Java-99 深入浅出 MySQL 并发事务控制详解:更新丢失、锁机制与MVCC全解析
点一下关注吧!!!非常感谢!!持续更新!!!
🚀 AI篇持续更新中!(长期更新)
AI炼丹日志-31- 千呼万唤始出来 GPT-5 发布!“快的模型 + 深度思考模型 + 实时路由”,持续打造实用AI工具指南!📐🤖
💻 Java篇正式开启!(300篇)
目前2025年08月11日更新到:
Java-94 深入浅出 MySQL EXPLAIN详解:索引分析与查询优化详解
MyBatis 已完结,Spring 已完结,Nginx已完结,Tomcat已完结,分布式服务正在更新!深入浅出助你打牢基础!
📊 大数据板块已完成多项干货更新(300篇):
包括 Hadoop、Hive、Kafka、Flink、ClickHouse、Elasticsearch 等二十余项核心组件,覆盖离线+实时数仓全栈!
大数据-278 Spark MLib - 基础介绍 机器学习算法 梯度提升树 GBDT案例 详解
并发事务
事务并发处理可能会带来一些问题,比如:更新丢失、赃读、不可重复读、幻读等。
数据库事务更新丢失问题详解
当多个事务并发地对数据库中的同一行记录进行更新操作时,可能会产生更新丢失现象。这种情况通常发生在没有适当并发控制机制的情况下,主要分为以下两种类型:
1. 回滚覆盖(Rollback Overwrite)
定义:当一个事务执行回滚操作时,意外地将其他事务已经提交的数据覆盖掉。
发生场景:
- 事务A和事务B同时读取某行记录
- 事务A先修改该记录并提交
- 事务B随后修改该记录但最终决定回滚
- 在回滚过程中,事务B将记录恢复为最初读取的状态,导致事务A的修改被覆盖
示例:
假设银行账户余额为1000元:
- 事务A读取余额为1000元
- 事务B读取余额为1000元
- 事务A存入200元,更新余额为1200元并提交
- 事务B尝试取款300元,但系统检测余额不足(因为事务B看到的仍是1000元)
- 事务B回滚,将余额恢复为最初读取的1000元
- 结果:事务A的200元存款"丢失"
2. 提交覆盖(Commit Overwrite)
定义:当一个事务提交更新时,覆盖了其他事务已经提交的数据。
发生场景:
- 事务A和事务B同时读取某行记录
- 事务A先修改该记录并提交
- 事务B随后修改该记录并提交
- 事务B的提交覆盖了事务A的修改
示例:
假设商品库存为100件:
- 事务A读取库存为100件
- 事务B读取库存为100件
- 事务A卖出10件,更新库存为90件并提交
