LangChain4j
目录
大模型部署
自己部署(本机)
其他部署
大模型调用
常见参数
响应数据
LangChain4j
会话功能
快速入门
Spring整合LangChain4j
AiServices工具类
声明式使用
流式调用
消息注解
会话记忆
会话记忆隔离
会话记忆持久化
RAG知识库
原理
快速入门
1.存储(构建向量数据库操作对象)
2.检索(构建向量数据库检索对象)
核心API
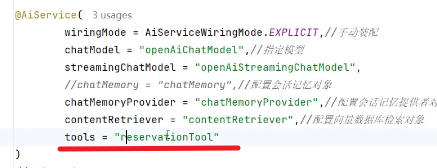
Tools工具
原理
实现
大模型部署
自己部署(本机)
Ollama是一种用于快速下载、部署、管理大模型的工具,官网地址:Ollama
可以使用postman来访问大模型
Ollama默认端口为11434
其他部署
阿里云百炼、智能百度云等都是其他公司部署的大模型,我们只需要调用api即可
大模型调用
常见参数
使用大模型需要传递的参数,在不同的平台都会给出详细的说明,并且不同平台的核心参数,基本都一致

system的作用是给大模型设定一个角色
响应数据


LangChain4j
会话功能
快速入门
1.引入Langchain4j依赖
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-open-ai</artifactId><version>1.0.1</version></dependency>2.构建OpenAiChatModel对象
3.调用chat方法与大模型交互
public class App
{public static void main( String[] args ){OpenAiChatModel model = OpenAiChatModel.builder().baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1").apiKey("api-key").modelName("qwen-plus").build();String result = model.chat("刘强东是谁");System.out.println(result);}
}

