《WINDOWS 环境下32位汇编语言程序设计》第3章 使用MASM
经过第2章的准备工作,相信大家都已经建好了Win32汇编的工作环境,并已经可以编译程序了,现在让我们来编译所带光盘的Chapter03\HelloWorld目录下的“Hello World”程序。这是一个相当小的程序,就和DOS时代下经典的“Hello World”程序一样,并没有涉及系统中很多的东西,甚至连Windows系统中基本的消息驱动机制也没有看到,它只是简单地弹出一个消息框,在上面显示了一句“Hello,World!”,并在文字的下面显示了一个“确定”按钮,就停在那里了,当用户按下“确定”按钮时,程序退出,同时消息框消失。这个程序运行的结果如图3.1所示。
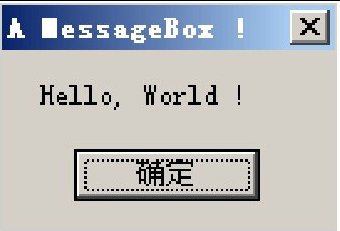
图3.1 Win32汇编的Hello,World程序
但这样一个小程序从结构来看,“麻雀虽小,五脏俱全”,用它来举例说明Win32汇编源程序的框架是最合适不过的了,本章将从这个程序出发,探讨MASM在Win32汇编中的用法,由于篇幅所限,讨论的内容只涉及MASM在Win32编程中常用的部分。
3.1 Win32汇编源程序的结构
任何种类的语言,总是有基本的源程序结构规范,在讨论C语言的书中,大家都会记得这个非常经典的“Hello World”程序:
#include <stdio.h>main(){printf("Hello, world\n");}像这样一个程序,就说明了C语言中最基本的格式,main()中的括号和下面的花括号说明了一个函数的定义方法,printf语句是对函数典型的调用方法,调用函数语句后面的分号也是基本的格式。C是一种高级语言,在C源程序中,不必为堆栈段、数据段和代码段的定义而担心,编译器会把程序中的字符串和语句代码分别放到它们该去的地方,程序开始执行的时候也会自己找到main()函数。而汇编是低级语言,必须为所有的语句找到它们该去的地方,所以在DOS的汇编中,Hello World又长成了这样一副模样:
【学习笔记】
;16bit.asm DOS环境下的汇编语言
;在XP系统环境下运行,使用masm命令进行编译和链接:
;masm 16bit.asm;
;link16 16bit.obj;
;堆栈段
stack segment
db 100 dup(?)
stack ends
;数据段
data segment
szHello db 'Hello, world',0dh,0ah,'$'
data ends
assume cs:code, ds:data, ss:stack
;代码段
code segment
start:mov ax, data mov ds, ax mov ah, 9mov dx, offset szHello int 21hmov ah, 4chint 21h
code ends
end start 用16位编译器编译调试:masm 16bit.asm; 生成16bit.OBJ文件,link16 16bit.obj; 生成16bit.exe
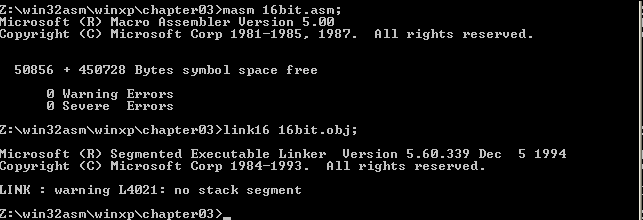
用debug调试:
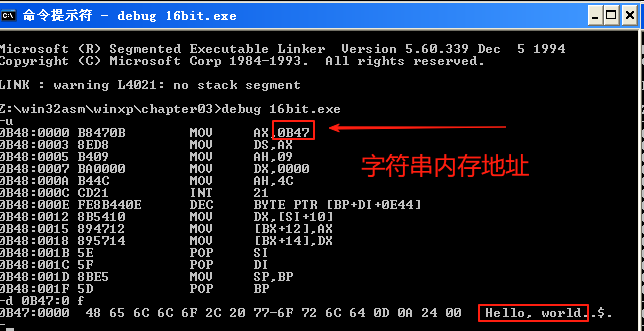
在这个源程序中,stack段为堆栈找了个家,hello world字符串跑到数据段中去了,代码则放在代码段中,程序的开始语句必须由最后一句end start来说明应该从start这个标号开始执行,整个程序在使用过DOS汇编的程序员眼里是非常的熟悉。
到了Win32汇编的时候,程序的基本结构还是如此,先来看一看这个看起来很新鲜的Win32的Hello World程序:
【学习笔记】
;Hello.asm Windows环境下32位汇编语言
;在XP系统环境下运行,使用ml命令进行编译和链接:
;ml /c /coff Hello.asm
;link /subsystem:windows Hello.obj
.386
.model flat,stdcall
option casemap:none ;区分大小写
;include文件定义
include windows.inc
include user32.inc
includelib user32.lib
include kernel32.inc
includelib kernel32.lib;数据段
.data
szCaption BYTE 'A MessageBox !', 0
szText BYTE 'Hello, World !', 0;代码段
.code
start:invoke MessageBox, NULL, offset szText, offset szCaption, MB_OKinvoke ExitProcess, 0
end start 使用masm32开发包工具进行编译,链接。然后运行Hello.exe,下面是运行效果:
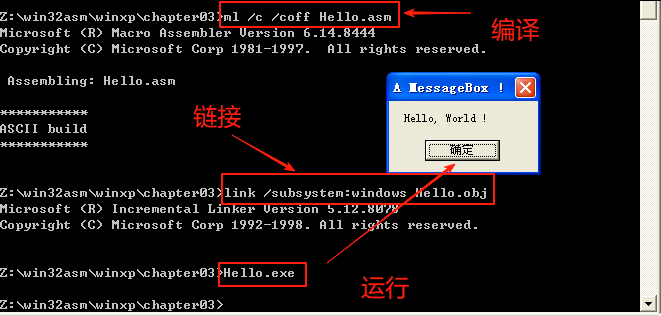
怎么样,看来和上面的C及DOS汇编又不同了吧!但从include,.data和.code等语句“顾名思义”也能看出一点苗头来,include应该就是包含别的文件,.data想必是数据段,.code应该就是代码段了吧!接下来通过这个例子程序逐段介绍Win32汇编程序的结构。
3.1.1 模式定义
程序的第一部分是模式和源程序格式的定义语句:
.386
.model flat,stdcall
option casemap:none这些指令定义了程序使用的指令集、工作模式和格式。
1.指定使用的指令集
.386语句是汇编语言的伪指令,它在低版本的宏汇编中就已经存在,类似的指令还有.8086, .1 86, .286, .386/.386p, .486/.486p和 .586/.586p等,用于告诉编译器在本程序中使用的指令集。在DOS的汇编中默认使用的是8086指令集,那时候如果在源程序中写入80386所特有的指令或使用32位的寄存器就会报错,为了在DOS环境下进行保护模式编程或仅为了使用32位寄存器,常在DOS的汇编中使用 .386来定义。Win32环境工作在80386及以上的处理器中,所以.386这一句是必不可少的。
后面带p的伪指令则表示程序中可以使用特权指令,如:
mov cr0, eax
这一类指令必须在特权级0上运行,如果只指定 .386,那么使用普通的指令是可以的,编译时到这一句就会报错,如果我们要写的程序是VxD等驱动程序,中间要用到特权指令,那么必须定义 .386p,在应用程序级别的Win32编程中,程序都是运行在优先级3上,不会用到特权指令,只需定义 .386就够了。80486和Pentium处理器指令是80386处理器指令的超集,同理,如果程序中要用80486处理器或Pentium处理器的指令,则必须定义 .486或 .586。另外,Intel公司的80x86系列处理器从Pentium MMX开始增加了MMX指令集,为了使用MMX指令,除了定义 .586之外,还要加上一句 .mmx伪指令:
.586
.mmx
2..model语句
.model语句在低版本的宏汇编中已经存在,用来定义程序工作的模式,它的使用方法是:
.model 内存模式 [,语言模式][,其他模式]
内存模式的定义影响最后生成的可执行文件,可执行文件的规模从小到大,可以有很多种类型,在DOS的可执行程序中,有只用到64 KB的 .com文件,也有大大小小的 .exe文件。到了Win32环境下,又有了可以用4 GB内存的PE格式可执行文件,编写不同类型的可执行文件要用 .model语句定义不同的参数,具体如表3.1所示。
表3.1 内存模式 | |
模式 | 内存使用方式 |
tiny | 用来建立.com文件,所有的代码、数据和堆都在同一个64KB段内 |
small | 建立代码和数据分别用一个64KB段的.exe文件 |
medium | 代码段可以有多个64KB段,数据段只有一个64KB段 |
compact | 代码段只有一个64KB段,数据段可以有多个64KB段 |
large | 代码段和数据段都可以有多个64KB段 |
huge | 同large,并且数据段中的一个数组也可以超过64KB |
flat | Win32程序使用的模式,代码和数据段使用同一个4GB段 |
在前面章节中已经提到过:Windows程序运行在保护模式下,系统把每一个Win32应用程序都放到分开的虚拟地址空间中去运行,也就是说,每一个应用程序都拥有其相互独立的4 GB地址空间,对Win32程序来说,只有一种内存模式,即flat(平坦)模式,意思是内存是很“平坦”地从0延伸到4 GB,再没有64 KB段大小限制。对比一下DOS版本的Hello World和Win32版本的Hello World开始部分的不同,DOS程序中有这样两句:
mov ax,data
mov ds,ax意思是把数据段寄存器DS指向data数据段,data数据段在前面已经用data segment语句定义,只要DS不重新设置,那么从此以后指令中涉及的数据默认将从data数据段中取得,所以下面的语句是从data数据段取出szHello字符串的地址后再显示:
mov ah,9mov dx,offset szHelloint 21h纵观Win32汇编的源程序,没有一处可以找到ds或es等段寄存器的使用,因为所有的4GB空间用32位的寄存器全部都能访问到了,不必在头脑中随时记着当前使用的是哪个数据段,这就是“平坦”内存模式带来的好处。
如果定义了.model flat,MASM自动为各种段寄存器做了如下定义:
ASSUME cs:FLAT, ds:FLAT, ss:FLAT, es:FLAT, fs:ERROR, gs:ERROR
也就是说,CS,DS,ES和SS段全部使用平坦模式,FS和GS寄存器默认不使用,这时若在源程序中使用FS或GS,在编译时会报错。如果有必要使用它们,只需在使用前用下面的语句声明一下就可以了(比如在第14章的异常处理中要用到FS寄存器):
assume fs:nothing, gs:nothing或者assume fs:flat, gs:flat
在Win32汇编中,.model语句中还应该指定语言模式,即子程序的调用方式,例子中用的是stdcall,它指出了调用子程序或Win32 API时参数传递的次序和堆栈平衡的方法,相对于stdcall,不同的语言类型还有C,SysCall,BASIC,FORTRAN和PASCAL,虽然各种高级语言在调用子程序时都是使用堆栈来传递参数,但它们的处理方法各有不同。要和其他语言配合,就必须指定相应的语言种类。Windows的API调用使用的是stdcall格式,所以在Win32汇编中没有选择,必须在 .model中加上stdcall参数。关于参数传递的细节,在3.4.2节中有详细的描述。
3.option语句
用option语句定义的选项有很多,如option language定义和option segment定义等,在Win32汇编程序中,需要的只是定义option casemap:none,这个语句定义了程序中的变量和子程序名是否对大小写敏感,由于Win32 API中的API名称是区分大小写的,所以必须指定这个选项,否则在调用API的时候会有问题。
3.1.2 段的定义
1.段的概念
把上面的Win32的Hello World源程序中的语句归纳精简一下,再列在下面:
.386.model flat,stdcalloption casemap:none<一些include语句>.data<一些字符串、变量定义>.code<代码><开始标号><其他语句>end开始标号
上一节讲到的选项、模式等定义并不会在编译好的可执行程序中产生什么,它们只是“说明”,而真正的数据和代码是定义在各个段中的,如上面的 .data段和 .code段,考虑到不同的数据类型,还可以有其他种类的数据段,下面是包含全部段的源程序结构:
.386.model flat,stdcalloption casemap:none<一些include语句>.stack [堆栈段的大小].data<一些初始化过的变量定义>.data?<一些没有初始化过的变量定义>.const<一些常量定义>.code<代码><开始标号><其他语句>end开始标号.stack,.data,.data?,.const和 .code是分段伪指令,Win32中实际上只有代码和数据之分,.data,.data?和 .const都是数据段,.code是代码段,与DOS汇编不同,由于Win32汇编不必考虑堆栈,系统会为程序分配一个向下扩展的、足够大的段作为堆栈段,所以.stack段定义常常被忽略。
前面不是说过Win32环境下不用“段”了吗?是的,这些“段”实际上并不是DOS汇编中那种意义的段,而是内存的“分段”。上一个段的结束就是下一个段的开始,所有的“分段”合起来,包括系统使用的地址空间,就组成了整个可以寻址的4 GB空间。由于Win32环境的内存管理使用了80386处理器的分页机制,每个页(4 KB大小)可以自由指定属性,所以上一个4 KB可能是代码,属性是可执行但不可写,下一个4KB就有可能是既可读也可写但不可执行的数据,再下面呢?有可能是可读不可写也不可执行的数据。Win32汇编源程序中“分段”的概念实际上是把不同类型的数据或代码归类,再放到不同属性的内存页(也就是不同的“分段”)中,这中间不涉及使用不同的段选择器。虽然使用和DOS汇编同样的 .code和 .data语句来定义,意思可是完全不同了!为了简单起见,在本书中还是简称“段”,读者应该注意到其中不同的含义。
2.数据段
.data,.data?和 .const定义的是数据段,分别对应不同方式的数据定义,在最后生成的可执行文件中也分别放在不同的节区(Section)中。程序中的数据定义一般可以归纳为3类。
第一类是可读可写的已定义变量。这些数据在源程序中已经被定义了初始值,而且在程序的执行中有可能被更改,如一些标志等,这些数据必须定义在 .data段中,.data段是已初始化数据段,其中定义的数据是可读可写的,在程序装入完成的时候,这些值就已经在内存中了,.data段一般存放在可执行文件的_DATA节区内。
第二类是可读可写的未定义变量。这些变量一般是当做缓冲区或者在程序执行后才开始使用的,这些数据可以定义在 .data段中,也可以定义在 .data?段中,但一般把它放到.data?段中。虽然定义在这两种段中都可以正常使用,但定义在 .data?段中不会增大 .exe文件的大小。举例说明,如果要用到一个100 KB的缓冲区,可以用下面的语句定义:
szBuffer db 100 * 1024 dup (?)