- 事务B卖出5件,基于最初读取的100件计算,更新库存为95件并提交
- 结果:正确的库存应为85件(100-10-5),但最终显示为95件,事务A的10件销售记录被覆盖
解决方案
数据库系统通常采用以下机制防止更新丢失:
- 锁机制:行级锁、表级锁等
- 乐观并发控制:使用版本号或时间戳检测冲突
- 悲观并发控制:在读取数据时就加锁
- 多版本并发控制(MVCC):维护数据的多个版本
这些机制的具体实现因数据库系统而异,如MySQL的InnoDB引擎主要使用MVCC和行级锁来避免此类问题。
赃读
一个事务读取了另一个事务修改但未提交的数据
不可重复读
一个事务中多次读取同一行记录不一致,后面读取的和前面读取的不一致。
幻读
一个事务中多次按相同条件查询,结果不一致。后续查询的结果和面前查询结果不同,多了或少了几行记录。
数据库事务的全局排队机制
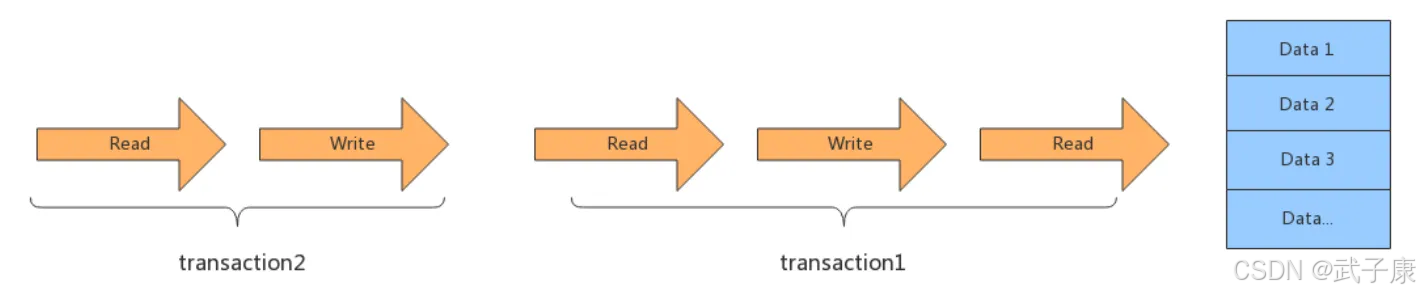
基本概念
全局排队是一种最为基础的事务处理方式,它将所有并发事务强制转换为串行执行。在这种模式下,数据库系统会维护一个全局事务队列,按照"先进先出"的原则依次处理每个事务请求。
实现原理
- 当一个新事务到达时,系统将其加入等待队列尾部
- 当前执行的事务完成后,系统从队列头部取出下一个事务开始执行
- 这个过程持续进行,确保任何时候只有一个事务处于活动状态
典型特征
- 强一致性保证:由于事务是完全串行执行的,消除了所有并发异常(如脏读、不可重复读、幻读等)
- 性能瓶颈:吞吐量直接受限于单事务的处理速度,无法利用多核CPU的并行计算能力
- 简单实现:不需要复杂的锁管理机制,实现代码量少,调试容易
适用场景
- 嵌入式数据库系统(如SQLite的默认模式)
- 对一致性要求极高但吞吐量要求不高的应用
- 系统开发和测试阶段,用于排除并发问题
性能表现示例
假设每个事务平均需要10ms处理时间:
- 理论最大TPS:1000ms/10ms = 100事务/秒
- 实际应用中,由于调度开销,通常只能达到理论值的60-80%
优缺点对比
优点:
- 实现简单,维护成本低
- 完全避免并发冲突
- 调试方便,执行顺序可预测
缺点:
- 资源利用率低(CPU、I/O多处于空闲状态)
- 响应时间随队列长度线性增长
- 无法满足现代高并发应用的需求
现代应用中的改进
虽然纯粹的全局排队已很少用于生产环境,但其思想仍被应用于:
- 某些特定操作的串行化执行(如DDL操作)
- 分布式系统的协调者节点
- 作为其他并发控制算法的降级方案
