因果推断在用户流失预警的案例研究
文章出自:Beyond Churn Prediction and Churn Uplift
本篇文章的技术亮点在于超越了传统的客户流失预测,强调通过因果推断来提升收益。作者提出了不同的干预策略,并通过模拟数据验证了这些策略的有效性,尤其是通过“总收益提升”方法来实现利润最大化。
实际案例中,作者通过不同的干预策略,展示了如何根据客户的流失概率和收益潜力来选择目标客户,最终找到了一种有效的赠品策略,成功实现了盈利。
文章目录
- 1 玩具案例
- 2 探索性数据分析
- 3 分人群策略讨论
- 3.1 针对流失客户
- 3.2 针对高收入客户
- 3.3. 针对客户流失提升客户
- 3.4. 针对收入提升客户
- 3.5. 针对总收入提升客户
- 4 分人群解析
- 5 优化策略:加权观测值
- 6 结论
- 7 参考文献
- 8 代码
在数据科学中,一项非常常见的任务是客户流失预测。然而,预测客户流失通常只是一个中间步骤,很少是最终目标。通常,我们真正关心的是减少客户流失,这是一个独立的目标,不一定相关。事实上,例如,知道长期客户比新客户更不容易流失并不是一个可操作的洞察,因为我们无法增加客户的活跃时长。我们更想知道的是,一种(或多种)处理如何影响客户流失。这通常被称为churn uplift。
在本文中,我们将不仅仅考虑客户流失预测和客户流失提升,转而考虑客户流失预防活动的最终目标:增加收入。首先,一项减少客户流失的政策也可能对收入产生影响,这应该被考虑在内。然而,更重要的是,只有当客户不流失时,增加收入才具有相关性。反之,对于高收入客户来说,减少客户流失更为重要。客户流失和收入之间的这种互动对于理解任何处理活动的盈利能力都至关重要,不应被忽视。
1 玩具案例
在文章的其余部分,我们将使用一个玩具示例来说明主要思想。假设我们是一家公司,致力于减少客户流失并最终增加收入。
假设我们决定测试一个新想法:向我们的用户发送一份价值 $1 的赠品。为了测试这种处理是否有效,我们随机将其发送给了我们客户群中的一个子样本。
cost = 1
让我们看看我们手头的数据。我从 src.dgp 导入了数据生成过程 dgp_gift()。我还从 src.utils 导入了一些绘图函数和库。
from src.utils import *
from src.dgp import dgp_giftdgp = dgp_gift(n=100_000)
df = dgp.generate_data()
df.head()
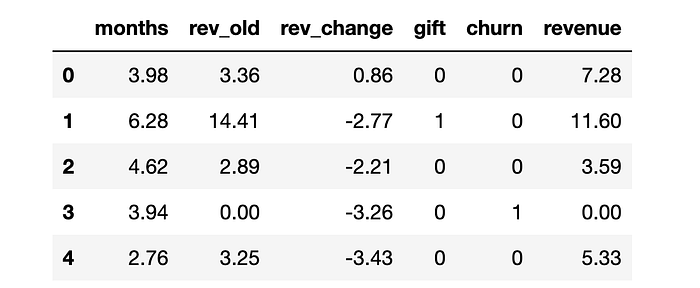
