线程安全 -- 2
目录
1、监视器锁
1.1、synchronized 关键字
1.2、可重入
2、死锁
2.1、死锁的三种情况
2.2、死锁是怎样构成的
2.3、如何避免死锁
3、线程安全类
4、内存可见性
4.1、编译器优化
4.2、volatile 关键字
4.3、在 JMM 中的表述
5、指令重排序
1、监视器锁
监视器锁(monitor lock)
在Java中,监视器锁(也称为内置锁或对象锁)是通过关键字 synchronized 实现的,它是Java语言提供的一种基本的线程同步机制。监视器锁确保了当一个线程正在执行一个对象的同步代码块时,其他线程无法进入该对象的任何其他同步代码块。
是JVM中采用的一个术语。在使用锁的过程中可能会抛出 监视器锁(monitor lock)这种异常
1.1、synchronized 关键字
在上节 线程安全 中已经讲过了,这里就不赘述了
1.2、可重入
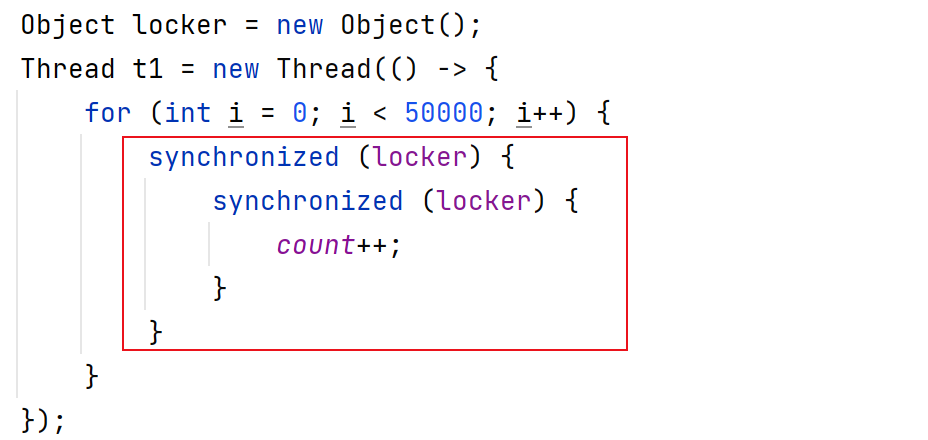
案例引入:
class Counter2 {private int count = 0;public void add() {synchronized (this) {count++;}}public int get() {return count;}
}public class Demo19 {public static void main(String[] args) throws InterruptedException {Counter2 counter = new Counter2();Thread t1 = new Thread(() -> {for (int i = 0; i < 50000; i++) {synchronized (counter) {counter.add();}}});t1.start();System.out.println("count = " + counter.get());}
}上述代码对同一个语句加锁了两次:
在实际上开发中,一旦方法调用的层次比较深,就容易出现这种情况


上述写法等价与:
代码分析:
1. 第一次进行加锁操作,能够成功(锁没有人使用)
2. 第二次进行加锁,锁对象是已经被占用的状态。所以第二次加锁会触发阻塞等待要想解除阻塞,需要往下执行;而要想往下执行,就需要等到第一次加的锁被释放
这样的问题,就称为“死锁”,死锁是一个非常严重的bug,代码执行到这一块之后会卡住
为了解决上述的问题,Java 的 synchronized 引入了可重入的概念:
当某个线程针对一个锁加锁成功后,后续该线程再次针对这个锁进行加锁,不会触发阻塞,而是直接往下走,因为当前这把锁是被这个线程持有。但是,如果是其他线程尝试加锁,会正常阻塞
可重入锁的实现原理:
在可重入锁的内部,包含了 “线程持有者” 和 “计数器” 两个信息:
1)如果某个线程加锁的时候,发现锁已经被人占用,但是恰好占用的正是自己,那么仍然可以继续获取到锁,并让计数器自增(每次触发 { 的时候,把计数器++)
2)解锁时,计数器递减为0的时候(每次触发 } 的时候,把计数器--),才真正释放锁(才能被别的线程获取到)
synchronized 同步块对同一条线程来说是可重入的
所以案例中代码可以正常执行,不会出现自己把自己锁死的问题
面试问题:
如何自己实现一个可重入锁?
