深度学习 --- ResNet神经网络
深度学习 — ResNet神经网络
文章目录
- 深度学习 --- ResNet神经网络
- 一,ResNet提出
- 二,网络过深导致的问题
- 三,残差结构
- 四,网络的结构
- 五,变换策略
- 六,使用ResNet进行花卉识别
- 6.1 构建模型
- 6.2 模型训练
- 6.3 模型预测
一,ResNet提出
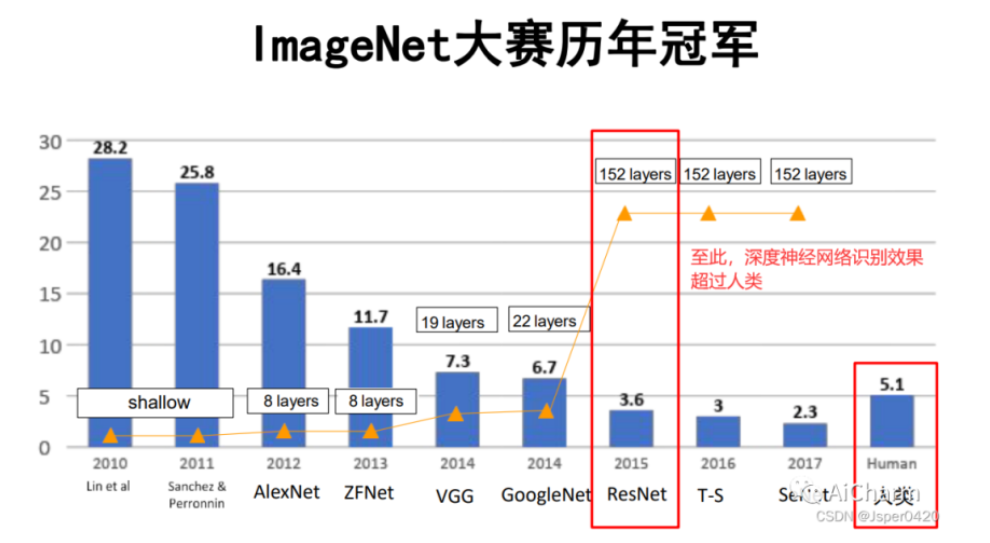
Resnet是一种深度神经网络架构,被广泛用于计算机视觉任务,特别是图像分类。ResNet是2015年的ImageNet大规模视觉识别竞赛(ImageNet Large Scale Visual Recognition Challenge, ILSVRC)中获得了图像分类和物体识别的冠军,是中国人何恺明、张祥雨、任少卿、孙剑在微软亚洲研究院(AI黄埔军校)的研究成果。
二,网络过深导致的问题
在深度学习发展过程中,随着网络深度的增加,会出现梯度消失或梯度爆炸的问题,导 致网络难以训练。即使通过归一化等方法解决了梯度问题,还会面临退化问题,即网络深度增加时,模型的训 练误差和测试误差反而增大。
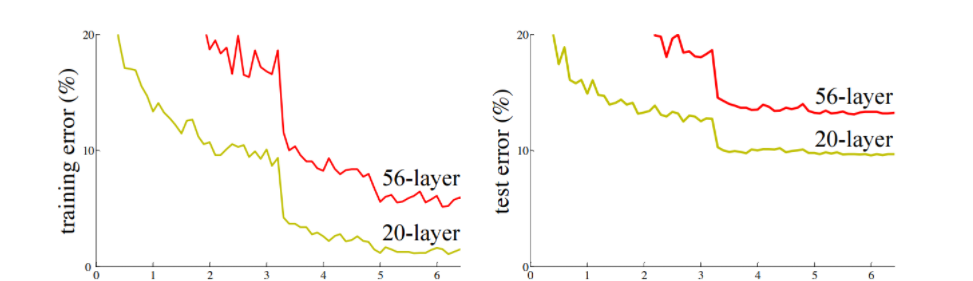
从上图可以看出,当网络层数增加时(例如从20层增加到56层),模型的效果反而变差了(误差率升高)。这说明网络并不是越深越好。
在深度神经网络训练中,每一层可以视为一个函数操作,记为。在反向传播过程中,梯度通过链式法则逐层计算。假设每个操作的梯度值小于1,那么多个小于1的数相乘会使结果逐渐变小。在神经网络中,随着反向传播的逐层传递,梯度可能会变得非常小,甚至趋近于零,这就是梯度消失问题。
相反,如果网络层操作后的输出值大于1,那么在反向传播时,梯度可能会相应增大。这种情况下,可能会出现梯度爆炸问题。梯度爆炸是指在深度神经网络中,梯度在逐层传递过程中逐渐放大,导致底层网络的参数更新过大,甚至可能引发数值溢出。
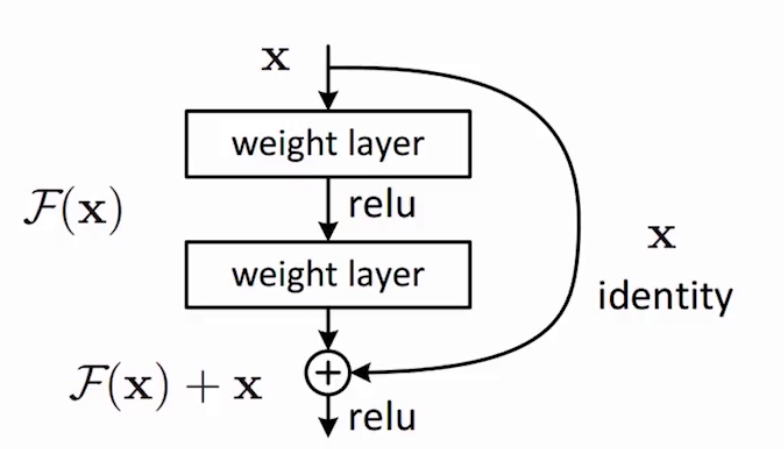
三,残差结构
在ResNet被提出之前,神经网络的架构主要是通过简单地堆叠卷积层和池化层来构建的。这种传统的架构在处理较浅的网络时效果尚可,但随着网络层数的增加,训练难度会急剧上升,导致诸如梯度消失或梯度爆炸等问题,进而影响模型的性能。因此,ResNet的出现对计算机视觉领域产生了深远的影响,它不仅解决了深层网络训练的难题,还为后续的深度学习研究提供了新的思路。
ResNet的核心创新在于引入了残差块(Residual Block)的概念。在传统的神经网络中,每一层的目的是直接学习输入到输出的映射关系。然而,这种直接映射的方式在深层网络中往往难以实现,因为随着网络层数的增加,梯度在反向传播过程中会逐渐变小甚至消失,导致网络难以训练。ResNet的残差块则改变了这一传统思路,它专注于学习输入与输出之间的残差映射,而不是直接拟合原始的目标函数。
具体来说,ResNet的核心思想是让网络去学习输入与输出之间的差异(即残差),而不是直接拟合原始的目标函数。假设我们期望的映射函数是H(x),ResNet会让网络去拟合残差函数F(x) = H(x) - x。最终的输出则是F(x) + x。这种结构是通过“跳过连接”(skip connections)或“快捷连接”(shortcut connections)实现的,即直接将输入信号添加到输出信号上。
这种设计的巧妙之处在于,它为网络提供了一种“捷径”,使得信息可以直接从输入端传递到输出端,而不需要经过每一层的逐层传递。这种“捷径”可以有效缓解梯度消失的问题,因为梯度可以通过这些连接直接传递到较浅的层,而不会因为逐层传递而逐渐变小。同时,这种设计也避免了梯度爆炸的问题,因为残差映射的性质使得网络的输出更加稳定。