这个语句如果放在 .data段中,编译器认为这些数据在程序装入时就必须有效,所以它在生成可执行文件的时候保留了所有的100 KB的内容,即使它们是全零!假设程序其他部分的大小是50 KB,那么最后的 .exe文件就会是150 KB大小,如果缓冲区定义为1MB,那么 .exe文件会增大到1050 KB。.data?段则不同,其中的内容编译器会认为程序在开始执行后才会用到,所以在生成可执行文件的时候只保留了大小信息,不会为它浪费磁盘空间。在与上面同样的情况下,即使缓冲区定义为1 MB,可执行文件同样只有50 KB!总之,.data?段是未初始化数据段,其中的数据也是可读可写的,但在可执行文件中不占空间,.data?段在可执行文件中一般存放在_BSS节区中。
第三类数据是一些常量。如一些要显示的字符串信息,它们在程序装入的时候也已经有效,但在整个执行过程中不需要修改,这些数据可以放在 .const段中,.const段是常量段,它是可读不可写的。为了方便起见,在小程序中常常把常量一起定义到 .data段中,而不另外定义一个 .const段。在程序中如果不小心用了对 .const段中的数据做写操作的指令,会引起保护错误,Windows会显示一个如图3.2所示的提示框并结束程序。
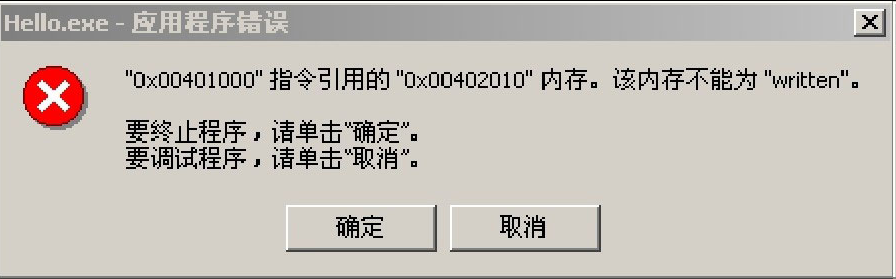
图3.2 对 .const段写操作引起的非法操作
如果不怕程序可读性不佳的话,把 .const段中定义的内容混到 .code段中去也可以正常使用,因为 .code段也是可以读的。
3.代码段
.code段是代码段,所有的指令都必须写在代码段中,在可执行文件中,代码段一般是放在_TEXT节区中的。Win32环境中的数据段是不可执行的,只有代码段有可执行的属性。对于工作在特权级3的应用程序来说,.code段是不可写的,在编DOS汇编程序的时候,好事的程序员往往有个习惯,就是靠改动代码段中的代码来做一些反跟踪的事情,如果企图在Win32汇编下做同样的事情,结果就是和上面同样的“非法操作”。
当然事物总有两面性,在Windows 95下,在特权级0下运行的程序对所有的段都有读写的权利,包括代码段。另外,在优先级3下运行的程序也不是一定不能写代码段,代码段的属性是由可执行文件PE头部中的属性位决定的,通过编辑磁盘上的 .exe文件,把代码段属性位改成可写,那么在程序中就允许修改自己的代码段。一个典型的应用就是一些针对可执行文件的压缩软件和加壳软件,如Upx和PeCompact等,这些软件靠把代码段进行变换来达到解压缩或解密的目的,被处理过的可执行文件在执行时需要由解压代码来将代码段解压缩,这就需要写代码段,所以这些软件对可执行文件代码段的属性预先做了修改。
4.堆栈段
在程序中不必定义堆栈段,系统会自动分配堆栈空间。唯一值得一提的是,堆栈段的内存属性是可读写并且是可执行的,这样靠动态修改代码的反跟踪模块可以拷贝到堆栈中去边修改边执行。一些病毒或者黑客工具用到的缓冲区溢出技术也用到了这个特征,有兴趣了解的读者可以查阅相关的资料。
3.1.3 程序结束和程序入口
在C语言源程序中,程序不必显式地指定程序由哪里开始执行,编译器已经约定好从main()函数开始执行了。而在汇编源程序中,并没有一个main函数,程序员可以指定从代码段的任何一个地方开始执行,这个地方由程序最后一句的end语句来指定:
end [开始地址]
这句语句同时表示源程序结束,所有的代码必须在end语句之前,例如:
end start
上述语句指定程序从start这个标号开始执行。当然,start标号必须在程序的代码段中有所定义。
但是,一个源程序不必非要指定入口标号,这时候可以把开始地址忽略不写,这种情况发生在编写多模块程序的单个模块的时候。当分开写多个程序模块时,每个模块的源程序中也可以包括 .data,.data?,.const和 .code段,结构就和上面的Win32 Hello World一样,只是其他模块最后的end语句必须不带开始地址。当最后把多个模块链接在一起的时候,只能有一个主模块指定入口地址,在多个模块中指定入口地址或者没有一个模块指定了入口地址,链接程序都会报错。
3.1.4 注释和换行
注释是源程序中不可忽略的一部分,汇编源程序的注释以分号(;)开始,注释既可以在一行的头部,也可以在一行的中间,一行中所有在分号之后的字符全部当做注释处理,但在字符串的定义中包含在引号内的分号不当做是注释的开始。
举例如下:
;这里是注释
call_ PrintChar ;这里是注释
szChar db 'Hello, world;',0dh,0ah ;world后面的分号不是注释,后面的才是当源程序的某一行过长,不利于阅读的时候,可以分行书写,分行的办法是在一行的最后用反斜杠(\)做换行符,如:
invoke MessageBox,NULL,offset szText,offset szCaption,MB_OK可以写为:
invoke MessageBox,\Null,\ ;父窗口句柄offset szText,\ ;消息框中的文字offset szCaption,\ ;标题文字MB_OK“一行的最后”指的是最后一个有用的字符,反斜杠后面多几个空格或加上注释并不影响换行符的使用,如上例所示,这一点与makefile文件中换行符的规定有所不同。
3.2 调用API
3.2.1 API是什么
Win32程序是构筑在Win32 API基础上的。在Win32 API中,包括了大量的函数、结构和消息等,它不仅为应用程序所调用,也是Windows自身的一部分,Windows自身的运行也调用这些API函数。
在DOS下,操作系统的功能是通过各种软中断来实现的,如大家都知道int 21h是DOS中断,int 13h和int 10h是BIOS中的磁盘中断和视频中断。当应用程序要引用系统功能时,要把相应的参数放在各个寄存器中再调用相应的中断,程序控制权转到中断中去执行,完成以后会通过iret中断返回指令回到应用程序中。如DOS汇编下的Hello World程序中有下列语句:
mov ah,9
mov dx,offset szHello
int 21h这3条语句调用DOS系统模块中的屏幕显示功能,功能号放在ah中,9号功能表示屏幕显示,要输出到屏幕上的内容的地址放在dx中,然后去调用int 21h,字符串就会显示到屏幕上。
这个例子说明了应用程序调用系统功能的一般过程。首先,系统提供功能模块并约定参数的定义方法,同时约定调用的方式,应用程序按照这个约定来调用系统功能。在这里,ah中放功能号9,dx中放字符串地址就是约定的参数,int 21h是约定的调用方式。
下面来看看这种方法的不便之处。首先,所有的功能号定义是冷冰冰的数字,int 21h的说明文档是这样的:
int 21 Functions:
00——Program termination
01——Keyboard input
02——Display output
03——AUX input
04——AUX output
05——Printer output
06——Direct console I/O
07——Direct STDIN input, no echo
08——Keyboard input, no echo
09——Print string
0A——Buffered keyboard input
0B——Check standard input status
再进入09号功能看使用方法:
Print string (Func 09)
AH = 09h
DS:DX -> string terminated by "$"这就是DOS时代汇编程序员都有一厚本《中断大全》的原因,因为所有的功能编号包括使用的参数定义仅从字面上看,是看不出一点头绪来的。
另外,80x86系列处理器能处理的中断最多只能有256个,不同的系统服务程序使用了不同的中断号,这可怜的中断数量显得太少了,结果到最后是中断挂中断,大家抢来抢去的,把好好的一个系统搞得像接力赛跑一样。
对于这些弱点,程序员们都有个愿望:系统功能如果能以功能名称作为子程序名直接调用就好了,参数也最好定义得有意义一点,这样一来写程序就会方便得多,编系统扩展模块就不必总是操心往哪个中断上面挂了,最好能把上面int 21h/ah=9的调用写成下面这副样子:
call PrintString,addr szHello终于,好消息出来了,Win32环境中的编程接口就是这个样子!这就是API,它实际上是以一种新的方法代替了DOS中用软中断的方式。与DOS的结构相比,Win32的系统功能模块放在Windows的动态链接库(DLL)中,DLL是一种Windows的可执行文件,采用的是和 .exe文件同样的PE格式,在PE格式文件头的导出表中,以字符串形式指出了这个DLL能提供的函数列表。应用程序使用字符串类型的函数名指定要调用的函数。
应用程序在使用的时候由Windows自动装入DLL程序并调用相应的函数。
实际上,Win32的基础就是由DLL组成的。Win32 API的核心由3个DLL提供,它们是:
● KERNEL32.DLL——系统服务功能。包括内存管理、任务管理和动态链接等。
● GDI32.DLL——图形设备接口。利用VGA与DRV之类的显示设备驱动程序完成显示文本和矩形等功能。
● USER32.DLL——用户接口服务。建立窗口和传送消息等。
当然,Win32 API还包括其他很多函数,这些也是由DLL提供的,不同的DLL提供了不同的系统功能。如使用TCP/IP协议进行网络通信的DLL是Wsock32.dll,它所提供的API称为Socket API;专用于电话服务方面的API称为TAPI(Telephony API),包含在Tapi32.dll中。所有的这些DLL提供的函数组成了现在所用的Win32编程环境。
3.2.2 调用API
与在DOS中用中断方式调用系统功能一样,用API方式调用存放在DLL中的函数必须同样约定一个规范,用来定义函数的调用方法、参数的传递方法和参数的定义,洋洋洒洒几百MB的Windows系统比起才几百KB规模的DOS,其系统函数的规模和复杂程度都上了一个数量级,所以在使用一个API时,带的参数数量多达十几个是常有的事,在DOS下用寄存器来传递参数的方法显然已经不能胜任了。
Win32 API是用堆栈来传递参数的,调用者把参数一个个压入堆栈,DLL中的函数程序再从堆栈中取出参数处理,并在返回之前将堆栈中已经无用的参数丢弃。在Microsoft发布的《Microsoft Win32 Programmer's Reference》中定义了常用API的参数和函数声明,先来看消息框函数的声明:
int MessageBox(HWND hWnd, // handle to owner windowLPCTSTR lpText, // text in message boxLPCTSTR lpCaption, // message box titleUINT uType // message box style);最后还有一句说明:
Library: Use User32.lib.上述函数声明说明了MessageBox有4个参数,它们分别是HWND类型的窗口句柄(hWnd),LPCTSTR类型的要显示的字符串地址(lpText)和标题字符串地址(lpCaption),还有UINT类型的消息框类型(uType)。这些数据类型看起来很复杂,但有一点是很重要的,对于汇编语言来说,Win32环境中的参数实际上只有一种类型,那就是一个32位的整数,所有这些HWND,LPCTSTR和UINT实际上就是汇编中的dword(double word),之所以定义为不同的模样,是为了说明其用途。可能是因为Windows是用C写成的吧,或者是因为世界上的程序员用C语言的最多,Windows所有编程资料发布的格式都是用C格式的。
上面的声明用汇编的格式来表达就是:
MessageBox Proto hWnd:dword,lpText:dword,lpCaption:dword,uType:dword上面最后一句Library: Use User32.lib则说明了这个函数包括在User32.dll中。
有了函数原型的定义以后,就是调用的问题了,Win32 API调用中要把参数放入堆栈,顺序是最后一个参数最先进栈,在汇编中调用MessageBox函数的方法是:
push uType
push lpCaption
push lpText
push hWnd
call MessageBox在源程序编译链接成可执行文件后,call MessageBox语句中的MessageBox会被换成一个地址,指向可执行文件中的导入表,导入表中指向MessageBox函数的实际地址会在程序装入内存的时候,根据User32.dll在内存中的位置由Windows系统动态填入。
1.使用invoke语句
API是可以调用了,另一个烦人的问题又出现了,Win32的API动辄就是十几个参数,整个源程序一眼看上去基本上都是把参数压入堆栈的push指令,参数的个数和顺序很容易搞错,由此引起的莫名其妙的错误源源不断,源程序的可读性看上去也很差。如果写的时候少写了一句push指令,程序在编译和链接的时候都不会报错,但在执行的时候必定会崩溃,原因是堆栈对不齐了。
有没有解决的办法呢?最好是像C语言一样,能在同一句中打入所有的参数,并在参数使用错误的时候能够提示。
Microsoft终于做了一件好事,在MASM中提供了一个伪指令实现了这个功能,那就是invoke伪指令,它的格式是:
invoke 函数名[,参数1][,参数2]……对MessageBox的调用在MASM中可以写成:
invoke MessageBox,NULL,offset szText,offset szCaption,MB_OK注意,invoke并不是80386处理器的指令,而是一个MASM编译器的伪指令,在编译的时候由编译器把上面的指令展开成我们需要的4个push指令和1个call指令,同时,进行参数数量的检查工作,如果带的参数数量和声明时的数量不符,编译器会报错:
error A2137: too few arguments to INVOKE编译时看到这样的错误报告,首先要检查的是有没有少写了一个参数。由于对于不带参数的API调用,invoke伪指令的参数检查功能可有可无,所以既可以用call API_Name这样的语法也可以用invoke API_Name这样的语法。
