数据清洗(Data Cleansing)新手教学简单易懂(缺失值、异常值、重复数据、不一致数据、格式问题),附实战案例
数据清洗(Data Cleaning)详解
一、什么是数据清洗
数据清洗(Data Cleaning,又称 Data Cleansing 或 Data Scrubbing)是数据预处理中的核心环节。它的目标是 识别并修正数据中的错误、不一致或缺失部分,以提高数据质量,从而为后续的数据分析、建模和机器学习提供可靠基础。
在真实场景中,原始数据往往存在以下问题:
缺失值:例如某些用户没有填写邮箱或年龄。
异常值:某条记录的年龄为 200 岁,或工资为负数。
重复数据:同一用户被录入多次。
不一致数据:如性别字段中同时出现
M、male、男。格式问题:日期格式混乱,如
2025/08/18与18-08-2025混用。
如果不进行清洗,分析结果可能会严重偏差。
二、数据清洗的常见步骤
1. 缺失值处理
缺失值是最常见问题。处理方式包括:
删除法:直接删除包含缺失值的行或列(适合缺失率高的情况)。
填充法:用均值、中位数、众数或插值方法补全。
模型预测:使用机器学习算法预测缺失值。
| 方法 | 说明 | 适用场景 | 优缺点 |
|---|---|---|---|
| 删除法 | 直接删除包含缺失值的行或列 | 当缺失值比例较高,且该行/列对整体分析影响不大时 | ✅ 简单快速;❌ 可能丢失有用信息 |
| 填充法 | 用均值、中位数、众数或插值方法补全 | 当缺失值比例较小,且数据分布规律明显时 | ✅ 保留更多数据;❌ 可能引入偏差 |
| 模型预测 | 使用机器学习模型(如 KNN、回归)预测缺失值 (将其他完整的列作为特征,缺失值的列作为标签,进行训练预测) | 当数据复杂、缺失值对结果影响较大时 | ✅ 填充值更合理;❌ 计算复杂度高,需额外建模 |
示例(Pandas):
import pandas as pd
import numpy as np# 构造样例数据
df = pd.DataFrame({"姓名": ["张三", "李四", "王五", "赵六"],"年龄": [25, np.nan, 30, 28],"工资": [5000, 6000, None, 8000]
})# 缺失值填充
df["年龄"].fillna(df["年龄"].mean(), inplace=True) # 用均值填充
df["工资"].fillna(df["工资"].median(), inplace=True) # 用中位数填充
1. 函数作用
在 Pandas 中,
fillna()用于 填充缺失值 (NaN)。
常见于DataFrame或Series对象,用来替换空值,使数据更加完整。
2. 基本语法
DataFrame.fillna(value=None, method=None, axis=None, inplace=False, limit=None, downcast=None)
3. 参数解析
参数 说明 value 用于替换缺失值的值,可以是标量、字典或 Series。例如 df.fillna(0),所有 NaN 填充为 0。method 采用插值法填充:
-ffill(前向填充):用前一个非 NaN 值填充
-bfill(后向填充):用后一个非 NaN 值填充axis 填充方向:
-0或'index'(按列填充)
-1或'columns'(按行填充)inplace 是否在原对象上直接修改:
-False(默认,返回新对象)
-True(直接修改原对象,不返回)limit 限制填充的次数。例如 limit=1只填充一次缺失值,剩下的保留 NaN。downcast 尝试将填充值转换为合适的更小的数据类型,比如从 float64转成int32。
2. 异常值检测与处理
异常值会严重影响模型。常见方法:
箱线图法(IQR):利用四分位距检测异常值。
Z-Score 方法:根据数据分布的标准差判断。
逻辑规则:如年龄不能小于 0,工资不可能为负数。
示例(Z-Score):
from scipy import stats# 检测工资异常值
z_scores = stats.zscore(df["工资"])
df = df[(abs(z_scores) < 3)] # 保留 |Z|<3 的数据
3. 重复数据处理
重复记录会影响统计和建模,常用方法:
# 删除重复行
df = df.drop_duplicates()
4. 数据标准化与一致化
实际数据可能存在不同的表示方法:
性别字段:
M/F、男/女、1/0。日期字段:
2025-08-18、2025/8/18。
处理方式:
# 性别字段统一
df["性别"] = df["性别"].replace({"男": "M", "女": "F"})
5. 数据格式规范化
确保数据类型正确:
# 转换日期字段
df["日期"] = pd.to_datetime(df["日期"], errors="coerce")# 转换数值字段
df["工资"] = pd.to_numeric(df["工资"], errors="coerce")
三、数据清洗在项目中的意义
提升数据质量:减少噪声和偏差。
增强模型性能:机器学习模型对“脏数据”很敏感。
节省分析成本:避免在错误数据上浪费计算和决策。
确保结果可靠:让分析结论更符合业务逻辑。
四、案例:员工数据清洗
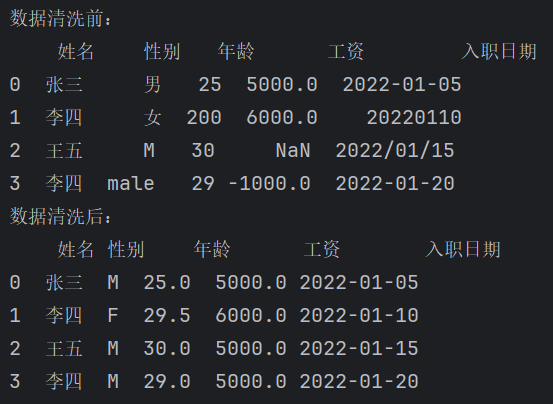
假设我们有一份员工数据,部分字段存在缺失、重复、异常情况。
import pandas as pd
import numpy as npdata = {"姓名": ["张三", "李四", "王五", "李四"],"性别": ["男", "女", "M", "male"],"年龄": [25, 200, 30, 29],"工资": [5000, 6000, None, -1000],"入职日期": ["2022-01-05", "20220110", "2022/01/15", "2022-01-20"]
}df = pd.DataFrame(data)
print("数据清洗前:\n",df)# 1. 缺失值处理
df["工资"].fillna(df["工资"].median(), inplace=True)# 2. 异常值处理(逻辑规则)
df.loc[df["年龄"] > 100, "年龄"] = df["年龄"].median()
df.loc[df["工资"] < 0, "工资"] = df["工资"].median()# 3. 重复数据去重
df = df.drop_duplicates()# 4. 一致化
df["性别"] = df["性别"].replace({"男": "M", "女": "F", "male": "M"})# 5. 日期规范化
df["入职日期"] = pd.to_datetime(df["入职日期"], errors="coerce")print("数据清洗后:\n",df)清洗后,数据更干净,适合后续分析。
五、总结
数据清洗是数据科学和机器学习流程中至关重要的一步。主要目标是 去除噪声、修正错误、统一格式、处理缺失与异常。
在实践中,可以结合 Pandas、NumPy、正则表达式、机器学习算法 等工具,构建自动化的数据清洗流程。
一句话总结:
没有高质量数据,就没有高质量模型。数据清洗是数据分析的第一步,也是最重要的一步。