构建时序感知的智能RAG系统:让AI自动处理动态数据并实时更新知识库
现代RAG(Retrieval-Augmented Generation)和智能体架构在处理问答任务时,依赖于能够随时间动态更新的知识库,这类知识库通常包含财务报告、技术文档等持续变化的信息。为确保推理和规划过程的逻辑性与准确性,需要建立相应的时序管理机制。
针对规模不断增长且存在幻觉风险的动态知识库,需要构建一个独立的逻辑-时序(时间感知)智能体管道来管理AI产品中的演进知识库。该管道的核心组件包括:
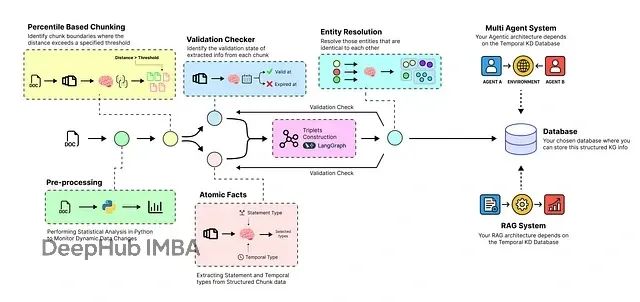
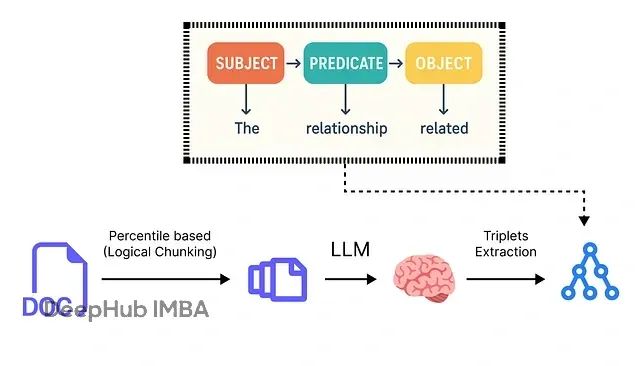
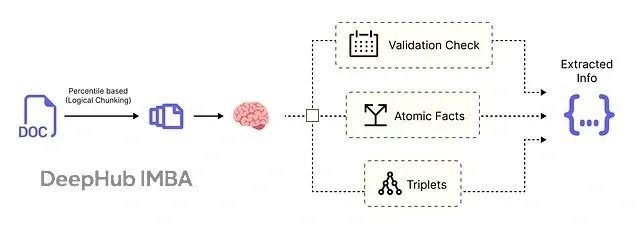
本文介绍的系统采用六层架构设计:语义分块模块将大型原始文档分解为具有上下文意义的文本单元;原子事实提取模块使用大语言模型读取每个文本块并提取原子事实、时间戳及相关实体;实体解析模块通过自动识别和合并重复实体(如"AMD"与"Advanced Micro Devices")来清理数据;时序失效模块在新信息到达时智能识别并解决矛盾,将过时事实标记为"失效"状态;知识图构建模块将最终的、清洁的、带时间戳的事实组装成AI智能体可查询的连接图结构;优化知识库模块将最终的动态知识图存储在可扩展的云数据库中,创建可靠且实时更新的知识基础,为RAG或智能体系统提供支撑。
将构建一个端到端的时序智能体管道,实现从原始数据到动态知识库的转换,并在此基础上构建多智能体系统以验证其性能表现。
动态数据的预处理与分析
本文将处理随时间持续演进的数据集,以公司财务状况作为典型应用场景。
企业会定期发布财务表现更新信息,包括股价波动、重大事件(如高管变更)以及前瞻性预期(如季度收入同比增长预测)等内容。在医疗领域,ICD编码的演进同样体现了数据动态特性——从ICD-9到ICD-10的转换使诊断代码数量从约14,000个增加到68,000个。
为模拟真实应用场景,本文采用John Henning提供的earnings_call HuggingFace数据集,该数据集包含不同公司在特定时间段内的财务表现信息。
首先加载数据集并进行统计分析:
# Import loader for Hugging Face datasets
from langchain_community.document_loaders import HuggingFaceDatasetLoader # Dataset configuration
hf_dataset_name = "jlh-ibm/earnings_call" # HF dataset name
subset_name = "transcripts" # Dataset subset to load # Create the loader (defaults to 'train' split)
loader = HuggingFaceDatasetLoader( path=hf_dataset_name, name=subset_name, page_content_column="transcript" # Column containing the main text
) # This is the key step. The loader processes the dataset and returns a list of LangChain Document objects. documents = loader.load()
研究重点关注数据集的transcript子集,该子集包含不同公司的原始文本信息,构成任何RAG或AI智能体架构的基础数据结构。
# Let's inspect the result to see the difference print(f"Loaded {len(documents)} documents.") #### OUTPUT #### Loaded 188 documents.
数据集共包含188个转录本,需要统计其中涉及的独特公司数量:
# Count how many documents each company has
company_counts = {} # Loop over all loaded documents
for doc in documents: company = doc.metadata.get("company") # Extract company from metadata if company: company_counts[company] = company_counts.get(company, 0) + 1 # Display the counts
print("Total company counts:")
for company, count in company_counts.items(): print(f" - {company}: {count}") #### OUTPUT ####
Total company counts: - AMD: 19 - AAPL: 19 - INTC: 19 - MU: 17 - GOOGL: 19 - ASML: 19 - CSCO: 19 - NVDA: 19 - AMZN: 19 - MSFT: 19
数据分布基本均衡,各公司样本数量相近。检查随机转录本的元数据结构:
# Print metadata for two sample documents (index 0 and 33)
print("Metadata for document[0]:")
print(documents[0].metadata) print("\nMetadata for document[33]:")
print(documents[33].metadata) #### OUTPUT ####
{'company': 'AMD', 'date': datetime.date(2016, 7, 21)} {'company': 'AMZN', 'date': datetime.date(2019, 10, 24)}
元数据中company字段标识转录本所属公司,date字段表示信息对应的时间范围。
# Print the first 200 characters of the first document's content
first_doc = documents[0]
print(first_doc.page_content[:200]) #### OUTPUT ####
Thomson Reuters StreetEvents Event Transcript
E D I T E D V E R S I O N
Q2 2016 Advanced Micro Devices Inc Earnings Call
JULY 21, 2016 / 9:00PM GMT
===================================== ...