TASM中没有invoke伪指令,它直接使用call指令实现同样的功能,如在TASM源代码中写上:
call MessageBox,NULL,offset szText,offset szCaption,MB_OKTASM编译器会将其展开成我们需要的4个push指令和1个call指令。
2.API函数的返回值
有的API函数有返回值,如MessageBox定义的返回值是int类型的数,返回值的类型对汇编程序来说也只有dword一种类型,它永远放在eax中。如果要返回的内容不是一个eax所能容纳的,Win32 API采用的方法一般是eax中返回一个指向返回数据的指针,或者在调用参数中提供一个缓冲区地址,干脆把数据直接返回到缓冲区中去。
3.函数的声明
在调用API函数的时候,函数原型也必须预先声明,否则,编译器会不认这个函数。invoke伪指令也无法检查参数个数。声明函数的格式是:
函数名 proto [距离] [语言] [参数1]:数据类型,[参数2]:数据类型,……句中的proto是函数声明的伪指令,距离可以是NEAR,FAR,NEAR16,NEAR32,FAR16或FAR32,Win32中只有一个平坦的段,无所谓距离,所以在定义时是忽略的;语言类型就是 .model那些类型,如果忽略,则使用 .model定义的默认值。
后面就是参数的列表了,由于Win32 API仅仅使用dword类型的参数,所以绝大多数的数据类型都是dword,另外对于编译器来说,它只关心参数的数量,参数的名称在这里是“无用”的,仅是为了可读性而设置的,可以省略掉,所以下面两句消息框函数的定义实际上是一样的:
MessageBox Proto hWnd:dword,lpText:dword,lpCaption:dword,uType:dword
MessageBox Proto :dword,:dword,:dword,:dword在Win32环境中,和字符串相关的API共有两类,分别对应两个字符集:一类是处理ANSI字符集的,另一类是处理Unicode字符集的。前一类函数名字的尾部带一个“A”字符,处理Unicode的则带一个“W”字符。我们比较熟悉的ANSI字符串是以NULL结尾的一串字符数组,每一个ANSI字符占一个字节宽。对于欧洲语言体系,ANSI字符集已经足够了,但对于有成千上万个不同字符的几种东方语言体系来说,Unicode字符集更有用。每一个Unicode字符占两个字节的宽度,这样一来就可以同时定义65536个不同的字符了。
MessageBox和显示字符串有关,同样它有两个版本,严格地说,系统中有两个定义:
MessageBoxA Proto hWnd:dword,lpText:dword,lpCaption:dword,uType:dword
MessageBoxW Proto hWnd:dword,lpText:dword,lpCaption:dword,uType:dword虽然《Microsoft Win32 Programmer's Reference》中只有一个MessageBox定义,从MSDN上查询也是如此,但User32.dll中确实没有MessageBox,而只有MessageBoxA和MessageBoxW,那么为什么在源代码中还是可以使用MessageBox呢?这是因为在程序的头文件user32.inc中有一句:
MessageBox equ <MessageBoxA> 它把MessageBox偷梁换柱变成了MessageBoxA。在源程序中继续沿用MessageBox是为了程序的可读性,以及保持和手册的一致性,但对于编译器来说,实际是在使用MessageBoxA。
并不是每个Win32系统都支持W系列的API,在Windows 9x系列中,对Unicode是不支持的,绝大多数的API只有ANSI版本(为数不多的几个例外是存在MessageBoxW等函数,它们让Unicode版本的程序在检测到系统不支持的时候,能有机会用消息框提示用户并退出),只有Windows NT系列才对Unicode完全支持。为了编写在几个平台中通用的程序,一般应用程序都使用ANSI版本的API函数集。
为了使程序更有移植性,在源程序中一般不直接指明使用Unicode还是ANSI版本,而是使用宏汇编中的条件汇编功能来统一替换,如在源程序中使用MessageBox,但在头文件中定义:
if UNICODEMessageBox equ <MessageBoxW>
elseMessageBox equ <MessageBoxA>
endif所有涉及版本问题的API都可以按此方法定义,然后在源程序的头部指定UNICODE=1或UNICODE=0,重新编译后就能产生不同的版本。
4.include语句
对于所有要用到的API函数,在程序的开始部分都必须预先声明,但这个步骤显然是比较麻烦的,为了简化操作,可以采用各种语言通用的解决办法,就是把所有的声明预先放在一个文件中,在用到的时候再用include语句包含进来。现在回到Win32 Hello World程序,这个程序用到了两个API函数:MessageBox和ExitProcess,它们分别在User32.dll和Kernel32.dll中,在MASM32 SDK软件包中已经包括了所有DLL的API函数声明列表,每个DLL对应<DLL名.inc>文件,在源程序中只要使用include语句包含进来就可以了:
include user32.inc
include kernel32.inc当用到其他的API函数时,只需相应增加对应的include语句。
include语句还用来在源程序中包含其他文件,当多个源程序用到相同的函数定义、常量定义,甚至源代码时,可以把相同的部分写成一个文件,然后在不同的源程序中用include语句包含进来。
编译器对include语句的处理仅是简单地把这一行用指定的文件内容替换掉而已。
include语句的语法是:
include 文件名
或 include <文件名>
当遇到要包括的文件名和 MASM 的关键字同名等可能会引起编译器混淆的情况时,可以用“<>”将文件名括起来。
5.includelib语句
在DOS汇编中,使用中断调用系统功能是不必声明的,处理器自己知道到中断向量表中去取中断地址。在Win32汇编中使用API函数,程序必须知道调用的API函数存在于哪个DLL中,否则,操作系统必须搜索系统中存在的所有DLL,并且无法处理不同DLL中的同名函数,这显然是不现实的,所以,必须有个文件包括DLL库正确的定位信息,这个任务是由导入库来实现的。
在使用外部函数的时候,DOS下有函数库的概念,那时的函数库实际上是静态库,静态库是一组已经编写好的代码模块,在程序中可以自由引用,在源程序编译成目标文件,最后要链接成可执行文件的时候,由link程序从库中找出相应的函数代码,一起链接到最后的可执行文件中。DOS下C语言的函数库就是典型的静态库。库的出现为程序员节省了大量的开发时间,缺点就是每个可执行文件中都包括了要用到的相同函数的代码,占用了大量的磁盘空间,在执行的时候,这些代码同样重复占用了宝贵的内存。
Win32环境中,程序链接的时候仍然要使用函数库来定位函数信息,只不过由于函数代码放在DLL文件中,库文件中只留有函数的定位信息和参数数目等简单信息,这种库文件叫做导入库,一个DLL文件对应一个导入库,如User32.dll文件用于编程的导入库是User32.lib,MASM32 SDK软件包中包含了所有DLL的导入库。
为了告诉链接程序使用哪个导入库,使用的语句是:
includelib 库文件名或 includelib <库文件名>与include的用法一样,在要包括让编译器混淆的文件名时加方括号。Win32 Hello world程序用到的两个API函数MessageBox和ExitProcess分别在User32.dll和Kernel32.dll中,那么在源程序使用的相应语句为:
includelib user32.lib
includelib kernel32.lib和include语句的处理不同,includelib不会把 .lib文件插入到源程序中,它只是告诉链接器在链接的时候到指定的库文件中去找API函数的位置信息而已。
3.2.3 API参数中的等值定义
再回过头来看显示消息框的语句:
invoke MessageBox,NULL,offset szText,offset szCaption,MB_OK在uType这个参数中使用了MB_OK,这个MB_OK是什么意思呢,先来看《Microsoft Win32 Programmer's Reference》中的说明:
uType —— 定义对话框的类型,这个参数可以是以下标志的合集:
要定义消息框上显示按钮,用下面的某一个标志:
MB_ABORTRETRYIGNORE —— 消息框有三个按钮:“终止”,“重试”和“忽略”
MB_HELP —— 消息框上显示一个“帮助”按钮,按下后发送WM_HELP消息
MB_OK —— 消息框上显示一个“确定”按钮,这是默认值
MB_OKCANCEL —— 消息框上显示两个按钮:“确定”和“取消”
MB_RETRYCANCEL —— 消息框上显示两个按钮:“重试”和“忽略”
MB_YESNO —— 消息框上显示两个按钮:“是”和“否”
MB_YESNOCANCEL —— 消息框上显示三个按钮:“是”、“否”和“取消” 要在消息框中显示图标,用下面的某一个标志:
MB_ICONWARNING —— 显示惊叹号图标
MB_ICONINFORMATION —— 显示消息图标
MB_ICONASTERISK —— 显示危险图标
MB_ICONQUESTION —— 显示问号图标
MB_ICONSTOP —— 显示停止图标 ……
这些是uType参数说明中的一小半,可以看出,参数中可以用的值有很多种,让我们换一个值试试看,把语句改为:
invoke MessageBox,NULL,offset szText,\offset szCaption, MB_ICONWARNING or MB_YESNO再编译执行看,屏幕上出现了一个不一样的消息框,如图3.3所示。
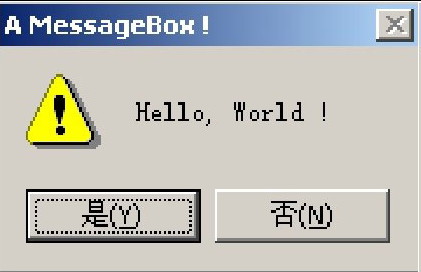
图3.3 另一个消息框
和参数说明中的一样!消息框中出现了一个惊叹号图标,按钮也变成了“是”和“否”两个按钮!MB_ICONWARNING和MB_YESNO等参数究竟是什么意思呢,MASM中显然没有这样的预定义,让我们先来找Visual C++的头文件,在WinUser.h中可以找到下面一段:
/** MessageBox() Flags*/#define MB_OK 0x00000000L#define MB_OKCANCEL 0x00000001L#define MB_ABORTRETRYIGNORE 0x00000002L#define MB_YESNOCANCEL 0x00000003L#define MB_YESNO 0x00000004L#define MB_RETRYCANCEL 0x00000005L#define MB_ICONHAND 0x00000010L#define MB_ICONQUESTION 0x00000020L#define MB_ICONEXCLAMATION 0x00000030L#define MB_ICONASTERISK 0x00000040L#if(WINVER >= Ox0400)#define MB_USERICON 0x00000080L#define MB_ICONWARNING MB_ICONEXCLAMATION#define MB_ICONERROR MB_ICONHAND#endif /* WINVER >= 0x0400 */#define MB_ICONINFORMATION MB_ICONASTERISK#define MB_ICONSTOP MB_ICONHAND……显然,MB_YESNO就是4,MB_ICONWARNING就是30h,默认的MB_OK就是0,Win32 API的参数使用这样的定义方法是为了免除程序员死记数值定义的麻烦。在编写Win32汇编程序时,MASM32 SDK软件包中的Windows.inc也包括了所有这些参数的定义,只要在程序的开头包含这个定义文件:
include windows.inc就可以方便地完全按照API手册来使用Win32函数。
打开\masm32\include目录下的Windows.inc查看一下,可以发现整个文件总共有两万六千多行,包括了几乎所有的Win32 API参数中的常量和数据结构定义。正是有了这个文件中详尽的定义,Win32ASM才得以流行起来,试想一下,哪个程序员愿意每使用一个API语句,就到函数手册中去看参数,然后到Microsoft发布的Visual C++的头文件中去找对应的数值,再应用到汇编源程序中?这样会有80%以上的时间花在做无用功上(最后还是要骂Microsoft为什么不提供汇编格式的头文件,毕竟MASM32 SDK软件包不是Microsoft出的)。
有时候由于版本的原因,当使用最新的API手册时,会发现有些参数使用的常量在Windows.inc中并没有定义,这下惨了,谁都不知道类似于MB_XXXYYY的符号代表什么数值,Microsoft的《Microsoft Programmer's Reference》手册中从来就不会把参数对应的数值写进去。遇到这种情况,只有拿出最原始的办法了,就是到最新的Visual C++或SDK的include目录中去,在C语言格式的 .h头文件中把定义找出来,然后自行增补到Windows.inc中去。如果这样也找不到定义值的话,那只好放弃使用这个API了。
3.3 标号、变量和数据结构
当程序中要跳转到另一位置时,需要有一个标识来指示新的位置,这就是标号,通过在目标地址的前面放上一个标号,可以在指令中使用标号来代替直接使用地址。
使用变量是任何编程语言都要遇到的工作,Win32汇编也不例外,在MASM中使用变量也有需要注意的几个问题,错误地使用变量定义或用错误的方法初始化变量会带来难以定位的错误。变量是计算机内存中已命名的存储位置,在大部分的语言中都有很多种类的变量,如整数型、浮点型和字符串等,不同的变量有不同的用途和尺寸,比如说虽然长整数和单精度浮点数都是32位长,但它们的用途不同。
