视觉语言导航(12)——LLM-VLN 4.2
这是课上做的笔记,因此很多记得比较急,之后会逐步完善,每节课的逻辑流程写在大纲部分。
传统VLN的问题

新的认知核心-LLM
旧范式是预训练+模仿学习+深度学习,预训练是积累通用经验,模仿学习是在领域内快速预热学习,遇到未知情况还得看深度学习。
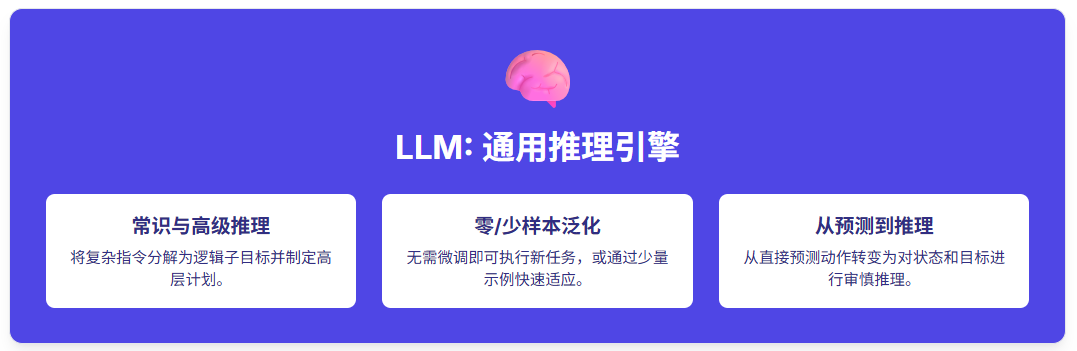


LLM的在VLN的牛逼技能
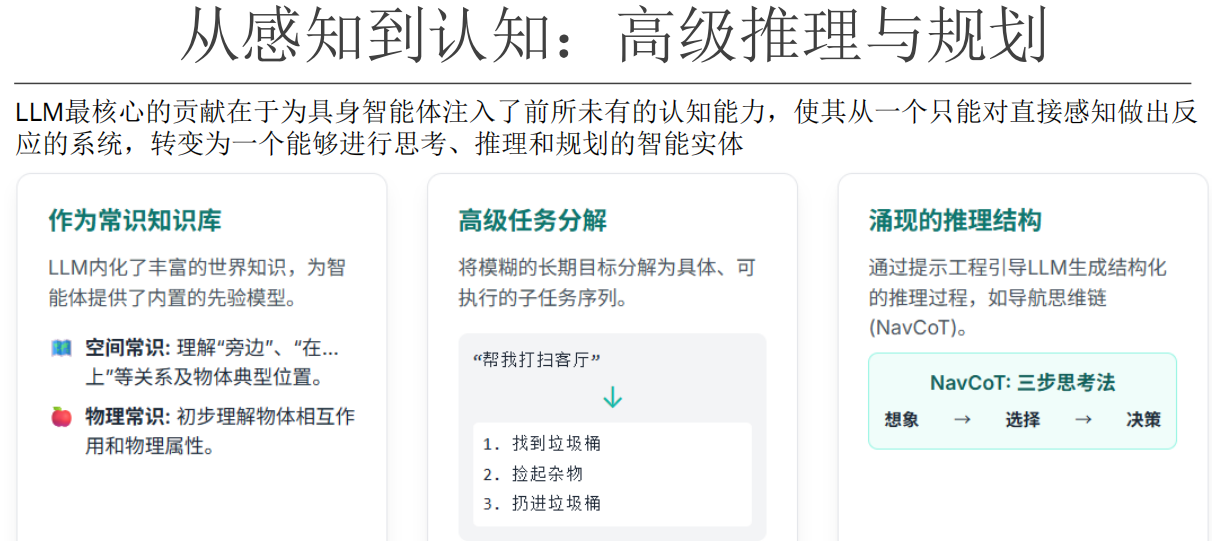

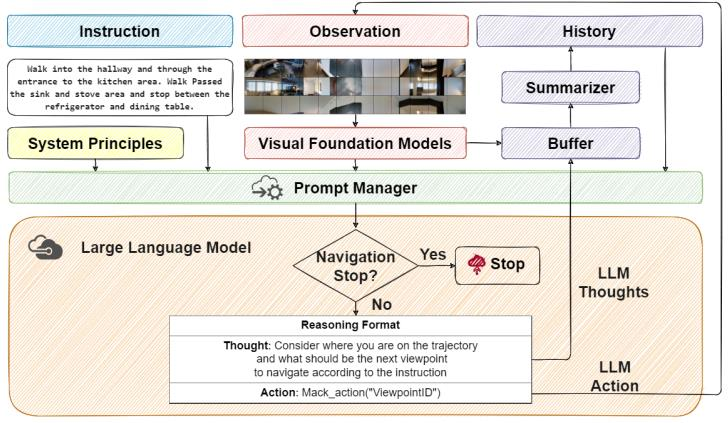
NavGPT架构
NavGPT的核心想法是,通过扩大模型规模而“涌现”出的大型语言模型(LLM)的巨大常识和推理 能力,可以直接应用于像VLN这样的具身任务,而无需任何针对性的任务训练或微调
NavGPT模块化架构
NavGPT是一个模块化系统,它在一个LLM内部协同了推理(Thoughts)和决策(Actions) 。它遵循经典的导航系统原则,通过一系列辅助模块与环境交互,整个过程由一个提示管理器(prompt manager)来协调
优缺点
NavGPT中的提示工程

NavGPT的延申

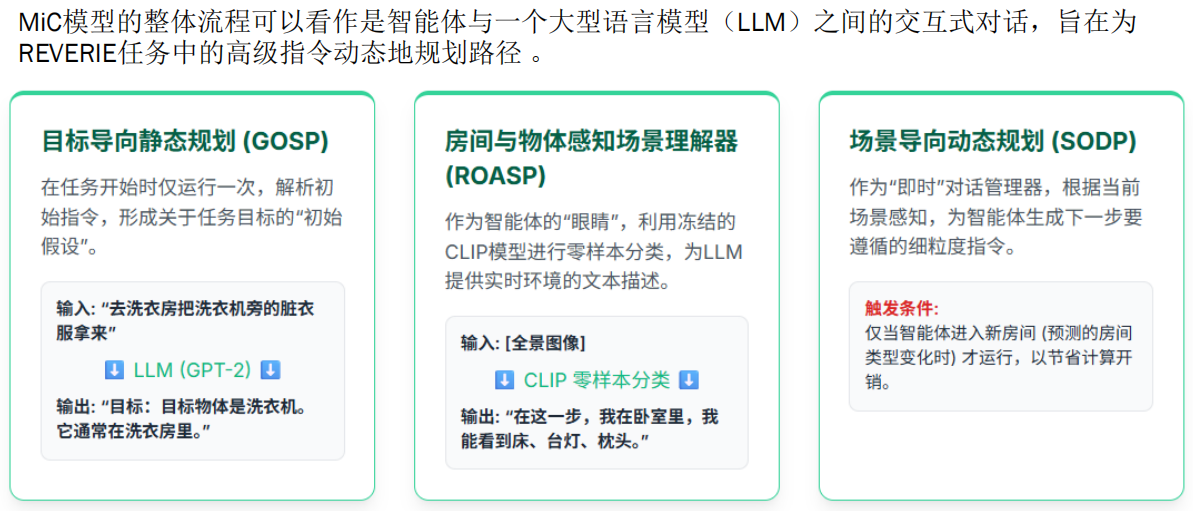