我们有 100_000 名客户的信息,我们观察到他们活跃的 months(月数)、他们在上个月产生的收入 (rev_old)、上个月和前一个月之间的收入变化 (rev_change)、他们是否随机收到了 gift(赠品),以及两个感兴趣的结果:churn(客户流失),即他们是否不再是活跃客户,以及他们在当前月份产生的 revenue(收入)。我们用字母 YYY 表示结果,用字母 WWW 表示处理,用字母 XXX 表示其他变量。
Y = ['churn', 'revenue']
W = 'gift'
X = ['months', 'rev_old', 'rev_change']
请注意,为简单起见,我们只考虑了数据的单期快照,并将数据的面板结构总结为几个变量。通常,我们将拥有更长的时间序列,并且结果(例如客户生命周期价值)的时间范围也更长。
我们可以用以下有向无环图 (DAG) 来表示底层数据生成过程。节点代表变量,箭头代表潜在的因果关系。我用绿色突出显示了两个感兴趣的关系:gift 对 churn 和 revenue 的影响。请注意,churn 与收入相关,因为流失的客户,根据定义,产生的收入为零。
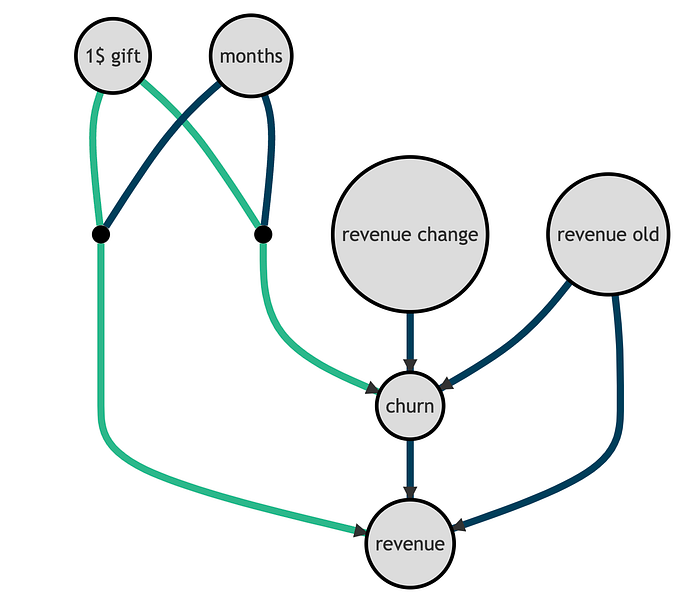
重要的是,过去的收入和收入变化是 churn 和 revenue 的预测因子,但与我们的干预无关。相反,干预对 churn 和 revenue 的影响因客户总活跃 months 的不同而不同。
虽然这个数据生成过程很简单,但它旨在捕捉一个重要的洞察:那些能很好地预测 churn 或 revenue 的变量,不一定能预测 churn 或 revenue 的提升。我们稍后将看到这如何影响我们的分析。
让我们首先探索数据。
2 探索性数据分析
让我们从 churn 开始。公司上个月流失了多少客户?
df.churn.mean()
0.19767
公司上个月流失了近 20%20\%20% 的客户!gift 有助于防止客户流失吗?
我们想比较收到赠品的客户与未收到赠品的客户的流失频率。
由于赠品是随机的,差分均值估计器是 gift 对 churn 的平均处理效应 (ATE) 的无偏估计器。
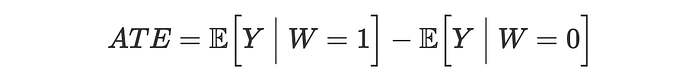
我们通过线性回归计算差分均值估计。我们还包括其他协变量以提高估计器的效率。
smf.ols("churn ~ " + W + " + " + " + ".join(X), data=df).fit().summary().tables[1]
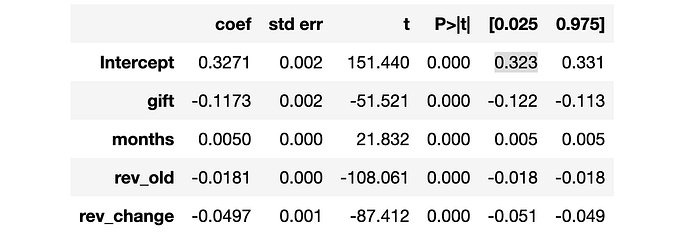
看起来 gift 使客户流失率降低了大约 111111 个百分点,即几乎是基线水平 32%32\%32% 的三分之一!它对 revenue 也有影响吗?