顾名思义,变量的值在程序运行中是需要改变的,所以它必须定义在可写的段内,如.data和 .data?,或者在堆栈内。按照定义的位置不同,MASM中的变量也分为全局变量和局部变量两种。
在MASM中标号和变量的命名规范是相同的,它们是:
(1)可以用字母、数字、下划线及符号@、$和?。
(2)第一个符号不能是数字。
(3)长度不能超过240个字符。
(4)不能使用指令名等关键字。
(5)在作用域内必须是唯一的。
3.3.1 标号
1.标号的定义
当在程序中使用一条跳转指令的时候,可以用标号来表示跳转的目的地,编译器在编译的时候会把它替换成地址,标号既可以定义在目的指令同一行的头部,也可以在目的指令前一行单独用一行定义,标号定义的格式是:
标号名: 目的指令 ;方法1
或
标号名:: 目的指令 ;方法2
常用的方法是使用方法1(标号后跟一个冒号),这时标号的作用域是当前的子程序,在单个子程序中的标号不能同名,否则编译器不知该用哪个地址,但在不同的子程序中可以有相同名称的标号,这意味着不能从一个子程序中用跳转指令跳到另一个子程序中。
需要从一个子程序中用跳转指令跳到另一个子程序中的标号时,可以用方法2(标号后跟两个冒号)来定义,这时标号的作用域是整个程序,对任何其他子程序都是可见的。
在低版本的MASM中,标号在整个程序中是唯一的,子程序中的标号也可以从整个程序的任何地方转入(相当于任何标号都是用方法2定义的)。而Win32汇编使用的高版本MASM中默认的标号作用域是当前的子程序,这是因为为了提供对局部变量和参数的支持,编译器会在子程序的入口处自动加上对堆栈的初始化指令,从子程序的中间进入相当于跳过了这些初始化指令,访问局部变量和参数时会出问题。
当然,如果程序员确认在子程序的中间进入不会引起问题(如用不到局部变量或参数),那完全可以用方法2来定义作为入口的标号。
2.MASM中的@@
在DOS时代,为标号起名是个麻烦的事情,因为汇编指令用到跳转指令特别多,任何比较和测试等都要涉及跳转,所以在程序中会有很多标号,在整个程序范围内起个不重名的标号要费一番工夫,结果常常用addr1和addr2之类的标号一直延续下去,如果后来要在中间插一个标号,那么就常常出现addr1_1和loop10_5之类奇怪的标号。
实际上,很多标号只会使用一到两次,而且不一定非要起个有意义的名称,如汇编程序中下列代码结构很多:
mov cx,1234hcmp flag,1jz loc1mov cx,1000h
loc1:…loop loc1loc1在别的地方就再也用不到了,对于这种情况,高版本的MASM用@@标号去代替它:
mov cx,1234hcmp flag,1jz @Fmov cx,1000h@@:…loop @B【学习笔记】
;Test@Label.asm Windows环境下32位汇编语言 在win10系统环境下运行,使用VS2019进行编译和链接:
;当用@@做标号时,可以用@F和@B来引用它,@F表示本条指令后的第一个@@标号,
;@B表示本条指令前的第一个@@标号,程序中可以有多个@@标号,但@B和@F只寻找匹配最近的一个。
option casemap:none ;区分大小写
;include文件定义
include Irvine32.inc;数据段
.data
sum DWORD ?;代码段
.code
start:mov esi, offset summov ecx, 5cmp ecx, 4;ja loc1 ;如果大于4跳转到loc1ja @Fmov ecx, 5
@@: ; == loc1:add sum, ecx;loop loc1loop @Binvoke ExitProcess, 0
end start 在Win10环境下使用VS2019运行调试:
当用@@做标号时,可以用@F和@B来引用它,@F表示本条指令后的第一个@@标号,@B表示本条指令前的第一个@@标号,程序中可以有多个@@标号,但@B和@F只寻找匹配最近的一个。
不要在间隔太远的代码中使用@@标号,因为在以后的修改中,@@和@B,@F中间可能会被无意中插入一个新的@@,这样一来,@B或@F就会引用到错误的地方去,源程序中@@标号和跳转指令之间的距离最好限制在编辑器能够显示的同一屏幕的范围内。
3.3.2 全局变量
1.全局变量的定义
全局变量的作用域是整个程序,Win32汇编的全局变量定义在 .data或 .data?段内,可以同时定义变量的类型和长度,格式是:
变量名 类型 初始值1,初始值2,……
变量名 类型 重复数量dup(初始值1,初始值2,……)
MASM中可以定义的变量类型相当多,具体如表3.2所示。
表3.2 变量的类型 | |||
名称 | 表示方式 | 缩写 | 长度(字节) |
字节 | byte | db | 1 |
字 | word | dw | 2 |
双字(doubleword) | dword | dd | 4 |
三字(farword) | fword | df | 6 |
四字(quadword) | qword | dq | 8 |
十字节BCD码(tenbyte) | tbyte | dt | 10 |
有符号字节(signbyte) | sbyte | 1 | |
有符号字(signword) | sword | 2 | |
有符号双字(signdword) | sdword | 4 | |
单精度浮点数 | real4 | 4 | |
双精度浮点数 | real8 | 8 | |
10字节浮点数 | real10 | 10 | |
所有使用到变量类型的情况中,只有定义全局变量的时候类型才可以用缩写,现在先来看全局变量定义的几个例子:
.datawHour dw ? ;例1wMinute dw 10 ;例2_hWnd dd ? ;例3word_Buffer dw 100 dup (1,2) ;例4szBuffer byte 1024 dup (?) ;例5szText db 'Hello,world!' ;例6● 例1定义了一个未初始化的word类型变量,名称为wHour。
● 例2定义了一个名为wMinute的word类型变量,其值等于10。
● 例3定义了一个双字类型的变量_hWnd。
● 例4定义了一组字,以0001,0002,0001,0002,…的顺序在内存中重复100遍,一共是200个字。
● 例5定义了一个1024字节的缓冲区。
● 例6定义了一个字符串,总共占用了12字节。两头的单引号是定界的符号,并不属于字符串中真正的内容。
在byte类型变量的定义中,可以用引号定义字符串和数值定义的方法混用,假设要定义两个字符串“Hello,World!”和“Hello again”,每个字符串后面跟回车和换行符,最后以一个0字符结尾,可以定义如下:
szText db 'Hello,world!',0dh,0ah,'Hello again',0dh,0ah,02.全局变量的初始化值
全局变量在定义中既可以指定初值,也可以只用问号预留空间,在 .data?段中,只能用问号预留空间,因为 .data?不能指定初始值,这里就有一个问题:既然可以用问号预留空间,那么在实际运行的时候,这个未初始化的值是随机的还是确定的呢?答案是0,所以用问号指定的全局变量如果要以0为初始值的话,在程序中可以不必特地为它赋值。
3.3.3 局部变量
局部变量这个名称最早源于高级语言,主要是为了定义一些仅在单个函数里面有用的变量而提出的,使用局部变量能带来一些额外的好处,它使程序的模块化封装变得可能,试想一下,如果要用到的变量必须定义在程序的数据段里面,假设在一个子程序中要用到一些变量,当把这个子程序移植到别的程序时,除了把代码移过去以外,还必须把变量定义移过去。而即使把变量定义移过去了,由于这些变量定义在大家都可以用的数据段中,就无法对别的代码保持透明,别的代码有可能有意无意地修改它们。还有,在一个大的工程项目中,存在很多的子程序,所有的子程序要用到的变量全部定义到数据段中,会使数据段变得很大,混在一起的变量也使维护变得非常不方便。
局部变量这个概念出现以后,两个以上子程序都要用到的数据才被定义为全局变量统一放在数据段中,仅在子程序内部使用的变量则放在堆栈中,这样子程序可以编成“黑匣子”的模样,使程序的模块结构更加分明。
局部变量的作用域是单个子程序,在进入子程序的时候,通过修改堆栈指针esp来预留出需要的空间,在用ret指令返回主程序之前,同样通过恢复esp丢弃这些空间,这些变量就随之无效了。它的缺点就是因为空间是临时分配的,所以无法定义含有初始化值的变量,对局部变量的初始化一般在子程序中由指令完成。
在DOS时代,低版本的宏汇编本来无所谓全局变量和局部变量,所有的变量都是定义在数据段里面的,能被所有的子程序或主程序存取,就相当于现在所说的全局变量,用汇编语言在堆栈中定义局部变量是很麻烦的一件事情。要和高级语言做混合编程的时候,程序员往往很痛苦地在边上准备一张表,表上的内容是局部变量名和ebp指针的位置关系。
1.局部变量的定义
MASM用local伪指令提供了对局部变量的支持。定义的格式是:
local 变量名1[[重复数量]][:类型],变量名2[[重复数量]][:类型]……
local伪指令必须紧接在子程序定义的伪指令proc后、其他指令开始前,这是因为局部变量的数目必须在子程序开始的时候就确定下来,在一个local语句定义不下的时候,可以有多个local语句,语法中的数据类型不能用表3.2中的缩写,如果要定义数据结构,可以用数据结构的名称当做类型。Win32汇编默认的类型是dword,如果定义dword类型的局部变量,则类型可以省略。当定义数组的时候,可以 [] 括号括起来,不能使用定义全局变量的dup伪指令。局部变量不能和已定义的全局变量同名。局部变量的作用域是当前的子程序,所以在不同的子程序中可以有同名的局部变量。
这里有几个定义局部变量的例子:
local loc1[1024]:byte ;例1
local loc2 ;例2
local loc3:WNDCLASS ;例3
● 例1定义了一个1024字节长的局部变量loc1。
● 例2定义了一个名为loc2的局部变量,类型是默认值dword。
● 例3定义了一个WNDCLASS数据结构,名为loc3。
下面是局部变量使用的一个典型的例子:
TestProc proclocal @loc1:dword,@loc2:wordlocal @loc3:bytemov eax,@loc1mov ax,@loc2mov al,@loc3retTestProc endp这是一个名为TestProc的子程序,用local语句定义了3个变量,@loc1是dword类型,@loc2是word类型,@loc3是byte类型,在程序中分别有3句存取3个局部变量的指令,然后就返回了,编译成可执行文件后,再把它反汇编就得到了以下指令:
:00401000 55 push ebp
:00401001 8BEC mov ebp, esp
:00401003 83C4F8 add esp, FFFFFFF8
:00401006 8B45FC mov eax, dword ptr [ebp-04]
:00401009668B45FA mov ax, word ptr [ebp-06]
:0040100D 8A45F9 mov al, byte ptr [ebp-07]
:00401010 C9 leave :00401011 C3 ret
可以看到,反汇编后的指令比源程序多了前后两段指令,它们是:
:00401000 55 push ebp
:00401001 8BEC mov ebp, esp
:00401003 83C4F8 add esp, FFFFFFF8
…
:00401010 C9 leave
这些就是使用局部变量所必需的指令,分别用于局部变量的准备工作和扫尾工作。执行了call指令后,CPU把返回的地址压入堆栈,再转移到子程序执行,esp在程序的执行过程中可能随时用到,不可能用esp做指针来存取局部变量。大家一定有印象,在介绍寄存器的时候提到过ebp寄存器也是以堆栈段为默认数据段的,所以可以用ebp做指针,于是,在初始化前,先用一句push ebp指令把原来的ebp保存起来,然后把esp的值放到ebp中,供存取局部变量做指针用,再后面就是在堆栈中预留空间了,由于堆栈是向下增长的,所以要在esp中加一个负值,FFFFFFF8就是-8。慢着!一个dword加一个word再加一个字节不是7吗,为什么是8呢?这是因为在80386处理器中,以dword为界对齐时存取内存速度最快,所以MASM宁可浪费一个字节。执行了这3句指令后,初始化完成,就可以进行正常的操作了,从指令中可以看出局部变量在堆栈中的位置排列,如表3.3所示。
表3.3 上例中局部变量排列的顺序 | |
ebp偏移 | 内容 |
ebp+4 | 由call指令推入的返回地址 |
ebp | push ebp指令推入的原ebp值,然后新的ebp=现在的 esp |
ebp-4 | 第一个局部变量 |
ebp-6 | 第二个局部变量 |
ebp-7 | 第三个局部变量 |
在程序退出的时候,必须把正确的esp设置回去,否则,ret指令会从堆栈中取出错误的地址返回,看程序可以发现,ebp就是正确的初始esp值,因为子程序开始的时候已经有一句mov ebp,esp,所以要返回的时候只要先mov esp,ebp,然后再pop ebp,堆栈就是正确的了。
在80386指令集中有一条指令可以在一句中实现mov esp,ebp和pop ebp的功能,就是leave指令,所以,编译器在ret指令之前只使用了一句leave指令。
明白了局部变量使用的原理,就很容易理解使用时的注意点:ebp寄存器是关键,它起到保存原始esp的作用,并随时用做存取局部变量的指针基址,所以在任何时刻,不要尝试把ebp用于别的用途,否则会带来意想不到的后果。
Win32汇编中局部变量的使用方法可以解释一个很有趣的现象:在DOS汇编的时候,如果在子程序中的push指令和pop指令不配对,那么返回的时候ret指令从堆栈里得到的肯定是错误的返回地址,程序也就死掉了。但在Win32汇编中,push指令和pop指令不配对可能在逻辑上产生错误,却不会影响子程序正常返回,原因就是在返回的时候esp不是靠相同数量的push和pop指令来保持一致的,而是靠leave指令从保存在ebp中的原始值中取回来的,也就是说,即使把esp改得一塌糊涂也不会影响到子程序的返回,当然,“窍门”就在ebp,把ebp改掉,程序就玩完了!