March in Chat(MIC)架构(源于REVERIE交互式)
MIC交互模块刨析
- 用户发出指令:“去洗衣房把洗衣机旁的脏衣服拿来。”
- GOSP 解析指令:LLM 确定目标是洗衣机旁的脏衣服,通常位于洗衣房。
- 智能体开始移动:智能体从当前位置出发,进入第一个房间(假设是卧室)。
- ROASP 场景理解:智能体获取卧室的全景图像,CLIP 模型识别出床、台灯、枕头等物体,生成文本描述:“在这一步,我在卧室里,我能看到床、台灯、枕头。”
- SODP 动态规划:LLM 根据卧室的描述和目标洗衣房的位置,生成指令:“向前走两步,然后左转进入走廊。”
- 智能体继续移动:智能体按照指令移动到走廊,再进入下一个房间(假设是洗衣房)。
- ROASP 再次场景理解:智能体获取洗衣房的全景图像,生成新的环境描述。
- SODP 继续规划:LLM 根据洗衣房的描述,生成指令:“靠近洗衣机,找到旁边的脏衣服。”
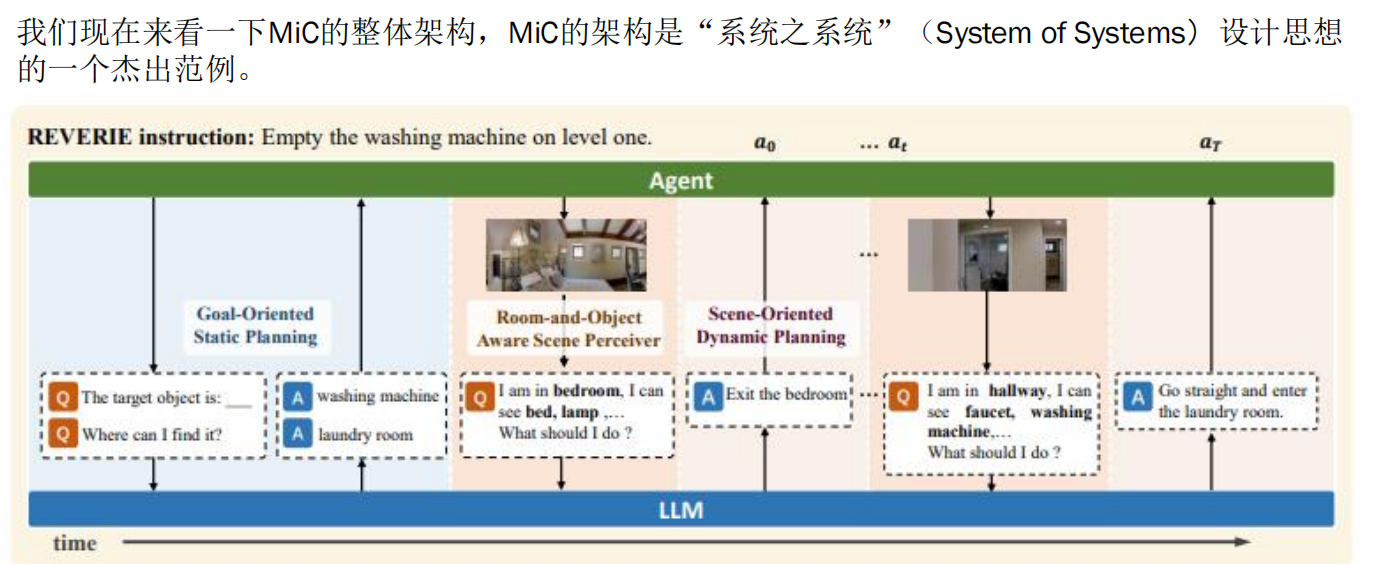
三大模块交互处理流程

1. 场景感知 (Textpercept)
目的:将LLM的推理“锚定”在当前真实环境中。
来源:来自ROASP(房间与物体感知场景理解器)模块。
内容:
- 当前环境描述:通过ROASP模块提供的实时环境文本描述,包括智能体所在的具体位置(如卧室、厨房等)、周围的物体(如床、台灯、枕头等)。
- 作用:让LLM能够准确地理解当前所处的物理环境,从而做出基于现实情况的决策和规划。
示例:
在这一步,我在卧室里,我能看到床、台灯、枕头。2. 动态选择的演示 (Dstep)
目的:为LLM提供高质量的规划参考。
来源:从FGR2R数据集中挑选语义最相似的规划范例。
内容:
- 历史规划案例:从FGR2R(Follow, Generate, Reason and Repeat)数据集中选取与当前任务和环境最为相似的历史规划案例。
- 作用:通过展示类似情境下的成功规划步骤,帮助LLM学习如何在当前情况下进行有效的路径规划和决策。
示例:
当目标是去洗衣房拿脏衣服时,一个成功的规划是:先从卧室走到走廊,然后进入洗衣房,在洗衣机旁边找到脏衣服。3. 任务与历史 (TextTask)
目的:提醒LLM总体目标和已执行计划,确保规划的连贯性。
内容:
- 任务目标:明确当前任务的最终目标,例如“去洗衣房把洗衣机旁的脏衣服拿来”。
- 已执行计划:回顾之前已经完成的步骤和行动,帮助LLM保持对任务进展的连续认知。
- 作用:确保LLM在生成新的规划步骤时,能够考虑到任务的整体目标和已完成的部分,避免偏离方向或重复操作。
示例:
任务目标:去洗衣房把洗衣机旁的脏衣服拿来。
已执行计划:从卧室走到走廊,进入洗衣房。DUET 的工作流程
指令解析与初始假设:
- GOSP 模块解析原始指令,形成关于任务目标的“初始假设”,生成静态规划信息 WGWG。
环境感知与场景理解:
- ROASP 模块获取当前环境的全景图像,生成实时环境的文本描述,为后续动态规划提供依据。
动态路径规划与指令生成:
- SODP 模块根据当前环境感知和任务目标,生成细粒度的动态规划信息 WSWS。
指令整合与执行:
- 将原始指令 WIWI、静态规划 WGWG 和动态规划 WSWS 整合成一条统一的指令字符串 WW。
- DUET 导航策略模块接收 WW 作为输入,指导智能体执行具体的导航动作。
在多模态交互系统(MIC)中,DUET导航模块作为核心组件之一,与GOSP(目标导向静态规划)、ROASP(基于观察的场景文本生成)和SODP(场景导向动态规划)模块紧密合作,共同完成复杂的导航任务。以下是这些组件如何协同工作的概述:
目标导向静态规划 (GOSP):这个模块负责解析原始指令,并根据任务目标和先验知识生成初步的路径规划信息。它为智能体提供了一个大致的方向和预期路径,帮助其快速接近目标区域。
基于观察的场景文本生成 (ROASP):此模块通过获取当前环境的全景图像,生成实时环境的文本描述。这些描述为动态规划提供了必要的环境信息,确保智能体能够根据实际场景做出正确的决策。