通过样本内容可以看出,当前示例为AMD的季度财报电话会议记录。
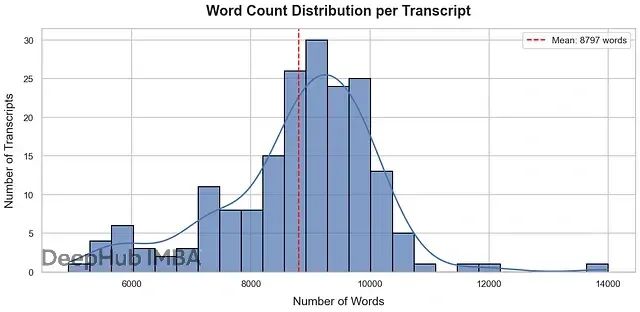
转录本内容较为庞大,因为其涵盖特定时间段的详细信息。需要统计188个转录本的平均词汇量:
# Calculate the average number of words per document
total_words = sum(len(doc.page_content.split()) for doc in documents)
average_words = total_words / len(documents) if documents else 0 print(f"Average number of words in documents: {average_words:.2f}") #### OUTPUT #### Average number of words in documents: 8797.124
每个转录本平均包含约9,000个词汇,信息量相当丰富。这种大规模信息处理正是构建结构化知识库AI智能体所需要的,而非简单的小文档处理。
财务数据通常基于不同时间框架,每个时间段代表该期间的特定信息。可以使用Python代码而非大语言模型从转录本中提取时间框架信息,以节约成本:
import re
from datetime import datetime # Helper function to extract a quarter string (e.g., "Q1 2023") from text
def find_quarter(text: str) -> str | None: """Return the first quarter-year match found in the text, or None if absent.""" # Match pattern: 'Q' followed by 1 digit, a space, and a 4-digit year match = re.findall(r"Q\d\s\d{4}", text) return match[0] if match else None # Test on the first document
quarter = find_quarter(documents[0].page_content)
print(f"Extracted Quarter for the first document: {quarter}") #### OUTPUT #### Extracted Quarter for the first document: Q2 2016
虽然通过大语言模型进行季度-日期提取能够实现更深层的数据理解,但考虑到当前数据的文本结构已经相对规范,可以暂时采用传统方法处理。
[外链图片转存中…(img-BimFacm9-1755525993047)]
我们对动态数据有了基本了解,可以开始通过时序AI智能体构建知识库。
基于百分位数的语义分块技术
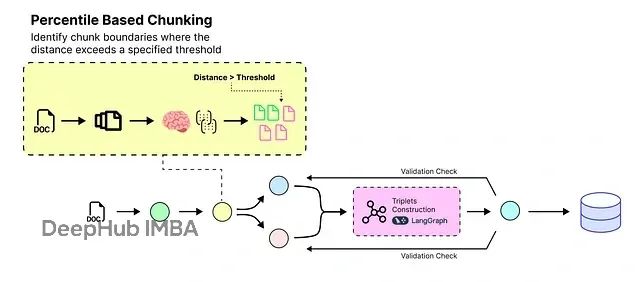
传统的数据分块方法通常基于随机分割或有意义的句子边界(如句号结束位置)进行处理。然而,这种方法可能导致信息丢失。例如:
净收入增长12%至210万美元。这一增长由较低的运营费用推动。
如果在句号处分割,就会失去净收入增长与较低运营费用之间的紧密关联。
本文采用基于百分位数的分块方法。该方法的工作原理如下:
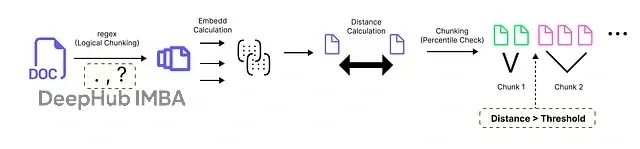
该分块算法包含六个步骤:首先使用正则表达式将文档分割为句子,通常在句号、问号或感叹号后断开;然后使用嵌入模型将每个句子转换为高维向量;计算连续句子向量间的语义距离,较大数值表示更显著的主题变化;收集所有距离并确定选定的百分位数(如第95百分位),以捕获异常大的跳跃;将距离大于或等于此阈值的边界标记为分块断点;最后将这些边界间的句子分组为块,应用min_chunk_size避免过小的块,并根据需要使用buffer_size添加重叠。
from langchain_nebius import NebiusEmbeddings# Set Nebius API key (⚠️ Avoid hardcoding secrets in production code) os.environ["NEBIUS_API_KEY"] = "YOUR_API_KEY_HERE" # 1. Initialize Nebius embedding model embeddings = NebiusEmbeddings(model="Qwen/Qwen3-Embedding-8B")
本文通过LangChain中的Nebius AI使用Qwen3-8B模型生成嵌入向量。LangChain模块支持多种嵌入提供商。
from langchain_experimental.text_splitter import SemanticChunker # Create a semantic chunker using percentile thresholding
langchain_semantic_chunker = SemanticChunker( embeddings, breakpoint_threshold_type="percentile", # Use percentile-based splitting breakpoint_threshold_amount=95 # split at 95th percentile )
选择第95百分位值作为阈值,当连续句子间的距离超过此值时将被视为断点。通过循环处理可以对转录本进行分块:
# Store the new, smaller chunk documents
chunked_documents_lc = [] # Printing total number of docs (188) We already know that
print(f"Processing {len(documents)} documents using LangChain's SemanticChunker...") # Chunk each transcript document
for doc in tqdm(documents, desc="Chunking Transcripts with LangChain"): # Extract quarter info and copy existing metadata quarter = find_quarter(doc.page_content) parent_metadata = doc.metadata.copy() parent_metadata["quarter"] = quarter # Perform semantic chunking (returns Document objects with metadata attached) chunks = langchain_semantic_chunker.create_documents( [doc.page_content], metadatas=[parent_metadata] ) # Collect all chunks chunked_documents_lc.extend(chunks) #### OUTPUT ####
Processing 188 documents using LangChains SemanticChunker... Chunking Transcripts with LangChain: 100%|██████████| 188/188 [01:03:44<00:00, 224.91s/it]
由于每个转录本包含约8,000个词汇,处理过程较为耗时。可通过异步函数优化运行时间,但为便于理解,当前循环实现了预期目标。
# Analyze the results of the LangChain chunking process
original_doc_count = len(docs_to_process)
chunked_doc_count = len(chunked_documents_lc) print(f"Original number of documents (transcripts): {original_doc_count}")
print(f"Number of new documents (chunks): {chunked_doc_count}")
print(f"Average chunks per transcript: {chunked_doc_count / original_doc_count:.2f}") #### OUTPUT ####
Original number of documents (transcripts): 188
Number of new documents (chunks): 3556 Average chunks per transcript: 19.00
平均每个转录本生成19个块。检查转录本中的随机块示例:
# Inspect the 11th chunk (index 10)
sample_chunk = chunked_documents_lc[10]
print("Sample Chunk Content (first 30 chars):")
print(sample_chunk.page_content[:30] + "...") print("\nSample Chunk Metadata:")
print(sample_chunk.metadata) # Calculate average word count per chunk
total_chunk_words = sum(len(doc.page_content.split()) for doc in chunked_documents_lc)
average_chunk_words = total_chunk_words / chunked_doc_count if chunked_documents_lc else 0 print(f"\nAverage number of words per chunk: {average_chunk_words:.2f}") #### OUTPUT ####
Sample Chunk Content (first 30 chars):
No, that is a fair question, Matt. So we have been very focused ... Sample Chunk Metadata:
{'company': 'AMD', 'date': datetime.date(2016, 7, 21), 'quarter': 'Q2 2016'} Average number of words per chunk: 445.42
块数据的元数据包含了额外信息,如所属季度以及便于检索的Python格式日期时间。
基于智能体的原子事实提取
数据经过整齐的分块组织后,可以使用大语言模型读取这些块并提取核心事实。
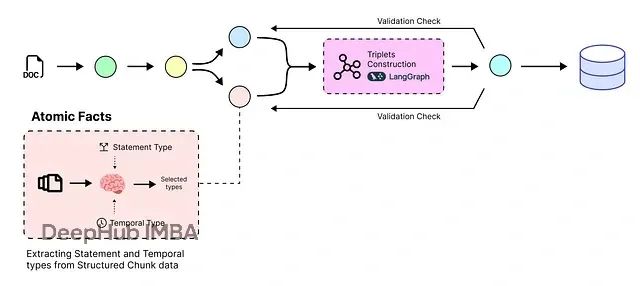
原子事实提取的必要性
需要将文本分解为尽可能小的"原子"事实,获得能够独立存在的单独声明,而非单一的复杂句子。
这一过程使信息更易于AI系统理解、查询和推理。
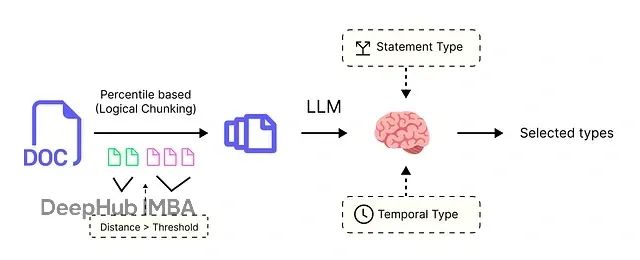
为确保大语言模型提供清洁、可预测的输出,需要提供严格的指令集。在Python中最佳实践是使用Pydantic模型,这些模型充当大语言模型必须遵循的架构或模板。
首先使用枚举定义标签的允许类别:
from enum import Enum# Enum for temporal labels describing time sensitivity class TemporalType(str, Enum): ATEMPORAL = "ATEMPORAL" # Facts that are always true (e.g., "Earth is a planet") STATIC = "STATIC" # Facts about a single point in time (e.g., "Product X launched on Jan 1st") DYNAMIC = "DYNAMIC" # Facts describing an ongoing state (e.g., "Lisa Su is the CEO")
每个类别捕获不同类型的时间引用:ATEMPORAL表示普遍正确且不随时间变化的语句(如"水在100摄氏度沸腾");STATIC表示在特定时间点变为真实且此后保持不变的语句(如"John于2020年6月1日被聘为经理");DYNAMIC表示可能随时间变化且需要时间上下文准确解释的语句(如"John是团队经理")。
