Critic-V: VLM Critics Help Catch VLM Errors in Multimodal Reasoning(CVPR 2025)
研究方向:Image Captioning
1. 论文介绍
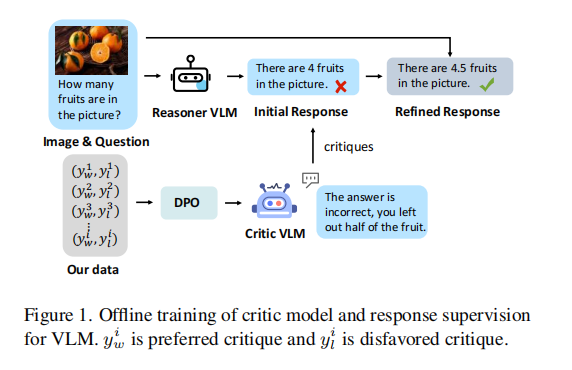
本文中提出了一个基于人类反馈强化学习(RLHF)的框架,用于在VLM的生成过程中引入外部高质量的监督和反馈,以有效减少错误并增强其推理路径的可靠性。该框架通过整合两个独立组件来解耦推理过程和评论过程:Reasoner(推理模型),负责生成候选答案;Critic(批评模型),负责对候选答案进行评估。
根据视觉和文本输入生成推理路径,并由Critic(批评模型)提供建设性批评以精炼这些路径。在此方法中,Reasoner(推理模型)根据文本提示生成推理响应,这些响应可以根据Critic(批评模型)的反馈迭代演变为策略。
2. 方法介绍
Reasoner–Critic 框架
数据生成
从 VQA 数据集中拿到 图像–问题–正确答案。
用 GPT-4o 在正确答案中插入 1–5 个虚假细节(错误)。
这些“退化版答案”作为模拟错误的参考。
批评生成
让多个 VLM对这些“错误答案”写出批评,指出里面的问题。
于是每个问答对会有多个批评版本(质量参差不齐)。
批评分数计算(Rule-based Reward, RBR)
结合 Jaccard 指数(检测出的错误集合 vs 实际插入的错误集合和GPT-based 得到一个综合批评分数。
这个分数用来比较不同批评的优劣,构建偏好关系(哪条更好、哪条更差)。
构建偏好数据集(Critique-VQA dataset)
最终得到一个包含问题、图像、优选批评和不佳批评的数据集
训练 Critic(DPO)
在这个偏好数据集上,用 Direct Preference Optimization (DPO) 训练 Critic 模型。
DPO 的目标:让 Critic 给高质量批评更高概率,给低质量批评更低概率。
推理时应用(Reasoner–Critic Loop)
Reasoner 给出答案 → Critic 检查并反馈 → Reasoner 修正 → 迭代优化。
最终输出更准确、更可靠的推理结果。
2.1 Reasoner(推理模型)
Reasoner(推理模型)负责在给定的状态下选择适当的推理动作
。它的目标是通过优化策略函数来生成更准确的推理路径;
策略函数 决定了给定状态
时推理模型选择动作
的概率,且该策略函数由参数
控制,强化学习通过调整这些参数来优化推理过程;
值函数 估计了执行特定动作
在状态
中所期望的回报;
Critic(批评模型) 评估 Reasoner 的推理路径并计算出值函数,从而影响 Reasoner 的决策。
是对策略参数的梯度,表示策略参数更新的方向和大小。
传统标准的强化学习基于策略梯度的策略更新规则
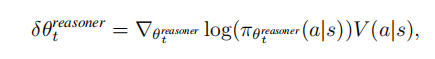
受动态文本提示(Preasoner)驱动的策略更新规则
![]()
代表当前的文本提示,
是由Critic(批评模型)提供的批评(反馈),I 是输入图像,而 Rt是奖励信号
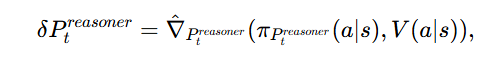
表示使用TextGrad方法计算的梯度
Critic(批评模型)对文本提示的优化
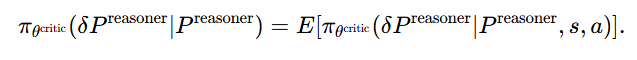
最终文本提示的更新规则
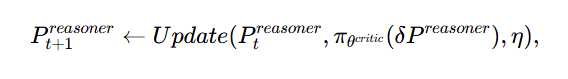
Update函数负责将评论家的反馈应用于改进文本提示Preasoner,而η代表学习率
2.2 Critic(批评模型)
Critic(批评模型)的策略参数更新
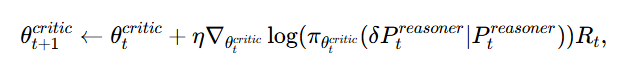
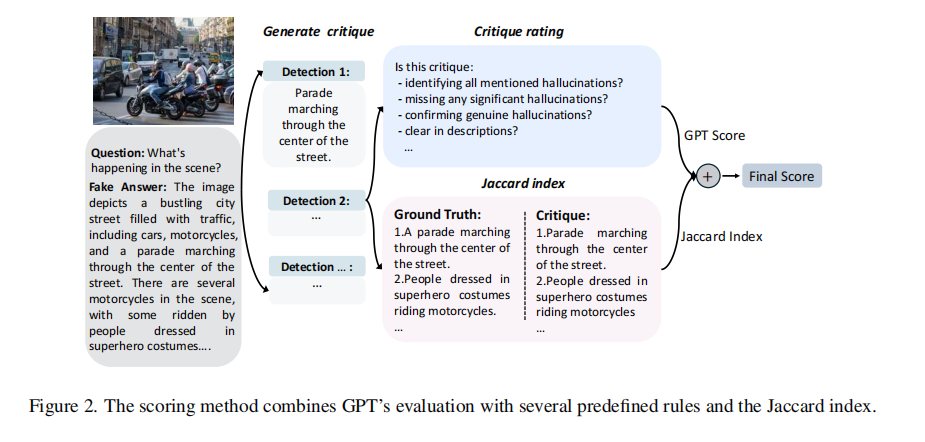
视觉错误插入技术(VEST):向 VQA 数据集中的问题-图像对的答案中插入虚假的细节来生成“退化版”答案,这些虚假的细节模拟了推理过程中可能出现的错误或不完全信息。
引入Jaccard 指数(交并比)调整较长的批评中包含的无关信息或“挑剔”,Jaccard 指数通过以下公式比较 GPT-4o 插入的错误集(G)与 VLM 检测到的错误集(C)
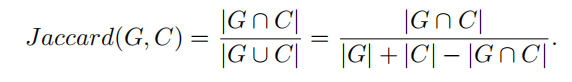
用基于规则的奖励(RBR)机制(覆盖度、准确性、描述质量)来对批评打分,批评的最终得分是Jaccard 指数和基于GPT的得分的组合
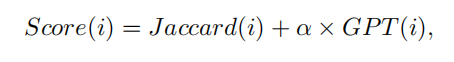
根据偏好分数得到批评排名