与客户流失一样,我们将 revenue 对 gift(我们的处理变量)进行回归,以估计平均处理效应。
smf.ols("revenue ~ " + W + " + " + " + ".join(X), data=df).fit().summary().tables[1]
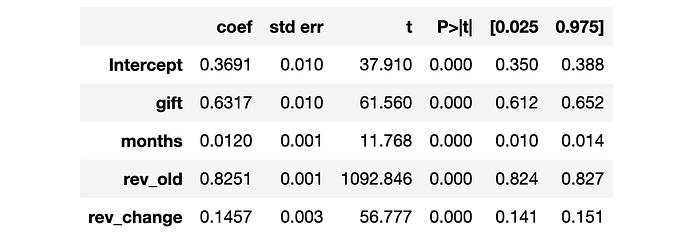
看起来 gift 平均增加了 0.630.630.63 美元的收入,这意味着它不盈利。这是否意味着我们应该停止向客户发送赠品?这取决于情况。事实上,赠品可能对某些客户群有效。我们只需要识别它们。
3 分人群策略讨论
在本节中,我们将尝试了解是否存在一种数据驱动的盈利方式来发送 gift,即通过针对特定客户。特别是,我们将比较不同人群策略,目标是增加收入。
在本节中,我们将需要一些算法来预测 revenue 或 churn,或预测收到 gift 的概率。我们使用来自 lightgbm 库的梯度提升树模型。我们对所有政策使用相同的模型,这样我们就不能将性能差异归因于预测准确性。
from lightgbm import LGBMClassifier, LGBMRegressor
为了评估每项政策,我们希望在独立的验证数据集中,将实施政策的隐含利润 Π(1)\Pi^{(1)}Π(1) 与不实施政策的隐含利润 Π(0)\Pi^{(0)}Π(0) 进行比较,针对每个个体。我们将这两个量称为潜在结果,它们的差值称为利润提升,我们用 τ\tauτ 表示。请注意,提升是不可观测的,因为对于每个客户,我们只能观测到两种潜在结果中的一种,即有或没有 gift。然而,由于我们正在处理合成数据,我们可以进行预言机评估。如果您想了解如何使用真实数据评估提升模型,我推荐我的入门文章。
首先,让我们将利润 Π\PiΠ 定义为客户不流失 CCC 时的净收入 RRR。
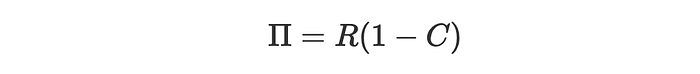
因此,对于接受处理的个体,对利润的总体影响由两个假设量之间的差值给出:接受处理时的利润 Π(1)\Pi^{(1)}Π(1) 减去未接受处理时的利润 Π(0)\Pi^{(0)}Π(0)。
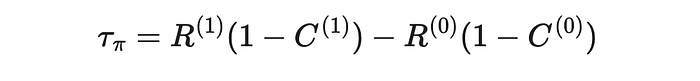
未接受处理的个体的影响为零。
def evaluate_policy(policy):data = dgp.generate_data(seed_data=4, seed_assignment=5, keep_po=True)data['profits'] = (1 - data.churn) * data.revenuebaseline = (1-data.churn_c) * data.revenue_ceffect = policy(data) * (1-data.churn_t) * (data.revenue_t-cost) + (1-policy(data)) * (1-data.churn_c) * data.revenue_creturn np.sum(effect - baseline)
3.1 针对流失客户
第一个人群策略可能是只针对流失客户。假设我们只向预测流失率高于平均水平的客户发送 gift。
model_churn = LGBMClassifier().fit(X=df[X], y=df['churn'])policy_churn = lambda df : (model_churn.predict_proba(df[X])[:,1] > df.churn.mean())
evaluate_policy(policy_churn)
-5497.46
该政策不盈利,将导致总计超过 500050005000 美元的损失。
您可能会认为问题在于任意阈值,但事实并非如此。下面我绘制了所有可能政策阈值的总体效应。
x = np.linspace(0, 1, 100)
y = [evaluate_policy(lambda df : (model_churn.predict_proba(df[X])[:,1] > p)) for p in x]fig, ax = plt.subplots(figsize=(10, 3))
sns.lineplot(x=x, y=y).set(xlabel='Churn Policy Threshold', title='Aggregate Effect');
ax.axhline(y=0, c='k', lw=3, ls='--');
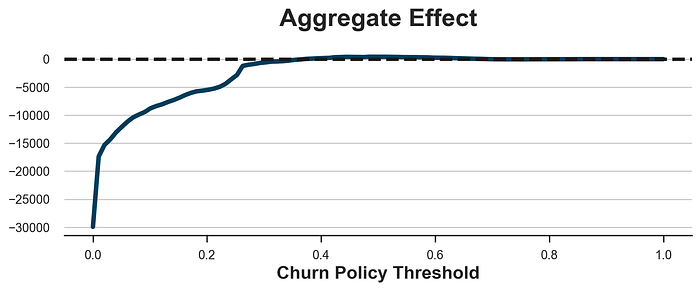
