Leetcode 14 java
今天复习一下以前做过的题目,感觉是忘光了。
给你两个单链表的头节点 headA 和 headB ,请你找出并返回两个单链表相交的起始节点。如果两个链表不存在相交节点,返回 null 。
图示两个链表在节点 c1 开始相交:
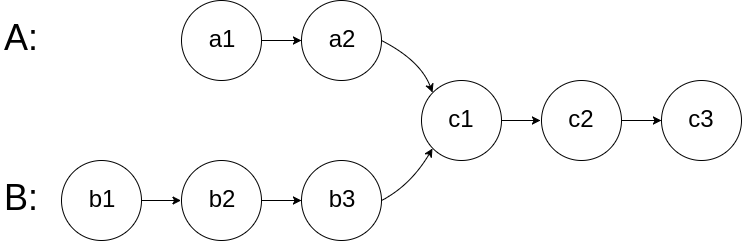
题目数据 保证 整个链式结构中不存在环。
注意,函数返回结果后,链表必须 保持其原始结构 。
自定义评测:
评测系统 的输入如下(你设计的程序 不适用 此输入):
intersectVal- 相交的起始节点的值。如果不存在相交节点,这一值为0listA- 第一个链表listB- 第二个链表skipA- 在listA中(从头节点开始)跳到交叉节点的节点数skipB- 在listB中(从头节点开始)跳到交叉节点的节点数
评测系统将根据这些输入创建链式数据结构,并将两个头节点 headA 和 headB 传递给你的程序。如果程序能够正确返回相交节点,那么你的解决方案将被 视作正确答案 。
示例 1:
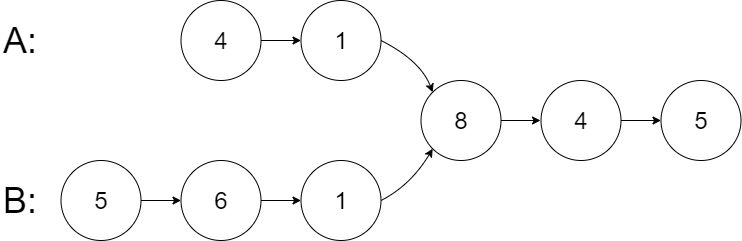
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,6,1,8,4,5], skipA = 2, skipB = 3
输出:Intersected at '8'
解释:相交节点的值为 8 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,6,1,8,4,5]。
在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。
— 请注意相交节点的值不为 1,因为在链表 A 和链表 B 之中值为 1 的节点 (A 中第二个节点和 B 中第三个节点) 是不同的节点。换句话说,它们在内存中指向两个不同的位置,而链表 A 和链表 B 中值为 8 的节点 (A 中第三个节点,B 中第四个节点) 在内存中指向相同的位置。
示例 2:
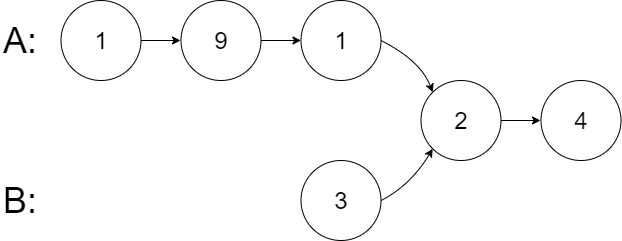
输入:intersectVal = 2, listA = [1,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1
输出:Intersected at '2'
解释:相交节点的值为 2 (注意,如果两个链表相交则不能为 0)。
从各自的表头开始算起,链表 A 为 [1,9,1,2,4],链表 B 为 [3,2,4]。
在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。
示例 3:
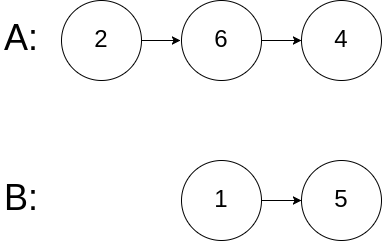
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2
输出:No intersection
解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。
由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。
这两个链表不相交,因此返回 null 。
提示:
listA中节点数目为mlistB中节点数目为n1 <= m, n <= 3 * 1041 <= Node.val <= 1050 <= skipA <= m0 <= skipB <= n- 如果
listA和listB没有交点,intersectVal为0 - 如果
listA和listB有交点,intersectVal == listA[skipA] == listB[skipB]
进阶:你能否设计一个时间复杂度 O(m + n) 、仅用 O(1) 内存的解决方案?
1 我的想法以及分析
看到这个题目我的反应是要用指针的,之前做过是有一点点印象的(但不多)。
1.如果有交点
那么从尾指针开始回溯,两个链表到从尾到交点的节点数一定是相同的
2.如果没有交点
那么从尾指针开始回溯,两个链表最终指针会回到头指针,节点数就是链表的长度(没有前驱指针,这个不能实现)
那这个想法有什么用呢?如果我们存在一个这样的指针:两个链表都从尾开始遍历,遇到交叉节点停下并返回当前所在节点位置,如果没有遇到就返回链表长度(所以就算没有交叉)
这就是我的思路了,但是实际上我应该怎么操作?