# Enum for statement labels classifying statement nature class StatementType(str, Enum): FACT = "FACT" # An objective, verifiable claim OPINION = "OPINION" # A subjective belief or judgment PREDICTION = "PREDICTION" # A statement about a future event
StatementType枚举定义了语句的性质类型:FACT表示在表述时为真实但可能后续变化的语句(如"公司上季度收入500万美元");OPINION表示个人信念或感受,仅在表述时为真(如"我认为该产品会表现良好");PREDICTION表示对未来的预测,从当前到预测时间结束都具有有效性(如"明年销售额将增长")。
通过定义这些固定类别,确保智能体在信息分类时的一致性。
创建使用这些枚举定义输出结构的Pydantic模型:
from pydantic import BaseModel, field_validator# This model defines the structure for a single extracted statement
class RawStatement(BaseModel): statement: str statement_type: StatementType temporal_type: TemporalType # This model is a container for the list of statements from one chunk
class RawStatementList(BaseModel): statements: list[RawStatement]
这些模型构成了与大语言模型的契约,明确规定处理块完成后的输出必须是包含statements列表的JSON对象,列表中每项都必须具有statement、statement_type和temporal_type属性。

为大语言模型提供关于标签的上下文定义,帮助其理解FACT与OPINION之间的区别,或STATIC与DYNAMIC语句之间的差异:
# These definitions provide the necessary context for the LLM to understand the labels.
LABEL_DEFINITIONS: dict[str, dict[str, dict[str, str]]] = { "episode_labelling": { "FACT": dict(definition="Statements that are objective and can be independently verified or falsified through evidence."), "OPINION": dict(definition="Statements that contain personal opinions, feelings, values, or judgments that are not independently verifiable."), "PREDICTION": dict(definition="Uncertain statements about the future on something that might happen, a hypothetical outcome, unverified claims."), }, "temporal_labelling": { "STATIC": dict(definition="Often past tense, think -ed verbs, describing single points-in-time."), "DYNAMIC": dict(definition="Often present tense, think -ing verbs, describing a period of time."), "ATEMPORAL": dict(definition="Statements that will always hold true regardless of time."), }, }
这些定义通过解释为什么应该为提取信息分配特定标签,为大语言模型提供支持。使用这些定义创建提示模板:
# Format label definitions into a clean string for prompt injection
definitions_text = "" for section_key, section_dict in LABEL_DEFINITIONS.items(): # Add a section header with underscores replaced by spaces and uppercased definitions_text += f"==== {section_key.replace('_', ' ').upper()} DEFINITIONS ====\n" # Add each category and its definition under the section for category, details in section_dict.items(): definitions_text += f"- {category}: {details.get('definition', '')}\n"
该definitions_text字符串将成为提示的关键部分,为大语言模型提供准确执行任务所需的定义基础。
构建主要的提示模板,整合输入、任务指令、标签定义以及展示良好输出的关键示例:
from langchain_core.prompts import ChatPromptTemplate # Define the prompt template for statement extraction and labeling
statement_extraction_prompt_template = """
You are an expert extracting atomic statements from text. Inputs:
- main_entity: {main_entity}
- document_chunk: {document_chunk} Tasks:
1. Extract clear, single-subject statements.
2. Label each as FACT, OPINION, or PREDICTION.
3. Label each temporally as STATIC, DYNAMIC, or ATEMPORAL.
4. Resolve references to main_entity and include dates/quantities. Return ONLY a JSON object with the statements and labels.
""" # Create a ChatPromptTemplate from the string template prompt = ChatPromptTemplate.from_template(statement_extraction_prompt_template)
最后连接所有组件。创建LangChain链,将提示链接到大语言模型,并指示大语言模型根据RawStatementList模型构建输出:
from langchain_nebius import ChatNebius
import json# Initialize our LLM
llm = ChatNebius(model="deepseek-ai/DeepSeek-V3") # Create the chain: prompt -> LLM -> structured output parser statement_extraction_chain = prompt | llm.with_structured_output(RawStatementList)
本文通过Nebius使用deepseek-ai/DeepSeek-V3模型处理此任务,该模型功能强大且擅长遵循复杂指令。
在数据集的单个块上测试链的实际效果:
# Select the sample chunk we inspected earlier for testing extraction
sample_chunk_for_extraction = chunked_documents_lc[10] print("--- Running statement extraction on a sample chunk ---")
print(f"Chunk Content:\n{sample_chunk_for_extraction.page_content}")
print("\nInvoking LLM for extraction...") # Call the extraction chain with necessary inputs
extracted_statements_list = statement_extraction_chain.invoke({ "main_entity": sample_chunk_for_extraction.metadata["company"], "publication_date": sample_chunk_for_extraction.metadata["date"].isoformat(), "document_chunk": sample_chunk_for_extraction.page_content, "definitions": definitions_text
}) print("\n--- Extraction Result ---")
# Pretty-print the output JSON from the model response print(extracted_statements_list.model_dump_json(indent=2))
运行代码后获得以下块的结构化输出:
#### OUTPUT ####
{ "statements": [ { "statement": "AMD has been very focused on the server launch for the first half of 2017.", "statement_type": "FACT", "temporal_type": "DYNAMIC" }, { "statement": "AMD's Desktop product should launch before the server launch.", "statement_type": "PREDICTION", "temporal_type": "STATIC" }, { "statement": "AMD believes true volume availability will be in the first quarter of 2017.", "statement_type": "OPINION", "temporal_type": "STATIC" }, { "statement": "AMD may ship some limited volume towards the end of the fourth quarter.", "statement_type": "PREDICTION", "temporal_type": "STATIC" } ] }
至此完成了原子事实步骤,准确提取了时序和基于语句的事实,为后续更新奠定基础。
实体解析与去重机制
原子事实提取完成后,需要处理实体冗余问题。在不同文档中,同一实体可能有多种表示方式(如"AMD"与"Advanced Micro Devices"),必须建立实体解析机制来识别并合并这些重复实体。
构建
[外链图片转存中…(img-YM6uYiXC-1755525993049)]
实体提取模型
首先定义Pydantic模型来结构化实体提取过程:
# Model for storing a single extracted entity
class RawEntity(BaseModel): entity: str entity_type: str # Container model for a list of entities
class RawEntityList(BaseModel): entities: list[RawEntity]
实体类型可以是人员、组织、地点或其他相关类别。创建实体提取链以从语句中识别关键实体:
# Prompt template for entity extraction
entity_extraction_prompt = """
You are an expert at identifying entities in statements. For the given statement, extract all entities and classify them by type.
