基于粒子群优化算法优化支持向量机的数据回归预测 PSO-SVM
一、作品详细简介
1.1附件文件夹程序代码截图

全部完整源代码,请在个人首页置顶文章查看:
学行库小秘_CSDN博客编辑https://blog.csdn.net/weixin_47760707?spm=1000.2115.3001.5343
1.2各文件夹说明
1.2.1 main.m主函数文件
该代码实现了使用PSO优化SVR的参数,并在回归问题上进行预测和评估的整个流程。以下是对代码实现步骤的详细解释:
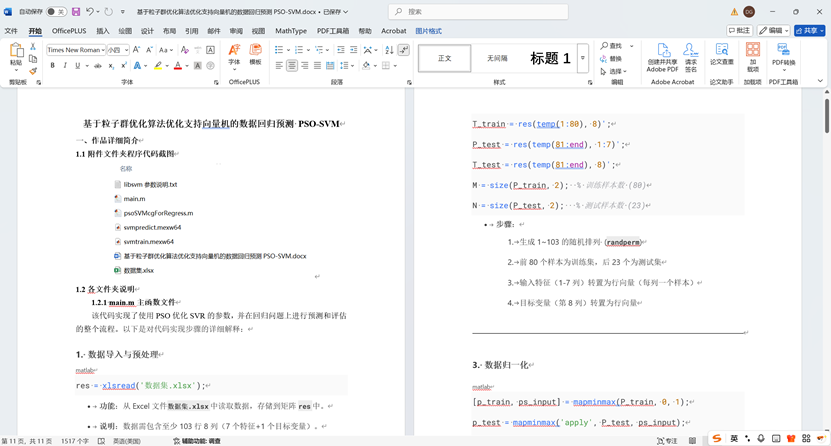
1. 数据导入与预处理
- 功能:从Excel文件数据集.xlsx中读取数据,存储到矩阵res中。
- 说明:数据需包含至少103行8列(7个特征+1个目标变量)。
2. 划分训练集和测试集
- 步骤:
- 生成1~103的随机排列 (randperm)
- 前80个样本为训练集,后23个为测试集
- 输入特征(1-7列)转置为行向量(每列一个样本)
- 目标变量(第8列)转置为行向量
3. 数据归一化
- 功能:将数据归一化到[0,1]区间
- 步骤:
- 对训练输入P_train归一化,保存参数ps_input
- 用相同参数归一化测试输入P_test