场景导向动态规划 (SODP):利用ROASP提供的环境感知信息和GOSP的目标指引,SODP模块生成细粒度的行动指令,使智能体能够灵活应对环境变化并高效地朝目标前进。
DUET导航模块:整合了来自GOSP、ROASP和SODP的信息,形成统一的指令字符串,指导智能体执行具体的导航动作。它不仅考虑了原始的任务目标,还结合了静态和动态规划的结果,以提高导航过程中的灵活性和鲁棒性。

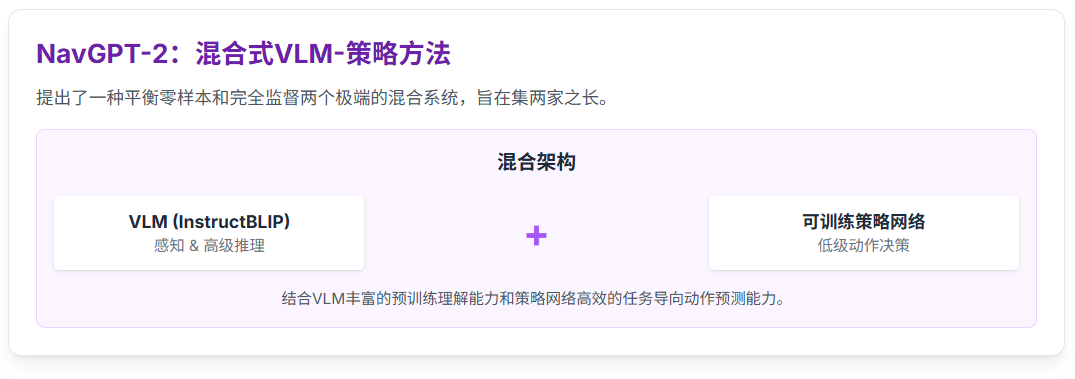
NavGPT与MIC的优势

MIC的问题在于,用了对话机制,因此整合了多个模块,流程长,且中间变量多,容易积累误差,产生领域鸿沟。
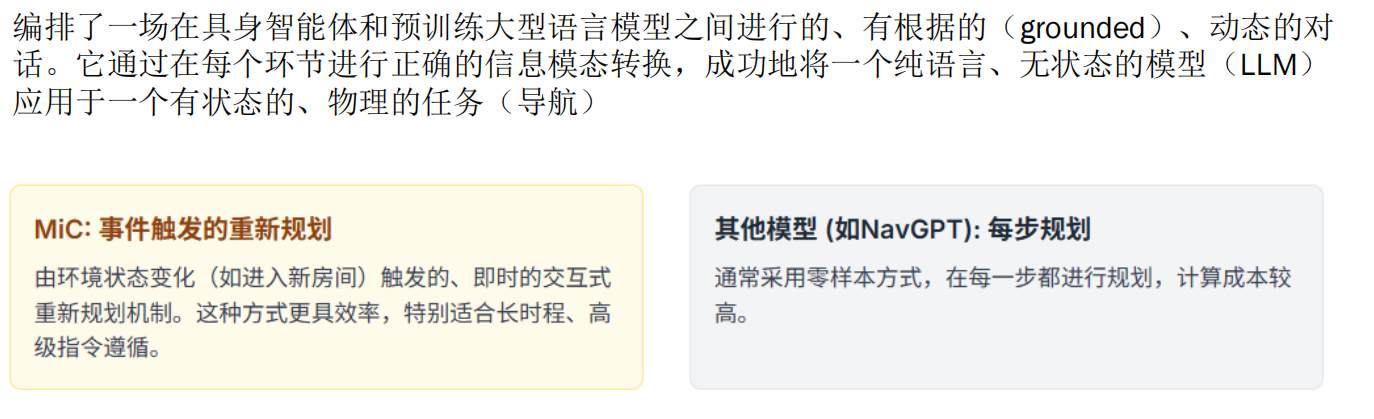
Navid——摒弃中间表征的端到端模型

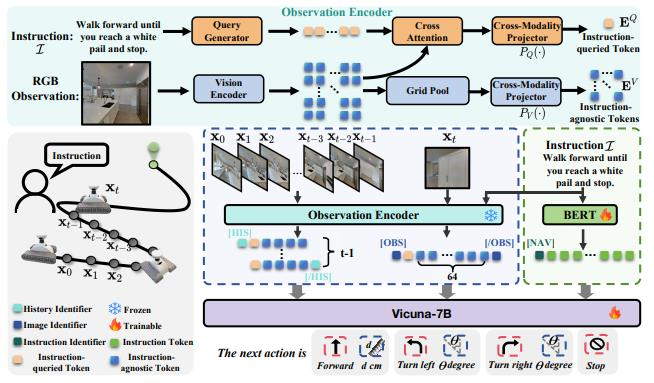
在 Navid 模型中,对于每一帧图像生成的两种类型的视觉令牌(token)——指令无关 token 和指令查询 token——是通过不同的机制得到的。让我们详细解释一下这两种 token 的生成过程。
1. 指令无关 token