1.在锁内部记录当前是哪个线程持有的锁.后续每次加锁,都进行判定
2.通过计数器,记录当前加锁的次数,从而确定何时真正进行解锁
2、死锁
2.1、死锁的三种情况
1. 一个线程,一把锁,连续加锁两次(Java中有可重入,不会出现死锁)
2. 两个线程,两把锁,每个线程获取到一把锁之后,尝试获取对方的锁
经典面试题:手写一个出现死锁的代码
示例:
public class Demo20 {public static void main(String[] args) throws InterruptedException {Object locker1 = new Object();Object locker2 = new Object();Thread t1 = new Thread(() -> {synchronized (locker1) {try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}// 尝试拿到 locker2 锁synchronized (locker2) {System.out.println("t1 线程两个锁都获取到");}}});Thread t2 = new Thread(() -> {synchronized (locker2) {try {Thread.sleep(1000);} catch (InterruptedException e) {throw new RuntimeException(e);}// 尝试拿到 locker1 锁synchronized (locker1) {System.out.println("t2 线程两个锁都获取到");}}});t1.start();t2.start();t1.join();t2.join();}
}执行程序后,发现结果是空的,没有打印任何东西
打开查看线程工具,发现两个线程都处于阻塞状态
但两个线程中如果不加 sleep,就不一定会出现这种情况了
不加sleep,很可能 t1 一口气就把 locker1 和 locker2 都拿到了,这个时候 t2 还动,就无法构成死锁了


3. N个线程M把锁
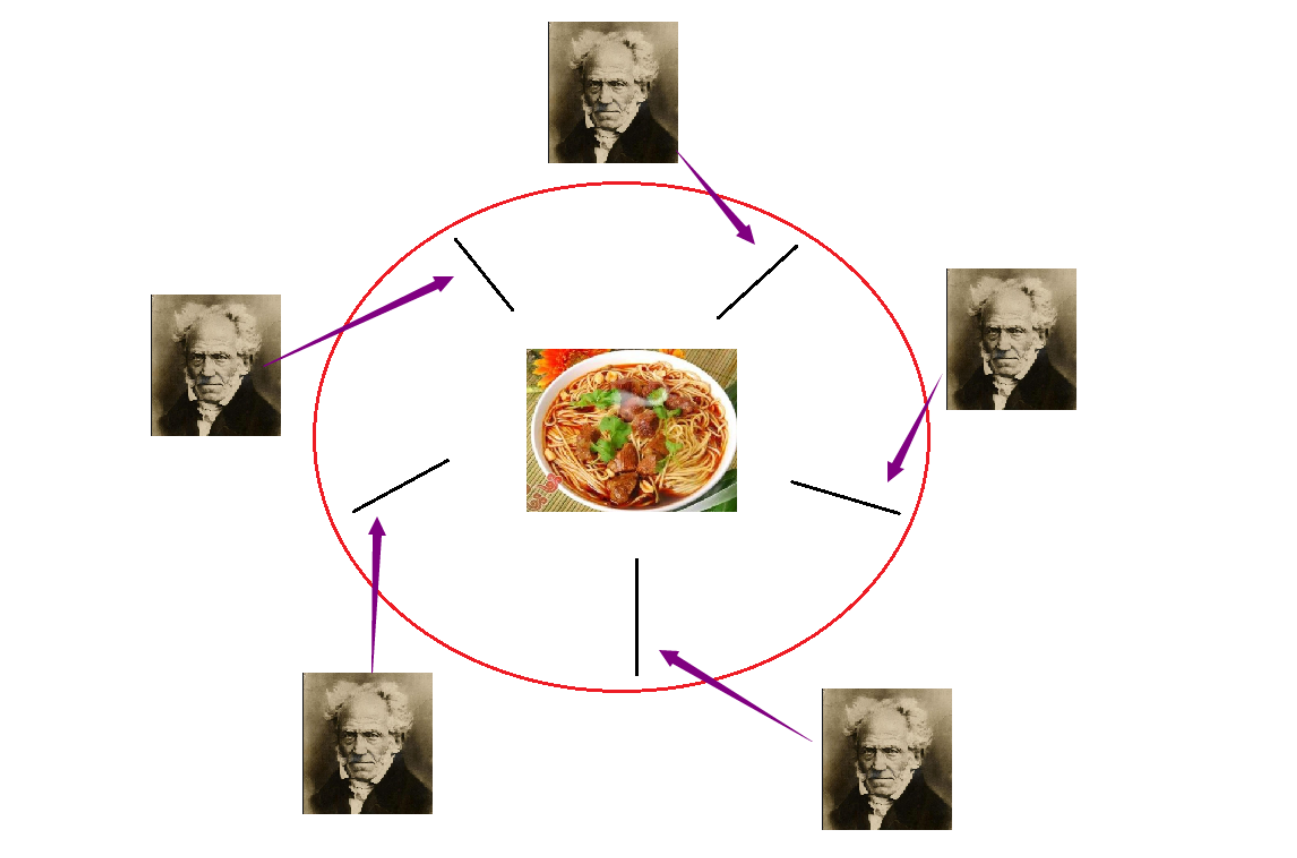
一个经典的模型,哲学家就餐问题:
问题设定为五名哲学家围坐圆桌,每人需同时获取左右两支筷子方能进餐。当所有哲学家同时持有单侧筷子时,系统将陷入循环等待状态导致死锁。

2.2、死锁是怎样构成的
构成死锁的四个必要条件(重要):
1. 锁是互斥的(锁的基本性质)
一个线程拿到锁之后,另一个线程再尝试获取锁,必须要阻塞等待
2. 锁是 不可抢占 / 不可剥夺 的(锁的基本性质)
线程1拿到锁,线程2也尝试获取这个锁,线程2必须阻塞等待,而不是直接把锁抢过来
3. 请求和保持
一个线程拿到锁1之后,不释放锁1的前提下,获取锁2
4. 循环等待