2.局部变量的初始化值
显然,局部变量是无法在定义的时候指定初始化值的,因为local伪指令只是简单地把空间给留出来,那么开始使用时它里面是什么值呢?和全局变量不一样,局部变量的起始值是随机的,是其他子程序执行后在堆栈里留下的垃圾,所以,对局部变量的值一定要初始化,特别是定义为结构后当参数传递给API函数的时候。
在API函数使用的大量数据结构中,往往用0做默认值,如果用局部变量定义数据结构,初始化时只定义了其中的部分字段,那么剩余字段的当前值可能是编程者预想不到的数值,传给API函数后,执行的结果可能是意想不到的,这是初学者很容易忽略的一个问题。所以最好的办法是:在赋值前首先将整个数据结构填0,然后再初始化要用的字段,这样其余的字段就不必一个个地去填0了,RtlZeroMemory这个API函数就是实现填0的功能的。
3.3.4 数据结构
数据结构实际上是由多个字段组成的数据“样板”,相当于一种自定义的数据类型,数据结构中间的每一个字段可以是字节、字、双字、字符串或所有可能的数据类型。比如在API函数RegisterClass中要使用到一个叫做WNDCLASS的数据结构,Microsoft的手册中是如下定义的:
typedef struct _WNDCLASS {UINT style;WNDPROC lpfnWndProc;int cbClsExtra;int cbWndExtra;HINSTANCE hInstance;HICON hIcon;HCURSOR hCursor;HBRUSH hbrBackground;LPCTSTR lpszMenuName;LPCTSTR lpszClassName;
} WNDCLASS, *PWNDCLASS;
注意,这是C语言格式的,这个数据结构包含了10个字段,字段的名称是style,lpfnWndProc和cbClsExtra等,前面的UINT和WNDPROC等是这些字段的类型,在汇编中,数据结构的写法如下:
结构名 struct
字段1 类型 ?
字段2 类型 ?
……
结构名 ends
上面的WNDCLASS结构定义用汇编的格式来表示就是:
WNDCLASS struct
style DWORD ?
lpfnWndProc DWORD ?
cbClsExtra DWORD ?
cbWndExtra DWORD ?
hInstance DWORD ?
hIcon DWORD ?
hCursor DWORD ?
hbrBackground DWORD ?
lpszMenuName DWORD ?
lpszClassName DWORD ?
WNDCLASS ends
和大部分的常量一样,几乎所有API所涉及的数据结构在Windows.inc文件中都已经有定义了。要注意的是,定义了数据结构实际上只是定义了一个“样板”,上面的定义语句并不会在哪个段中产生数据,与Word中使用各种“信纸”与“文书”等模板类似,定义了数据结构以后就可以多次在源程序中用这个“样板”当做数据类型来定义数据,使用数据结构在数据段中定义数据的方法如下:
.data?
stWndClass WNDCLASS <>
……
或者:
.data
stWndClass WNDCLASS <1,1,1,1,1,1,1,1,1,1>
……
这个例子定义了一个以WNDCLASS为结构的变量stWndClass,第一段的定义方法是未初始化的定义方法,第二段是在定义的同时指定结构中各字段的初始值,各字段的初始值用逗号隔开,在这个例子中10个字段的初始值都指定为1。
在汇编中,数据结构的引用方法有好几种,以上面的定义为例,如果要使用stWndClass中的lpfnWndProc字段,最直接的办法是:
mov eax,stWndClass.lpfnWndProc
它表示把lpfnWndProc字段的值放入eax中去,假设stWndClass在内存中的地址是403000h,这句指令会被编译成mov eax,[403004h],因为lpfnWndProc是stWndClass中的第二个字段,第一个字段是dword,已经占用了4字节的空间。
在实际使用中,常常有使用指针存取数据结构的情况,如果使用esi寄存器做指针寻址,可以使用下列语句完成同样的功能:
mov esi,offset stWndClass
mov eax,[esi + WNDCLASS.lpfnWndProc]
注意:第二句是[esi + WNDCLASS.lpfnWndProc]而不是[esi + stWndClass.lpfnWnd Proc],因为前者会被编译成mov eax,[esi+4],而后者会被编译成mov eax,[esi+403004h],后者的结果显然是错误的!如果要对一个数据结构中的大量字段进行操作,这种写法显然比较烦琐,MASM还有一个用法,可以用assume伪指令把寄存器预先定义为结构指针,再进行操作:
mov esi,offset stWndClass
assume esi:ptr WNDCLASS
mov eax,[esi].lpfnWndProc
…
assume esi:nothing
这样,使用寄存器也可以用逗点引用字段名,程序的可读性比较好。这样的写法在最后编译成可执行程序的时候产生同样的代码。注意:在不再使用esi寄存器做指针的时候要用assume esi:nothing取消定义。
结构的定义也可以嵌套,如果要定义一个新的NEW_WNDCLASS结构,里面包含一个老的WNDCLASS结构和一个新的dwOption字段,那么可以如下定义:
NEW_WNDCLASS struct
dwOptiond word ?
oldWndClass WNDCLASS <>
NEW_WNDCLASS ends
假设现在esi是指向一个NEW_WNDCLASS的指针,那么引用里面嵌套的oldWndClass中的lpfnWndProc字段时,就可以用下面的语句:
mov eax, [esi].oldWndClass.lpfnWndProc
结构的嵌套在Windows的数据定义中也是常有的,比如在第13章13.3节中使用的DEBUG_EVENT结构中竟然使用了4层数据结构的嵌套。熟练掌握数据结构的使用对Win32汇编编程是很重要的!
3.3.5 变量的使用
1.以不同的类型访问变量
这个话题有点像C语言中的数据类型强制转换,C语言中的类型转换指的是把一个变量的内容转换成另外一种类型,转换过程中,数据的内容已经发生了变化,如把浮点数转换成整数后,小数点后的内容就丢失了。在MASM中以不同的类型访问不会对变量造成影响。
举一个简单的例子,先以db方式定义一个缓冲区:
szBuffer db 1024 dup (?)