Entity types include: PERSON, ORGANIZATION, LOCATION, DATE, PRODUCT, CONCEPT, etc. Statement: {statement} Return ONLY a JSON object with the entities and their types.
""" # Create extraction chain
entity_prompt = ChatPromptTemplate.from_template(entity_extraction_prompt) entity_extraction_chain = entity_prompt | llm.with_structured_output(RawEntityList)
实体归一化算法
实体归一化是识别指向同一现实世界对象的不同文本表示的过程。该算法的工作原理如下:
实现基于相似度的实体归一化函数:
from difflib import SequenceMatcherdef normalize_entities(entities: list[str], similarity_threshold: float = 0.8) -> dict[str, str]: """ Normalize entities by grouping similar names together. Returns a mapping from original entity to normalized entity. """ entity_groups = {} normalized_mapping = {} for entity in entities: entity_lower = entity.lower() best_match = None best_similarity = 0 # Find the best matching existing group for representative in entity_groups.keys(): similarity = SequenceMatcher(None, entity_lower, representative.lower()).ratio() if similarity > best_similarity and similarity >= similarity_threshold: best_similarity = similarity best_match = representative if best_match: # Add to existing group entity_groups[best_match].append(entity) normalized_mapping[entity] = best_match else: # Create new group entity_groups[entity] = [entity] normalized_mapping[entity] = entity return normalized_mapping
该函数通过计算实体间的文本相似度来识别重复项,当相似度超过阈值时将实体归为同一组。
批量实体处理
对提取的语句进行批量实体处理:
def extract_and_normalize_entities(statements: list[str]) -> tuple[list[dict], dict[str, str]]: """ Extract entities from statements and normalize them. Returns extracted entities and normalization mapping. """ all_entities = [] entity_names = set() # Extract entities from each statement for statement in tqdm(statements, desc="Extracting entities"): try: extracted = entity_extraction_chain.invoke({"statement": statement}) for entity_info in extracted.entities: all_entities.append({ "statement": statement, "entity": entity_info.entity, "entity_type": entity_info.entity_type }) entity_names.add(entity_info.entity) except Exception as e: print(f"Error extracting entities from statement: {e}") continue # Normalize entity names normalization_mapping = normalize_entities(list(entity_names)) # Apply normalization to extracted entities for entity_info in all_entities: entity_info["normalized_entity"] = normalization_mapping.get( entity_info["entity"], entity_info["entity"] ) return all_entities, normalization_mapping
通过这一过程,可以确保"AMD"、“Advanced Micro Devices”、"AMD Corp"等不同表示形式都被识别为同一实体。
时序失效与知识图构建
随着时间推移,某些事实可能变得过时或被新信息所取代。时序失效模块负责识别这些矛盾并维护知识库的一致性。
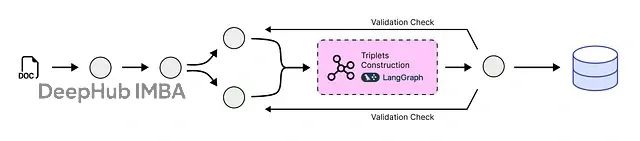
冲突检测机制
构建冲突检测系统来识别相互矛盾的语句:
class ConflictType(str, Enum): TEMPORAL_OVERRIDE = "TEMPORAL_OVERRIDE" # New information supersedes old DIRECT_CONTRADICTION = "DIRECT_CONTRADICTION" # Mutually exclusive statements VALUE_UPDATE = "VALUE_UPDATE" # Numerical or categorical updates
class ConflictResolution(BaseModel): conflict_type: ConflictType superseded_statements: list[str] superseding_statement: str confidence: float reasoning: str
实现冲突检测算法:
def detect_conflicts(statements_with_metadata: list[dict]) -> list[ConflictResolution]: """ Detect temporal conflicts between statements. """ conflicts = [] # Group statements by entity and sort by date entity_statements = {} for stmt_data in statements_with_metadata: entity = stmt_data.get("primary_entity") if entity not in entity_statements: entity_statements[entity] = [] entity_statements[entity].append(stmt_data) # Sort by date for each entity for entity, statements in entity_statements.items(): statements.sort(key=lambda x: x.get("date", datetime.min)) # Check for conflicts within entity statements for i in range(len(statements) - 1): current = statements[i] next_stmt = statements[i + 1] # Use LLM to determine if statements conflict conflict = check_statement_conflict(current, next_stmt) if conflict: conflicts.append(conflict) return conflictsdef check_statement_conflict(stmt1: dict, stmt2: dict) -> ConflictResolution | None: """ Use LLM to determine if two statements conflict. """ conflict_prompt = f""" Analyze these two statements for conflicts: Statement 1 (from {stmt1.get('date')}): {stmt1.get('statement')} Statement 2 (from {stmt2.get('date')}): {stmt2.get('statement')} Determine if there is a conflict and what type. """ # Implementation would use LLM to analyze conflicts # Return ConflictResolution if conflict detected, None otherwise pass
知识图构建
使用NetworkX构建动态知识图,其中节点表示实体,边表示关系:
import networkx as nx
from datetime import datetimeclass TemporalKnowledgeGraph: def __init__(self): self.graph = nx.MultiDiGraph() self.facts = {} # fact_id -> fact_data self.active_facts = set() # Currently valid fact IDs self.superseded_facts = set() # Invalidated fact IDs def add_fact(self, fact_id: str, statement: str, entities: list[str], date: datetime, statement_type: str, temporal_type: str): """Add a new fact to the knowledge graph.""" self.facts[fact_id] = { "statement": statement, "entities": entities, "date": date, "statement_type": statement_type, "temporal_type": temporal_type, "is_active": True } self.active_facts.add(fact_id) # Add entities as nodes for entity in entities: if not self.graph.has_node(entity): self.graph.add_node(entity, entity_type="UNKNOWN") # Add relationships between entities if len(entities) >= 2: for i in range(len(entities) - 1): self.graph.add_edge( entities[i], entities[i + 1], fact_id=fact_id, date=date, statement=statement ) def supersede_fact(self, old_fact_id: str, new_fact_id: str, reasoning: str): """Mark an old fact as superseded by a new one.""" if old_fact_id in self.active_facts: self.active_facts.remove(old_fact_id) self.superseded_facts.add(old_fact_id) self.facts[old_fact_id]["is_active"] = False self.facts[old_fact_id]["superseded_by"] = new_fact_id self.facts[old_fact_id]["supersession_reason"] = reasoning def query_facts(self, entity: str, date_range: tuple = None, statement_type: str = None) -> list[dict]: """Query facts related to an entity with optional filters.""" results = [] for fact_id in self.active_facts: fact = self.facts[fact_id] # Check if entity is involved if entity not in fact["entities"]: continue # Apply date filter if date_range and not (date_range[0] <= fact["date"] <= date_range[1]): continue # Apply statement type filter if statement_type and fact["statement_type"] != statement_type: continue results.append(fact) return results def get_entity_timeline(self, entity: str) -> list[dict]: """Get chronological timeline of facts for an entity.""" entity_facts = self.query_facts(entity) return sorted(entity_facts, key=lambda x: x["date"])
