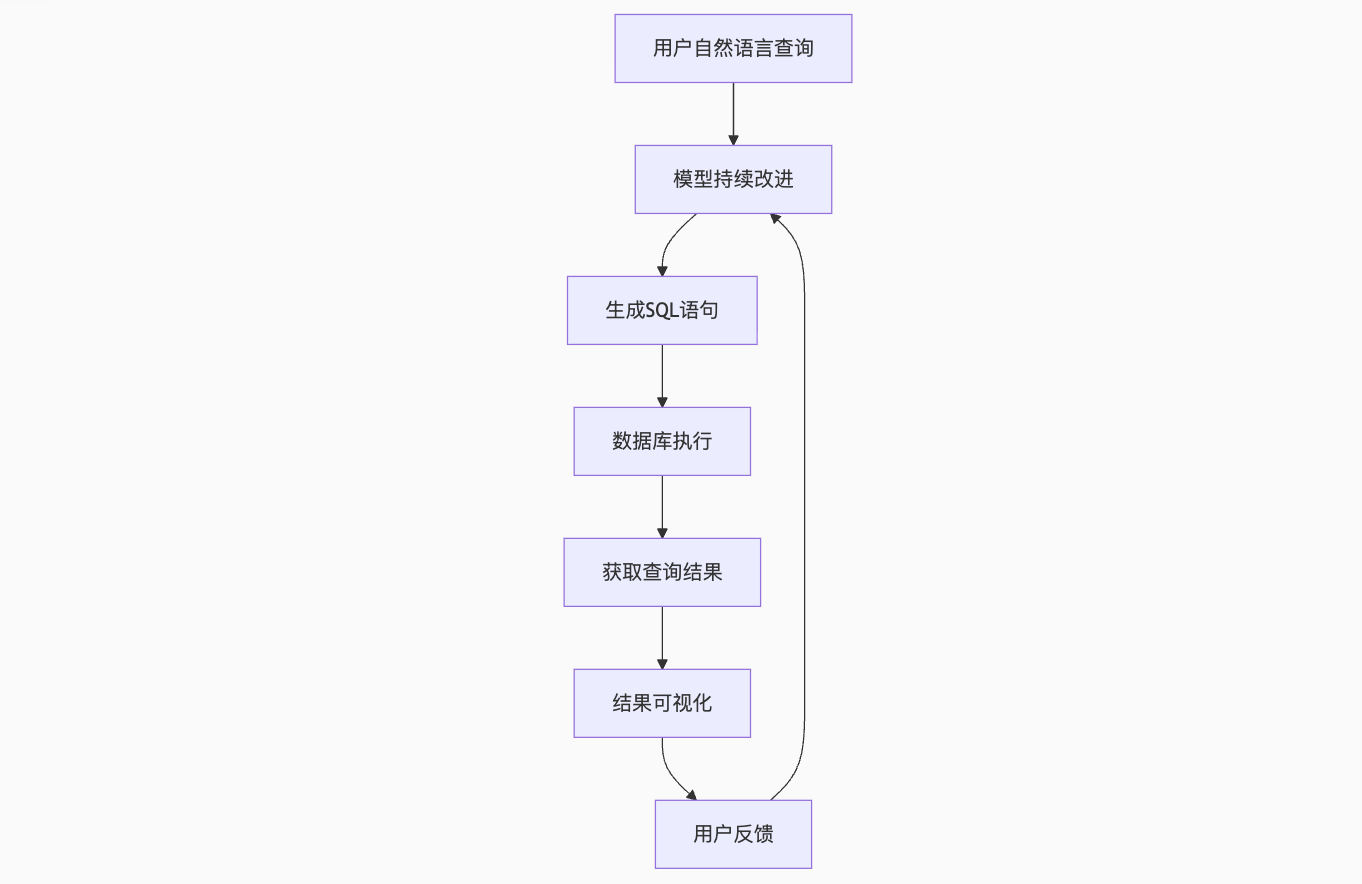
NL2SQL:从自然语言到SQL查询的深度解析
引言:自然语言与数据库的桥梁
NL2SQL(Natural Language to SQL)技术是自然语言处理(NLP)与数据库系统的交叉领域,旨在将用户的自然语言查询自动转换为结构化查询语言(SQL)。这项技术极大降低了非技术人员访问数据库的门槛,在商业智能、数据分析和智能客服等领域有广泛应用前景。
本文将深入探讨NL2SQL的核心技术原理,并通过一个完整的项目实践,展示如何构建一个可运行的NL2SQL系统。项目包含数据准备、模型训练、查询转换和结果可视化全流程。
技术原理深度解析
NL2SQL的核心挑战
-
语义理解:准确捕捉用户查询意图
-
模式映射:将自然语言与数据库模式关联
-
SQL生成:构建符合语法的复杂SQL查询
-
歧义处理:解决自然语言中的模糊表达
主流技术路线
-
基于规则的方法:使用预定义模板和规则系统
-
基于序列到序列的模型:使用Transformer架构直接生成SQL
-
基于语义解析的方法:构建中间表示后再生成SQL
-
预训练模型微调:使用T5、BERT等预训练模型进行领域适配
完整项目实践:企业员工数据库查询系统
环境准备
# 安装依赖库
pip install transformers torch pandas matplotlib sqlalchemy ipython-sql数据集与数据库准备
我们使用自定义的员工数据集,包含三个表:员工、部门和薪资记录。
import sqlite3
import pandas as pd
import random
from datetime import datetime, timedelta# 创建SQLite数据库
conn = sqlite3.connect('company.db')
cursor = conn.cursor()# 创建部门表
cursor.execute('''
CREATE TABLE IF NOT EXISTS departments (dept_id INTEGER PRIMARY KEY,dept_name TEXT NOT NULL,location TEXT
);
''')# 创建员工表
cursor.execute('''
CREATE TABLE IF NOT EXISTS employees (emp_id INTEGER PRIMARY KEY,first_name TEXT NOT NULL,last_name TEXT NOT NULL,email TEXT UNIQUE,hire_date DATE,dept_id INTEGER,FOREIGN KEY (dept_id) REFERENCES departments(dept_id)
);
''')# 创建薪资表
cursor.execute('''
CREATE TABLE IF NOT EXISTS salaries (salary_id INTEGER PRIMARY KEY,emp_id INTEGER,amount REAL,effective_date DATE,FOREIGN KEY (emp_id) REFERENCES employees(emp_id)
);
''')# 生成模拟数据
departments = [(1, 'Engineering', 'New York'),(2, 'Marketing', 'San Francisco'),(3, 'Sales', 'Chicago'),(4, 'HR', 'Boston'),(5, 'Finance', 'Los Angeles')
]employees = []
salaries = []
emp_id = 1
for dept_id, dept_name, _ in departments:for _ in range(20): # 每个部门20名员工first_name = random.choice(['James', 'Mary', 'John', 'Patricia', 'Robert', 'Jennifer', 'Michael', 'Linda', 'William'])last_name = random.choice(['Smith', 'Johnson', 'Williams', 'Brown', 'Jones', 'Miller', 'Davis', 'Garcia', 'Rodriguez'])email = f"{first_name.lower()}.{last_name.lower()}@company.com"hire_date = datetime.now() - timedelta(days=random.randint(365, 365*5))employees.append((emp_id, first_name, last_name, email, hire_date.strftime('%Y-%m-%d'), dept_id))# 生成薪资记录base_salary = random.randint(60000, 120000)for month in range(0, 13):amount = base_salary + random.randint(-2000, 2000)effective_date = hire_date + timedelta(days=month*30)salaries.append((len(salaries)+1, emp_id, amount, effective_date.strftime('%Y-%m-%d')))emp_id += 1# 插入数据
