LeetCode100-438找到字符串中所有的字母异位词
本文基于各个大佬的文章
上点关注下点赞,明天一定更灿烂!

前言
Python基础好像会了又好像没会,所有我直接开始刷leetcode一边抄样例代码一边学习吧。本系列文章用来记录学习中的思考,写给自己看的,也欢迎大家在评论区指导~
您的每一条评论都会让我更有学习的动力。
一、分析题目

异位词,好熟悉的名次,我们好像在哪儿见过。
嗷,在这里。LeetCode100刷题-49字母异位词分组-CSDN博客
二、思路以及代码
这个题目其实可以转化为固定长度窗口问题,固定的长度是p的长度
思路:
1.求出p的长度k,设置此长度为窗口大小
2.从头往后对比,如果当前窗口内的字符串排序之后跟p相同,就记录起始索引;不同就继续往后对比
class Solution:def findAnagrams(self, s: str, p: str) -> List[int]:k=len(p)left=0result=[] #列表记录相同的起始索引if len(s)<k:return []else:for right in range(k,len(s)+1):if p.sorted()==s[left:right].sorted():result.append(left)left+=1return result运行一下试试,出错了。显示错误在sorted函数的使用
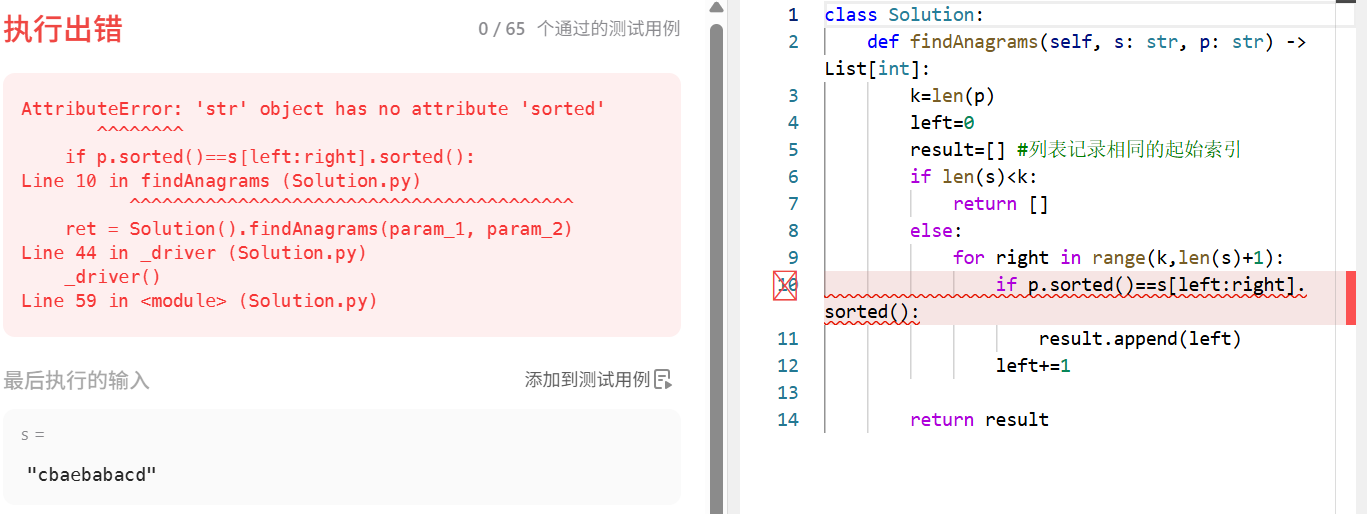
更正一下,sorted(parm)
#if p.sorted()==s[left:right].sorted():更正sort的用法
if sorted(p)==sorted(s[left:right]):很遗憾超时了,虽然结果和思路都是正确的。超时原因应该是每一轮循环都要进行调用sorted函数比较。