正如我们所看到的,无论阈值如何,基本上不可能获得任何利润。
问题在于,客户可能流失的事实并不意味着 gift 会对其流失概率产生任何影响。这两个衡量标准并非完全无关(例如,我们无法降低流失概率为 0%0\%0% 的客户的流失概率),但它们并非同一回事。
3.2 针对高收入客户
现在让我们尝试一个不同的人群策略:我们只向高收入客户发送赠品。例如,我们可能只向收入排名前 10%10\%10% 的客户发送赠品。这个想法是,如果该政策确实能降低客户流失,那么这些客户是降低客户流失最有利可图的客户。
model_revenue = LGBMRegressor().fit(X=df[X], y=df['revenue'])policy_revenue = lambda df : (model_revenue.predict(df[X]) > np.quantile(df.revenue, 0.9))
evaluate_policy(policy_revenue)
-4730.82
该政策再次不盈利,导致大量损失。和以前一样,这不是选择阈值的问题,如下图所示。我们能做的最好的事情是设置一个非常高的阈值,这样我们就不会处理任何人,并且我们获得零利润。
x = np.linspace(0, 100,
```markdown
```python
x = np.linspace(0, 100, 100)
y = [evaluate_policy(lambda df : (model_revenue.predict(df[X]) > c)) for c in x]fig, ax = plt.subplots(figsize=(10, 3))
sns.lineplot(x=x, y=y).set(xlabel='Revenue Policy Threshold', title='Aggregate Effect');
ax.axhline(y=0, c='k', lw=3, ls='--');
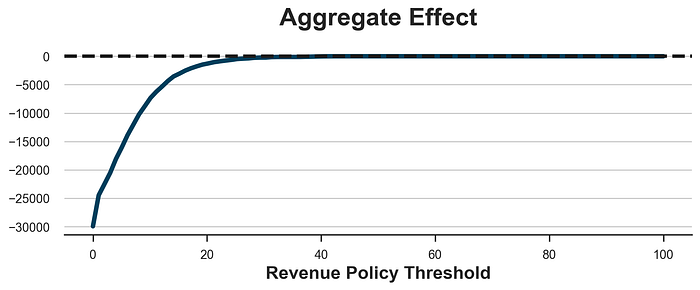
问题在于,在我们的设置中,高收入客户的流失概率并没有降低到足以使 gift 盈利的程度。这部分也归因于一个在现实中经常观察到的事实:高收入客户最初也是最不容易流失的客户。
现在让我们考虑一组更相关的政策:基于提升uplift的人群策略。
3.3. 针对客户流失提升客户
一个更明智的方法是针对那些在收到 111 美元 gift 后 churn 概率下降最多的客户。我们使用双重稳健估计器来估计客户流失提升,它是表现最好的提升模型之一。如果您不熟悉元学习器,我建议从我的入门文章开始。
我们从 Microsoft 的 econml 库中导入双重稳健学习器。
from econml.dr import DRLearnerDR_learner_churn = DRLearner(model_regression=LGBMRegressor(), model_propensity=LGBMClassifier(), model_final=LGBMRegressor())
DR_learner_churn.fit(df['churn'], df[W], X=df[X]);
现在我们已经估计了客户流失提升,我们可能会倾向于只针对那些具有高负提升的客户(负值,因为我们希望降低客户流失)。例如,我们可能会向所有估计提升大于平均客户流失的客户发送 gift。
policy_churn_lift = lambda df : DR_learner_churn.effect(df[X]) < - np.mean(df.churn)
evaluate_policy(policy_churn_lift)
-3925.24
该政策仍然不盈利,导致近 400040004000 美元的损失。
问题在于我们没有考虑政策的成本。事实上,降低客户流失概率只对高收入客户有利可图。举一个极端的例子:避免一个不产生任何收入的客户流失是不值得任何干预的。
因此,我们只向那些其流失概率乘以收入的权重下降幅度大于赠品成本的客户发送 gift。
model_revenue_1 = LGBMRegressor().fit(X=df.loc[df[W] == 1, X], y=df.loc[df[W] == 1, 'revenue'])policy_churn_lift = lambda df : - DR_learner_churn.effect(df[X]) * model_revenue_1.predict(df[X]) > cost
evaluate_policy(policy_churn_lift)
318.03
这项政策终于盈利了!