该知识图支持动态更新,能够处理事实的失效和替换,同时保持历史记录用于审计和分析。
集成处理流程
将所有组件整合为完整的处理流程:
def process_documents_to_knowledge_graph(documents: list) -> TemporalKnowledgeGraph: """ Complete pipeline from documents to temporal knowledge graph. """ kg = TemporalKnowledgeGraph() print("Step 1: Semantic chunking...") chunked_docs = [] for doc in tqdm(documents, desc="Chunking documents"): chunks = langchain_semantic_chunker.create_documents( [doc.page_content], [doc.metadata] ) chunked_docs.extend(chunks) print(f"Step 2: Extracting statements from {len(chunked_docs)} chunks...") all_statements = [] for chunk in tqdm(chunked_docs, desc="Extracting statements"): try: statements = statement_extraction_chain.invoke({ "main_entity": chunk.metadata.get("company"), "publication_date": chunk.metadata.get("date", "").isoformat(), "document_chunk": chunk.page_content, "definitions": definitions_text }) for stmt in statements.statements: all_statements.append({ "statement": stmt.statement, "statement_type": stmt.statement_type, "temporal_type": stmt.temporal_type, "source_metadata": chunk.metadata, "date": chunk.metadata.get("date") }) except Exception as e: print(f"Error processing chunk: {e}") continue print("Step 3: Extracting and normalizing entities...") statements_text = [s["statement"] for s in all_statements] entities_data, normalization_map = extract_and_normalize_entities(statements_text) print("Step 4: Building knowledge graph...") for i, stmt_data in enumerate(all_statements): # Find entities for this statement stmt_entities = [ e["normalized_entity"] for e in entities_data if e["statement"] == stmt_data["statement"] ] fact_id = f"fact_{i}" kg.add_fact( fact_id=fact_id, statement=stmt_data["statement"], entities=stmt_entities, date=stmt_data["date"], statement_type=stmt_data["statement_type"], temporal_type=stmt_data["temporal_type"] ) print("Step 5: Detecting and resolving conflicts...") conflicts = detect_conflicts(all_statements) for conflict in conflicts: # Apply conflict resolution to knowledge graph # Implementation depends on specific conflict resolution strategy pass return kg
多智能体系统验证
构建完成时序知识图后,需要验证其在实际AI应用中的性能表现。通过构建多智能体系统来测试知识库的可靠性和实用性。
智能体架构设计
设计三个专门化智能体来处理不同类型的查询:
class QueryType(str, Enum): FACTUAL = "FACTUAL" # Direct fact retrieval ANALYTICAL = "ANALYTICAL" # Analysis and reasoning TEMPORAL = "TEMPORAL" # Time-based queries
class KnowledgeAgent: def __init__(self, knowledge_graph: TemporalKnowledgeGraph, agent_type: str): self.kg = knowledge_graph self.agent_type = agent_type self.llm = ChatNebius(model="deepseek-ai/DeepSeek-V3") def process_query(self, query: str, context: dict = None) -> str: """Process a query using the knowledge graph.""" relevant_facts = self._retrieve_relevant_facts(query, context) return self._generate_response(query, relevant_facts, context) def _retrieve_relevant_facts(self, query: str, context: dict) -> list[dict]: """Retrieve facts relevant to the query.""" # Implementation depends on query analysis and entity extraction pass def _generate_response(self, query: str, facts: list[dict], context: dict) -> str: """Generate response based on retrieved facts.""" facts_text = "\n".join([f"- {f['statement']}" for f in facts]) prompt = f""" Based on the following verified facts from our knowledge base, answer the query. Query: {query} Relevant Facts: {facts_text} Provide a comprehensive answer based only on the given facts. """ response = self.llm.invoke(prompt) return response.contentclass FactualAgent(KnowledgeAgent): def __init__(self, knowledge_graph: TemporalKnowledgeGraph): super().__init__(knowledge_graph, "FACTUAL") def _retrieve_relevant_facts(self, query: str, context: dict) -> list[dict]: """Retrieve direct factual information.""" # Extract entities from query entities = self._extract_query_entities(query) all_facts = [] for entity in entities: facts = self.kg.query_facts(entity) all_facts.extend(facts) return all_facts[:10] # Limit to top 10 most relevantclass AnalyticalAgent(KnowledgeAgent): def __init__(self, knowledge_graph: TemporalKnowledgeGraph): super().__init__(knowledge_graph, "ANALYTICAL") def _retrieve_relevant_facts(self, query: str, context: dict) -> list[dict]: """Retrieve facts for analytical reasoning.""" # More sophisticated retrieval for analysis entities = self._extract_query_entities(query) facts = [] for entity in entities: # Get both current facts and historical context current_facts = self.kg.query_facts(entity) timeline = self.kg.get_entity_timeline(entity) facts.extend(current_facts) facts.extend(timeline[-5:]) # Recent history return factsclass TemporalAgent(KnowledgeAgent): def __init__(self, knowledge_graph: TemporalKnowledgeGraph): super().__init__(knowledge_graph, "TEMPORAL") def _retrieve_relevant_facts(self, query: str, context: dict) -> list[dict]: """Retrieve time-sensitive information.""" entities = self._extract_query_entities(query) date_range = self._extract_date_range(query) facts = [] for entity in entities: if date_range: entity_facts = self.kg.query_facts(entity, date_range=date_range) else: entity_facts = self.kg.get_entity_timeline(entity) facts.extend(entity_facts) return facts
多智能体协调机制
实现智能体协调器来管理不同智能体间的协作:
class MultiAgentOrchestrator: def __init__(self, knowledge_graph: TemporalKnowledgeGraph): self.factual_agent = FactualAgent(knowledge_graph) self.analytical_agent = AnalyticalAgent(knowledge_graph) self.temporal_agent = TemporalAgent(knowledge_graph) self.classifier = ChatNebius(model="deepseek-ai/DeepSeek-V3") def process_query(self, query: str) -> dict: """Route query to appropriate agent(s) and coordinate response.""" query_type = self._classify_query(query) if query_type == QueryType.FACTUAL: response = self.factual_agent.process_query(query) return {"agent": "factual", "response": response} elif query_type == QueryType.ANALYTICAL: # May require multiple agents factual_context = self.factual_agent.process_query(query) analytical_response = self.analytical_agent.process_query( query, context={"factual_base": factual_context} ) return { "agent": "analytical", "response": analytical_response, "context": factual_context } elif query_type == QueryType.TEMPORAL: response = self.temporal_agent.process_query(query) return {"agent": "temporal", "response": response} else: # Default to factual agent response = self.factual_agent.process_query(query) return {"agent": "default", "response": response} def _classify_query(self, query: str) -> QueryType: """Classify the type of query to route to appropriate agent.""" classification_prompt = f""" Classify this query into one of three types: - FACTUAL: Direct requests for specific facts - ANALYTICAL: Requests for analysis, comparison, or reasoning - TEMPORAL: Requests involving time-based information or trends Query: {query} Return only the classification type. """ response = self.classifier.invoke(classification_prompt) try: return QueryType(response.content.strip()) except ValueError: return QueryType.FACTUAL # Default fallback
