【深度学习】基于ESRNet模型的图像超分辨率训练
一、前言
- 基于ESRNet模型(ESRGAN简化版本)的图像超分辨率训练,可作为【机器学习】领域的学习样本,通过本项目,您可以了解机器学习的具体流程和关键概念。
文章目录
- 一、前言
- 二、概要
- 三、技术名词解释
- 四、整体架构流程
- 1、配置训练参数
- 2、数据集处理
- 3、神经网络模型
- 主模型(ESRNet)
- 残差块
- 4、训练过程
- 5、验证过程
- 五、训练模型效果验证
- 1、模型加载
- 2、图像预处理
- 3、超分辨率重建
- 4、结果保存
- 5、效果展示
- 六、更多训练
- 七、结语
二、概要
-
硬件配置:NVIDIA GeForce RTX 3050 Ti Laptop GPU(4GB显存)、16GB内存
-
PyTorch版本: 2.8.0+cu129、CUDA版本: 12.9
-
基于ESRNet模型(ESRGAN简化版本)的图像超分辨率训练,使用的数据集是公开的DIV2K图像集进行训练,训练出的模型可以实现图片超分辨率放大4倍的效果。
-
代码主要是由AI配合生成。
三、技术名词解释
有一些基础的概念需要掌握,具体的数学细节不探究,python内置的库都已经实现了,我们只需要学会调用就好。
- 1、 前向传播:是指输入数据从输入层开始,经过隐藏层逐层计算,最终得到输出层结果的过程。