为了更好地理解残差块的作用,可以将其比喻为一个高速公路系统。在这个系统中,主路是神经网络的正常运算路径,而捷径则是一条可以直接从输入端到达输出端的辅路。即使主路因为某些问题(如梯度消失)无法有效传递信息,数据仍然可以通过捷径直接流通,从而保证了信息的完整性和网络的学习能力。
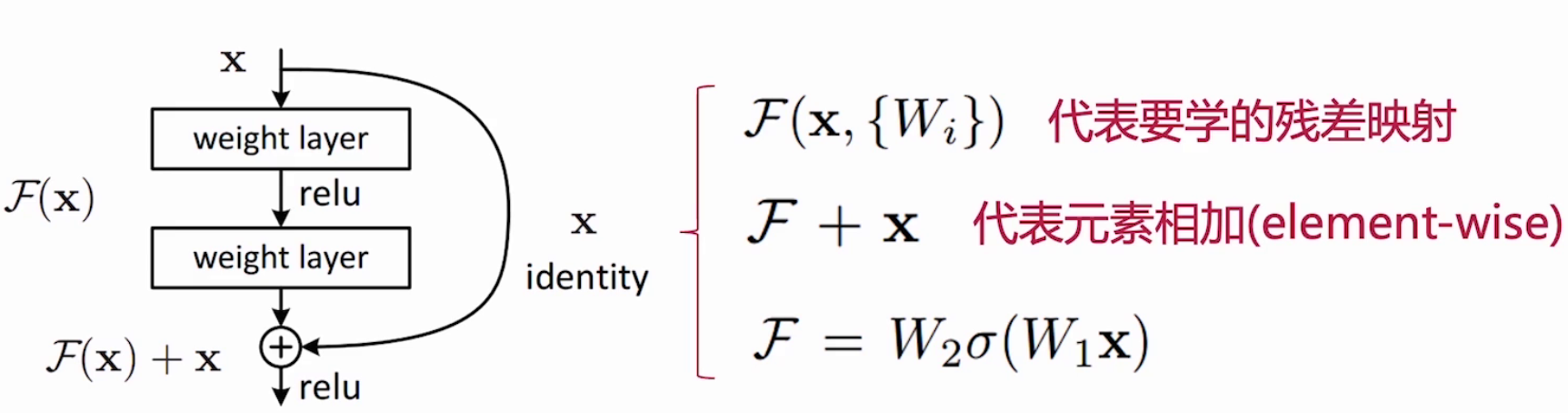
四,网络的结构
ResNet18,ResNet34,ResNet50,ResNet101,ResNet152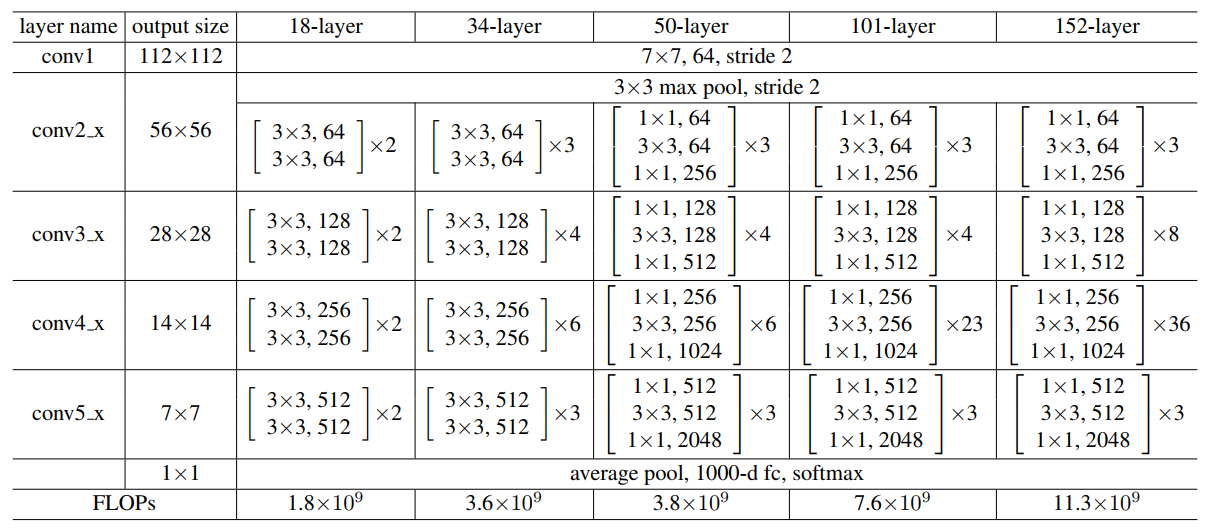
- ResNet-18:是 ResNet 家族中相对较浅的网络,由 4 个残差块组构成,每个残差块组包含不同数量的残差块。它的结构简单,计算量相对较小,适合计算资源有限或对模型复杂度要求不高的场景,如一些小型图像数据集的分类任务。它在一些对实时性要求较高的应用中,如移动设备上的图像识别,也有一定的应用。
- ResNet-34:同样由 4 个残差块组组成,但相比 ResNet-18,它在某些残差块组中包含更多的残差块,网络深度更深,因此能够学习到更复杂的特征表示。它在中等规模的图像数据集上表现良好,在一些对模型性能有一定要求但又不过分追求极致精度的任务中较为常用。
- ResNet-50:是一个比较常用的 ResNet 模型,在许多计算机视觉任务中都有广泛应用。它使用了瓶颈结构(Bottleneck)的残差块,这种结构通过先降维、再卷积、最后升维的方式,在减少计算量的同时保持了模型的表达能力。该模型在图像分类、目标检测、语义分割等任务中,都能作为性能不错的骨干网络,为后续的任务提供有效的特征提取。
- ResNet-101:比 ResNet-50 的网络层数更多,拥有更强大的特征提取能力。它适用于大规模图像数据集和复杂的计算机视觉任务,如在大型目标检测数据集中,能够更好地捕捉目标的细节特征,提升检测的准确性。由于其深度和复杂度,在处理高分辨率图像或需要精细特征表示的任务时表现出色。
- ResNet-152:是 ResNet 系列中深度较深的网络,具有极高的特征提取能力。但由于其深度很大,计算量和参数量也相应增加,训练和推理所需的时间和资源较多。它通常用于对精度要求极高的场景,如学术研究中的图像识别挑战、大规模图像搜索引擎的图像特征提取等。
五,变换策略
不同尺度的特征相加时,采用不同的维度变换策略。
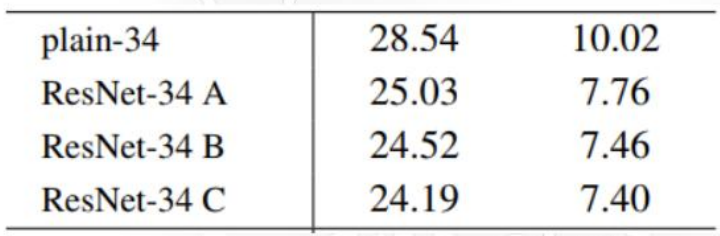
三种变换策略:
(A):在升维时使用补零
(B):在升维时使用1x1卷积进行映射
(C ):所有残差连接使用1x1卷积进行映射
六,使用ResNet进行花卉识别
6.1 构建模型
model.py
import torch
import torch.nn.functional as F
import torch.nn as nn# 定义残差块类,继承自 nn.Module
class ResBlock(nn.Module):def __init__(self, channels_in):# 调用父类的构造函数super().__init__()# 定义第一个卷积层,输入通道数为 channels_in,输出通道数为 30,卷积核大小为 5,填充为 2self.conv1 = torch.nn.Conv2d(channels_in, 30, 5, padding=2)# 定义第二个卷积层,输入通道数为 30,输出通道数为 channels_in,卷积核大小为 3,填充为 1self.conv2 = torch.nn.Conv2d(30, channels_in, 3, padding=1)def forward(self, x):# 输入数据通过第一个卷积层out = self.conv1(x)# 经过第一个卷积层的输出再通过第二个卷积层out = self.conv2(out)# 将输入 x 与卷积输出 out 相加,并通过 ReLU 激活函数return F.relu(out + x)# 定义 ResNet 网络类,继承自 nn.Module