排他锁(Exclusive Lock)
排他锁(X锁)是数据库并发控制中最严格的锁类型,它实现了对数据项的独占式访问。当一个事务对数据项加排他锁后,其他事务既不能对该数据项加排他锁也不能加共享锁,必须等待当前事务释放锁后才能继续操作。
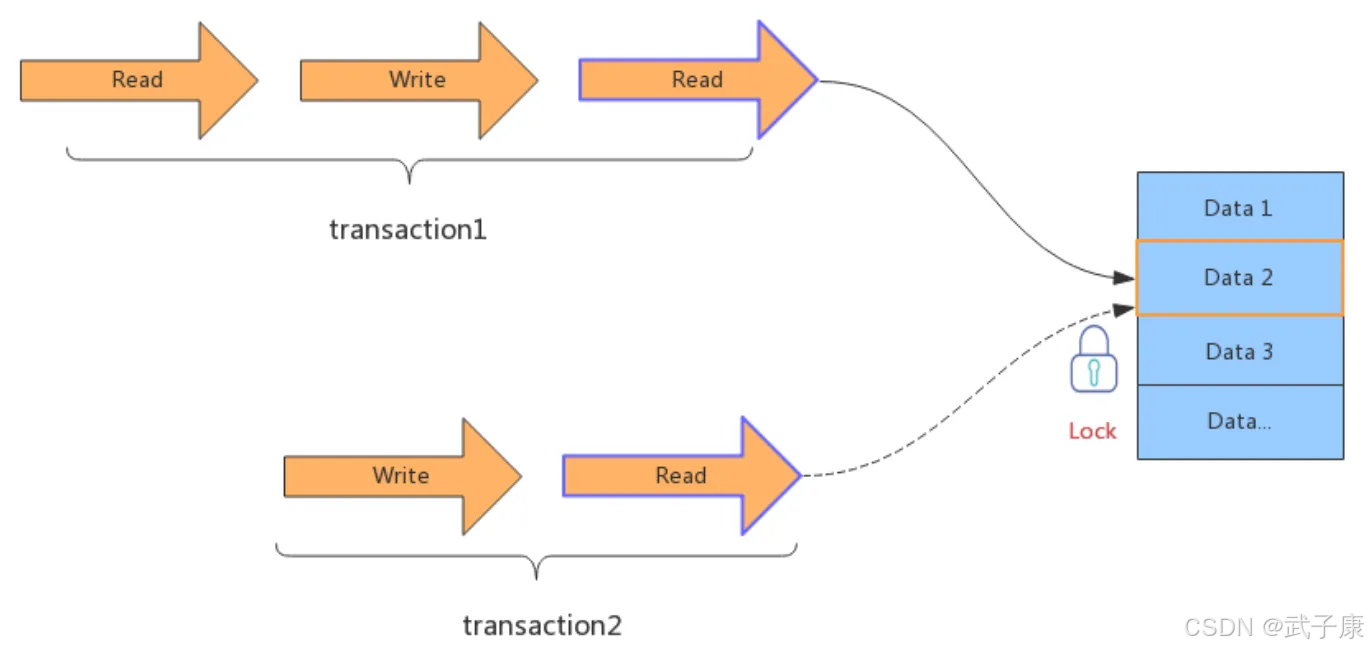
工作机制
-
获取锁阶段:
- 事务T1在读取或修改数据项D前,首先请求对D的排他锁
- 如果D当前未被其他事务锁定,系统立即授予T1排他锁
- 如果D已被其他事务T2锁定(无论是共享锁还是排他锁),T1必须等待直到T2释放锁
-
锁持续时间:
- 排他锁通常保持到事务结束(提交或回滚)
- 按照两阶段锁协议,事务在释放任何锁后不能再获取新锁
-
锁释放:
- 当事务完成对D的操作后,会在事务结束时自动释放锁
- 释放后,等待队列中的下一个事务可以获取锁
应用场景
-
数据修改操作:
- INSERT语句:插入新记录时自动获取排他锁
- UPDATE语句:修改现有记录需要排他锁
- DELETE语句:删除记录需要排他锁
-
显式锁定:
-- MySQL示例 SELECT * FROM accounts WHERE id = 1 FOR UPDATE; -- 对id=1的记录加排他锁 -
索引锁定:
- 当通过索引修改数据时,排他锁不仅会锁定数据行,还会锁定相关的索引项
性能影响
-
阻塞问题:
- 长时间持有排他锁会导致其他事务等待,降低系统吞吐量
- 可能出现死锁情况,需要死锁检测机制处理
-
锁粒度选择:
- 行级排他锁:锁定单行,并发度高
- 表级排他锁:锁定整个表,并发度低
-
隔离级别影响:
- 在READ COMMITTED级别,排他锁只保持到语句结束
- 在REPEATABLE READ和SERIALIZABLE级别,排他锁保持到事务结束
实际案例
银行转账事务中的排他锁使用:
BEGIN TRANSACTION;
-- 对账户A加排他锁
SELECT balance FROM accounts WHERE account_id = 'A' FOR UPDATE;
-- 对账户B加排他锁
SELECT balance FROM accounts WHERE account_id = 'B' FOR UPDATE;-- 执行转账操作
UPDATE accounts SET balance = balance - 100 WHERE account_id = 'A';
UPDATE accounts SET balance = balance + 100 WHERE account_id = 'B';COMMIT;