- 对训练输出T_train归一化,保存参数ps_output
- 用相同参数归一化测试输出T_test
4. 数据转置
- 目的:将数据转为每行一个样本的格式(适应SVM训练函数)
5. PSO参数设置
- 关键参数:
- c1=1.5:个体学习因子
- c2=1.7:社会学习因子
- maxgen=100:最大迭代次数
- sizepop=10:粒子群规模
- popcmin/popcmax=[0.1,100]:SVM参数C的范围
- popgmin/popgmax=[0.1,100]:SVM参数g的范围
6. PSO优化SVM参数
- 功能:使用粒子群算法(PSO)优化SVM的惩罚参数C和核参数g
- 输出:
- bestc:最优的C值
- bestg:最优的g值
- bestacc:最优精度
7. 训练SVM模型
- 参数说明:
- -t 2:使用RBF核函数
- -s 3:支持向量回归(SVR)
- -p 0.01:设置不敏感损失函数参数ε
8. 模型预测
- 输出:
- t_sim1/t_sim2:训练集/测试集的预测值
- error_1/error_2:预测误差指标
9. 数据反归一化
- 功能:将预测结果转换回原始数据量纲
10. 计算误差指标
- 指标说明:
- RMSE:衡量预测值与真实值的偏差
- R²:模型拟合优度(越接近1越好)