然后从其他地方取得了数据,但数据的格式是以字方式组织的,要处理数据,最有效的方法是两个字节两个字节地处理,但如果在程序中把szBuffer的值放入ax:
mov ax,szBuffer
编译器会报一个错:
error A2070: invalid instruction operands
意思是无效的指令操作,为什么呢?因为szBuffer是用db定义的,而ax的尺寸是一个word,等于两个字节,尺寸不符合。MASM中,如果要用指定类型之外的长度访问变量,必须显式地指出要访问的长度,这样,编译器忽略语法上的长度检验,仅使用变量的地址。使用的方法是:
类型ptr变量名
类型可以是byte,word,dword,fword,qword,real8和real10。如:
mov ax,word ptr szBuffer
mov eax,dword ptr szBuffer上述语句能通过编译,当然,类型必须和操作的寄存器长度匹配。在这里要注意的是,指定类型的参数访问并不会去检测长度是否溢出,看下面一段代码:
.data
bTest1 db 12h
wTest2 dw 1234h
dwTest3 dd 12345678h
…
.code
…
mov al,bTest1
mov ax,word ptr bTest1
mov eax,dword ptr bTest1
…上面的程序片断,每一句执行后寄存器中的值是什么呢,mov al,bTest1这一句很显然使al等于12h,下面的两句呢,ax和eax难道等于0012h和00000012h吗?实际运行结果很“奇怪”,竟然是3412h和78123412h,为什么呢?先来看反汇编的内容:
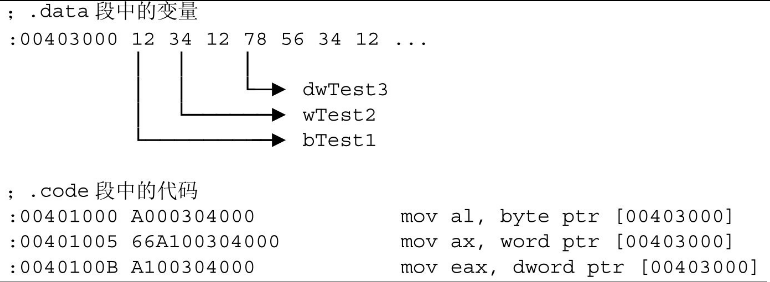
.data段中的变量是按顺序从低地址往高地址排列的,对于超过一个字节的数据,80386处理器的数据排列方式是低位数据在低地址,所以wTest2的1234h在内存中的排列是34h 12h,因为34h是低位。同样,dwTest3在内存中以78h 56h 34h 12h从低地址往高地址存放,在执行指令mov ax,word ptr bTest1的时候,是从bTest1的地址403000h处取一个字,其长度已经超过了bTest1的范围并落到了wTest2中,从内存中看,是取了bTest1的数据12h和wTest2的低位34h,在这两个字节中,12h位于低地址,所以ax中的数值是3412h。同样道理,看另一条指令:
mov eax,dword ptr bTest1
这条指令取了bTest1,wTest2的全部和dwTest3的最低位78h,在内存中的排列是12h 34h 12h 78h,所以eax等于78123412h。
这个例子说明了汇编中用ptr强制覆盖变量长度的时候,实质上只用了变量的地址,编译器并不会考虑定界的问题,程序员在使用的时候必须对内存中的数据排列有个全局概念,以免越界存取到意料之外的数据。
如果程序员的本意是类似于C语言的强制类型转换,想把bTest1的一个字节扩展到一个字或一个双字再放到ax或eax中,高位保持0而不是越界存取到其他的变量,可以用80386的扩展指令来实现。80386处理器提供的movzx指令可以实现这个功能,例如:
movzx ax,bTest1 ;例1
movzx eax,bTest1 ;例2
movzx eax,cl ;例3
movzx eax,ax ;例4
● 例1把单字节变量bTest1的值扩展到16位放入ax中。
● 例2把单字节变量bTest1的值扩展到32位放入eax中。
● 例3把cl中的8位值扩展到32位放入eax中。
● 例4把ax中的16位值扩展到32位放入eax中。
用movzx指令进行数据长度扩展是Win32汇编中经常用到的技巧,该指令总是将扩展的数据位用0代替。使用另一条指令movsx可以完成带符号位的扩展,当被扩展数据的最高位为0时,效果和movzx指令相同;当最高位为1时,则扩展部分的数据位全部用1填充。
2.变量的尺寸和数量
在源程序中用到变量的尺寸和数量的时候,可以用sizeof和lengthof伪指令来实现,格式是:
sizeof 变量名、数据类型或数据结构名
lengthof 变量名、数据类型或数据结构名
sizeof伪指令可以取得变量、数据类型或数据结构以字节为单位的长度,lengthof可以取得变量中数据的项数。假如定义了以下数据:
stWndClass WNDCLASS <>
szHello db 'Hello,world!',0
dwTest dd 1,2,3,4
…
.code
…
mov eax,sizeof stWndClass
mov ebx,sizeof WNDCLASS
mov ecx,sizeof szHello
mov edx,sizeof dword
mov esi,sizeof dwTest执行后eax的值是stWndClass结构的长度40,ebx同样是40,ecx的值是13,就是“Hello,world!”字符串的长度加上一个字节的0结束符,edx的值是一个双字的长度:4,而esi则等于4个双字的长度16。
如果把所有的sizeof换成lengthof,那么eax会等于1,因为只定义了1项WNDCLASS,而ecx同样等于13,esi则等于4,而lengthof WNDCLASS和lengthof dword是非法的用法,编译程序会报错。
要注意的是,sizeof和lengthof的数值是编译时候产生的,由编译器直接替换到指令中去,上边的指令最后产生的代码就是:
mov eax,40
mov ebx,40
mov ecx,13
mov edx,4
mov esi,16如果为了把Hello和World分两行定义,szHello是这样定义的:
szHello db 'Hello',0dh,0ah
db 'World',0那么sizeof szHello是多少呢?注意!是7而不是13,MASM中的变量定义只认一行,后一行db 'World',0实际上是另一个没有名称的数据定义,编译器认为sizeof szHello是第一行字符的数量。虽然把szHello的地址当参数传给MessageBox等函数显示时会把两行都显示出来,但严格地说这是越界使用变量。虽然在实际的应用中这样定义长字符串的用法很普遍,因为如果要显示一屏幕帮助,一行是不够的,但要注意的是:要用到这种字符串的长度时,千万不要用sizeof去表示,最好是在程序中用lstrlen函数去计算。
3.获取变量地址
获取变量地址的操作对于全局变量和局部变量是不同的。
对于全局变量,它的地址在编译的时候已经由编译器确定了,它的用法大家都不陌生:
mov 寄存器,offset变量名
其中offset是取变量地址的伪操作符,和sizeof伪操作符一样,它仅把变量的地址代到指令中去,这个操作是在编译时而不是在运行时完成的。
对于局部变量,它是用ebp来做指针操作的,假设ebp的值是40100h,那么局部变量1的地址是ebp-4即400FCh,由于ebp的值随着程序的执行环境不同可能是不同的,所以局部变量的地址值在编译的时候也是不确定的,不可能用offset伪操作符来获取它的地址。
80386处理器中有一条指令用来取指针的地址,就是lea指令,如:
lea eax,[ebp-4]
该指令可以在运行时按照ebp的值实际计算出地址放到eax中。
如果要在invoke伪指令的参数中用到一个局部变量的地址,该怎么办呢?参数中是不可能写入lea指令的,用offset又是不对的。MASM对此有一个专用的伪操作符addr,其格式为:
addr 局部变量名和全局变量名
当addr后跟全局变量名的时候,编译器自动按照offset的用法来使用;当addr后面跟局部变量名的时候,编译器会自动用lea指令先把地址取到eax中,然后用eax来代替变量地址使用。
要注意的是:对局部变量取地址的时候,addr伪操作符只能用在invoke的参数中,不能用在如下的mov指令中,这种限制很好理解,因为这种情况下,lea指令如何能被代到语句里面呢:
mov eax,addr局部变量名 ;注意:这是错误的用法
假设在一个子程序中有如下invoke指令:
invoke Test,eax,addr szHello
其中Test是一个需要两个参数的子程序,szHello是一个局部变量,会发生什么结果呢?编译器会把invoke伪指令和addr翻译成下面这个模样:
lea eax,[ebp-4]
push eax ;参数2:addr szHello
push eax ;参数1:eax
call Test
发现了什么?到push第一个参数eax之前,eax的值已经被lea eax,[ebp-4]指令覆盖了!也就是说,要用到的eax的值不再有效,所以,当在invoke中使用addr伪操作符时,注意在它的左边不能用eax,否则eax的值会被覆盖掉,当然eax用在addr右边的参数中用是可以的。幸亏MASM编译器对这种情况有如下错误提示:
error A2133: register value overwritten by INVOKE
否则,不知道又会引出多少莫名其妙的错误!
3.4 使用子程序
当程序中相同功能的一段代码用得比较频繁时,可以将它分离出来写成一个子程序,在主程序中用call指令来调用它。这样可以不用重复写相同的代码,仅仅用call指令就可以完成多次同样的工作了。Win32汇编中的子程序也采用堆栈来传递参数,这样就可以用invoke伪指令来进行调用和语法检查工作。
3.4.1 子程序的定义
子程序的定义方式如下所示。
子程序名 proc [距离][语言类型][可视区域][USES寄存器列表][,参数:类型]...[VARARG]
local 局部变量列表
指令
子程序名 endp
proc和endp伪指令定义了子程序开始和结束的位置,proc后面跟的参数是子程序的属性和输入参数。子程序的属性有:
● 距离——可以是NEAR,FAR,NEAR16,NEAR32,FAR16或FAR32,Win32中只有一个平坦的段,无所谓距离,所以对距离的定义往往忽略。
● 语言类型——表示参数的使用方式和堆栈平衡的方式,可以是StdCall,C,SysCall,BASIC、FORTRAN和PASCAL,如果忽略,则使用程序头部 .model定义的值。
● 可视区域——可以是PRIVATE,PUBLIC和EXPORT。PRIVATE表示子程序只对本模块可见;PUBLIC表示对所有的模块可见(在最后编译链接完成的 .exe文件中);EXPORT表示是导出的函数,当编写DLL的时候要将某个函数导出的时候可以这样使用。默认的设置是PUBLIC。
● USES寄存器列表——表示由编译器在子程序指令开始前自动安排push这些寄存器的指令,并且在ret前自动安排pop指令,用于保存执行环境,但笔者认为不如自己在开头和结尾用pushad和popad指令一次保存和恢复所有寄存器来得方便。
● 参数和类型——参数指参数的名称,在定义参数名的时候不能跟全局变量和子程序中的局部变量重名。对于类型,由于Win32中的参数类型只有32位(dword)一种类型,所以可以省略。在参数定义的最后还可以跟VARARG,表示在已确定的参数后还可以跟多个数量不确定的参数,在Win32汇编中唯一使用VARARG的API就是wsprintf,类似于C语言中的printf,其参数的个数取决于要显示的字符串中指定的变量个数。
完成了定义之后,可以用invoke伪指令来调用子程序,当invoke伪指令位于被调用的子程序代码之前的时候,编译器处理到invoke语句的时候还没有扫描到子程序的定义信息,所以会有以下错误信息:
error A2006: undefined symbol : 子程序名
这并不是说子程序的编写有错误,而是invoke伪指令无法得知子程序的定义情况,所以无法进行参数的检测。在这种情况下,为了让invoke指令能正常使用,必须在程序的头部用proto伪操作定义子程序的信息,“提前”告诉invoke语句关于子程序的信息,proto的用法见3.2.2节。当然,如果被调用的子程序定义在invoke语句前面的话,proto语句就可以省略了。
由于程序的调试过程中经常需要对一些子程序的参数个数进行调整,为了使它们保持一致,就需要同时修改proc语句和proto语句。在写源程序的时候有意识地把子程序的位置提到invoke语句的前面,省略掉proto语句,可以简化程序和避免出错。
3.4.2 参数传递和堆栈平衡
了解了子程序的定义方法后,让我们继续深入了解子程序的使用细节。在调用子程序时,参数的传递是通过堆栈进行的,也就是说,调用者把要传递给子程序的参数压入堆栈,子程序在堆栈中取出相应的值再使用,比如,如果要调用:
SubRouting(Var1,Var2,Var3)
经过编译后的最终代码可能..是(注意只是“可能”):
push Var3
push Var2
push Var1
call SubRouting
add esp,12
也就是说,调用者首先把参数压入堆栈,然后调用子程序,在完成后,由于堆栈中先前压入的数不再有用,调用者或者被调用者必须有一方把堆栈指针修正到调用前的状态,这就叫堆栈的平衡。参数是最右边的先入堆栈还是最左边的先入堆栈、还有由调用者还是被调用者来修正堆栈都必须有个约定(称为调用约定),不然就会产生错误的结果,这就是在上述文字中使用“可能”这两个字的原因。由于各种语言默认的调用约定是不同的,所以在proc以及proto语句的语言属性中确定语言类型后,编译器才可能将invoke伪指令翻译成正确的样子,不同语言的不同点如表3.4所示。
表3.4 不同语言调用方式的差别 | ||||||
C | SysCall | StdCall | BASIC | FORTRAN | PASCAL | |
最先入栈参数 | 右 | 右 | 右 | 左 | 左 | 左 |
清除堆栈者 | 调用者 | 子程序 | 子程序 | 子程序 | 子程序 | 子程序 |
允许使用 VARARG | 是 | 是 | 是 | 否 | 否 | 否 |
注:VARARG表示参数的个数可以是不确定的,如wsprintf函数,StdCall的堆栈清除平时是由子程序完成的,但使用VARARG时是由调用者清除的。
为了了解编译器对不同类型子程序的处理方式,先来看一段源程序:
;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>Sub1 proc C _Var1,_Var2mov eax,_Var1mov ebx,_Var2retSub1 endp;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>Sub2 proc PASCAL _Var1,_Var2Mov eax,_Var1mov ebx,_Var2retSub2 endp;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>Sub3 proc _Var1,_Var2mov eax,_Var1mov ebx,_Var2retSub3 endp;>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>…invoke Sub1,1,2invoke Sub2,1,2invoke Sub3,1,2
编译后再进行反汇编,看编译器是如何转换处理不同类型的子程序的:
; 这里是Sub1- C类型
:00401000 55 push ebp
:00401001 8BEC mov ebp, esp
:00401003 8B4508 mov eax, dword ptr [ebp+08]
:00401006 8B5D0C mov ebx, dword ptr [ebp+0C]
:00401009 C9 leave :0040100A C3 ret
; 这里是Sub2- PASCAL类型
:0040100B 55 push ebp
:0040100C 8BEC mov ebp, esp
:0040100E 8B450C mov eax, dword ptr [ebp+0C]
:00401011 8B5D08 mov ebx, dword ptr [ebp+08]
:00401014 C9 leave :00401015 C20800 ret 0008
; 这里是Sub3 — StdCall类型
:00401018 55 push ebp
:00401019 8BEC mov ebp, esp