class ResNet(nn.Module):def __init__(self,num_classes=5, init_weights=False):# 调用父类的构造函数super().__init__()self._config = {'num_classes': num_classes}# 定义第一个卷积层,输入通道数为 1,输出通道数为 20,卷积核大小为 5self.conv1 = torch.nn.Conv2d(3, 20, 5)# 定义第二个卷积层,输入通道数为 20,输出通道数为 15,卷积核大小为 3self.conv2 = torch.nn.Conv2d(20, 15, 3)# 定义最大池化层,池化核大小为 2self.maxpool = torch.nn.MaxPool2d(2)# 定义第一个残差块,输入通道数为 20self.resblock1 = ResBlock(channels_in=20)# 定义第二个残差块,输入通道数为 15self.resblock2 = ResBlock(channels_in=15)# 定义全连接层,输入特征数为 375,输出特征数为 10self.full_c = torch.nn.Linear(43740, self._config['num_classes'])def forward(self, x):# 获取输入数据的批次大小size = x.shape[0]# 输入数据通过第一个卷积层,然后进行最大池化,最后通过 ReLU 激活函数x = F.relu(self.maxpool(self.conv1(x)))# 经过第一个卷积和池化的输出通过第一个残差块x = self.resblock1(x)# 经过第一个残差块的输出通过第二个卷积层,然后进行最大池化,最后通过 ReLU 激活函数x = F.relu(self.maxpool(self.conv2(x)))# 经过第二个卷积和池化的输出通过第二个残差块x = self.resblock2(x)# 将输出数据展平为一维向量x = x.view(size, -1)# 展平后的向量通过全连接层x = self.full_c(x)return xdef _initialize_weights(self):for m in self.modules():if isinstance(m, nn.Conv2d):nn.init.kaiming_normal_(m.weight, mode='fan_out', nonlinearity='relu')if m.bias is not None:nn.init.constant_(m.bias, 0)elif isinstance(m, nn.Linear):nn.init.normal_(m.weight, 0, 0.01)nn.init.constant_(m.bias, 0)6.2 模型训练
import os
import sys
import json
import torch
import torch.nn as nn
from torchvision import transforms, datasets, utils
import matplotlib.pyplot as plt
import numpy as np
import torch.optim as optim