4.引入logback依赖,并设置logRequests和logResponses(可选)
OpenAiChatModel model = OpenAiChatModel.builder().baseUrl("https://dashscope.aliyuncs.com/compatible-mode/v1").apiKey("sk-0c6b65d9b9ac40eda1ad15b0e635ef71").modelName("qwen-plus").logRequests(true).logResponses(true).build();Spring整合LangChain4j
1.构建springboot项目
2.引入起步依赖
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-open-ai-spring-boot-starter</artifactId><version>1.0.1-beta6</version></dependency>
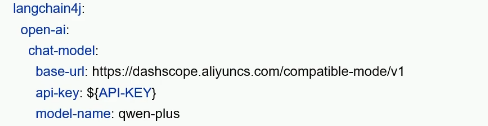
3.application.yml中配置大模型
4.开发接口,调用大模型
@RestController
public class ChatController {@Autowiredprivate OpenAiChatModel model;@RequestMapping("/chat")public String chat(String message) {//浏览器传递的用户问题String result =model.chat(message);return result;}}AiServices工具类
1.引入依赖
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-spring-boot-starter</artifactId><version>1.0.1-beta6</version></dependency>2.声明接口
3.使用AiServices为接口创建代理对象
@Configuration
public class CommonConfig {@Autowiredprivate OpenAiChatModel model;@Beanpublic ConSultantService conSultantService(){ConSultantService conSultantService =AiServices.builder(ConSultantService.class).chatModel(model).build();return conSultantService;}
}4.在Controller中注入并使用
@Autowiredprivate ConSultantService conSultantService;@RequestMapping("/chat")public String chat(String message) {return conSultantService.chat(message);
}声明式使用
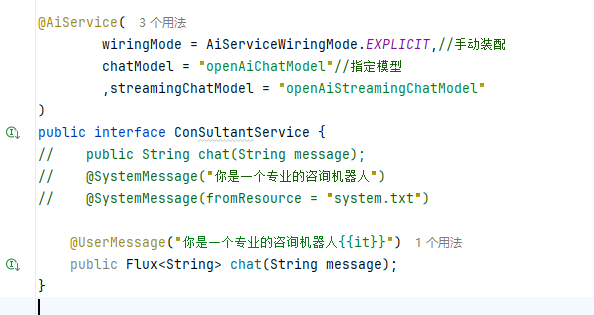
@AiService(wiringMode = AiServiceWiringMode.EXPLICIT,chatModel = "openAiChatModel"
)
public interface ConSultantService {public String chat(String message);
}流式调用
1.引入依赖
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-webflux</artifactId></dependency><dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-reactor</artifactId><version>1.0.1-beta6</version></dependency>
2.配置流式模型对象
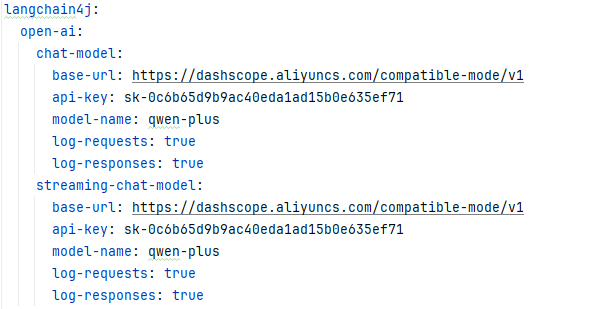
3.切换接口中方法的返回值类型
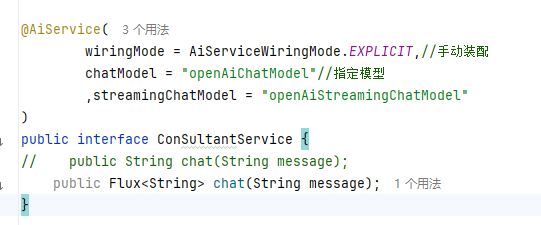
4.修改Controller中的代码
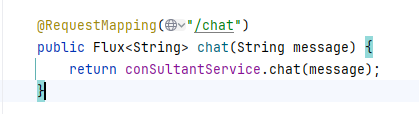
解决乱码问题
@RequestMapping(value = "/chat",produces = "text/html;charset=utf-8"
消息注解
@SystemMessage
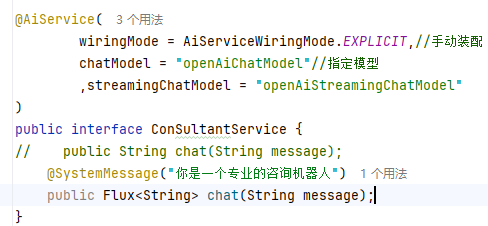
方法2
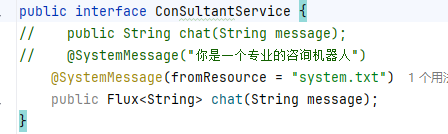
@UserMessage
只能用it来表示,或者用@V注解
会话记忆
大模型式不具备记忆能力的,要想让大模型记住之前聊天的内容,唯一的办法就是把之前聊天的内容与新的提示词一起发送给大模型。
1.定义会话记忆对象
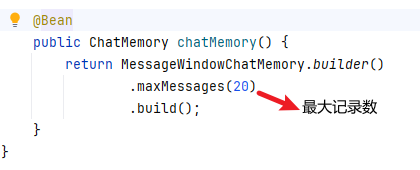
2.配置会话记忆对象
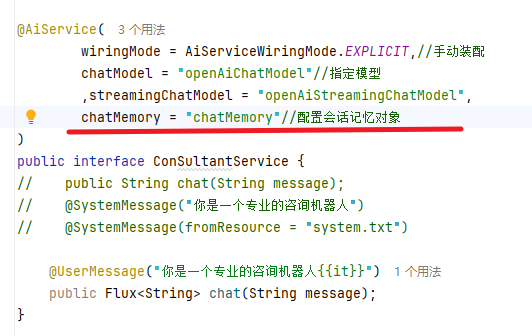
会话记忆隔离
刚才做的会话记忆,所有会话使用的是 同一个记忆存储对象,因此不同会话之间的记忆并没有做到隔离

1.定义会话记忆对象提供者
@Beanpublic ChatMemoryProvider chatMemoryProvider() {ChatMemoryProvider chatMemoryProvider = new ChatMemoryProvider() {@Overridepublic ChatMemory get(Object memoryId) {return MessageWindowChatMemory.builder().id(memoryId).maxMessages(20).build();}};return chatMemoryProvider;}2.配置会话记忆对象提供者