:0040101B 8B4508 mov eax, dword ptr [ebp+08]
:0040101E 8B5D0C mov ebx, dword ptr [ebp+0C]
:00401021 C9 leave
:00401022 C20800 ret 0008
…
; 这里是invoke Sub1,1,2 — C类型
:00401025 6A02 push 00000002
:00401027 6A01 push 00000001
:00401029 E8D2FFFFFF call 00401000
:0040102E 83C408 add esp, 00000008
; 这里是invoke Sub2,1,2 — PASCAL类型
:00401031 6A01 push 00000001
:00401033 6A02 push 00000002
:00401035 E8D1FFFFFF call 0040100B
; 这里是invoke Sub3,1,2 — StdCall类型
:0040103A 6A02 push 00000002
:0040103C 6A01 push 00000001
:0040103E E8D5FFFFFF call 00401018
可以清楚地看到,在参数入栈顺序上,C类型和StdCall类型是先把右边的参数先压入堆栈,而PASCAL类型是先把左边的参数压入堆栈。在堆栈平衡上,C类型是在调用者在使用call指令完成后,自行用add esp,8指令把8个字节的参数空间清除,而PASCAL和StdCall的调用者则不管这个事情,堆栈平衡的事情是由子程序用ret 8来实现的(ret指令后面加一个操作数表示在ret后把堆栈指针esp加上操作数)。
因为Win32约定的类型是StdCall,所以在程序中调用子程序或系统API后,不必自己来平衡堆栈,免去了很多麻烦。
存取参数和局部变量都是通过堆栈来定义的,和存取局部变量类似,参数的存取也是通过ebp做指针来完成的。在表3.3中,已经对ebp指针和局部变量的对应关系做了分析,现在来分析一下ebp指针和参数之间的对应关系,注意,这里是以Win32中的StdCall为例,不同的语言类型,指针的顺序可能是不同的。
假定在一个子程序中有两个参数,主程序调用时在push第一个参数前的堆栈指针esp为X,那么压入两个参数后的esp为X-8,程序开始执行call指令,call指令把返回地址压入堆栈,这时候esp为X-C,接下去是子程序中用push ebp来保存ebp的值,esp变为X-10,再执行一句mov ebp,esp,就可以开始用ebp存取参数和局部变量了,图3.4说明了这个过程。
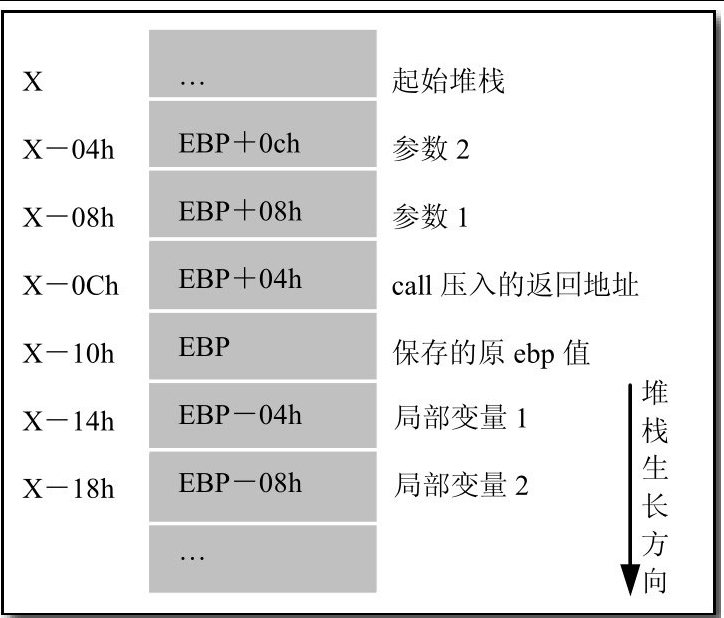
图3.4 ebp指针、参数和局部变量的关系
在源程序中,由于参数、局部变量和ebp的关系是由编译器自动维护的,所以读者不必关心它们的具体关系,但到了用Soft-ICE等工具来分析其他软件的时候,遇到调用子程序的时候一定要先看清楚它们之间的类型差别。
在子程序中使用参数,可以使用与存取局部变量同样的方法,因为这两者的构造原理几乎一模一样,所以,在子程序中有invoke语句时,如果要用到输入参数的地址当做invoke的参数,同样要遵循局部变量的使用方式,不能用offset伪操作符,只能用addr来完成。同样,所有对局部变量使用的限制几乎都可以适用于参数。
3.5 高级语法
以前高级语言和汇编的最大差别就是条件测试、分支和循环等高级语法。高级语言中,程序员可以方便地用类似于if,case,loop和while等语句来构成程序的结构流程,不仅条理清楚、一目了然,而且维护性相当好。而汇编程序员呢?只能在cmp指令后面绞尽脑汁地想究竟用几十种跳转语句中的哪一种,这里就能列出近三十个条件跳转指令来:ja,jae,jb,jbe,jc,je,jg,jge,jl,jle,jna,jnae,jnb,jnbe,jnc,jne,jng,jnge,jnl,jnle,jno,jnp,jns,jnz,jo,jp,jpe,jpo和jz等。虽然其中的很多指令我们一辈子也不会用到,但就是这些指令和一些loop,loopnz,以及被loop涉及的ecx等寄存器纠缠在一起,使在汇编中书写结构清晰、可读性好的代码变得相当困难,这也是很多人视汇编为畏途的一个原因。
现在好了,MASM中新引入了一系列的伪指令,涉及条件测试、分支和循环语句,利用它们,汇编语言有了与高级语言一样的结构,配合对局部变量和调用参数等高级语言中常见元素的支持,为使用Win32汇编编写大规模的应用程序奠定了基础。
3.5.1 条件测试语句
在高级语言中,所有的分支和循环语句首先要涉及条件测试,也就是涉及一个表达式的结果是“真”还是“假”的问题,表达式中往往有用来做比较和计算的操作符,MASM也不例外,这就是条件测试语句。
MASM条件测试的基本表达式是:
寄存器或变量 操作符 操作数
两个以上的表达式可以用逻辑运算符连接:
(表达式1)逻辑运算符(表达式2)逻辑运算符(表达式3)…
允许的操作符和逻辑运算符如表3.5所示。
表3.5 条件测试中的操作符 | ||
操作符和逻辑运算 | 操作 | 用途 |
== | 等于 | 变量和操作数之间的比较 |
!= | 不等于 | 变量和操作数之间的比较 |
> | 大于 | 变量和操作数之间的比较 |
>= | 大于等于 | 变量和操作数之间的比较 |
< | 小于 | 变量和操作数之间的比较 |
<= | 小于等于 | 变量和操作数之间的比较 |
& | 位测试 | 将变量和操作数做“与”操作 |
! | 逻辑取反 | 对变量取反或对表达式的结果取反 |
&& | 逻辑与 | 对两个表达式的结果进行逻辑“与”操作 |
|| | 逻辑或 | 对两个表达式的结果进行逻辑“或”操作 |
举例如下,左边为表达式,右边是表达式为“真”的条件:
x==3 ;x等于3
eax!=3 ;eax不等于3
(y>=3)&&ebx ;y大于等于3且ebx为非零值
(z&1)||!eax ;z和1进行“与”操作后非零或eax取反后非零
;也就是说z的位0等于1或者eax为零
细心的读者一定会发现,MASM的条件测试采用的是和C语言相同的语法。如!和&是对变量的操作符(取反和“与”操作),|| 和&&是表达式结果之间的逻辑“与”和逻辑“或”,而==、!=、>、< 等是比较符。同样,对于不含比较符的单个变量或寄存器,MASM也是将所有非零值认为是“真”,零值认为是“假”。
MASM的条件测试语句有几个限制,首先是表达式的左边只能是变量或寄存器,不能为常数;其次表达式的两边不能同时为变量,但可以同时是寄存器。这些限制来自于80x86的指令,因为条件测试伪操作符只是简单地把每个表达式翻译成cmp或test指令,80x86的指令集中没有cmp 0,eax之类的指令,同时也不允许直接操作两个内存中的数,所以对这两个限制是很好理解的。
除了这些和高级语言类似的条件测试伪操作,汇编语言还有特殊的要求,就是程序中常常要根据系统标志寄存器中的各种标志位来做条件跳转,这些在高级语言中是用不到的,所以又增加了以下一些标志位的状态指示,它们本身相当于一个表达式:
CARRY? 表示Carry位是否置位
OVERFLOW? 表示Overflow位是否置位
PARITY? 表示Parity位是否置位
SIGN? 表示Sign位是否置位
ZERO? 表示Zero位是否置位要测试eax等于ebx同时Zero位置位,条件表达式可以写为:
(eax==ebx) && ZERO?
要测试eax等于ebx同时Zero位清零,条件表达式可以写为:
(eax==ebx) && ! ZERO?
与C语言的条件测试相同,MASM的条件测试伪指令并不会改变被测试的变量或寄存器的值,只是进行“测试”而已,到最后它会被编译器翻译成类似于cmp或test之类的比较或位测试指令。
3.5.2 分支语句
分支语句用来根据条件表达式测试的真假执行不同的代码模块,MASM中的分支语句的语法如下:
.if条件表达式1
表达式1为“真”时执行的指令
[.elseif 条件表达式2]
表达式2为“真”时执行的指令
[.elseif 条件表达式3]
表达式3为“真”时执行的指令
…
[.else]
所有表达式为“否”时执行的指令
.endif
注意:关键字if/elseif/else/endif的前面有个小数点,如果不加小数点,就变成宏汇编中的条件汇编伪操作了,结果可是天差地别。
为了说明编译器究竟是如何处理这些伪指令的,先写一段如下的源代码:
.if eax && (ebx >= dwX) || !(dwY != ecx)mov esi,1
.elseif edxmov esi,2
.elseif esi & 1mov esi,3
.elseif ZERO? && CARRY?mov esi,4
.endif然后反汇编,得到了以下的汇编指令:
; .if eax
:00401000 0BC0 or eax, eax
:004010027408 je 0040100C
; (ebx >= dwX)
:00401004 3B1D00304000 cmp ebx, dword ptr [00403000]
:0040100A 7308 jnb 00401014
; (dwY != ecx)
:0040100C 390D04304000 cmp dword ptr [00403004], ecx
:004010127507 jne 0040101B
:00401014 BE01000000 mov esi, 00000001
:00401019 EB23 jmp 0040103E
; elseif edx
:0040101B 0BD2 or edx, edx :0040101D 7407 je 00401026
:0040101F BE02000000 mov esi, 00000002
:00401024 EB18 jmp 0040103E
; elseif esi & 1
:00401026 F7C601000000 test esi, 00000001
:0040102C 7407 je 00401035
:0040102E BE03000000 mov esi, 00000003
:00401033 EB09 jmp 0040103E
; ZERO?
:004010357507 jne 0040103E
; CARRY?
:004010377305 jnb 0040103E
:00401039 BE04000000 mov esi, 00000004
:0040103E
…
可以看到,MASM编译器对这些条件分支伪指令优化得相当好,看到这些反汇编后的指令,唯一的感觉是好像又回到了DOS汇编时代分支指令堆中,从这里可以发现,这些伪指令把汇编源程序的可读性基本上提高到了高级语言的水平。
分析反汇编代码可以发现,在不同的条件满足之后,先是执行满足条件后需要执行的指令,如上面的mov esi,0001和mov esi,0002等指令,这些指令执行后,后面都有一句直接跳转的指令jmp 0040103E,0040103E地址对应整个条件分支结构的尾部,这意味着,由.if/.elseif/.else/.endif条件分支伪指令构成的分支结构只能有一个条件被满足,也就是说,程序按照从上到下的各个条件表达式,顺序判断,当第一个条件表达式满足的时候,执行相应的代码,然后就忽略掉下面所有的其他条件表达式,即使后面有另一个满足条件时也是如此!如果需要构成的分支结构对于所有的表达式为“真”都要执行相应的代码,可以利用多个 .if/.endif来完成,如下所示:
.if 表达式1
表达式1为“真”要执行的指令
.endif
.if 表达式2
表达式2为“真”要执行的指令
.endif
…
使用.if/.else/.endif构成分支伪指令的时候,不要漏写前面的小数点,if/else/endif是宏汇编中条件汇编宏操作的伪操作指令,作用是根据条件决定在最后的可执行文件中包不包括某一段代码。比如在程序的调试阶段
DEBUG equ 1…
if DEBUGinvoke MessageBox,0,offset szText,offset szCaption, MB_OK
endif该代码用来显示一个调试信息,当程序正式发行时,将第一句改为DEBUG equ 0,然后再编译,那么可执行文件中根本不会包括这段代码,这和.if/.else/.endif构成分支的伪指令完全是两回事。
3.5.3 循环语句
循环是重复执行的一组指令,MASM的循环伪指令可以根据条件表达式的真假来控制循环是否继续,也可以在循环体中直接退出,使用循环的语法是:
.while 条件测试表达式
指令
[.break [.if退出条件]]
[.continue]
.endw
或
.repeat
指令
[.break [.if退出条件]]
[.continue]
.until 条件测试表达式(或.untilcxz [条件测试表达式])
.while/.endw循环首先判断条件测试表达式,如果结果是“真”,则执行循环体内的指令,结束后再回到 .while处判断表达式,如此往复,一直到表达式结果为“假”为止。.while/.endw指令有可能一遍也不会执行到循环体内的指令,因为如果第一次判断表达式时就遇到结果为“假”的情况,那么就直接退出循环。
.repeat/.until循环首先执行一遍循环体内的指令,然后再判断条件测试表达式,如果结果为“真”的话,就退出循环,如果为“假”,则返回 .repeat处继续循环,可以看出,.repeat/.until不管表达式的值如何,至少会执行一遍循环体内的指令。
也可以把条件表达式直接设置为固定值,这样就可以构建一个无限循环,对于.while/.end直接使用TRUE,对 .repeat/.until直接使用FALSE来当表达式就是如此,这种情况下,可以使用 .break伪指令强制退出循环,如果 .break伪指令后面跟一个 .if测试伪指令的话,那么当退出条件为“真”时才执行 .break伪指令。
在循环体中也可以用 .continue伪指令忽略以后的指令,遇到 .continue伪指令时,不管下面还有没有其他循环体中的指令,都会直接回到循环头部开始执行。
同样,为了深入了解MASM编译器把循环伪指令变成了什么,下面对比一段源程序和反汇编后的代码。首先是源程序:
.while eax > 1
mov esi,1
.break .if ebx
.continue
mov esi,2
.endw
.repeat
mov esi,1
.break .if !ebx
.continue
mov esi,2
.until eax > 1
.repeat
mov esi,1
.break
.untilcxz 以下是反汇编后的代码:
; .while 第一个循环开始
:00401000 EB10 jmp 00401012
:00401002 BE01000000 mov esi, 00000001
:00401007 0BDB or ebx, ebx
; .break .if ebx
:00401009750C jne 00401017
; .continue
:0040100B EB05 jmp 00401012
:0040100D BE02000000 mov esi, 00000002
; .while eax > 1
:00401012 83F801 cmp eax, 00000001
:00401015 77EB ja 00401002
; .repeat第二个循环开始
:00401017 BE01000000 mov esi, 00000001
; .break .if !ebx
:0040101C 0BDB or ebx, ebx
:0040101E 740C je 0040102C
; .continue
:00401020 EB05 jmp 00401027
:00401022 BE02000000 mov esi, 00000002
; .until eax > 1
:00401027 83F801 cmp eax, 00000001
:0040102A 76EB jbe 00401017
; .repeat第三个循环开始
:0040102C BE01000000 mov esi, 00000001
; .break
:00401031 EB02 jmp 00401035
; .untilcxz
:00401033 E2F7 loop 0040102C ;注意这里是loop指令!