-- 事务提交时自动释放所有排他锁
在这个例子中,两个SELECT…FOR UPDATE语句确保了在转账过程中,其他事务无法同时修改这两个账户的余额,从而保证了数据的一致性。
读写锁
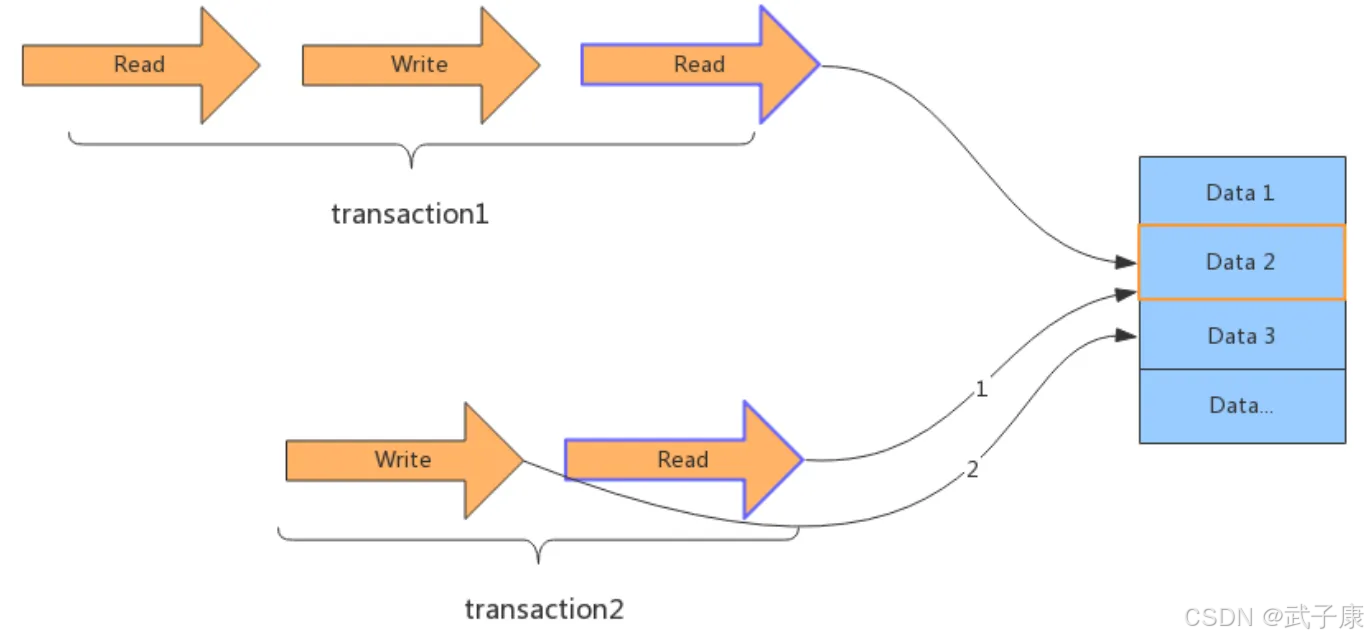
读写操作的基本类型
在并发编程中,数据的访问操作主要分为以下四种类型:
- 读读操作:多个线程同时读取数据
- 写写操作:多个线程同时写入数据
- 读写操作:一个线程读取数据时另一个线程写入数据
- 写读操作:一个线程写入数据时另一个线程读取数据
读写锁的核心思想
读写锁(ReadWrite Lock)是一种高级的同步机制,它通过区分读操作和写操作来优化并发性能。其核心思想包括:
- 读操作共享:允许多个线程同时获取读锁进行读取操作
- 写操作独占:只允许一个线程获取写锁进行写入操作,此时其他线程(无论是读还是写)都必须等待
- 读写互斥:当有线程持有写锁时,其他线程不能获取读锁;当有线程持有读锁时,其他线程不能获取写锁
实际应用场景
数据库系统
在数据库系统中,读写锁被广泛使用。例如:
- 多个客户端可以同时查询(读)数据库
- 但当一个客户端在更新(写)数据时,其他查询或更新操作必须等待
缓存系统
缓存系统中常见的使用模式:
// 伪代码示例
public Object getData(String key) {// 首先尝试获取读锁readLock.lock();try {if (cache.contains(key)) {return cache.get(key);}} finally {readLock.unlock();}// 缓存未命中,获取写锁writeLock.lock();try {// 双重检查if (!cache.contains(key)) {Object value = loadFromDB(key);cache.put(key, value);}return cache.get(key);} finally {writeLock.unlock();}
}
文件系统
文件系统中处理文件访问时:
- 多个进程可以同时读取文件
- 但当有进程在写入文件时,其他读写操作都必须等待
实现考虑因素
-
优先级策略:
- 读优先:倾向于让读操作先执行,可能导致写线程饥饿
- 写优先:倾向于让写操作先执行,可能影响读性能
- 公平策略:按照请求顺序执行
-
锁降级:允许线程在持有写锁的情况下获取读锁,然后释放写锁,实现从写锁到读锁的降级