3.ConsultantService接口方法中添加参数memoryId
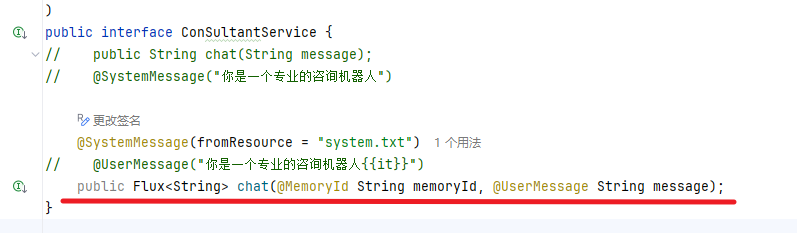
4.Controller中chat接口接收memoryId
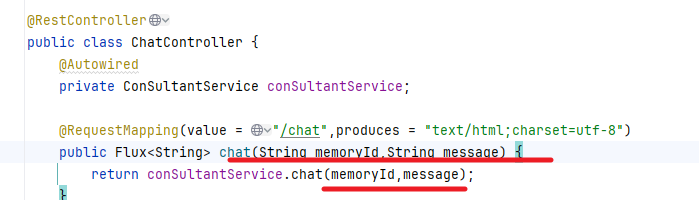
5.前端页面请求时传递memoryId
会话记忆持久化
刚才所做的会话记忆,只要后端重启,会话记忆就没有了
redis:nosql,非关系形数据库
1.准备redis环境
2.引入redis起步依赖
3.配置redis连接信息
4.提供ChatMemoryStore实现类
5.配置ChatMemoryStore