- MAE:绝对误差的平均值
- MBE:系统偏差方向(正/负)
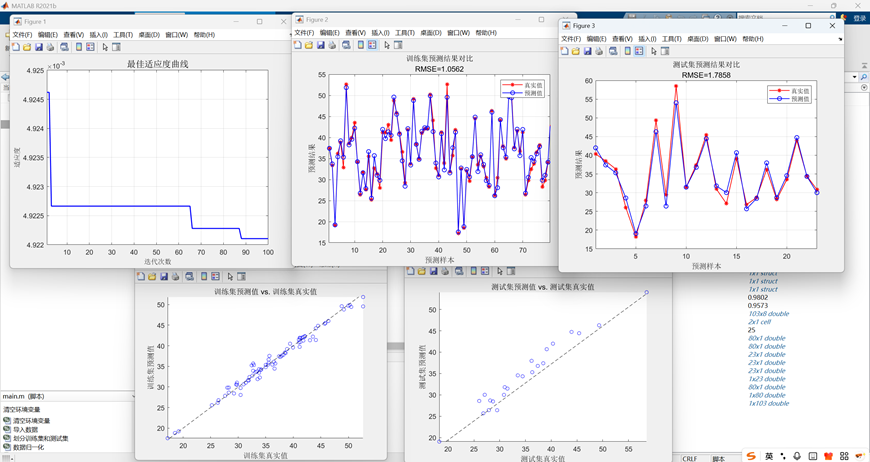
11. 结果可视化
- 可视化内容:
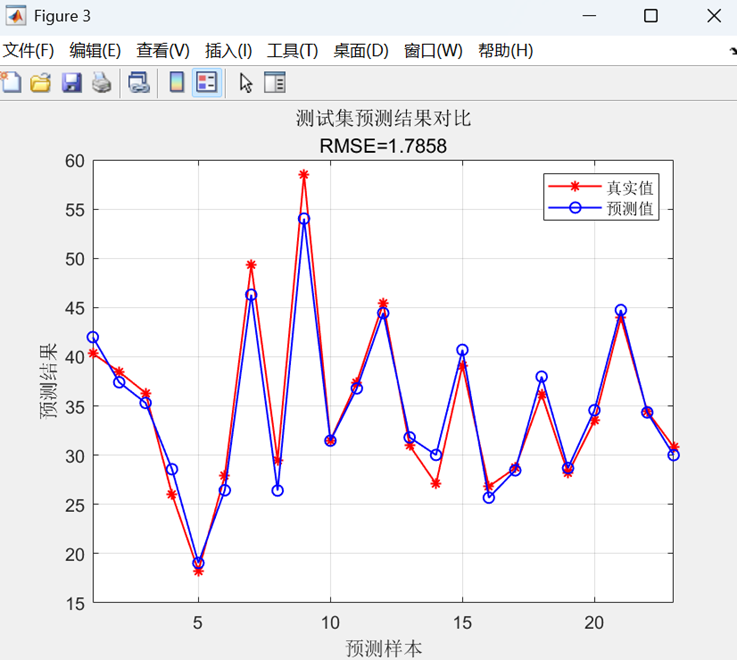
- 训练集/测试集预测值与真实值对比曲线
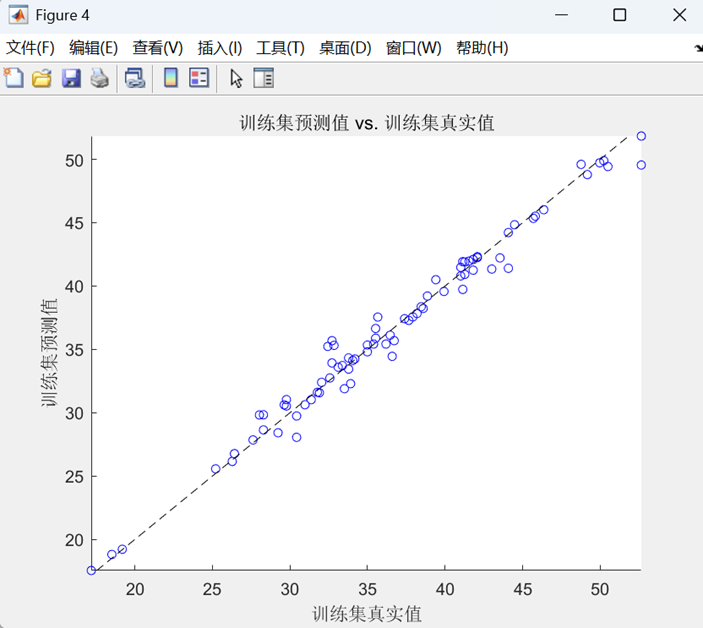
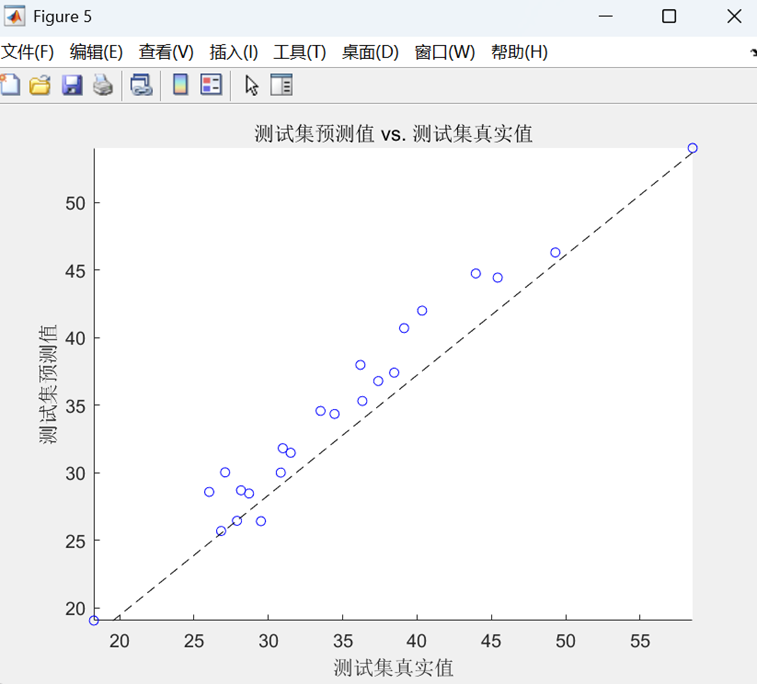
- 预测值-真实值散点图(带参考对角线)
- 所有图表均标注RMSE值
代码流程总结
- 数据准备:导入→随机划分→归一化
- 模型优化:使用PSO算法搜索最优SVM参数
- 模型训练:用最优参数训练SVR模型
- 预测评估:预测→反归一化→计算多维度误差指标
- 结果展示:预测对比图 + 散点图 + 数值指标输出
该代码实现了完整的机器学习建模流程,特别通过PSO优化解决了SVR参数选择难题,适用于中小规模回归预测问题。
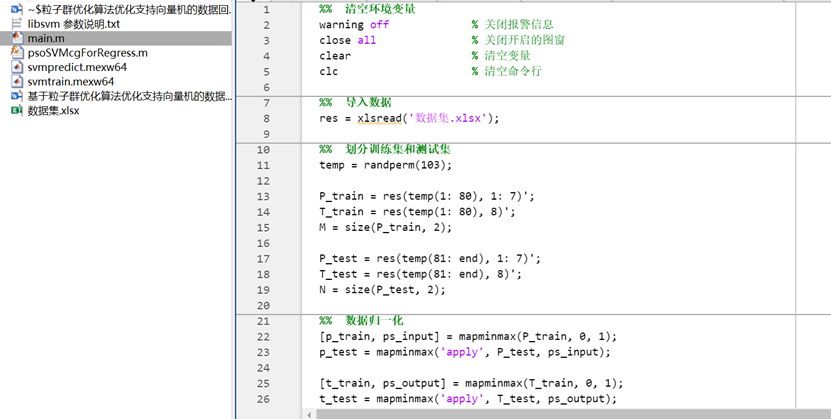
图2 main.m主函数文件部分代码
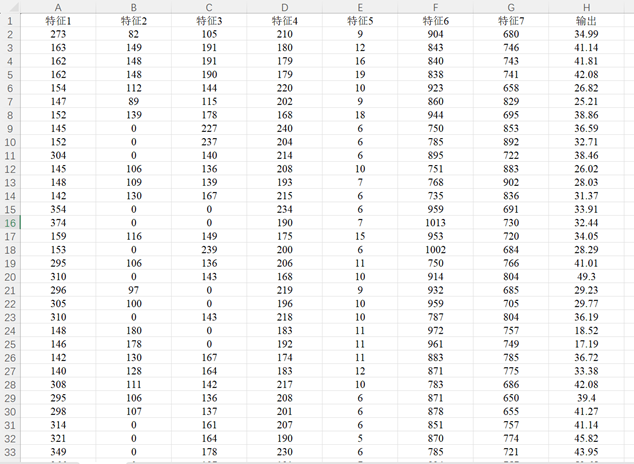
1.2.2 数据集文件