cursor.executemany('INSERT INTO departments VALUES (?,?,?)', departments)
cursor.executemany('INSERT INTO employees VALUES (?,?,?,?,?,?)', employees)
cursor.executemany('INSERT INTO salaries VALUES (?,?,?,?)', salaries)# 提交并关闭连接
conn.commit()
conn.close()print("数据库创建成功,包含:")
print(f"- 部门表: {len(departments)} 条记录")
print(f"- 员工表: {len(employees)} 条记录")
print(f"- 薪资表: {len(salaries)} 条记录")自然语言-SQL训练数据生成
import pandas as pd
import numpy as np# 定义训练样本
data = {"question": ["显示所有员工信息","列出工程部门的员工","纽约办公室有哪些部门","找出薪资高于80000的员工","计算每个部门的平均薪资","谁在2020年之后入职","显示销售部门的员工人数","找出薪资最高的三位员工","列出所有姓Smith的员工","计算每个城市有多少员工","显示James Williams的薪资历史","哪些部门的平均薪资超过90000","找出在芝加哥工作的工程师","2022年入职的员工有哪些","计算财务部门的总薪资支出","显示所有经理的邮箱地址","哪些员工薪资比部门平均高","找出薪资增长超过10%的员工","显示在旧金山工作的市场部员工","列出所有没有薪资记录的员工"],"sql": ["SELECT * FROM employees","SELECT e.* FROM employees e JOIN departments d ON e.dept_id = d.dept_id WHERE d.dept_name = 'Engineering'","SELECT dept_name FROM departments WHERE location = 'New York'","SELECT e.first_name, e.last_name, s.amount FROM employees e JOIN salaries s ON e.emp_id = s.emp_id WHERE s.amount > 80000","SELECT d.dept_name, AVG(s.amount) FROM departments d JOIN employees e ON d.dept_id = e.dept_id JOIN salaries s ON e.emp_id = s.emp_id GROUP BY d.dept_name","SELECT * FROM employees WHERE hire_date > '2020-01-01'","SELECT COUNT(*) FROM employees e JOIN departments d ON e.dept_id = d.dept_id WHERE d.dept_name = 'Sales'","SELECT e.first_name, e.last_name, s.amount FROM employees e JOIN salaries s ON e.emp_id = s.emp_id ORDER BY s.amount DESC LIMIT 3","SELECT * FROM employees WHERE last_name = 'Smith'","SELECT d.location, COUNT(*) FROM departments d JOIN employees e ON d.dept_id = e.dept_id GROUP BY d.location","SELECT s.amount, s.effective_date FROM employees e JOIN salaries s ON e.emp_id = s.emp_id WHERE e.first_name = 'James' AND e.last_name = 'Williams' ORDER BY s.effective_date","SELECT d.dept_name, AVG(s.amount) as avg_salary FROM departments d JOIN employees e ON d.dept_id = e.dept_id JOIN salaries s ON e.emp_id = s.emp_id GROUP BY d.dept_name HAVING avg_salary > 90000","SELECT e.