RAG知识库
原理
RAG:检索增强生成。通过检索外部知识库的方式增大模型的生成能力。
原本流程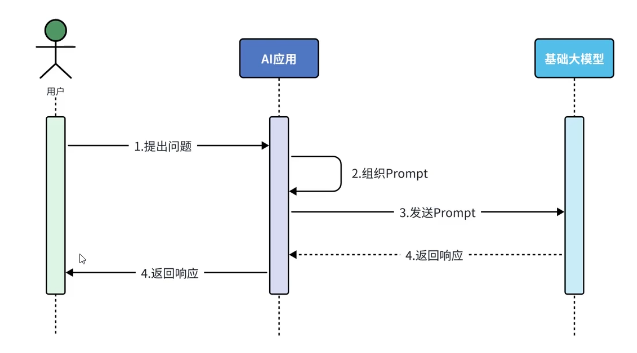
增加外部知识库后流程
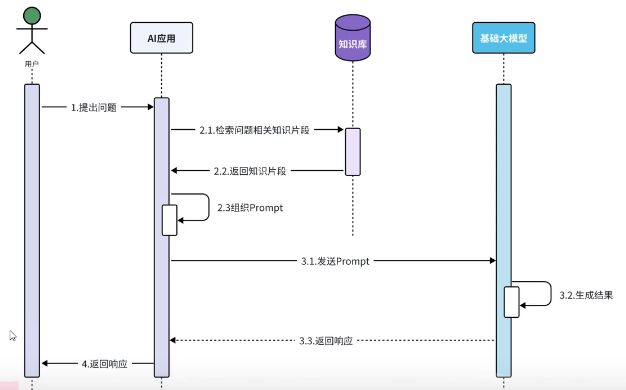
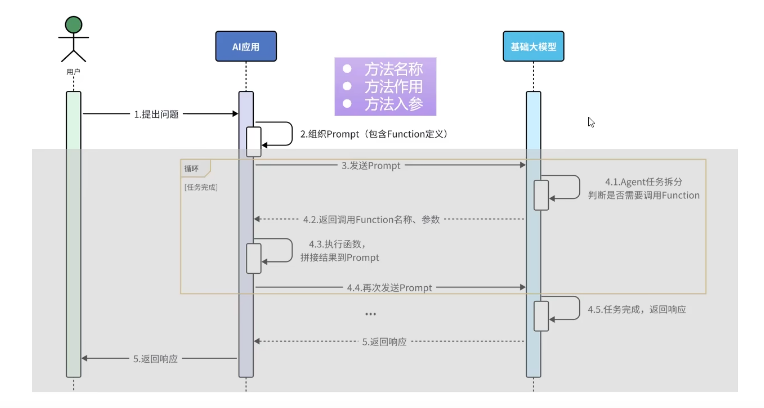
langchain4j能够完成组织Prompt及其以下的操作,我们需要关注的只有知识库如何搭建,以及用户如何检索出相应的片段
向量数据库:Milvus、Chroma、Pinecone、RedisSearch(Reids)、pgvector(PostgreSQL)
向量:是数学和物理中表示大小和方向的量
几何表示
有向线段,向量可以用一条带箭头的线段表示,线段的长度表示大小,箭头表示方向。
代数表示
坐标表示,在直角坐标系中,向量可以用一组坐标来表示
向量的余弦相似度,用于表示坐标系中两个点之间的距离远近
余弦相似度越大,说明向量方向越近,两点之间的距离越小
知识库存储流程:
把专业数据存储在文本中----->借助文本分割器将大的文档切割成一个个小的文本片段----->用专门的大模型,向量模型将一个个文本片段转换为向量----->把每个向量和对应的文本片段存储在向量数据库中
如何从向量数据库中检索出和用户信息相关的文本片段:
将用户提供的文本消息转化为向量----->与向量数据库中的向量进行比对----->得到对应的文本片段---->集合用户问题共同组成要提交的消息
快速入门
1.存储(构建向量数据库操作对象)
引入依赖
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-easy-rag</artifactId><version>1.0.1-beta6</version></dependency>加载知识数据文档
![]()
构建向量数据库操作对象
把文档切割、向量化并存储到向量数据库中
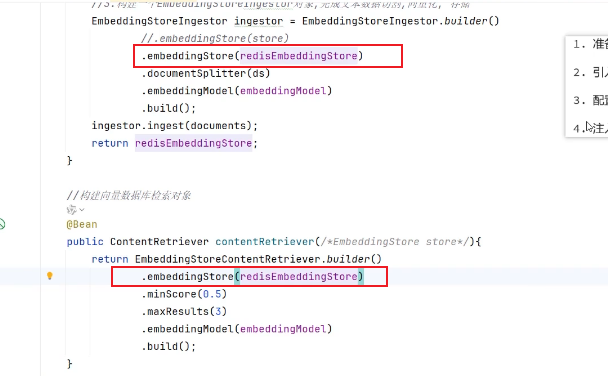
//构建向量数据库操作对象@Beanpublic EmbeddingStore embeddingStore() {//1.加载文档进内存List<Document> documents = ClassPathDocumentLoader.loadDocuments("content");//2.构建向量数据库操作对象InMemoryEmbeddingStore store = new InMemoryEmbeddingStore();//3.构建一个EmbeddingStoreIngest对象,完成文本数据切割,向量化,存储。EmbeddingStoreIngestor ingestor = EmbeddingStoreIngestor.builder().embeddingStore(store).build();ingestor.ingest(documents);return store;}2.检索(构建向量数据库检索对象)
构建向量数据库检索对象
//构建向量数据库检索对象@Beanpublic ContentRetriever contentRetriever(EmbeddingStore embeddingStore) {return EmbeddingStoreContentRetriever.builder().embeddingStore(embeddingStore).minScore(0.5) //相似度阈值.maxResults(3) //返回结果数量.build();}配置向量数据库检索对象
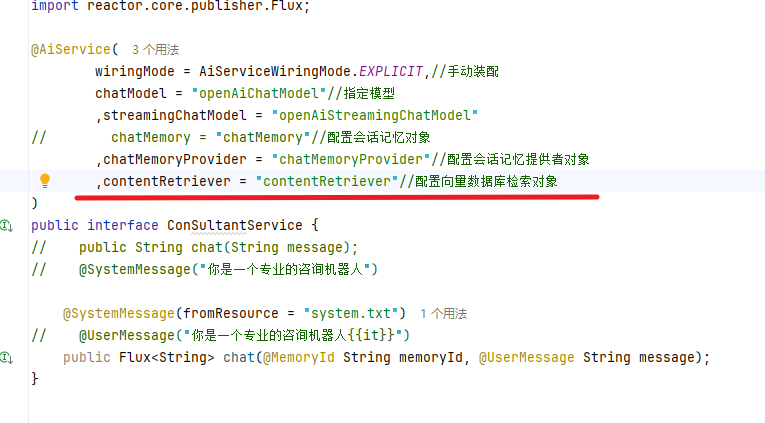
核心API
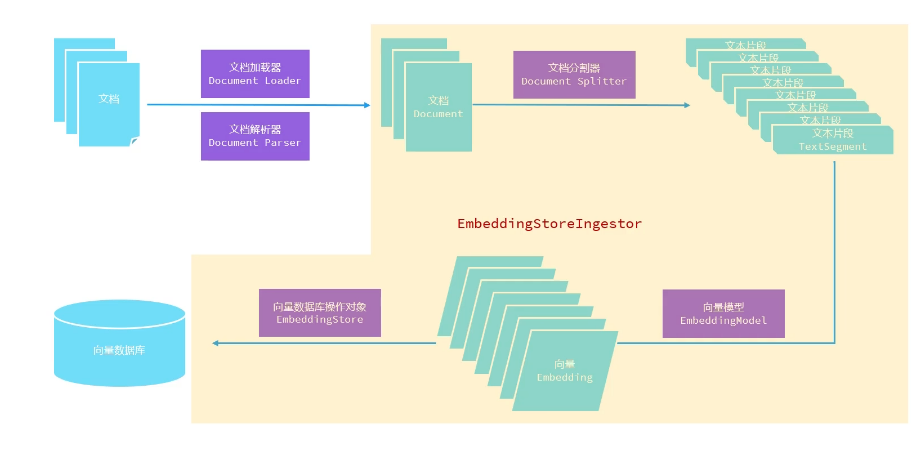
文档加载器,用于把磁盘或者网络中的数据加载进程序
以下为langchain4j提供的方法
FileSystemDocumentLoader,根据本地磁盘绝对路径加载
ClassPathDocumentLoader,根据类路径加载
UrlDocumentLoader,根据url路径加载
文档解析器,用于解析使用文档加载器加载进内存的内容,把非纯文本数据转化为纯文本
以下为langchain4j提供的方法
TextDocumentParser - 解析纯文本格式的文件
ApachePdfBoxDocumentParser - 解析PDF格式文件
ApachePoiDocumentParser - 解析微软的Office文件(例如DOC、PPT、XLS)
ApacheTikaDocumentParser(默认) - 几乎可以解析所有格式的文件
如果需要切换文本解析器
1.准备pdf格式的数据
2.引入依赖
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-document-parser-apache-pdfbox</artifactId><version>1.0.1-beta6</version> </dependency>
3.指定解析器

