欠拟合和过拟合的特征标志,有什么方法解决,又该如何避免
这是一张欠拟合 vs 过拟合的对照总结表,把特征标志 → 解决方法 → 避免策略一次性梳理清楚 📊
整理 by Moshow郑锴@https://zhengkai.blog.csdn.net/
🤖 欠拟合 & 过拟合 总览表
| 类型 | 特征标志 | 常见原因 | 解决方法 | 避免策略 |
|---|---|---|---|---|
| 欠拟合 (Underfitting) | - 训练集误差高,测试集误差也高 - 模型无法捕捉数据的主要趋势 - 学习曲线在低精度水平趋于平稳 | - 模型过于简单(特征不足、参数少) - 特征表达能力弱 - 正则化过强 - 训练不足(迭代次数少) | - 增加特征数量或多样性 - 使用更复杂的模型(如增加模型参数、换更强算法) - 降低正则化强度 - 增加训练时间或轮数 | - 在建模前做好特征工程 - 选用合适复杂度的模型 - 适度正则化,避免过度约束 |
| 过拟合 (Overfitting) | - 训练集误差极低,测试集误差高 - 学习曲线显示训练集和验证集差距大 - 模型对噪声敏感,泛化差 | - 模型过于复杂(参数太多) - 特征过多且无关特征多 - 数据量不足 - 缺乏正则化 | - 增加训练数据量 - 特征选择/降维,去除无关特征 - 增强正则化(L1/L2、Dropout) - 使用交叉验证调参 - 采用集成方法(Bagging、Boosting) | - 在建模过程中实时监控验证集表现 - 使用早停法(Early Stopping)防止过训练 - 保持模型复杂度与数据规模匹配 - 数据增强(尤其是图像/文本任务) |
💡 小贴士
- 欠拟合像“没学会就去考试”,过拟合则是“死记硬背答案”。
- 理想状态是找到偏差-方差平衡点,既能很好地拟合训练数据,又能对新数据泛化。
- 整理 by Moshow郑锴@https://zhengkai.blog.csdn.net/
偏差-方差权衡图 📈
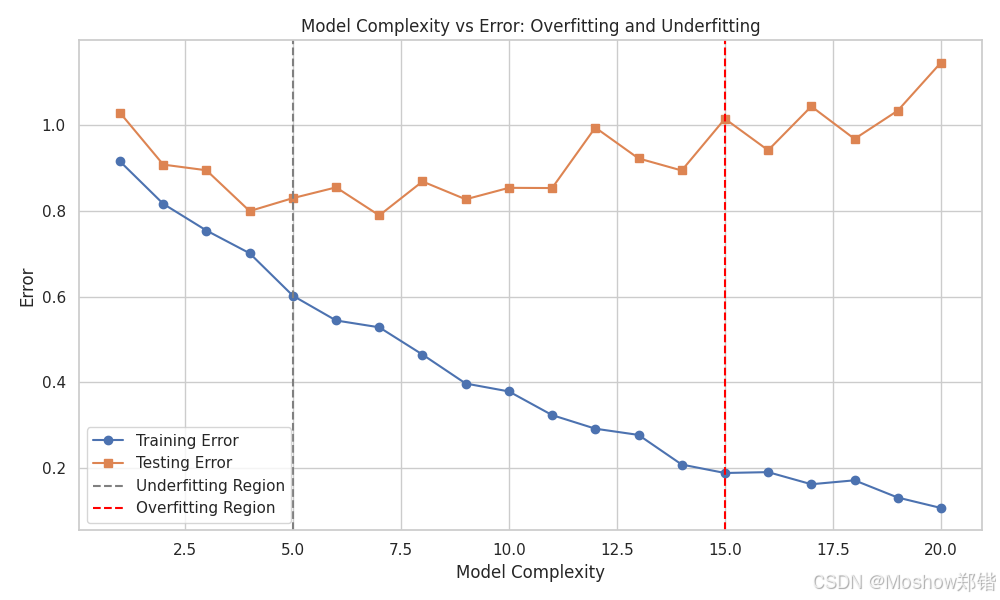
用模型复杂度和误差变化趋势来直观展示它们的区别:
-
左侧(欠拟合区):模型太简单,训练误差和测试误差都很高,没学到数据的主要规律
-
中间(最佳拟合区):训练误差和测试误差都较低,泛化能力最佳
-
右侧(过拟合区):模型太复杂,训练误差极低但测试误差升高,对噪声过度敏感
你可以点击上方的图片卡片查看高清版本,放大后能清楚看到:
-
蓝色曲线:训练误差随复杂度变化
-
橙色曲线:测试误差随复杂度变化
-
虚线标注了欠拟合区和过拟合区的位置