多个线程、多把锁之间的等待过程,构成了 “循环”。例如 A 等待 B,B 等待 C,C 等待 A
2.3、如何避免死锁
由于前两个条件是锁的基本性质,无法避免,所以只能从后两个条件下手
打破必要条件 3 或 4 的任何一个条件都能够打破死锁
打破3:代码中加锁时,不要 "嵌套”,所以把嵌套的锁改成并列的锁就可以。
但这种做法不够通用,有些情况下就是需要拿到多个锁,再进行某个操作的(嵌套,很难避免)
打破4:严格按照约定的固定顺序获取锁,确保所有线程按相同的顺序加锁,从而避免循环等待。例如:约定每个线程在加锁时,永远是先获取序号小的锁后获取序号大的锁
上述的经典面试题中的死锁,约定两个线程都必须先 locker1, 后 locker2,就可以避免循环等待

3、线程安全类
Java标准库中很多都是线程不安全的。这些类可能会涉及到多线程修改共享数据,但又没有任何加锁措施。
例如数据结构的集合类中,线程不安全的有:
ArrayList、LinkedList、HashMap、TreeMap、HashSet、TreeSet、StringBuilder
使用了锁机制的线程安全类有:
Vector、HashTable、ConcurrentHashMap、StringBuffer
Vector、HashTable、StringBuffer 这三个虽然有 synchronized,但不推荐使用
^
原因分析:
1. 使用锁是有代价的,一旦代码中使用了锁,意味着代码可能会因为锁的竞争产生阻塞。出线程阻塞,cpu 就会调度走,可能很长时间才会调度回来继续执行,会使程序的执行效率大打折扣。
2. 使用锁时,一定要思考清楚,这个地方是否确实需要锁,不需要的时候不要乱加
3. ConcurrentHashMap 相比于HashTable来说,是高度优化的版本。是在多线程中推荐使用的哈希表
还有的类虽然没有加锁,但是不涉及 “修改",仍然是线程安全的
例如:String
4、内存可见性
一个线程读取,一个线程修改,修改线程修改的值,并没有被读取线程读到,这样的问题就是 “内存可见性问题”,是造成线程安全问题的原因之一
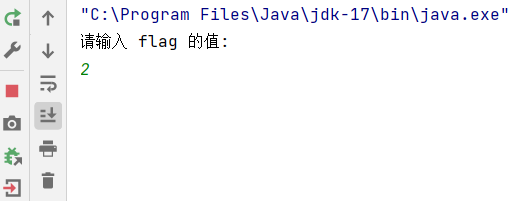
示例:
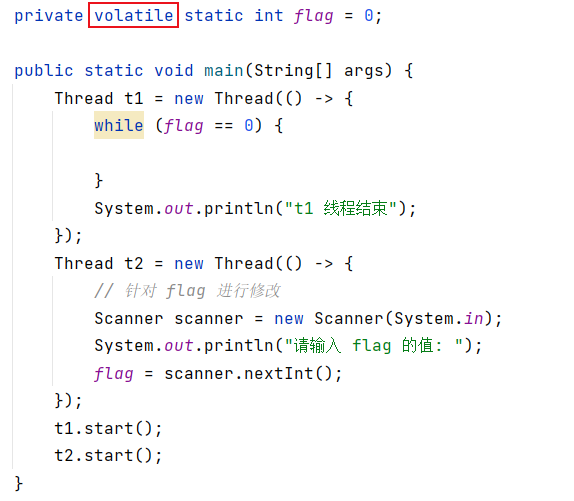
public class Demo21 {private static int flag = 0;public static void main(String[] args) {Thread t1 = new Thread(() -> {while (flag == 0) {}System.out.println("t1 线程结束");});Thread t2 = new Thread(() -> {// 针对 flag 进行修改Scanner scanner = new Scanner(System.in);System.out.println("请输入 flag 的值: ");flag = scanner.nextInt();});t1.start();t2.start();}