Listnode Pa = headA ,Pb =headB;//题目里只给了默认是头指针
其实我可以把原来的思路改一下,每个指针在交叉节点处停下,如果余下的链表长度一致,说明当前节点是交叉节点,如果不是,那就是没有相交(按照题目所给的数据)
往下读取的操作是
Pa=Pa.next
怎么读取第一个链表的节点呢?
不知道怎么写了,是不是有一个统一长度的操作?(看题解了hh)把链表全部向右对齐,左边空的地方用null填满。
while(Pa ! = Pb){
Pa = null ? headB : null ;
Pb = null ? headA : null ;
} //这里回头看发现写的是错的!!!!!就留着这个错误吧长记性。
return Pa;//看懂了,如果对齐了发觉没有相同节点,那么就是没有相交。
还有值得注意的是,如果一开始给的就是两个空链表,那肯定就是null
if (headA = null || headB = null )
{
return null;
}
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode(int x) {* val = x;* next = null;* }* }*/
public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {if (headA == null || headB == null)return null;ListNode pA = headA , pB = headB ;while (pA != pB){pA = pA == null ? headB : pA.next;pB = pB == null ? headA : pB.next;}return pA;}
}你的思路方向和对题目的理解是准确且有价值的,尤其抓住了 “相交链表从交点到尾端长度一致” 的核心特征,这是解决问题的关键前提,说明你对链表相交的本质逻辑有清晰认知。
同时,你也注意到了两个重要细节:
- 想到了 “统一长度” 的操作(后续结合题解理解的 “对齐” 思路),这和双指针法的核心逻辑不谋而合;
- 考虑到 “空链表直接返回 null” 的边界情况,避免了异常场景的遗漏。
如果说可以优化的点,主要是代码实现的细节衔接:
- 最初思路里 “从尾回溯” 的操作,在单链表中无法直接实现(单链表只能从前向后遍历,没有前驱指针),所以后续转向 “双指针切换链表” 的思路是非常正确的调整;
- 代码里 “Pa = null ? headB : null ;” 这类语法需要修正(三元运算符的条件和结果写反了),但你能理解 “指针为空时切换到另一链表头部” 的逻辑,已经掌握了算法的核心。
2 分析
要解决相交链表问题,核心是利用双指针 “对齐” 链表长度的思路,在满足时间复杂度 O (m+n) 和空间复杂度 O (1) 的前提下找到相交节点。以下是完整分析和代码实现:
一、核心思路:双指针 “路程补偿” 法
两个链表若相交,从相交节点到尾节点的 “共同段长度” 是相同的。差异在于相交前的 “独有段长度”(设为lenA独和lenB独)。
双指针通过遍历完自身链表后切换到另一链表头部,实现 “路程补偿”:
- 指针
pa从headA出发,遍历完 A 后切换到headB继续走; - 指针
pb从headB出发,遍历完 B 后切换到headA继续走; - 最终两指针会 “对齐” 到相交节点(若相交),或同时走到
null(若不相交)。
原理:两指针最终走的总路程都是 lenA独 + lenB独 + 共同段长度,路程相等且速度相同,必然在目标位置相遇。
二、代码实现(含边界处理)
java
运行
/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode(int x) {* val = x;* next = null;* }* }*/
public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {// 边界处理:若任一链表为空,直接返回null(无相交可能)if (headA == null || headB == null) {return null;}ListNode pa = headA; // 指针pa初始指向A的头ListNode pb = headB; // 指针pb初始指向B的头// 循环终止条件:pa == pb(要么是相交节点,要么是都为null)while (pa != pb) {// pa走一步:若遍历完A,切换到B的头;否则走nextpa = (pa == null) ? headB : pa.next;// pb走一步:若遍历完B,切换到A的头;否则走nextpb = (pb == null) ? headA : pb.next;}// 最终pa和pb要么同时指向相交节点,要么同时为nullreturn pa;}
}
三、关键细节解释
- 边界处理:若
headA或headB为空,直接返回null(空链表不可能与其他链表相交)。 - 循环逻辑:
- 当
pa遍历完 A(即pa == null),切换到 B 的头部继续走,相当于 “补偿”lenB独的长度; - 当
pb遍历完 B(即pb == null),切换到 A 的头部继续走,相当于 “补偿”lenA独的长度; - 若两链表相交:
pa和pb会在遍历完 “自身长度 + 对方独有长度” 后,同时到达相交节点; - 若两链表不相交:
pa和pb会在遍历完 “自身长度 + 对方长度” 后,同时到达null。