from tqdm import tqdm
from model import ResNetdef main():# 使用GPUdevice = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")print("using {} device.".format(device))data_transform = {"train":transforms.Compose([transforms.RandomResizedCrop(224), # 随机裁剪 224*224transforms.RandomHorizontalFlip(), # 随机翻转 水平方向随机翻转进行数据增强transforms.ToTensor(), # 转化为Tensortransforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),"val":transforms.Compose([transforms.Resize((224, 224)), # cannot 224, must (224, 224)transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])}# 数据集路径data_root = os.path.abspath(os.path.join(os.getcwd(), "dataset"))image_path = os.path.join(data_root, "flower_photos") # flower data set path# 加载整个数据集dataset = datasets.ImageFolder(root=image_path, transform=data_transform["train"])train_num = len(dataset) # 数据集总图片数# 字典,类别:索引{'daisy':0, 'dandelion':1, 'roses':2, 'sunflower':3, 'tulips':4}flower_list = dataset.class_to_idx # 去获取分类名称所对应的索引cla_dict = dict((val, key) for key, val in flower_list.items())# 写入json文件json_str = json.dumps(cla_dict, indent=4)with open('flower_ResNet/class_indices.json', 'w') as json_file:json_file.write(json_str)# 划分训练集和验证集train_size = int(0.8 * len(dataset))val_size = len(dataset) - train_sizetrain_dataset, validate_dataset = torch.utils.data.random_split(dataset, [train_size, val_size])batch_size = 32train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=batch_size, shuffle=True, num_workers=0)validate_loader = torch.utils.data.DataLoader(validate_dataset, batch_size=4, shuffle=False, num_workers=0)print("using {} images for training, {} images