文档分割器,用于把一个大的文档,切割成一个一个的小片段
DocumentByParagraphSplitter - 按照段落分割文本
DocumentByLineSplitter - 按照行分割文本
DocumentBySentenceSplitter - 按照句子分割文本
DocumentByWordSplitter - 按照词分割文本
DocumentByCharacterSplitter - 按照固定数量的字符分割文本
DocumentByRegexSplitter - 按照正则表达式分割文本
DocumentSplitters.recursive(..)(默认) - 递归分割器,优先段落分割,再按照行分割,再按照句子分割
切换文本分割器
1.构建文本分割器对象

2.设置文本分割器对象

向量模型,用于把文档分割后的片段向量化或者查询时把用户输入的内容向量化
更换向量模型
1.配置向量模型信息
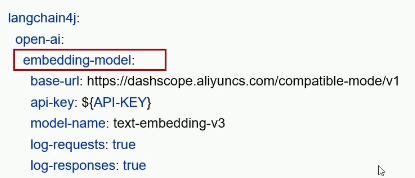
2.设置EmbeddingModel
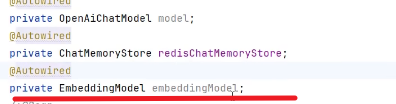
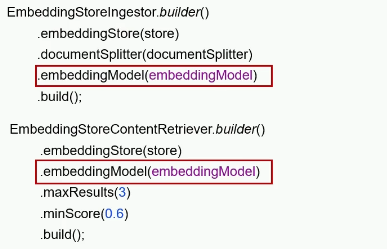
EmbeddingStore,用于操作向量数据库(添加、检索)
1.准备向量数据库
![]()
2.引入依赖
<dependency><groupId>dev.langchain4j</groupId><artifactId>langchain4j-community-redis-spring-boot-starter</artifactId><version>1.0.1-beta6</version></dependency>
3.配置向量数据库信息

4.注入RedisEmbeddingStore并使用
![]()
Tools工具
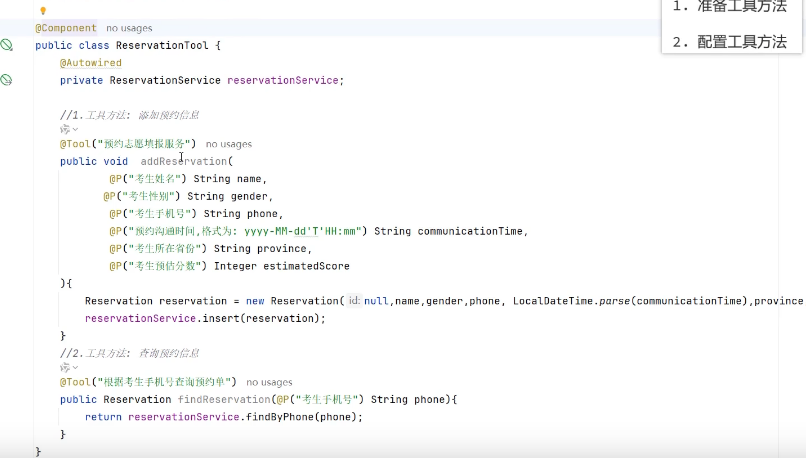
准备工作:开发一个预约信息服务,可以读写MySql中预约表中的信息
原理
实现
1.准备工具方法
2.配置工具方法