- 2、反向传播:是神经网络训练的核心算法,从输出层反向逐层计算损失函数,并通过梯度下降法更新权重(W)和偏置(b),使得输出结果逐渐逼近真实值。
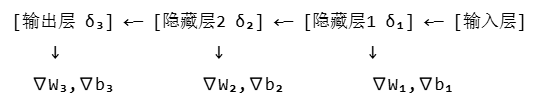
- 3、PSNR:峰值信噪比,主要用于评估图像压缩、重建等场景中输出图像与原始图像的相似度,PSNR值越高表示图像质量越好,通常认为:
30dB~50dB:压缩后图像质量良好。
20dB~30dB:人眼可察觉差异但未显著失真。
低于20dB:图像质量明显下降。
- 4、BICUBIC:双三次插值,是一种常用于图像缩放、旋转等几何变换中的插值算法,在本次实验中主要是对HR图像进行降采样生成低分辨率(LR)图像。
- 5、损失函数:用于衡量模型预测结果与真实结果之间差异的核心指标,模型训练的核心目标就是通过调整参数来最小化损失函数的值,使预测结果尽可能接近真实值。取值范围为 {0, 1}正确为 0,错误为 1。
- 6、tensor:在深度学习和PyTorch框架中,Tensor(张量) 是最核心的数据结构,可以理解为多维数组的扩展,用于高效存储和操作数值数据。它如同“神经网络的乐高积木”,构建了整个计算流程。
- 7、学习率:核心作用是控制参数更新的步长,
过大:跳过最优解,导致震荡或发散(损失函数剧烈波动)。
过小:收敛过慢,陷入局部最优或停滞。
初期:较高学习率快速拟合低频特征。
中期:逐步衰减优化高频结构。
后期:小学习率微调局部纹理。 - 8、ReLU激活函数:深度学习中常用的激活函数,其数学表达式非常简单:f(x) = max(0, x)。
计算速度快:只需简单的阈值操作,
缓解梯度消失问题:在正区间内导数恒为 1,有助于深层网络的训练,
稀疏激活:会使一部分神经元输出为 0,形成稀疏表示,提高模型泛化能力。
四、整体架构流程
1、配置训练参数
- 可以根据硬件的具体配置情况修改下列参数。
class Config:data_dir = "E:/PyCharm/project/DIV2K/DIV2K_train_HR" # 数据集路径scale_factor = 4 # 超分辨率放大倍数batch_size = 8 # 批量大小patch_size = 64 # 训练时裁剪的patch大小num_epochs = 15 # 训练轮数lr = 1e-4 # 学习率num_workers = 4 # 数据加载线程数device = torch.device("cuda" if torch.cuda.is_available() else "cpu") # 自动选择设备use_amp = True # 是否使用混合精度训练
2、数据集处理
- 输入配对:低分辨率(LR)图像(由HR下采样生成)与原始高分辨率(HR)图像组成训练对
数据增强:随机裁剪(64×64patches)、水平翻转、90°旋转
批量生成:DataLoader按batch_size(默认8)加载数据,启用pin_memory加速GPU传输
class DIV2KDataset(Dataset):def __init__(self, data_dir, file_indices, scale_factor, patch_size=None, is_train=True):# 初始化参数self.file_names = [f"{i:04d}.png" for i in file_indices] # 生成文件名列表def __getitem__(self, idx):# 加载高分辨率(HR)图像hr_img = Image.open(img_path).convert('RGB')# 训练时的数据增强,解决数据稀缺问题、提升模型鲁棒性、防止过拟合if self.is_train:# 随机裁剪# 随机水平翻转# 随机旋转90度# 生成低分辨率(LR)图像 - 通过降采样lr_size = (hr_img.width // self.scale_factor, hr_img.height // self.scale_factor)lr_img = hr_img.resize(lr_size, Image.BICUBIC)# 转换为张量return lr_tensor, hr_tensor
3、神经网络模型
主模型(ESRNet)
-
实现图像超分辨率(从低分辨率LR到高分辨率HR的映射)
基于ESRGAN(增强型超分辨率生成对抗网络)的简化版本
核心思想:通过深度卷积网络学习LR到HR的复杂非线性映射
class ESRNet(nn.Module):def __init__(self, scale_factor=4):super(ESRNet, self).__init__()# 初始卷积层self.conv1 = nn.Conv2d(3, 64, kernel_size=9, padding=4)# 16个残差块self.res_blocks = nn.Sequential(*[ResidualBlock(64) for _ in range(16)])# 中间卷积层self.conv2 = nn.Conv2d(64, 64, kernel_size=3, padding=1)# 上采样部分upsampling = []for _ in range(int(np.log2(scale_factor))): # scale_factor=4需要2次上采样upsampling += [nn.Conv2d(64, 256, kernel_size=3, padding=1),nn.PixelShuffle(2), # 子像素卷积上采样nn.LeakyReLU(0.2, inplace=True)]self.upsample = nn.Sequential(*upsampling)# 输出卷积层self.conv3 = nn.Conv2d(64, 3, kernel_size=9, padding=4)
残差块
- 卷积神经网络(CNN)中常用的一种网络结构组件,核心思想是解决深层神经网络训练中的梯度消失或梯度爆炸问题,使得训练非常深的网络成为可能。
#定义了一个继承自nn.Module的残差块类,这是PyTorch神经网络模块的基类。
class ResidualBlock(nn.Module): def __init__(self, channels):super(ResidualBlock, self).__init__()self.conv1 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)self.conv2 = nn.Conv2d(channels, channels, kernel_size=3, padding=1)
#channels: 输入和输出的通道数
#定义了两个3x3的卷积层:
#conv1: 输入输出通道数相同,使用1像素的padding保持空间维度
#conv2: 同上,构成两个连续的卷积层def forward(self, x): #前向传播residual = x # 保存原始输入作为残差x = self.relu(self.bn1(self.conv1(x))) # 卷积→批归一化→ReLUx = self.bn2(self.conv2(x))x += residual # 残差连接return x
4、训练过程
# 训练循环主体
for epoch in range(1, cfg.num_epochs + 1):model.train() # 设置为训练模式for batch_idx, (lr_imgs, hr_imgs) in enumerate(train_loader):# 1. 数据准备lr_imgs = lr_imgs.to(cfg.device, non_blocking=True) # 移动到GPUhr_imgs = hr_imgs.to(cfg.device, non_blocking=True)# 2. 前向传播,混合精度,减少显存占用with torch.amp.autocast(device_type='cuda', enabled=cfg.use_amp):sr_imgs = model(lr_imgs) # 生成超分辨率图像loss = criterion(sr_imgs, hr_imgs) # 3. 计算损失函数# 4. 反向传播与优化optimizer.zero_grad(set_to_none=True)scaler.scale(loss).backward() # 梯度缩放反向传播scaler.step(optimizer) # 参数更新scaler.update()# 5. 日志记录if batch_idx % cfg.log_interval == 0:print(f"Epoch: {epoch} | Batch: {batch_idx} | Loss: {loss.item():.6f}")
5、验证过程
if epoch % cfg.val_interval == 0:model.eval() # 设置为评估模式val_psnr = 0.0with torch.no_grad(): # 禁用梯度计算for lr_imgs, hr_imgs in val_loader:# 1. 数据准备lr_imgs = lr_imgs.to(cfg.device)hr_imgs = hr_imgs.to(cfg.device)# 2. 生成SR图像(混合精度)with torch.amp.autocast(device_type='cuda', enabled=cfg.use_amp):sr_imgs = model(lr_imgs)# 3. 计算PSNRval_psnr += calculate_psnr(sr_imgs.clamp(0,1), hr_imgs.clamp(0,1))# 4. 模型保存avg_psnr = val_psnr / len(val_loader)if avg_psnr > best_psnr:best_psnr = avg_psnrtorch.save(model.state_dict(), f"best_model_psnr{avg_psnr:.2f}.pth")# 5. 学习率调整scheduler.step(avg_psnr)
- 训练得到的模型结果输出示例:

五、训练模型效果验证
- 低分辨率图像输入→模型处理→高分辨率图像输出
1、模型加载
#定义模型结构:
class ESRNet(torch.nn.Module): # 主网络结构,与训练时保持一致
class ResidualBlock(torch.nn.Module): # 残差块结构#加载预训练权重:
model = ESRNet(scale_factor=4).to(device) #4倍放大
model.load_state_dict(torch.load(model_path, map_location=device))
model.eval() # 固定模型参数
2、图像预处理
#读取与转换图像:
img = Image.open(image_path).convert('RGB') # 确保RGB格式
transform = ToTensor()
lr_tensor = transform(lr_img).unsqueeze(0).to(device)
#添加batch维度并送设备,
#batch维度是张量(Tensor)中表示批量样本数量的维度,
#它的存在是为了让模型能够同时处理多个输入样本,从而利用硬件并行计算能力提高效率。
3、超分辨率重建
with torch.no_grad(): # 禁用梯度计算sr_tensor = model(lr_tensor) # 模型预测sr_tensor = torch.clamp(sr_tensor, 0, 1) # 将张量中的所有数值限制在 [0, 1] 范围内,确保超分辨率重建后的图像像素值合法且可正确显示
4、结果保存
to_pil = ToPILImage()
sr_img = to_pil(sr_tensor.squeeze(0).cpu()) #移除batch维度并转CPU
sr_img.save(output_path)
5、效果展示
- 我训练了90次,得到了psnr27.10的模型,当然训练次数越多越能接近psnr30,重构出来的图片质量会更高。

- 原图:分辨率510x342。

- 通过模型超分辨率重构后,得到图片的分辨率是2040x1368。因为训练的次数还不够,得到的图片细节上稍微有一点点糊。

六、更多训练
- 如果觉得训练的模型参数不够好,想从上次中断的地方恢复训练,只需加载checkpoint文件。
if os.path.exists(checkpoint_path):checkpoint = torch.load(checkpoint_path)model.load_state_dict(checkpoint['model_state_dict'])optimizer.load_state_dict(checkpoint['optimizer_state_dict'])
七、结语
本文一共是三个流程:1、初步训练模型;2、模型效果验证;3、继续训练获得参数更好的模型。
完整的代码可以自取,在文章顶部展示,如果对您有帮助,请不吝点赞和收藏喔!