for validation.".format(train_size, val_size))net = ResNet(num_classes=5, init_weights=True)net.to(device)loss_function = nn.CrossEntropyLoss()optimizer = optim.Adam(net.parameters(), lr=0.0002)epochs = 10save_path = './flower_ResNet/ResNet.pth' # 保存网络的路径best_acc = 0.0 # 定义这个参数是为了在后边训练网络中保存准确率最高的那次模型train_steps = len(train_loader)for epoch in range(epochs):# trainnet.train()running_loss = 0.0train_bar = tqdm(train_loader, file=sys.stdout)for step, data in enumerate(train_bar):images, labels = dataoptimizer.zero_grad()outputs = net(images.to(device))loss = loss_function(outputs, labels.to(device))loss.backward()optimizer.step()# print statisticsrunning_loss += loss.item()train_bar.desc = "train epoch[{}/{}] loss:{:.3f}".format(epoch + 1, epochs, loss)# validatenet.eval()acc = 0.0with torch.no_grad():val_bar = tqdm(validate_loader, file=sys.stdout)for val_data in val_bar:val_images, val_labels = val_dataoutputs = net(val_images.to(device))predict_y = torch.max(outputs, dim=1)[1]acc += torch.eq(predict_y, val_labels.to(device)).sum().item()val_accurate = acc / val_sizeprint('[epoch %d] train_loss: %.3f val_accuracy: %.3f' % (epoch + 1, running_loss / train_steps, val_accurate))if val_accurate > best_acc:best_acc = val_accuratetorch.save(net.state_dict(), save_path)print('Finished Training')if __name__ == '__main__':main()
6.3 模型预测
import os
import json
import torch
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
from model import ResNet