性能评估框架
建立评估框架来测试多智能体系统的性能:
class EvaluationFramework: def __init__(self, orchestrator: MultiAgentOrchestrator): self.orchestrator = orchestrator self.test_queries = [] self.results = [] def add_test_query(self, query: str, expected_type: QueryType, expected_entities: list[str] = None): """Add a test query with expected results.""" self.test_queries.append({ "query": query, "expected_type": expected_type, "expected_entities": expected_entities or [] }) def run_evaluation(self) -> dict: """Run evaluation on all test queries.""" results = { "total_queries": len(self.test_queries), "successful_classifications": 0, "response_quality_scores": [], "detailed_results": [] } for test_case in self.test_queries: try: response = self.orchestrator.process_query(test_case["query"]) # Evaluate classification accuracy classified_correctly = ( self._infer_query_type(response["agent"]) == test_case["expected_type"] ) if classified_correctly: results["successful_classifications"] += 1 # Evaluate response quality (simplified) quality_score = self._evaluate_response_quality( response["response"], test_case ) results["response_quality_scores"].append(quality_score) results["detailed_results"].append({ "query": test_case["query"], "expected_type": test_case["expected_type"], "agent_used": response["agent"], "classified_correctly": classified_correctly, "quality_score": quality_score, "response": response["response"][:100] + "..." # Truncated }) except Exception as e: print(f"Error processing query '{test_case['query']}': {e}") results["detailed_results"].append({ "query": test_case["query"], "error": str(e) }) # Calculate summary statistics results["classification_accuracy"] = ( results["successful_classifications"] / results["total_queries"] ) results["average_quality_score"] = ( sum(results["response_quality_scores"]) / len(results["response_quality_scores"]) if results["response_quality_scores"] else 0 ) return results def _infer_query_type(self, agent_name: str) -> QueryType: """Infer query type from agent name.""" mapping = { "factual": QueryType.FACTUAL, "analytical": QueryType.ANALYTICAL, "temporal": QueryType.TEMPORAL } return mapping.get(agent_name, QueryType.FACTUAL) def _evaluate_response_quality(self, response: str, test_case: dict) -> float: """Evaluate the quality of a response (simplified scoring).""" # This is a simplified quality evaluation # In practice, this could use more sophisticated metrics score = 0.0 # Check if response is not empty if response and len(response.strip()) > 0: score += 0.3 # Check if response mentions expected entities for entity in test_case.get("expected_entities", []): if entity.lower() in response.lower(): score += 0.2 # Check response length (not too short, not too long) if 50 <= len(response) <= 500: score += 0.3 # Check for coherence (simplified: no repeated phrases) words = response.split() if len(set(words)) / len(words) > 0.7: # Unique word ratio score += 0.2 return min(score, 1.0) # Cap at 1.0
系统测试与验证
运行完整的测试套件验证系统性能:
def run_comprehensive_evaluation(): """Run comprehensive evaluation of the temporal knowledge system.""" # Process documents to create knowledge graph print("Building knowledge graph from documents...") kg = process_documents_to_knowledge_graph(documents[:20]) # Use subset for testing # Create multi-agent orchestrator orchestrator = MultiAgentOrchestrator(kg) # Set up evaluation framework evaluator = EvaluationFramework(orchestrator) # Add test queries test_queries = [ { "query": "What was AMD's revenue in Q2 2016?", "expected_type": QueryType.FACTUAL, "expected_entities": ["AMD", "revenue", "Q2 2016"] }, { "query": "How has AMD's performance changed over time?", "expected_type": QueryType.ANALYTICAL, "expected_entities": ["AMD", "performance"] }, { "query": "What events happened at AMD between 2016 and 2017?", "expected_type": QueryType.TEMPORAL, "expected_entities": ["AMD", "2016", "2017"] }, { "query": "Compare AMD and Intel's market positions.", "expected_type": QueryType.ANALYTICAL, "expected_entities": ["AMD", "Intel", "market"] }, { "query": "Who is the CEO of AMD?", "expected_type": QueryType.FACTUAL, "expected_entities": ["AMD", "CEO"] } ] for test_query in test_queries: evaluator.add_test_query(**test_query) # Run evaluation print("Running evaluation...") results = evaluator.run_evaluation() # Display results print("\n=== EVALUATION RESULTS ===") print(f"Total queries processed: {results['total_queries']}") print(f"Classification accuracy: {results['classification_accuracy']:.2%}") print(f"Average quality score: {results['average_quality_score']:.2f}") print("\nDetailed Results:") for result in results['detailed_results']: if 'error' not in result: print(f"Query: {result['query']}") print(f" Agent: {result['agent_used']}") print(f" Correct: {result['classified_correctly']}") print(f" Quality: {result['quality_score']:.2f}") print(f" Response: {result['response']}") print() return results# Run the evaluation evaluation_results = run_comprehensive_evaluation()
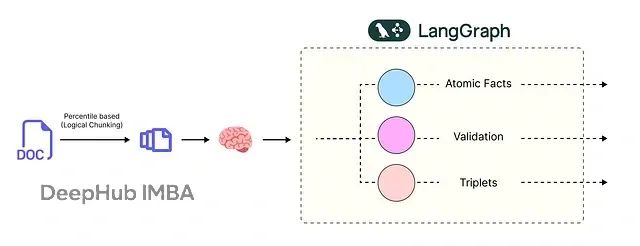
使用LangGraph自动化多智能体工作流
为了进一步提升系统的自动化程度和可扩展性,可以使用LangGraph来编排复杂的多智能体工作流。LangGraph提供了一个强大的框架来定义、执行和监控多步骤AI流程。
LangGraph工作流设计
首先定义工作流的状态结构:
from langgraph.graph import Graph, StateGraph
from typing import TypedDict, List, Optional
from langgraph.graph import ENDclass WorkflowState(TypedDict): """State shared across all nodes in the workflow.""" query: str query_type: Optional[str] extracted_entities: List[str] retrieved_facts: List[dict] response: Optional[str] confidence_score: float requires_temporal_analysis: bool requires_analytical_reasoning: bool error_message: Optional[str]
定义各个工作流节点:
def query_classification_node(state: WorkflowState) -> WorkflowState: """Classify the incoming query to determine processing strategy.""" try: # Use LLM to classify query classification_prompt = f""" Classify this query into categories and determine processing requirements: Query: {state['query']} Determine: 1. Primary type: FACTUAL, ANALYTICAL, or TEMPORAL 2. Whether temporal analysis is needed (True/False) 3. Whether analytical reasoning is needed (True/False) Return as JSON with keys: type, temporal_analysis, analytical_reasoning """ llm = ChatNebius(model="deepseek-ai/DeepSeek-V3") response = llm.invoke(classification_prompt) # Parse response (simplified) import json classification = json.loads(response.content) state["query_type"] = classification["type"] state["requires_temporal_analysis"] = classification["temporal_analysis"] state["requires_analytical_reasoning"] = classification["analytical_reasoning"] state["confidence_score"] = 0.8 # Placeholder except Exception as e: state["error_message"] = f"Classification error: {str(e)}" state["confidence_score"] = 0.0 return statedef entity_extraction_node(state: WorkflowState) -> WorkflowState: """Extract entities from the query for targeted fact retrieval.""" try: extraction_prompt = f""" Extract all relevant entities from this query: Query: {state['query']} Return a JSON list of entities: ["entity1", "entity2", ...] """ llm = ChatNebius(model="deepseek-ai/DeepSeek-V3") response = llm.invoke(extraction_prompt) import json entities = json.loads(response.content) state["extracted_entities"] = entities except Exception as e: state["error_message"] = f"Entity extraction error: {str(e)}" state["extracted_entities"] = [] return statedef fact_retrieval_node(state: WorkflowState) -> WorkflowState: """Retrieve relevant facts from the knowledge graph.""" try: # This would access the actual knowledge graph # For demonstration, we'll simulate fact retrieval retrieved_facts = [] for entity in state["extracted_entities"]: # Simulate knowledge graph query facts = [ { "statement": f"Sample fact about {entity}", "date": "2023-01-01", "confidence": 0.9, "source": "earnings_call" } ] retrieved_facts.extend(facts) state["retrieved_facts"] = retrieved_facts except Exception as e: state["error_message"] = f"Fact retrieval error: {str(e)}" state["retrieved_facts"] = [] return statedef temporal_analysis_node(state: WorkflowState) -> WorkflowState: """Perform temporal analysis on retrieved facts.""" if not state["requires_temporal_analysis"]: return state try: # Sort facts by date and analyze trends facts = state["retrieved_facts"] sorted_facts = sorted(facts, key=lambda x: x.get("date", "")) temporal_prompt = f""" Analyze the temporal patterns in these facts: Facts: {json.dumps(sorted_facts, indent=2)} Identify trends, changes over time, and temporal relationships. """ llm = ChatNebius(model="deepseek-ai/DeepSeek-V3") analysis = llm.invoke(temporal_prompt) # Add temporal analysis to facts state["retrieved_facts"].append({ "statement": f"Temporal analysis: {analysis.content}", "type": "analysis", "confidence": 0.7 }) except Exception as e: state["error_message"] = f"Temporal analysis error: {str(e)}" return statedef analytical_reasoning_node(state: WorkflowState) -> WorkflowState: """Perform analytical reasoning on facts.""" if not state["requires_analytical_reasoning"]: return state try: reasoning_prompt = f""" Perform analytical reasoning on these facts to answer the query: Query: {state['query']} Facts: {json.dumps(state['retrieved_facts'], indent=2)} Provide analytical insights, comparisons, and reasoning. """ llm = ChatNebius(model="deepseek-ai/DeepSeek-V3") reasoning = llm.invoke(reasoning_prompt) # Add reasoning to facts state["retrieved_facts"].append({ "statement": f"Analytical reasoning: {reasoning.content}", "type": "reasoning", "confidence": 0.8 }) except Exception as e: state["error_message"] = f"Analytical reasoning error: {str(e)}" return statedef response_generation_node(state: WorkflowState) -> WorkflowState: """Generate final response based on all available information.""" try: response_prompt = f""" Generate a comprehensive response to this query based on the available facts: Query: {state['query']} Query Type: {state['query_type']} Available Facts and Analysis: {json.dumps(state['retrieved_facts'], indent=2)} Provide a clear, well-structured response that directly addresses the query. """ llm = ChatNebius(model="deepseek-ai/DeepSeek-V3") response = llm.invoke(response_prompt) state["response"] = response.content except Exception as e: state["error_message"] = f"Response generation error: {str(e)}" state["response"] = "Unable to generate response due to processing error." return state
构建LangGraph工作流
将所有节点连接成一个有向无环图:
def create_temporal_knowledge_workflow() -> StateGraph: """Create the LangGraph workflow for temporal knowledge processing.""" # Create the state graph workflow = StateGraph(WorkflowState) # Add nodes workflow.add_node("classify_query", query_classification_node) workflow.add_node("extract_entities", entity_extraction_node) workflow.add_node("retrieve_facts", fact_retrieval_node) workflow.add_node("temporal_analysis", temporal_analysis_node) workflow.add_node("analytical_reasoning", analytical_reasoning_node) workflow.add_node("generate_response", response_generation_node) # Define the workflow edges workflow.set_entry_point("classify_query") workflow.add_edge("classify_query", "extract_entities") workflow.add_edge("extract_entities", "retrieve_facts") workflow.add_edge("retrieve_facts", "temporal_analysis") workflow.add_edge("temporal_analysis", "analytical_reasoning") workflow.add_edge("analytical_reasoning", "generate_response") workflow.add_edge("generate_response", END) return workflow.compile()
并行处理优化
对于更复杂的场景,可以实现并行处理来提高效率:
def create_parallel_workflow() -> StateGraph: """Create a workflow with parallel processing capabilities.""" workflow = StateGraph(WorkflowState) # Add all nodes workflow.add_node("classify_query", query_classification_node) workflow.add_node("extract_entities", entity_extraction_node) workflow.add_node("retrieve_facts", fact_retrieval_node) workflow.add_node("temporal_analysis", temporal_analysis_node) workflow.add_node("analytical_reasoning", analytical_reasoning_node) workflow.add_node("generate_response", response_generation_node) # Conditional routing based on query type def route_after_classification(state: WorkflowState) -> str: """Route to appropriate processing based on classification.""" if state.get("error_message"): return "generate_response" # Skip to error response return "extract_entities" def route_after_facts(state: WorkflowState) -> str: """Route based on analysis requirements.""" if state["requires_temporal_analysis"] and state["requires_analytical_reasoning"]: return "parallel_analysis" # Custom parallel node elif state["requires_temporal_analysis"]: return "temporal_analysis" elif state["requires_analytical_reasoning"]: return "analytical_reasoning" else: return "generate_response" # Set up the flow workflow.set_entry_point("classify_query") workflow.add_conditional_edges( "classify_query", route_after_classification, { "extract_entities": "extract_entities", "generate_response": "generate_response" } ) workflow.add_edge("extract_entities", "retrieve_facts") workflow.add_conditional_edges( "retrieve_facts", route_after_facts, { "temporal_analysis": "temporal_analysis", "analytical_reasoning": "analytical_reasoning", "generate_response": "generate_response", "parallel_analysis": "temporal_analysis" # Start with temporal } ) workflow.add_edge("temporal_analysis", "analytical_reasoning") workflow.add_edge("analytical_reasoning", "generate_response") workflow.add_edge("generate_response", END) return workflow.compile()
工作流执行与监控
实现工作流的执行和监控机制:
class WorkflowExecutor: def __init__(self, workflow_graph): self.workflow = workflow_graph self.execution_history = [] def execute_query(self, query: str) -> dict: """Execute a query through the workflow and return results.""" # Initialize state initial_state = WorkflowState( query=query, query_type=None, extracted_entities=[], retrieved_facts=[], response=None, confidence_score=0.0, requires_temporal_analysis=False, requires_analytical_reasoning=False, error_message=None ) # Execute workflow try: final_state = self.workflow.invoke(initial_state) # Record execution execution_record = { "query": query, "success": final_state.get("error_message") is None, "response": final_state.get("response"), "confidence": final_state.get("confidence_score", 0.0), "entities_found": len(final_state.get("extracted_entities", [])), "facts_retrieved": len(final_state.get("retrieved_facts", [])), "processing_time": time.time() # Simplified timestamp } self.execution_history.append(execution_record) return { "query": query, "response": final_state.get("response", "No response generated"), "confidence": final_state.get("confidence_score", 0.0), "metadata": { "query_type": final_state.get("query_type"), "entities": final_state.get("extracted_entities", []), "facts_used": len(final_state.get("retrieved_facts", [])), "temporal_analysis": final_state.get("requires_temporal_analysis", False), "analytical_reasoning": final_state.get("requires_analytical_reasoning", False) } } except Exception as e: error_record = { "query": query, "success": False, "error": str(e), "processing_time": time.time() } self.execution_history.append(error_record) return { "query": query, "response": f"Error processing query: {str(e)}", "confidence": 0.0, "error": True } def get_performance_metrics(self) -> dict: """Calculate performance metrics from execution history.""" if not self.execution_history: return {"message": "No executions recorded"} total_executions = len(self.execution_history) successful_executions = sum(1 for record in self.execution_history if record.get("success", False)) avg_confidence = sum( record.get("confidence", 0) for record in self.execution_history if record.get("success", False) ) / max(successful_executions, 1) avg_entities = sum( record.get("entities_found", 0) for record in self.execution_history if record.get("success", False) ) / max(successful_executions, 1) avg_facts = sum( record.get("facts_retrieved", 0) for record in self.execution_history if record.get("success", False) ) / max(successful_executions, 1) return { "total_executions": total_executions, "success_rate": successful_executions / total_executions, "average_confidence": avg_confidence, "average_entities_per_query": avg_entities, "average_facts_per_query": avg_facts }
完整系统演示
最后,将所有组件整合为一个完整的演示系统:
def run_complete_demonstration(): """Run a complete demonstration of the temporal knowledge system.""" print("=== TEMPORAL KNOWLEDGE SYSTEM DEMONSTRATION ===\n") # Create the workflow print("1. Creating LangGraph workflow...") workflow = create_temporal_knowledge_workflow() executor = WorkflowExecutor(workflow) # Test queries test_queries = [ "What was AMD's revenue in Q2 2016?", "How has AMD's stock price changed over the past year?", "Compare AMD and Intel's market performance.", "What are the recent developments at NVIDIA?", "Predict AMD's future growth based on current trends." ] print("2. Processing test queries...\n") for i, query in enumerate(test_queries, 1): print(f"Query {i}: {query}") result = executor.execute_query(query) print(f"Response: {result['response'][:200]}...") print(f"Confidence: {result['confidence']:.2f}") print(f"Metadata: {result.get('metadata', {})}") print("-" * 50) # Display performance metrics print("\n3. Performance Metrics:") metrics = executor.get_performance_metrics() for key, value in metrics.items(): print(f" {key}: {value}") return executor# Run the complete demonstration demonstration_executor = run_complete_demonstration()
总结与扩展
本文构建了一个完整的时序AI智能体系统,成功实现了从原始动态文档到可查询知识库的端到端转换。该系统的核心创新包括:
关键技术成果
语义分块技术通过基于百分位数的方法实现了上下文相关的文档分割,相比传统随机分割方法能够更好地保持信息完整性。该技术在处理大型财务文档时表现出色,平均每个文档生成19个语义连贯的块。
原子事实提取利用结构化的Pydantic模型和精心设计的提示工程,实现了对复杂文本中核心事实的精确提取。系统能够区分事实、观点和预测,并为每个语句分配适当的时间标签。
实体解析机制通过字符串相似度算法和归一化处理,解决了实体重复和表示不一致的问题。该机制确保"AMD"、"Advanced Micro Devices"等不同表示被识别为同一实体。
时序失效处理实现了智能冲突检测和解决机制,能够识别相互矛盾的信息并维护知识库的一致性。当新信息与旧信息冲突时,系统会自动标记过时信息并更新知识状态。
动态知识图构建使用NetworkX构建了支持时间演进的知识图,该图结构支持复杂查询、历史追踪和关系推理。
多智能体协调设计了专门化的智能体来处理不同类型的查询,包括事实检索、分析推理和时序查询。通过智能体协调器实现了查询的自动路由和响应整合。
LangGraph工作流自动化利用LangGraph框架实现了复杂多步骤处理流程的自动化,支持并行处理和条件路由,大幅提升了系统的可扩展性和维护性。
实际应用价值
该系统在多个领域具有广泛的应用前景:
金融分析领域可以处理财报、分析师报告和市场新闻,为投资决策提供实时更新的知识支持。系统能够追踪公司业绩变化、识别市场趋势并预警潜在风险。
医疗健康系统能够管理不断演进的医学知识,包括诊断指南更新、药物信息变更和治疗方案优化。特别适用于处理医学编码系统的版本迁移。
企业知识管理为大型组织提供动态的企业知识库,能够整合来自不同部门的信息更新,确保决策基于最新的准确信息。
法律合规系统可以追踪法规变化、政策更新和合规要求演进,为企业提供实时的法律合规指导。
技术扩展方向
向量数据库集成可以引入Pinecone、Weaviate或Milvus等专业向量数据库来提升大规模知识检索的性能。这将支持更复杂的语义搜索和相似性匹配。
实时数据流处理通过集成Apache Kafka或Apache Pulsar等流处理技术,系统可以处理实时数据更新,实现近实时的知识库更新。
多模态信息处理扩展系统以处理图像、视频和音频内容,利用多模态大语言模型提取跨媒体的知识信息。
联邦学习支持在保护数据隐私的前提下,支持多个组织间的知识共享和协作学习,构建更全面的行业知识库。
自动化评估体系开发更精细的知识质量评估指标,包括事实准确性验证、时间一致性检查和逻辑完整性评估。
分布式架构优化通过微服务架构和容器化部署,提升系统的可扩展性和容错能力,支持大规模企业级应用。
该时序AI智能体系统为动态知识管理提供了一个强大而灵活的解决方案。通过结合先进的自然语言处理技术、知识图谱构建和多智能体协调,系统能够有效处理现实世界中复杂的信息演进挑战。随着技术的不断发展和应用场景的扩展,该系统将在智能决策支持和知识管理领域发挥越来越重要的作用。
本文完整代码:https://avoid.overfit.cn/post/dca5bc9a98774341a20aeb81eecb9e0d
作者:Fareed Khan