否处于部署模式,选择不同的前向传播方式。
接着,定义了一个 Block 类,它是 VanillaNet 的基本构建块。每个 Block 包含多个卷积层和激活函数,可能还包括池化层。该类的 forward 方法实现了数据的前向传播,具体操作包括卷积、激活和池化。Block 类还提供了一个 switch_to_deploy 方法,用于在模型部署时融合批量归一化层,以提高推理速度。
VanillaNet 类是整个模型的核心,包含多个 Block 组成的网络结构。它的初始化方法接收输入通道数、类别数、各层的维度、丢弃率、激活函数数量、步幅等参数。根据这些参数,构建了模型的各个层,并通过 ModuleList 将它们组织在一起。模型的前向传播方法 forward 负责处理输入数据,并通过各个 Block 进行特征提取。
在模型中还定义了一些辅助方法,例如 _init_weights 用于初始化卷积层和线性层的权重,change_act 用于修改激活函数的学习率,switch_to_deploy 用于在部署时优化模型结构。
此外,文件中还定义了一些函数,如 update_weight 用于更新模型的权重,和多个以 vanillanet_ 开头的函数,这些函数用于创建不同配置的 VanillaNet 模型,并支持加载预训练权重。
最后,在 main 部分,程序创建了一个随机输入,并实例化了一个 VanillaNet 模型(具体为 vanillanet_10),然后进行前向传播并打印输出特征的尺寸。
总体来说,这个程序文件实现了一个灵活且可扩展的卷积神经网络模型,适用于多种图像处理任务,并提供了便于使用的接口来创建不同配置的模型。
源码文件

源码获取
欢迎大家点赞、收藏、关注、评论啦 、查看👇🏻获取联系方式👇🏻