import osos.environ["KMP_DUPLICATE_LIB_OK"] = "TRUE"def main():device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")data_transform = transforms.Compose( # 依然是对数据先进行预处理[transforms.Resize((224, 224)),transforms.ToTensor(),transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])# load imageimg_path = "./dataset/flower_photos/dandelion/8223949_2928d3f6f6_n.jpg"assert os.path.exists(img_path), "file: '{}' dose not exist.".format(img_path)img = Image.open(img_path) # 直接使用PIL库载入一张图像plt.imshow(img) # 简单展示一下这张图片# [N, C, H, W]img = data_transform(img) # 对图片进行预处理# expand batch dimensionimg = torch.unsqueeze(img, dim=0) # 扩充一个维度,添加一个batch维度# read class_indictjson_path = './flower_ResNet/class_indices.json' # 读取json文件,也就是索引对应的类别名称assert os.path.exists(json_path), "file: '{}' dose not exist.".format(json_path)with open(json_path, "r") as f:class_indict = json.load(f) # 对json文件进行解码,解码成我们所需要的字典# create modelmodel = ResNet(num_classes=5).to(device) # 初始化我们的网络# load model weightsweights_path = "./flower_ResNet/ResNet.pth"assert os.path.exists(weights_path), "file: '{}' dose not exist.".format(weights_path)model.load_state_dict(torch.load(weights_path)) # 载入我们的网络模型model.eval() # 进入eval模式,没有dropout的那个with torch.no_grad(): # 不跟踪变量的损失梯度# predict classoutput = torch.squeeze(model(img.to(device))).cpu() # 将数据通过model进行正向传播得到输出# squeeze将输出进行压缩,把第一个维度的batch压缩掉了predict = torch.softmax(output, dim=0) # softmax得到概率分布predict_cla = torch.argmax(predict).numpy() # 概率最大处所对应的索引值print_res = "class: {} prob: {:.3}".format(class_indict[str(predict_cla)],predict[predict_cla].numpy())# 打印预测名称,已经对应类别的概率plt.title(print_res)for i in range(len(predict)):print("class: {:10} prob: {:.3}".format(class_indict[str(i)],predict[i].numpy()))plt.show()if __name__ == '__main__':main()