MQ积压如何处理
处理消息队列(MQ)积压是一个需要系统化分析的运维挑战。下面我将结合常见原因,分步骤说明处理方案,并区分应急措施和根本解决方案:
一、快速诊断积压原因(核心!)
- 监控告警分析:
- 队列深度监控: 检查积压量的增长趋势(是突增还是持续上升?)
- 生产者速率 vs 消费者速率: 对比消息生产速度与消费速度。
- 消费者处理延迟: 监控单个消息处理耗时、失败率、重试次数。
- 资源监控: 消费者所在服务器的CPU、内存、磁盘IO、网络I/O是否达到瓶颈?
- 外部依赖: 数据库连接池、下游API响应时间是否正常?
- 日志分析:
- 检查消费者日志是否有大量错误/重试(如数据库连接超时、HTTP调用异常、业务逻辑失败)。
- 是否有GC停顿或内存溢出(OOM)导致消费者卡顿。
二、应急处理方案(立即止血)
| 方案 | 适用场景 | 操作方式 | 注意事项 |
|---|---|---|---|
| 1. 纵向扩容 | 消费者资源不足 | 提升消费者服务器CPU/内存 | 物理机需重启;虚拟机/容器可在线调整 |
| 2. 横向扩容(核心) | 消费能力不足 | 动态增加消费者应用实例数 | Kafka等需注意分区数限制(消费实例数≤分区数) |
| 3. 紧急扩容Broker | 积压导致磁盘/内存不足 | 增加Broker节点或提升单节点配置 | Kafka需重新分配分区;RabbitMQ需调整集群 |
| 4. 紧急处理脏数据 | 因特定消息卡死 | 将问题消息路由至死信队列(DLQ) | RabbitMQ需配置DLX;Kafka需跳过异常消息 |
| 5. 临时限流 | 保护下游服务 | 主动降低生产者发送速率或暂停非核心生产 | Kafka可使用quota功能;RabbitMQ限流插件 |
| 6. 迁移堆积队列 | 积压量过大阻塞集群 | 将部分分区/队列拆分到独立集群 | Kafka重分区;RabbitMQ重建队列 |
三、根本解决方案(预防再次积压)
- 优化消费者性能:
- 异步/批处理: 将单条处理改为批量处理(如Kafka的
max.poll.records优化)。 - 多线程处理: 在单个消费者进程内启用线程池处理(需保证线程安全)。
- 反序列化加速: 使用二进制协议(如Protobuf/Avro),避免JSON解析瓶颈。
- 资源复用: 数据库连接池预热,HTTP连接池复用。
- 异步/批处理: 将单条处理改为批量处理(如Kafka的
- 逻辑优化:
- 避免循环调用: 消除消息处理中的同步等待(如递归查询)。
- 降级策略: 非核心操作可异步执行或跳过。