}输入 2
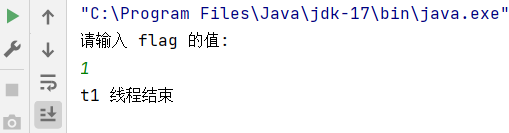
运行结果:
发现修改线程修改的值,并没有被读线程读到
这是由于编译器优化所导致的问题

4.1、编译器优化
由于程序员的水平,参差不齐,JDK 的开发人员,就希望通过让编译器 & JVM 对程序员写的代码,自动的进行优化。编译器 / JVM 会在原有逻辑不变的前提下,对代码进行调整使程序效率更高
编译器,虽然声称优化操作是能够保证逻辑不变的,但也不是一定的。尤其是在多线程的程序中,编译器的判断可能出现失误,可能导致 编译器的优化,使优化后的逻辑,和优化前的逻辑出现细节上的偏差
上述示例的 while 循环中,包括 load 指令和 cmp 指令,load 的时间开销可能是 cmp 的几干倍
load 指令:读内存中 flag 的值,并将数据加载到寄存器中
cmp 指令:读取寄存器中的数据,满足条件会跳转
1. 修改线程取决于用户输入,用户输入的时间往往很慢,此时读取线程已经循环很多次了,执行过程中 JVM 就能感知到 load 反复执行的结果每次都是一样的。
2. JVM 执行这么多次读 flag 的操作发现值始终都是 0,既然都是一样的结果,那就不要执行这么多次了,于是就把读取内存的操作,优化成读取寄存器的操作(把内存的值加载到寄存器了,后续再 load 不再重新读内存,直接从寄存器里来取)
3. 所以等用户输入值修改 flag 的时候,此时 t1 线程就感知不到了(编译器优化,使得t1线程的读操作,不是真正读内存)

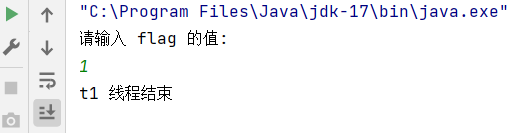
微调示例的代码:
在循环中加上 1 毫秒的 sleep

发现程序正常执行了
原因分析:
原本这个循环 1s 钟循环几千万,上亿次,但是加了 sleep(1) 之后循环次数大幅度降低了
引入 sleep 之后,sleep 消耗的时间相比于上面 load flag 的操作,高了不知道多少倍
把读内存操作优化成读寄存器,优化提升的效率远不如 sleep(1) 消耗的时间多,优不优化已经无足轻重了,所以 JVM 没有选择优化
4.2、volatile 关键字
针对内存可见性问题,不能指望通过 sleep 解决,因为使用 sleep 会大大影响到程序的效率。我们希望,不使用 sleep 也能解决 内存可见性问题
JDK 的开发人员知道可见性问题,但在编译器优化的角度难以进行调整,所以就在语法中,引入volatile 关键字,通过这个关键字来修饰某个变量,编译器这对这个变量的读取操作,就不会被优化成读取寄存器了
volatile:易变的,(计算机内存)易失的。使用这个关键字修饰的变量,就表示这个变量属于 “易失”、“易变” 的,编译器就不能对其进行优化了