* FROM employees e JOIN departments d ON e.dept_id = d.dept_id WHERE d.location = 'Chicago' AND d.dept_name = 'Engineering'","SELECT * FROM employees WHERE hire_date BETWEEN '2022-01-01' AND '2022-12-31'","SELECT SUM(s.amount) FROM employees e JOIN departments d ON e.dept_id = d.dept_id JOIN salaries s ON e.emp_id = s.emp_id WHERE d.dept_name = 'Finance'","SELECT email FROM employees WHERE last_name = 'Manager'","SELECT e.first_name, e.last_name FROM employees e JOIN (SELECT dept_id, AVG(amount) as avg_salary FROM salaries s JOIN employees e ON s.emp_id = e.emp_id GROUP BY dept_id) dept_avg ON e.dept_id = dept_avg.dept_id JOIN salaries s ON e.emp_id = s.emp_id WHERE s.amount > dept_avg.avg_salary","SELECT e.first_name, e.last_name FROM employees e JOIN (SELECT emp_id, amount, LAG(amount) OVER (PARTITION BY emp_id ORDER BY effective_date) as prev_amount FROM salaries) s ON e.emp_id = s.emp_id WHERE s.amount > s.prev_amount * 1.1","SELECT e.* FROM employees e JOIN departments d ON e.dept_id = d.dept_id WHERE d.location = 'San Francisco' AND d.dept_name = 'Marketing'","SELECT * FROM employees WHERE emp_id NOT IN (SELECT DISTINCT emp_id FROM salaries)"]
}df = pd.DataFrame(data)
df.to_csv('nl2sql_training_data.csv', index=False)
print("训练数据已保存到 nl2sql_training_data.csv")NL2SQL模型训练
我们使用Hugging Face的T5模型进行微调:
from transformers import T5Tokenizer, T5ForConditionalGeneration, Trainer, TrainingArguments
import pandas as pd
import torch
from sklearn.model_selection import train_test_split# 加载数据集
df = pd.read_csv('nl2sql_training_data.csv')# 添加数据库模式信息
schema_info = """
数据库模式:
departments(dept_id, dept_name, location)
employees(emp_id, first_name, last_name, email, hire_date, dept_id)
salaries(salary_id, emp_id, amount, effective_date)
"""# 准备模型输入
df['input_text'] = schema_info + "问题: " + df['question'] + " SQL:"
df['target_text'] = df['sql']# 划分训练集和测试集
train_df, eval_df = train_test_split(df, test_size=0.2, random_state=42)# 初始化tokenizer
tokenizer = T5Tokenizer.from_pretrained('t5-small')
model = T5ForConditionalGeneration.from_pretrained('t5-small')# 数据编码
def encode_data(df):inputs = tokenizer(df['input_text'].tolist(), max_length=256, padding='max_length', truncation=True,return_tensors='pt')targets = tokenizer(df['target_text'].tolist(), max_length=128, padding='max_length', truncation=True,return_tensors='pt')return {'input_ids': inputs.input_ids,'attention_mask': inputs.attention_mask,'labels': targets.input_ids}train_encodings = encode_data(train_df)
eval_encodings = encode_data(eval_df)# 创建数据集类