-
锁升级:从读锁升级为写锁,通常需要特别处理以避免死锁
性能优势
相比普通的互斥锁,读写锁在以下场景中能显著提高性能:
- 读操作远多于写操作的系统
- 读操作耗时较长的场景
- 数据读取频繁但更新不频繁的缓存系统
通过这种细粒度的锁控制,系统可以在保证线程安全的同时,最大限度地提高并发性能。
读写锁,可以让读和读并行,而读和写、写和读、写和写这几种之间还是要加排他锁。
MVCC (多版本并发控制)
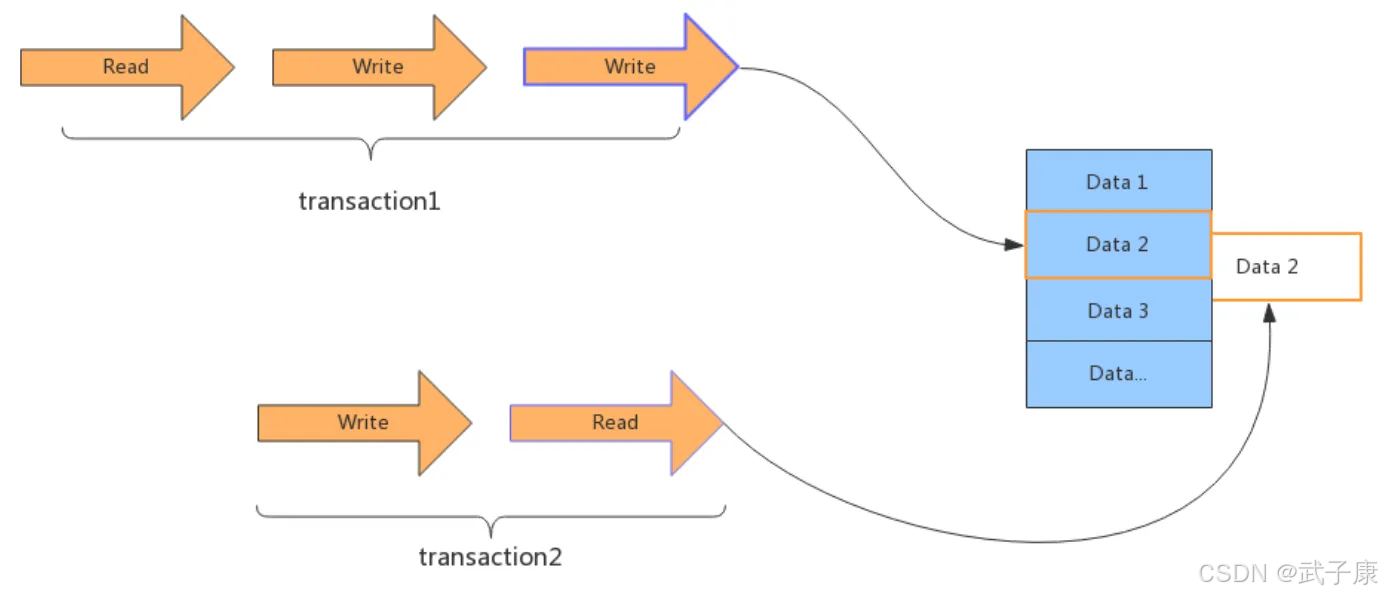
多版本并发控制(Multi-Version Concurrency Control,简称MVCC)是一种数据库并发控制技术,它基于"写时复制"(Copy On Write)的思想实现。MVCC的核心机制是为数据库中每个数据项维护多个版本,通过版本控制来实现高效的并发访问。
MVCC的工作原理
-
版本存储机制:
- 每个事务在修改数据时不会直接覆盖原有数据,而是创建该数据的新版本
- 系统会为每个版本记录创建时间戳或事务ID,标记该版本的创建时间
-
读操作处理:
- 读操作可以访问在事务开始前已经提交的数据版本
- 这种机制实现了"快照读"(Snapshot Read),确保读取的数据视图是一致的
-
并发控制能力:
- 读并行:多个读事务可以同时访问数据库的不同版本数据
- 读写并行:读事务可以访问已提交的旧版本,而写事务可以创建新版本
- 写读并行:写事务创建新版本时,读事务仍可访问旧版本
-
写冲突处理:
- 写写冲突:系统不允许两个事务同时修改同一数据项的同一版本
- 当检测到写写冲突时,通常采用以下策略之一:
- 中止其中一个事务
- 让一个事务等待另一个事务完成
MVCC的优势
- 提高并发性能:避免了大多数读操作需要等待的情况
- 减少锁争用:读操作不需要获取锁,大大降低了系统开销
- 保持一致性:通过版本控制确保事务看到一致的数据视图
实际应用示例
PostgreSQL中的MVCC实现:
- 使用事务ID(xmin)和失效事务ID(xmax)标记每个元组的生命周期
- 通过可见性规则判断哪些版本对当前事务可见
- 使用VACUUM机制定期清理不再需要的旧版本
MySQL InnoDB的MVCC实现:
- 通过隐藏的DB_TRX_ID字段记录创建和删除事务ID
- 使用undo日志存储旧版本数据
- 通过ReadView机制实现不同隔离级别下的可见性控制
MVCC技术通过维护数据的多个版本,实现了读操作与写操作之间的高度并行性,是现代数据库系统提高并发性能的关键技术之一。