对比伪指令和翻译成的实际指令,可以对循环的伪指令有更好的理解:.break翻译成一个跳转指令跳到循环结束的地方,.continue是一个无条件跳转指令跳到循环开始的地方,.while是先比较条件再执行循环体,而 .repeat是先执行循环体再比较条件的。
对指令的分析中可以发现,.while/.endw和 .repeat/.until循环没有使用loop指令的优势,因为loop指令可以自动递减ecx的值来控制循环,不使用loop将会在循环体内多设置一条参数递减的指令,但不用loop指令的好处是带来更多的灵活性。为了弥补这个缺陷,可以使用 .repeat/.untilcxz伪指令,编译器将会强制使用loop指令来完成循环,当然,在这种用法中,程序员必须在循环开始前正确设置ecx的值。
如果又想用loop指令来构成循环又要使用条件表达式怎么办,这时同样可以在 .untilcxz伪指令后加条件测试语句,只不过这时候有很大的限制,第一只能是单个条件表达式,不能用&&或||来构成多项表达式了;第二即使是单个表达式中,也只能用==或!=操作符,不能用其他比较大小的操作符,因为这时编译器的翻译方式是在一个比较指令后使用loopz或loopnz来构成循环,这个指令不能测试其他标志位。
在分支和循环的伪指令反汇编后可以发现,在使用>、>=、<和<=比较符时,MASM的伪指令总是将比较以后的跳转指令使用为jb和jnb等无符号数比较跳转的指令,这就意味着,MASM的条件测试总是把操作数当做无符号数看待,这样,假设eax等于1,那么表达式(eax >-1)的值是“假”,因为-1表示为0ffffffffh,如果当做无符号数看,它反而是最大的数!如果程序中需要构造有符号数的比较分支或循环结构,那么必须另外用jl和jg等有符号数比较跳转的指令来完成,使用条件测试配合分支或循环伪指令可能会得到错误的结果!
3.6 代码风格
随着程序功能的增加和版本的提高,程序越来越复杂,源文件也越来越多,风格规范的源程序会对软件的升级、修改和维护带来极大的方便,要想开发一个成熟的软件产品,必须在编写源程序的时候就有条不紊、细致严谨。
在编程中,在程序排版、注释、命名和可读性等问题上都有一定的规范,虽然编写可读性良好的代码并不是必然的要求(世界上还有难懂代码比赛,看谁的代码最不好读懂!),但好的代码风格实际上是为自己将来维护和使用这些代码节省时间。本节就是对汇编语言代码风格的建议。
3.6.1 变量和函数的命名
1.匈牙利表示法
匈牙利表示法主要用在变量和子程序的命名,这是现在大部分程序员都在使用的命名约定。“匈牙利表示法”这个奇怪的名字是为了纪念匈牙利籍的Microsoft程序员Charles Simonyi,他首先使用了这种命名方法。
匈牙利表示法用连在一起的几个部分来命名一个变量,格式是类型前缀加上变量说明,类型用小写字母表示,如用h表示句柄,用dw表示double word,用sz表示以0结尾的字符串等,说明则用首字母大写的几个英文单词组成,如TimeCounter,NextPoint等,可以令人一眼看出变量的含义来,在汇编语言中常用的类型前缀有:
b 表示byte
w 表示word
dw 表示dword
h 表示句柄
lp 表示指针
sz 表示以0结尾的字符串
lpsz 表示指向0结尾的字符串的指针
f 表示浮点数
st 表示一个数据结构
这样一来,变量的意思就很好理解:
hWinMain 主窗口的句柄
dwTimeCount 时间计数器,以双字定义
szWelcome 欢迎信息字符串,以0结尾
lpBuffer 指向缓冲区的指针
stWndClass WNDCLASS结构
…
很明显,这些变量名比count1,abc,commandlinebuffer和FILEFLAG之类的命名要易于理解。由于匈牙利表示法既描述了变量的类型,又描述了变量的作用,所以能帮助程序员及早发现变量的使用错误,如把一个数值当指针来使用引发的内存页错误等。
对于函数名,由于不会返回多种类型的数值,所以命名时一般不再用类型开头,但名称还是用表示用途的单词组成,每个单词的首字母大写。Windows API是这种命名方式的绝好例子,当人们看到ShowWindow,GetWindowText,DeleteFile和GetCommandLine之类的API函数名称时,恐怕不用查手册,就能知道它们是做什么用的。比起int 21h/09h和int 13h/02h之类的中断调用,好处是不必多讲的。
2.对匈牙利表示法的补充
使用匈牙利表示法已经基本上解决了命名的可读性问题,但相对于其他高级语言,汇编语言有语法上的特殊性,考虑下面这些汇编语言特有的问题:
● 对局部变量的地址引用要用lea指令或用addr伪操作,全局变量要用offset;对局部变量的使用要特别注意初始化问题。如何在定义中区分全局变量、局部变量和参数?
● 汇编的源代码占用的行数比较多,代码行数很容易膨胀,程序规模大了如何分清一个函数是系统的API还是本程序内部的子程序?
实际上上面的这些问题都可以归纳为区分作用域的问题。为了分清变量的作用域,命名中对全局变量、局部变量和参数应该有所区别,所以我们需要对匈牙利表示法做一些补充,以适应Win32汇编的特殊情况,下面的补充方法是笔者提出的,读者可以参考使用:
● 全局变量的定义使用标准的匈牙利表示法,在参数的前面加下划线,在局部变量的前面加@符号,这样引用的时候就能随时注意到变量的作用域。
● 在内部子程序的名称前面加下划线,以便和系统API区别。
如下面是一个求复数模的子程序,子程序名前面加下划线表示这是本程序内部模块,两个参数——复数的实部和虚部用_dwX和_dwY表示,中间用到的局部变量@dwResult则用@号开头:
_Calc proc _dwX,_dwYlocal @dwResultfinitfild _dwXfld st(0)fmul ;i * ifild _dwYfld st(0)fmul ;j * jfadd ;i * i + j * jfsqrt ;sqrt(i * i + j * j)fistp @dwResult ;put resultmov eax,@dwResultret_Calc endp
本书中所有的示范源代码采用的都是这样的命名约定。
3.6.2 代码的书写格式
1.排版方式
程序的排版风格应该遵循以下规则。
首先是大小写的问题,汇编程序中对于指令和寄存器的书写是不分大小写的,但小写代码比大写代码便于阅读,所以程序中的指令和寄存器等最好采用小写字母,而用equ伪操作符定义的常量则使用大写,变量和标号使用匈牙利表示法,大小写混合。
其次是使用Tab的问题。汇编源程序中Tab的宽度一般设置为8个字符。在语法上,指令和操作数之间至少有一个空格就可以了,但指令的助记符长度是不等长的,用Tab隔开指令和操作数可以使格式对齐,便于阅读。如:
xor eax,eax
fistp dwNumber
xchg eax,ebx上述代码的写法就不如下面的写法整齐:
xor eax,eax
fistp dwNumber
xchg eax,ebx还有就是缩进格式的问题。程序中的各部分采用不同的缩进,一般变量和标号的定义不缩进,指令用两个Tab缩进,遇到分支或循环伪指令再缩进一格,如:
.datadwFlag dd ?.codestart:mov eax,dwFlag.if dwFlag == 1call _Function1.elsecall _Function2.endif…合适的缩进格式可以明显地表现出程序的流程结构,也很容易发现嵌套错误,当缩进过多的时候,可以意识到嵌套过深,该改进程序结构了。
2.注释和空行
没有注释的程序是很难维护的,但注释的方法也很有讲究,写注释要遵循以下的规则:
● 不要写无意义的注释,如“将1放到eax中”,“跳转到exit标号处”等。
● 修改代码同时修改相应的注释,以保证注释与代码的一致性。
● 注释以描写一组指令实现的功能为主,不要解释单个指令的用法,那是应该由指令手册来完成的,不要假设看程序的人连指令都不熟悉。
● 对于子程序,要在头部加注释说明参数和返回值,子程序可以实现的功能,以及调用时应该注意的事项。
由于汇编语言是以一条指令为一行的,实现一个小功能就需要好几行,没有分段的程序很难看出功能模块来,所以要合理利用空行来隔开不同的功能块,一般以在高级语言中可以用一句语句来完成的一段汇编指令为单位插入一个空行。
3.避免使用宏
在MASM的宏功能中最好只使用条件汇编,用来选择编译不同的代码块来构建不同的版本,其他如宏定义和宏调用只会破坏程序的可读性,能够不用就尽量不用,虽然展开后只有一两句的宏定义不在此列,但既然展开后也只有一两句,那么和直接使用指令也就没有什么区别了。
在汇编中避免使用宏定义的理由是:汇编中随时要用到各个寄存器,宏定义不同于子程序,可以有选择地通过push/pop指令保护现场,在使用中很容易忽略里面用了哪个寄存器,从而对程序结构构成威胁。高级语言的宏定义则不会有这个问题。
笔者曾经见到过最极端的使用宏定义的程序是MicroMedia的Director SDK,100行左右的例子中几乎有90%都是宏定义,虽然例子很容易改成其他功能的程序,但要在里面加入新的功能则几乎是不可能的,因为程序中连C语言函数开始和结束的花括号都被改成了宏定义,这样一来,如果要真正使用这个开发包,则必须把宏定义“翻译”回原来的样子才能真正理解程序的流程。对于这样的代码,笔者是绝对不敢苟同的。
3.6.3 代码的组织
程序中要注意变量的组织和模块的组织方式。
由于过多的全局变量会影响程序的模块化结构,所以不要设置没必要的全局变量,尽量把变量定义成局部变量。把仅在子程序中使用的变量设置为局部变量可以使子程序更容易封装成一个黑匣子,如果无法把全部变量设置为局部变量,则尽量把这些数据改为参数输入输出,如果无法改为参数,那么意味着这个子程序不能不经修改地直接放到别的程序中使用。
在主程序中使用比较频繁的部分,以及便于封装成黑匣子在别的程序上用的代码,都应该写成子程序,但一个子程序的规模不应该太大,行数尽量限制在几百行之内,功能则限于完成单个功能。对于子程序,定义参数的时候要尽可能精简,对可能引起程序崩溃的参数,如指针等,要进行合法性检测。
子程序中在使用完申请的资源的时候,注意在退出前要释放所用资源,包括申请的内存和其他句柄等,对于打开的文件则要关闭。
对于程序员来说,开发每一个软件都要从头做起是很浪费时间的,一般的做法是从自己以前做过的程序中拷贝相似的代码,但修改还是要花一定的时间,最好的办法就是尽量把子程序做成一个黑匣子,可以不经修改地直接拿过来用,这样,每次编程相当于只是编写新增的部分,随着代码的积累,开发任何程序都将是很快的事情。