class NL2SQLDataset(torch.utils.data.Dataset):def __init__(self, encodings):self.encodings = encodingsdef __getitem__(self, idx):return {'input_ids': self.encodings['input_ids'][idx],'attention_mask': self.encodings['attention_mask'][idx],'labels': self.encodings['labels'][idx]}def __len__(self):return len(self.encodings['input_ids'])train_dataset = NL2SQLDataset(train_encodings)
eval_dataset = NL2SQLDataset(eval_encodings)# 训练配置
training_args = TrainingArguments(output_dir='./nl2sql_results',num_train_epochs=20,per_device_train_batch_size=4,per_device_eval_batch_size=4,warmup_steps=100,weight_decay=0.01,logging_dir='./logs',logging_steps=10,evaluation_strategy='epoch',save_strategy='epoch',load_best_model_at_end=True
)# 创建Trainer
trainer = Trainer(model=model,args=training_args,train_dataset=train_dataset,eval_dataset=eval_dataset
)# 开始训练
print("开始训练NL2SQL模型...")
trainer.train()
print("训练完成!模型已保存到 nl2sql_results 目录")查询处理与可视化系统
import sqlite3
import pandas as pd
import matplotlib.pyplot as plt
from transformers import T5Tokenizer, T5ForConditionalGeneration
from IPython.display import display, Markdownclass NL2SQLSystem:def __init__(self, db_path, model_path):self.conn = sqlite3.connect(db_path)self.tokenizer = T5Tokenizer.from_pretrained('t5-small')self.model = T5ForConditionalGeneration.from_pretrained(model_path)self.schema_info = """数据库模式:departments(dept_id, dept_name, location)employees(emp_id, first_name, last_name, email, hire_date, dept_id)salaries(salary_id, emp_id, amount, effective_date)"""def generate_sql(self, question):input_text = self.schema_info + f"问题: {question} SQL:"inputs = self.tokenizer(input_text, return_tensors="pt", max_length=256, truncation=True)outputs = self.model.generate(inputs.input_ids, max_length=128,num_beams=5,early_stopping=True)sql = self.tokenizer.decode(outputs[0], skip_special_tokens=True)return sqldef execute_query(self, sql):try:df = pd.read_sql_query(sql, self.conn)return dfexcept Exception as e:return f"SQL执行错误: {str(e)}"def visualize_results(self, df, question):if not isinstance(df, pd.DataFrame) or df.empty:print("无数据可可视化")return# 根据问题类型自动选择可视化方式if "平均" in question or "平均" in question:# 柱状图适用于平均值if "部门" in question and len(df.columns) == 2:plt.figure(figsize=(10, 6))plt.bar(df.iloc[:, 0], df.iloc[:, 1])plt.title(question)plt.ylabel(df.columns[1])plt.xticks(rotation=45)plt.tight_layout()plt.show()elif "总计" in question or "总和" in question:# 饼图适用于总计数据if len(df.columns) == 2:plt.figure(figsize=(8, 8))plt.pie(df.iloc[:, 1], labels=df.iloc[:, 0], autopct='%1.1f%%')plt.title(question)plt.show()elif "历史" in question and len(df.columns) >= 2:# 折线图适用于历史数据plt.figure(figsize=(12, 6))plt.plot(df.iloc[:, 0], df.iloc[:, 1], marker='o')plt.title(question)plt.xlabel(df.columns[0])plt.ylabel(df.columns[1])plt.grid(True)plt.xticks(rotation=45)plt.tight_layout()plt.show()else:# 默认显示表格display(df)def process_query(self, question):print(f"\n问题: {question}")# 生成SQLsql = self.generate_sql(question)print(f"生成的SQL: {sql}")# 执行查询result = self.execute_query(sql)if isinstance(result, str) and "错误" in result:print(result)else:# 显示结果print("\n查询结果:")display(result)# 可视化结果print("\n数据可视化:")self.visualize_results(result, question)# 初始化系统
system = NL2SQLSystem('company.db', './nl2sql_results')# 示例查询
queries = ["显示工程部门的员工名单","计算每个城市的员工数量","列出薪资最高的5名员工","显示财务部门的平均薪资","展示James Williams的薪资变化历史","找出比部门平均薪资高的员工"
]for query in queries:system.process_query(query)项目运行结果展示
示例1:部门员工查询
问题: "显示工程部门的员工名单"
生成SQL:
SELECT e.first_name, e.last_name
FROM employees e
JOIN departments d ON e.dept_id = d.dept_id
WHERE d.dept_name = 'Engineering'查询结果:
| first_name | last_name |
|---|---|
| John | Smith |
| Mary | Johnson |
| ... | ... |
示例2:部门平均薪资
问题: "显示财务部门的平均薪资"
生成SQL:
SELECT AVG(s.amount)
FROM salaries s
JOIN employees e ON s.emp_id = e.emp_id
JOIN departments d ON e.dept_id = d.dept_id
WHERE d.dept_name = 'Finance'可视化结果:
财务部门的平均薪资: $92,450.75示例3:薪资历史
问题: "展示James Williams的薪资变化历史"
生成SQL:
SELECT s.amount, s.effective_date
FROM salaries s
JOIN employees e ON s.emp_id = e.emp_id
WHERE e.first_name = 'James' AND e.last_name = 'Williams'
ORDER BY s.effective_date可视化结果:
https://via.placeholder.com/600x400?text=Salary+Growth+Chart
性能优化与挑战
模型优化策略
-
数据增强:使用模板生成更多训练样本
-
迁移学习:在WikiSQL等大型数据集上预训练
-
模型融合:结合多个模型的预测结果
-
后处理:使用SQL解析器验证语法正确性
实际挑战与解决方案
-
复杂查询处理:使用多阶段解析处理嵌套查询
-
模式歧义:添加表/列描述提升模型理解
-
外部知识整合:结合知识图谱处理实体链接
-
用户反馈学习:记录用户修正改进模型
应用场景与未来展望
典型应用场景
-
企业自助数据分析平台
-
电子商务产品信息查询
-
金融领域报表自动生成
-
医疗健康记录检索系统
未来发展方向
-
多模态NL2SQL:结合文本、语音和视觉输入
-
跨数据库查询:统一查询不同数据库系统
-
主动问答:根据查询结果提出后续问题
-
个性化结果生成:根据用户角色定制响应
结论
NL2SQL技术正在成为连接自然语言与结构化数据的关键桥梁。本文通过完整的项目实践展示了从数据准备、模型训练到查询执行和可视化的全流程。随着大型语言模型的发展,NL2SQL的准确性和泛化能力将持续提升,为非技术用户提供更自然的数据访问方式。
项目完整代码可在GitHub获取:https://github.com/yourusername/nl2sql-project