然而,我们仍然没有考虑一个渠道:干预也可能影响现有客户的收入。
3.4. 针对收入提升客户
与前一种方法对称,只考虑对 revenue 的影响,而忽略对客户流失的影响。我们可以估计非流失客户的 revenue 提升,并且只处理那些其收入增量效应(扣除客户流失后)大于 gift 成本的客户。
DR_learner_netrevenue = DRLearner(model_regression=LGBMRegressor(), model_propensity=LGBMClassifier(), model_final=LGBMRegressor())
DR_learner_netrevenue.fit(df.loc[df.churn==0, 'revenue'], df.loc[df.churn==0, W], X=df.loc[df.churn==0, X]);
model_churn_1 = LGBMClassifier().fit(X=df.loc[df[W] == 1, X], y=df.loc[df[W] == 1, 'churn'])policy_netrevenue_lift = lambda df : DR_learner_netrevenue.effect(df[X]) * (1-model_churn_1.predict(df[X])) > cost
evaluate_policy(policy_netrevenue_lift)
50.80
这项政策也盈利,但忽略了对客户流失的影响。我们如何将这项政策与前一项政策结合起来?
3.5. 针对总收入提升客户
有效结合客户流失影响和净收入影响的最佳方法是简单地估计总收入提升。隐含的最佳人群策略是处理那些总收入提升大于 gift 成本的客户。
DR_learner_revenue = DRLearner(model_regression=LGBMRegressor(), model_propensity=LGBMClassifier(), model_final=LGBMRegressor())
DR_learner_revenue.fit(df['revenue'], df[W], X=df[X]);policy_revenue_lift = lambda df : (DR_learner_revenue.effect(df[X]) > cost)
evaluate_policy(policy_revenue_lift)
2028.21
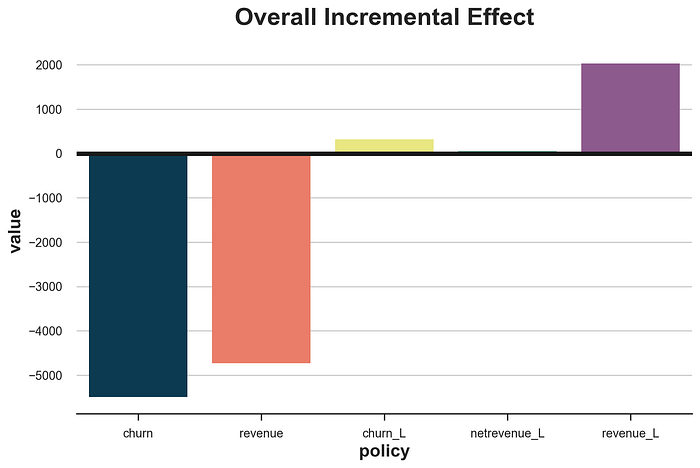
这项政策是迄今为止表现最好的,创造了超过 200020002000 美元的总利润!