数据集为Excel数据csv格式文件,可以方便地直接替换为自己的数据运行程序。原始数据文件包含7列特征列数据和1列输出标签列数据,一共包含103条样本数据,具体如图所示。
二、代码运行结果展示
该代码实现了基于粒子群优化支持向量机的回归预测模型。
首先,从Excel导入数据集并随机划分为80个训练样本和23个测试样本,对特征和目标变量进行归一化处理;
其次,利用粒子群算法(PSO)优化支持向量机(SVM)的惩罚参数C和核参数g,使用最优参数训练SVM回归模型;
最后,在训练集和测试集上进行预测,通过反归一化得到最终结果,计算RMSE、R²、MAE等评估指标,并绘制预测对比曲线和散点图进行可视化分析。
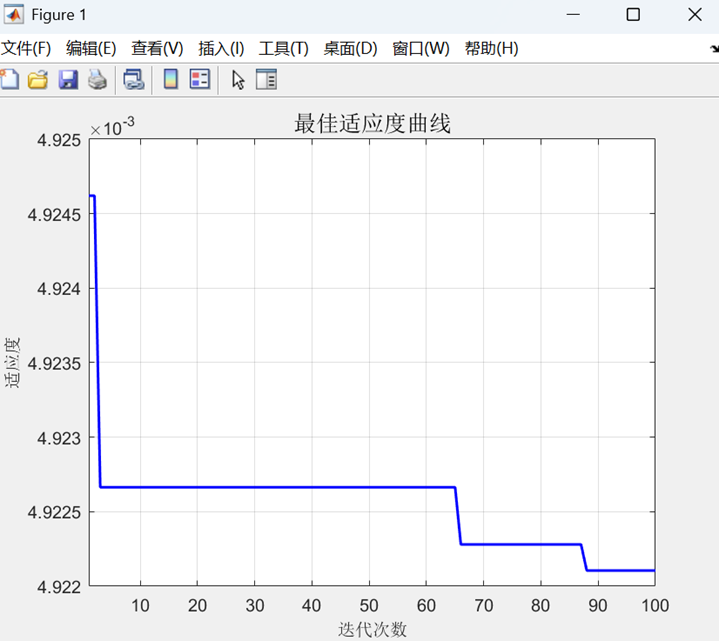
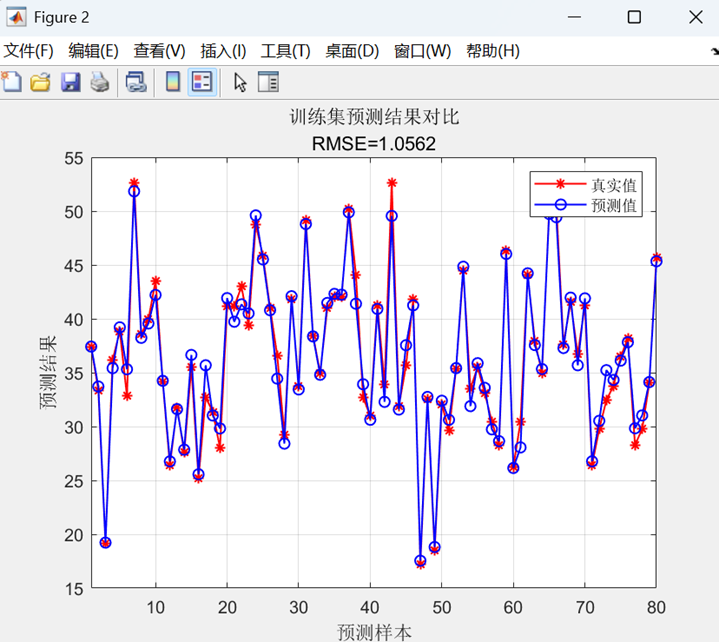
三、注意事项:
1.程序运行软件推荐Matlab 2018B版本及以上;
2.所有程序都经过验证,保证程序可以运行。此外程序包含简要注释,便于理解。
3.如果不会运行,可以帮忙远程运行原始程序以及讲解和其它售后,该服务需另行付费。
4. 代码包含详细的文件说明,以及对每个程序文件的功能注释,说明详细清楚。
5.Excel数据,可直接修改数据,替换数据后直接运行即可。