- 当
- 原始结构保留:仅通过指针遍历,未修改链表的
next指向,满足题目要求。
四、示例验证(以示例 1 为例)
- 链表 A:
4 → 1 → 8 → 4 → 5(长度 5);链表 B:5 → 6 → 1 → 8 → 4 → 5(长度 6)。 pa的路径:4→1→8→4→5→null→5→6→1→8(第 9 步到相交节点 8);pb的路径:5→6→1→8→4→5→null→4→1→8(第 9 步到相交节点 8);- 最终
pa == pb(都指向 8),返回该节点,符合预期
题友说:
“关于第二种解法发表下我的见解,统一长度说白了就是为了两个链表向右对齐,打个比方listA长度为5,listB长度为6,不好比较,那就把前面补充成null(先这样想)
listA=[null,4,1,8,4,5] listB=[5,6,1,8,4,5]
那这样长度就一样了,我们就能同时从开头移动A和B进行比较。
那回到正常的思路,想A和B长度一样,长度就都设置为A+B呗。那就往B最左边补充A长度(5)个null,A最左边补充B长度(6)个null。那就变成
listA=[null,null,null,null,null,null,4,1,8,4,5] listB=[null,null,null,null,null,5,6,1,8,4,5]
这样长度一样,好比较了吧,不过都是null,链表怎么移动啊,你就把A里面的6个null换成B的数据,B里面的null换成A的数据呗,反正都是要白白移动的,相交点在最后面,这样补全是为了我们好操作链表。
那这样理解的话这题就没问题了。代码是官方第二种解法的代码。”
3 (未完待续)哈希集合解法:相交链表问题的另一种思路
这个解法还没尝试过。
除了之前讨论的双指针法,哈希集合也是解决相交链表问题的经典思路,其核心是通过存储一个链表的所有节点,再遍历另一个链表查找 “共同节点”,具体分析如下:
一、思路与算法逻辑
哈希集合的核心是利用 “集合元素唯一性” 的特性,将一个链表的节点全部存入集合后,通过检查另一个链表的节点是否在集合中,判断是否相交及找到相交节点。步骤如下:
- 存储链表 A 的节点:遍历链表
headA,将每个节点(注意是存储节点本身,而非节点值)加入哈希集合visited。 - 查找链表 B 的节点:遍历链表
headB,对每个节点执行判断:- 若该节点在
visited中:说明此节点是两个链表的 “第一个共同节点”(因为是从headB头开始遍历),直接返回该节点。 - 若遍历完
headB所有节点都不在visited中:说明两链表不相交,返回null。
- 若该节点在
二、代码实现(Java)
java
运行
import java.util.HashSet;
import java.util.Set;/*** Definition for singly-linked list.* public class ListNode {* int val;* ListNode next;* ListNode(int x) {* val = x;* next = null;* }* }*/
public class Solution {public ListNode getIntersectionNode(ListNode headA, ListNode headB) {// 哈希集合:存储链表A的所有节点Set<ListNode> visited = new HashSet<ListNode>();ListNode temp = headA;// 第一步:遍历链表A,将所有节点加入集合while (temp != null) {visited.add(temp);temp = temp.next;}// 第二步:遍历链表B,查找集合中存在的节点temp = headB;while (temp != null) {if (visited.contains(temp)) {return temp; // 找到第一个相交节点,直接返回}temp = temp.next;}// 遍历完B仍未找到,说明无相交return null;}
}
三、关键细节说明
- 存储 “节点” 而非 “节点值”:
题目中明确 “值相同的节点可能是不同对象”(如示例 1 中 A 的 “1” 和 B 的 “1” 是不同节点),因此必须存储节点的引用(地址),而非仅比较值,避免误判。 - “第一个共同节点” 的必然性:
遍历headB时,第一个在集合中找到的节点就是相交起点 —— 因为headB从头部开始遍历,且相交后的所有节点都在集合中,第一个匹配的节点即为最早的相交节点。 - 原始结构保留:
仅通过指针遍历和集合存储,未修改任何链表的next指向,满足题目 “保持原始结构” 的要求。
四、复杂度分析
| 维度 | 分析 |
|---|---|
| 时间复杂度 | O (m + n):m 为headA长度,n 为headB长度,需各遍历一次,无嵌套循环。 |
| 空间复杂度 | O (m):需存储headA的所有 m 个节点,空间开销随headA长度线性增长。 |
五、与双指针法的对比
| 对比维度 | 哈希集合法 | 双指针法 |
|---|---|---|
| 时间复杂度 | O (m + n)(相同) | O (m + n)(相同) |
| 空间复杂度 | O (m)(需额外存储一个链表) | O (1)(仅用两个指针,最优) |
| 实现难度 | 逻辑直观,易理解 | 需理解 “路程补偿” 逻辑 |
若题目对空间开销无严格限制,哈希集合法是更易想到的解法;若要求O (1) 空间(如进阶要求),则双指针法更优。