优化一下,不用sorted函数,而是记录每个字母在窗口范围内出现的频率,若跟p的一样,则是相同
class Solution:def findAnagrams(self, s: str, p: str) -> List[int]:len_s,len_p=len(s),len(p)if len_s<len_p:return []s_cnt=defaultdict(int) #设置为字典,便于统计字符的个数p_cnt=defaultdict(int)result=[]#统计p的词频for char in p:p_cnt[char]+=1left,right=0,0while right<len_s:#统计s的词频s_cnt[s[right]]+=1# 窗口移动,s的词频更改 应该去掉s_cnt的首位,然后添加一位if right-left+1==len_p:s_cnt[s[left]]-=1if s_cnt[s[left]]==0:del s_cnt[s[left]]s_cnt[s[right]]+=1#如果s和p词频相同if s_cnt==p_cnt:#在result中记录词组的初始索引result.append(left)left+=1right+=1成功成功
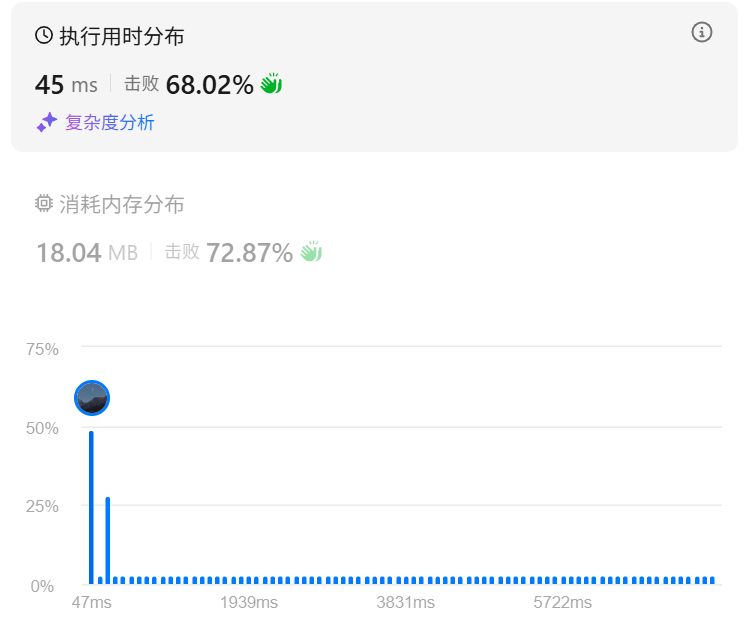
三、本题收获
包括内置的 sorted() 函数和列表的 sort() 方法,以及相关的参数和注意事项:
1. sorted() 函数
功能: sorted() 函数可以对任何可迭代对象(如列表、元组、字符串、字典等)进行排序,并返回一个新的已排序的列表,不修改原始对象
"""
语法:
sorted(iterable, key=None, reverse=False)
iterable: 要排序的可迭代对象。
key: 一个函数,用于在排序前对每个元素进行操作。它的返回值将用于排序。例如,key=len 可以对字符串列表按长度排序,key=abs 可以在排序数字列表时按绝对值排序。
reverse: 布尔值,True 表示降序排序,False 表示升序排序(默认)。
"""# 列表排序
numbers = [3, 1, 4, 1, 5, 9, 2, 6]
sorted_numbers = sorted(numbers) # 升序排序
print(sorted_numbers) # Output: [1, 1, 2, 3, 4, 5, 6, 9]
print(numbers) # Output: [3, 1, 4, 1, 5, 9, 2, 6] (原始列表不变)sorted_numbers_desc = sorted(numbers, reverse=True) # 降序排序
print(sorted_numbers_desc) # Output: [9, 6, 5, 4, 3, 2, 1, 1]# 字符串排序
string = "hello world"
sorted_string = sorted(string) # 默认升序 (按字符的ASCII值)
print(sorted_string) # Output: [' ', 'd', 'e', 'h', 'l', 'l', 'o', 'o', 'r', 'w']# 列表按元素长度排序
words = ["apple", "banana", "cherry"]
sorted_words = sorted(words, key=len)
print(sorted_words) # Output: ['apple', 'banana', 'cherry']# 字典排序(按键)
my_dict = {"c": 3, "a": 1, "b": 2}
sorted_dict_keys = sorted(my_dict.keys())
print(sorted_dict_keys) # Output: ['a', 'b', 'c']# 字典排序(按值)
sorted_dict_items = sorted(my_dict.items(), key=lambda item: item[1])
print(sorted_dict_items) # Output: [('a', 1), ('b', 2), ('c', 3)]2. 列表的 sort() 方法
功能: sort() 方法是列表对象的一个方法,用于在原地(in-place)对列表进行排序,直接修改原始列表,没有返回值(返回 None)。
"""
语法:
list.sort(key=None, reverse=False)
key: 一个函数,用于在排序前对每个元素进行操作。它的返回值将用于排序。例如,key=len 可以对字符串列表按长度排序,key=abs 可以在排序数字列表时按绝对值排序。
reverse: 布尔值,True 表示降序排序,False 表示升序排序(默认)。
"""
numbers = [3, 1, 4, 1, 5, 9, 2, 6]
numbers.sort() # 原地升序排序
print(numbers) # Output: [1, 1, 2, 3, 4, 5, 6, 9]numbers.sort(reverse=True) # 原地降序排序
print(numbers) # Output: [9, 6, 5, 4, 3, 2, 1, 1]words = ["apple", "banana", "cherry"]
words.sort(key=len)
print(words) # Output: ['apple', 'banana', 'cherry']# 注意点(不要这样写!)
result = numbers.sort() # sort() 修改原列表,返回None
print(result) # Output: None
总结:
| 特性 | sorted() | list.sort() |
|---|---|---|
| 是否修改原对象 | 否(返回新列表) | 是(原地修改) |
| 适用于 | 所有可迭代对象 | 列表 |
| 返回值 | 新的已排序的列表 | None |
| 内存使用 | 需要额外的内存存储排序后的列表 | 原地排序,通常更节省内存 |
总结
只会打暴力,基础一团糟,明天再学吧老铁,别真学会了。