使用 volatile 关键字优化示例代码:
加上 volatile 关键字之后,flag 变量的读取操作,就不会被编译器进行优化了
注意:volatile 解决的是内存可见性问题,不能解决原子性问题
volatile 关键字不能解决上节案例中的 count++ 的原子性问题(synchronized 保证原子性,volatile 保证内存可见性)
4.3、在 JMM 中的表述
JMM(Java Memory Model):Java 内存模型,是Java 官方文档中的术语
内存可见性问题在 JMM 中的表述:
每个线程,都有一个自己的 “工作内存”,同时这些线程共享同一个 “主内存”。当读取线程循环进行上述读取变量操作的时候,就会把主内存中的数据,拷贝到该线程的工作内存中。后续修改线程修改,也是先修改自己的工作内存,然后拷贝到主内存里。由于编译器优化后,读取线程仍然在读自己的工作内存,感知不到主内存的变化,就出现了内存可见性问题
分析:
1. 读取线程和修改线程:两个线程,一个线程进行读取,一个线程进行修改
2. 这里说的工作内存,其实不是平时所说的 “内存”,而是 cpu 的寄存器;主内存才是平时所说的内存,所以这段话和前面讲的,把读内存的操作,优化成读寄存器操作,是一个意思
3. 之所以表述不一样,其实是翻译的问题。工作内存:work memory,主内存:main memory。memory 这个单词,其实只表示 “存储” 的意思,main memory 才是真正所说的内存。而日常表达的时候,表示 “内存” 这个词也会使用 memory 简写,所以这个词也能翻译成内存。因此 work memory 应该理解成 “存储空间”
4. Java 文档上没有明确说 "寄存器"(register),而是使用更抽象的 work memon 表示,是为了能够兼容不同的硬件设备,因为不同的 cpu,用来缓存上述内存数据的区域,可能是不同的
缓存:
5. 寄存器虽然快,但空间太小,存不了多少东西。于是 cpu 的开发人员就在 cpu 上另外建设了一些存储空间,称为 “缓存”
6. 最早的 cpu 没有缓存,后来有了 L1 缓存,再后来又有了 L1+L2 缓存,现在是 L1+L2+L3缓存,未来还可能会有 L4
7. 缓存的存储空间越小,速度越快。上图中 L1 缓存速度最快,但最慢的 L3 缓存也比内存快得多
8. 内存数据缓存到 cpu 里,具体是在寄存器上,还是 L1 / L2 / L3 缓存上,是不确定的。所以 Java 文档为了表示这些情况,统一用 work memory 来表示,而不是明确说寄存器

5、指令重排序
也是编译器优化的一种体现形式。编译器会在逻辑不变的前提下,调整代码执行的先后顺序,以达到提升性能的效果。在多线程环境下,编译器的判断也可能出现失误
volatile 的功能有两方面:
1. 确保每次读取操作,都是读内存
2. 关于该变量的读取和修改操作,不会触发重排序