定义:通用的视觉特征,代表图像的整体内容,捕捉“场景中有什么”。
生成方式:
输入图像编码:
- 首先,将当前帧的图像输入到一个预训练的视觉编码器(如 Vision Transformer 或 ResNet)。这个编码器会提取图像中的基本特征,比如颜色、形状、纹理等。
- 视觉编码器输出一系列特征向量,这些向量可以看作是对图像不同部分的描述。
网格池化(Grid Pooling):
- 这些特征向量会被进一步处理,通常通过网格池化的方式,将图像分成多个小块(例如 8x8 的网格),每个小块对应一个特征向量。
- 这样做的目的是为了保留图像的空间结构信息,同时减少计算复杂度。
生成指令无关 token:
- 从这些特征向量中选择或聚合出一组代表图像整体内容的 token。例如,每帧图像可能生成 64 个这样的 token。
- 这些 token 不依赖于具体的任务指令,只关注图像本身的内容,因此被称为“指令无关 token”。
2. 指令查询 token
定义:通过交叉注意力生成,代表场景中与指令最相关的部分,捕捉“任务中什么最重要”。
生成方式:
指令编码:
- 将任务指令(如“向前走直到看到白色的桶”)输入到一个文本编码器(如 BERT),生成指令的特征向量。
- 这些特征向量包含了指令的语义信息。
交叉注意力机制:
- 将指令的特征向量与图像的特征向量一起输入到交叉注意力模块。
- 交叉注意力模块的作用是让模型能够关注图像中与指令最相关的信息。例如,如果指令提到“白色桶”,模型会特别注意图像中的白色物体。
- 通过交叉注意力机制,模型可以动态地调整对图像不同部分的关注程度。
生成指令查询 token:
- 根据交叉注意力的结果,从图像特征中提取出一组与指令最相关的 token。例如,每帧图像可能生成 4 个这样的 token。
- 这些 token 被称为“指令查询 token”,因为它们是根据具体任务指令来选择和生成的。
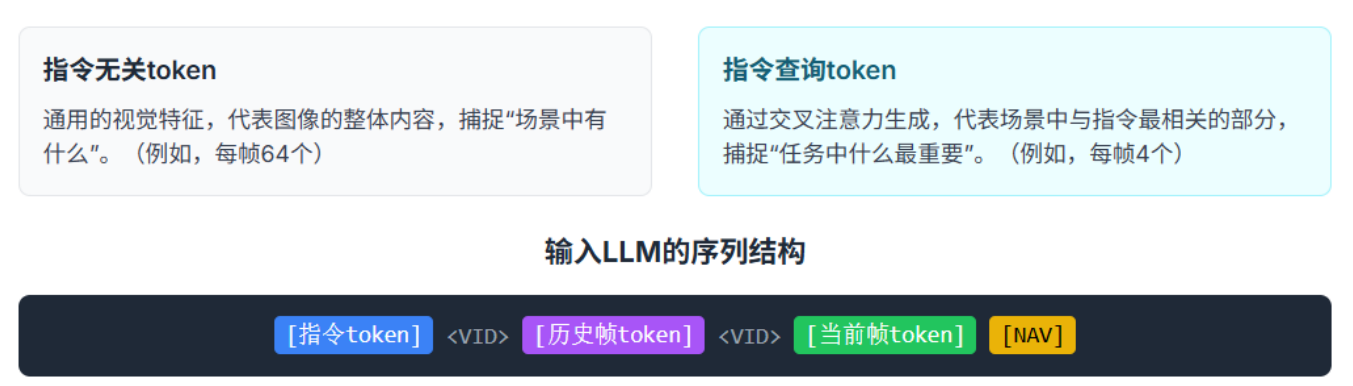
3. 输入 LLM 的序列结构
在生成了上述两种 token 后,它们会被组织成一个序列,作为输入传递给下游的语言模型(LLM),如 Vicuna-7B。这个序列的结构如下:
[指令 token] <VID> [历史帧 token] <VID> [当前帧 token] [NAV]- [指令 token]:表示任务指令的特征向量。
- <VID>:分隔符,用于区分不同的 token 类型。
- [历史帧 token]:之前帧的指令无关 token,用于提供历史信息。
- [当前帧 token]:当前帧的指令无关 token 和指令查询 token,用于提供当前环境的信息。