policies = [policy_churn, policy_revenue, policy_churn_lift, policy_netrevenue_lift, policy_revenue_lift]
df_results = pd.DataFrame()
df_results['policy'] = ['churn', 'revenue', 'churn_L', 'netrevenue_L', 'revenue_L']
df_results['value'] = [evaluate_policy(policy) for policy in policies]fig, ax = plt.subplots()
sns.barplot(df_results, x='policy', y='value').set(title='Overall Incremental Effect')
plt.axhline(0, c='k');
4 分人群解析
如果我们比较不同的政策,很明显,针对高收入或高流失概率的客户是最糟糕的选择。这不一定总是如此,但在我们的模拟数据中之所以如此,是因为两个在许多实际场景中也很常见的事实:
- 收入和流失概率呈负相关。
gift对churn(或revenue)的影响与基线值没有很强的负相关(或正相关)。
这两个事实中的任何一个都足以使针对收入或客户流失成为一个糟糕的策略。相反,应该针对那些具有高增量效应的客户。最好直接使用感兴趣的变量作为结果,在这种情况下是 revenue,只要可用。
为了更好地理解这个机制,我们可以将政策对利润的总体效应分解为三个部分。

这意味着有三个渠道可以使处理客户盈利。
- 如果客户是高收入客户,并且处理降低了其流失概率。
- 如果客户是未流失客户,并且处理增加了其收入。
- 如果处理对其收入和流失概率都产生了强烈影响。
通过客户流失提升进行定位只利用了第一个渠道,通过净收入提升进行定位只利用了第二个渠道,而通过总收入提升进行定位则利用了所有三个渠道,使其成为最有效的方法。
5 优化策略:加权观测值
正如 Lemmens, Gupta (2020) 所强调的,有时在估计提升时加权观测值可能是有价值的。特别是,可能值得对接近处理政策阈值的观测值给予更多权重。
想法是,加权通常会降低估计器的效率。然而,我们不关心所有观测值是否具有正确的估计,而是关心政策阈值是否估计正确。事实上,无论您估计净利润为 111 美元还是 100010001000 美元都无关紧要:隐含的政策是相同的:发送 gift。然而,估计净利润为 111 美元而不是 −1-1−1 美元会改变政策含义。因此,远离阈值的准确性的大幅损失有时值得在阈值处获得的小幅收益。
让我们尝试使用负指数权重,随着与阈值的距离增加而减小。
DR_learner_revenue_w = DRLearner(model_regression=LGBMRegressor(), model_propensity=LGBMClassifier(), model_final=LGBMRegressor())
w = np.exp(1 + np.abs(DR_learner_revenue.effect(df[X]) - cost))
DR_learner_revenue_w.fit(df['revenue'], df[W], X=df[X], sample_weight=w);policy_revenue_lift_w = lambda df : (DR_learner_revenue_w.effect(df[X]) > cost)
evaluate_policy(policy_revenue_lift_w)
1398.19
在我们的案例中,加权并不值得:隐含的政策仍然盈利,但比未加权模型获得的 202820282028 美元要少。
6 结论
在本文中,我们探讨了为什么以及如何超越客户流失预测和客户流失提升建模。特别是,应该专注于增加盈利能力的最终业务目标。这意味着将重点从预测转移到提升,同时将客户流失和收入结合到一个单一的结果中。
一个重要的注意事项是可用数据的维度。我们使用了一个玩具数据集,它至少在两个维度上高度简化了问题。首先,回顾过去,我们通常有更长的时间序列,可以(也应该)用于预测和建模目的。其次,展望未来,应该将客户流失与客户盈利能力的长期估计结合起来,这通常被称为客户生命周期价值。
7 参考文献
- Kennedy (2022), “Towards Optimal Doubly Robust Estimation of Heterogeneous Causal Effects”
- Bonvini, Kennedy, Keele (2021), “Minimax Optimal Subgroup Identification”
- Lemmens, Gupta (2020), “Managing Churn to Maximize Profits”
8 代码
您可以在这里找到原始的 Jupyter Notebook