- 消息压缩: 启用lz4/zstd压缩减少网络传输量。
- 内存管理: 避免超大消息(>1MB),限制本地缓存大小。
- 架构优化:
- 分区/队列优化: Kafka根据流量分配分区数;RabbitMQ调整prefetch count。
- 消费链解耦: 耗时操作拆分成多个队列(如:接收队列 → 处理队列 → 存储队列)。
- 流量分级: 突发流量独立队列 + 动态扩缩容。
- 消费者池化: Kubernetes HPA根据积压量自动扩缩实例。
- 冷热分离: 历史数据归档至S3/对象存储。
- 容错机制强化:
- 合理配置重试次数(如3次)与退避策略(指数退避)。
- 死信队列(DLQ)需有独立监控和告警。
- 实现消费者健康检查(如Kafka Lag Exporter报警)。
四、关键维护实践
- 容量规划:
- 压测确定单分区的吞吐能力(如Kafka单分区5000-10000 msg/s)。
- 预留20%~30%的突发流量缓冲空间。
- 监控覆盖关键指标:
- Kafka: Lag per partition, Produce/Consumer速率,Broker磁盘/CPU
- RabbitMQ: Queue depth, Unack消息数, Consumer数量
- 自动化处置:
- 当lag持续上升时自动触发扩容
- 消费者死亡自动重启
- 消息治理:
- TTL机制避免消息堆积(如RabbitMQ
x-message-ttl) - 定期清理测试队列
- TTL机制避免消息堆积(如RabbitMQ
五、技术选型建议
- 极高吞吐量(>100k/s): Kafka + 分区扩展
- 灵活路由需求: RabbitMQ + 死信队列 + 多机部署
- Serverless场景: AWS SQS / Azure Service Bus(自动扩缩)
- 云原生集成: AWS Kinesis + Lambda Auto Scaling
执行流程图
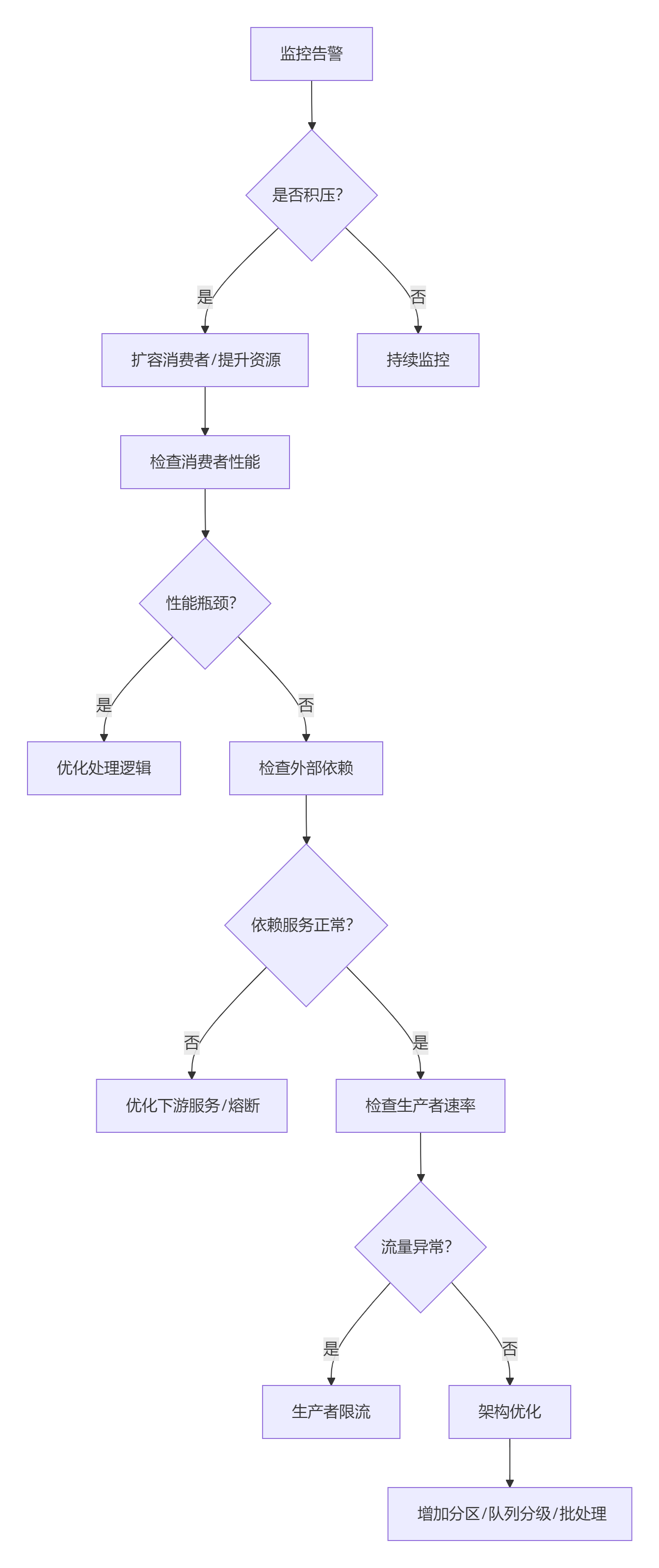
注意事项:
- 避免无脑增加消费者: Kafka必须同步增加分区数,否则无效
- 严禁跳过offset: 可能导致消息丢失,只应在测试环境使用
- 监控延迟比队列深度更重要: 例如消费滞后1小时需立即干预
- 压测: 任何优化后必须做全链路压测,验证吞吐量提升
📌 最终建议: 建立从监控告警→自动扩容→故障转移→根因分析的闭环处理机制。每次积压事件后需输出故障报告,持续迭代SOP流程。
通过上述系统化的分析和操作,大部分消息积压问题都能得到有效控制。务必优先保护消费端稳定性,再逐步提升系统吞吐量上限。