- [NAV]:导航相关的特殊 token,指示模型需要做出导航决策。
总结
- 指令无关 token 是通过对图像进行通用的特征提取和网格池化得到的,它们不依赖于具体的任务指令,只关注图像本身的内容。
- 指令查询 token 是通过将图像特征与任务指令结合,利用交叉注意力机制生成的,它们捕捉了图像中与任务最相关的信息。
- 这两种 token 被组织成一个序列,作为输入传递给语言模型,帮助模型做出更准确的导航决策。
训练流程

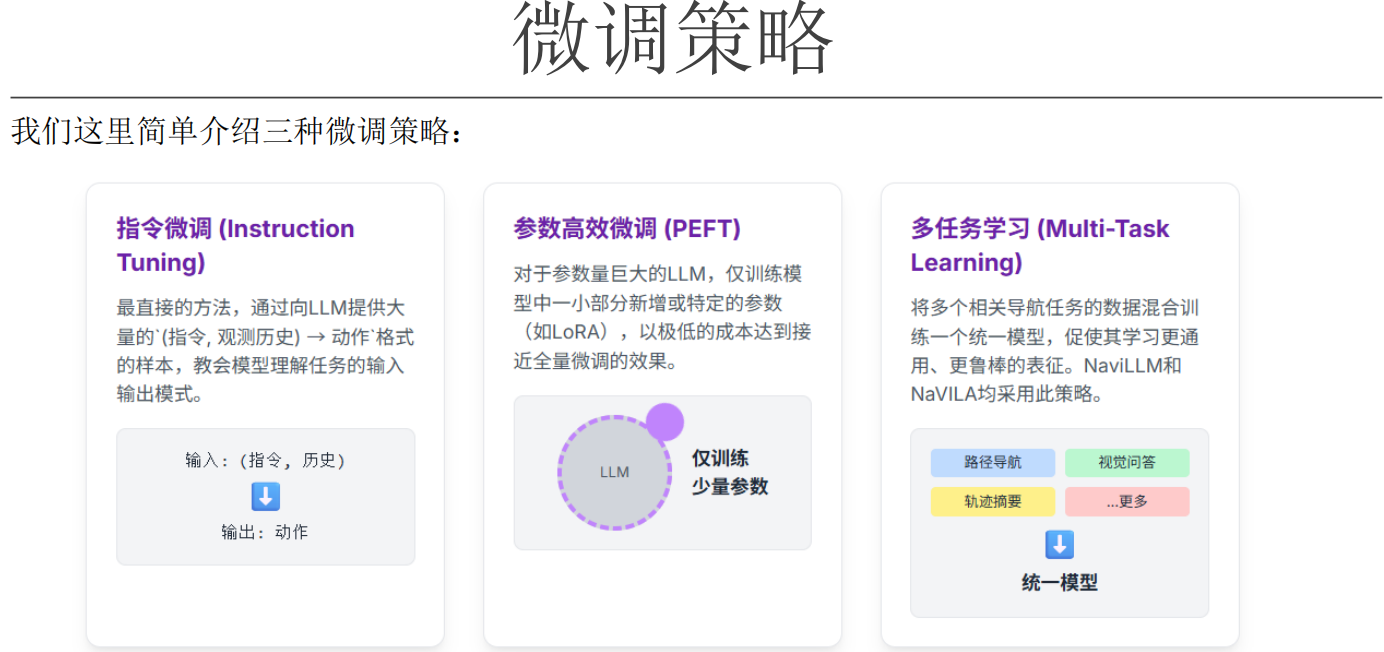
微调策略
为了让机器人适应具体的导航环境,需要微调
关键挑战和策略
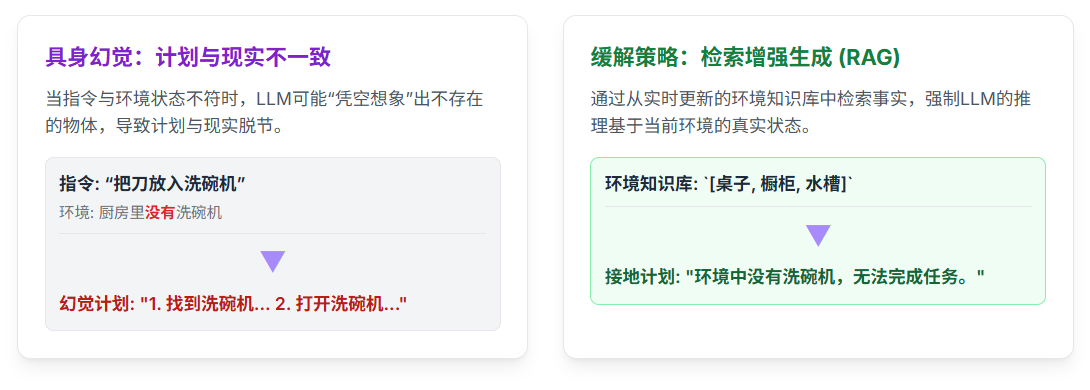
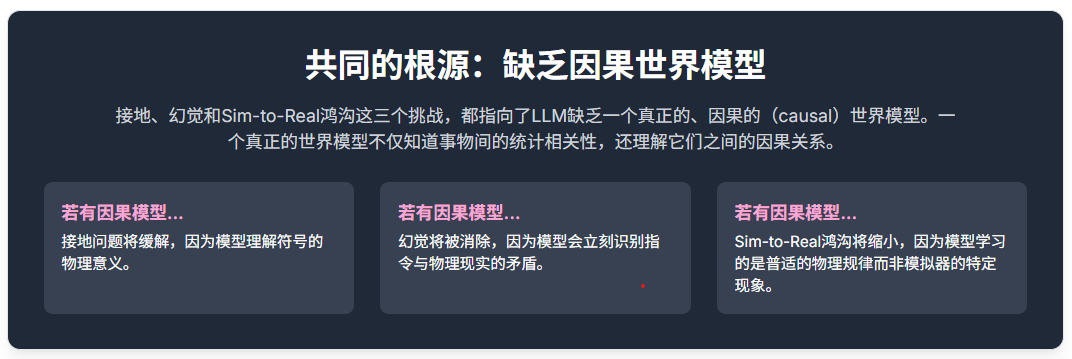
接地问题

幻觉问题
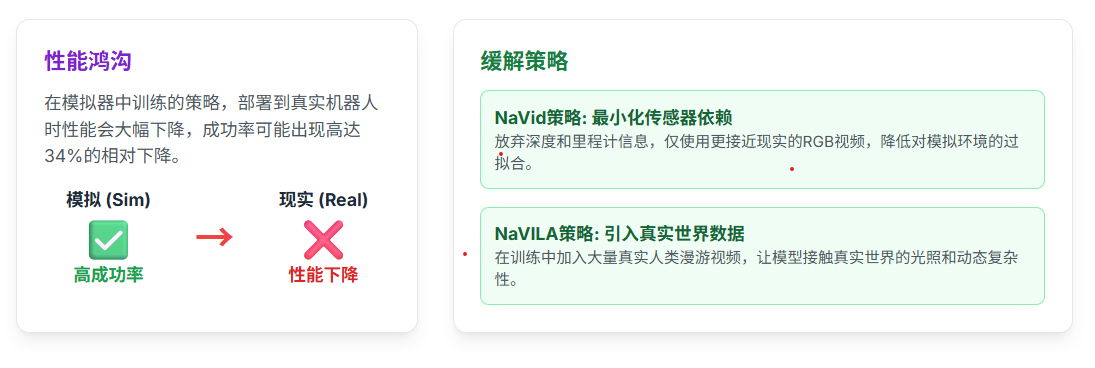
Sim-to-Real Gap(端到端秒了)
模拟到现实的鸿沟(Sim-to-Real Gap)是机器人学中一个长期存在的难题。在模拟器中训练的策略,在部署到真实机器人上时性能往往会大幅下降,原因在于模拟环境与真实世界在物理引擎、视觉渲染、传感器噪声等方面存在无法避免的差异。
未来展望