字节跳动 VeOmni 框架开源:统一多模态训练效率飞跃!
资料来源:火山引擎-开发者社区
多模态时代的训练痛点,终于有了“特效药”
当大模型从单一语言向文本 + 图像 + 视频的多模态进化时,算法工程师们的训练流程却陷入了 “碎片化困境”:
- 当业务要同时迭代 DiT、LLM 与 VLM时,很难在一套代码里顺畅切换;
- 而当模型形态一旦变化,底层并行组合和显存调度往往需要大量手工改写,耗时耗力;
- DIT 模型蒸馏需要大量的资源消耗,但是缺少高效的训练 infra 支持来提升效率……
这些困扰行业的痛点,字节跳动的工程师们早就遇到了 —— 于是,VeOmni 应运而生。作为字节内部验证过的 “统一多模态训练框架”,它经过内部千卡级别真实训练任务检验,训练了 UI-Tars1.5 等重要模型,为了能将字节跳动核心 AI Infra 能力服务更多用户,字节跳动决定开源 VeOmni,火山引擎基于进一步上支持了视频模型训练等功能,让 VeOmni 支持了更多模型训练场景,可以更好地服务更多用户。
VeOmni 是什么?一套框架,搞定所有多模态训练
VeOmni 是字节 Seed 团队与火山机器学习平台、IaaS 异构计算团队联合研发的统一多模态模型训练框架,核心定位是三个统一:“统一多模态、统一并行策略、统一算力底座”。
它通过统一的 API 将 LoRA 轻量微调、FSDP、Ulysses 和 Expert Parallel 等多种混合并行策略以及自动并行搜索能力内置于框架内部。无论是百亿级语言模型、跨模态视觉语言模型,还是 480P/720P、长序列的文本到视频(T2V)或图像到视频(I2V)生成模型,开发者都能够基于统一的训练流程快速启动训练。
框架支持在千卡级 GPU 集群上自动完成权重张量的切分、通信拓扑的优化、动态显存回收和异步 checkpoint。在开源的 Wan 2.1 等模型上实测显示,相较于同类开源方案,VeOmni 能够将训练吞吐提高超过 40%,同时显著降低显存使用与跨节点通信带宽压力。
借助 VeOmni,字节跳动成功实现了“支持最快落地的新模型形态、最大化超大规模算力利用率、最小化业务改动成本”三大目标,有效弥补了开源社区训练框架在扩展性和抽象层面上的不足,为包括 LLM 和 VLM 在内的多模态生成场景提供了一条统一且高效的训练路径。
火山引擎的用户可在机器学习平台中运用 VeOmni 的强大功能。
五大核心优势,破解训练效率瓶颈
VeOmni 的 “高效” 不是口号,而是用技术细节堆出来的。我们拆解了多模态训练的核心痛点,给出了针对性解决方案:
显存计算双优化:用最少的额外计算,换最多的显存
传统 “大颗粒” 重计算要么全关、要么全开,往往用 10%–20% 的额外计算只换一点显存。VeOmni 不一样 —— 它先给每个前向张量算一笔 “ROI 账”:省 1MB 显存需要付出多少微秒计算。然后按 ROI 排序,只选性价比最高的算子重计算(比如 gate1_mul 省 40MB 只要 180μs,down_proj 要 4000μs,差距 22 倍!)。
VeOmni框架在训练启动前自动把 ROI 排序,同等显存收益只选择性价比最高的算子进入重计算池:例如 gate1_mul 和 down_proj 都可回收约 40 MB,但前者只需180µs、后者要 4000µs,差距达 22 倍。这样就能在保证显存不会超出的前提下,把额外计算开销压到最低。
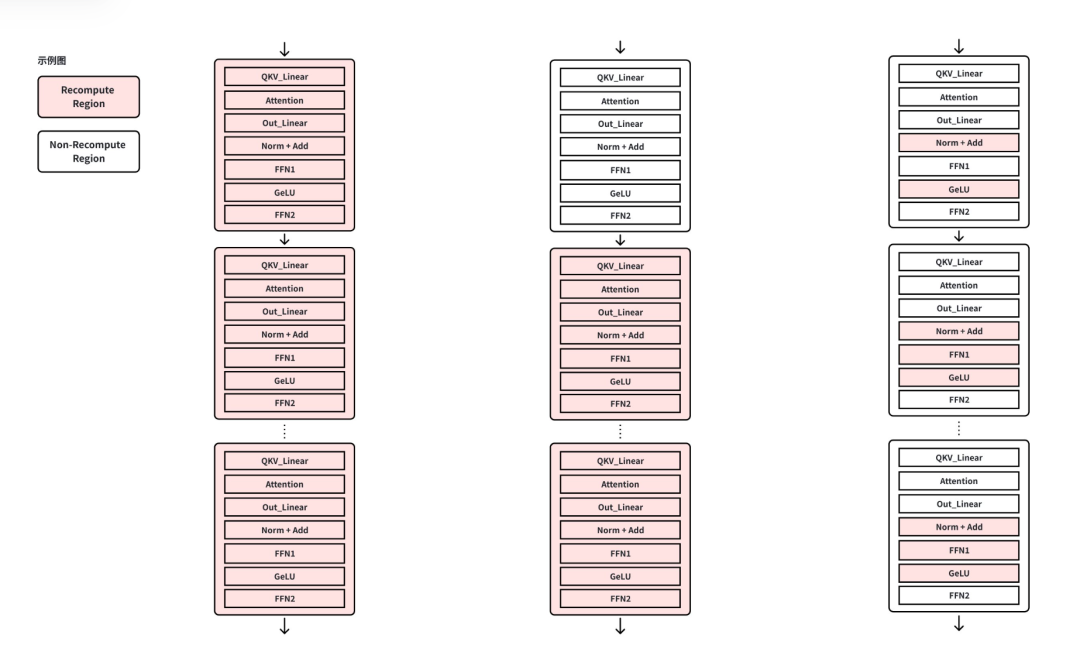
结果是:显存够用的前提下,额外计算开销压到最低。实测显示,相比按层重计算,VeOmni 的 Recompute 占比从 60% 降到 30%(Recompute 越低,效率越高),对 DiT 720P 视频训练、千亿 LLM 长序列训练效果显著。
混合并行 “组合拳”:一键匹配最优算力切分方案,显存峰值降 55%
VeOmni 内置多维并行体系,支持 FSDP、Ulysses 和 Expert Parallel (EP) 等多种并行原语,通过启动脚本可以一键进行笛卡尔组合,自动搜索最优的算力切分方案:
- FSDP 负责将参数、梯度和优化器状态切片到各个 GPU,突破显存瓶颈,横向扩批简单可靠;
- Ulysses Parallel 针对长序列任务,将注意力沿 head 维度拆解,有效缓解单卡显存压力;
- Expert Parallel 专门适用于 MoE 模型,可高效支持超大规模专家网络的训练。
这套并行体系已被应用于字节跳动内部多种模型的训练中,在处理 480P 和 720P 分辨率的 T2V/I2V 任务时,通过 FSDP 和 Ulysses 的组合,单轮迭代显存峰值可降低至原有基线的 45%。
算子级性能深挖:小核算子融合,访存次数降百倍
针对 DiT 中大量“小核算子”导致的访存抖动,VeOmni 把注意力-FFN-残差链路重写为单核 Kernel,长序列下显存碎片显著减少,访存次数下降数百倍。
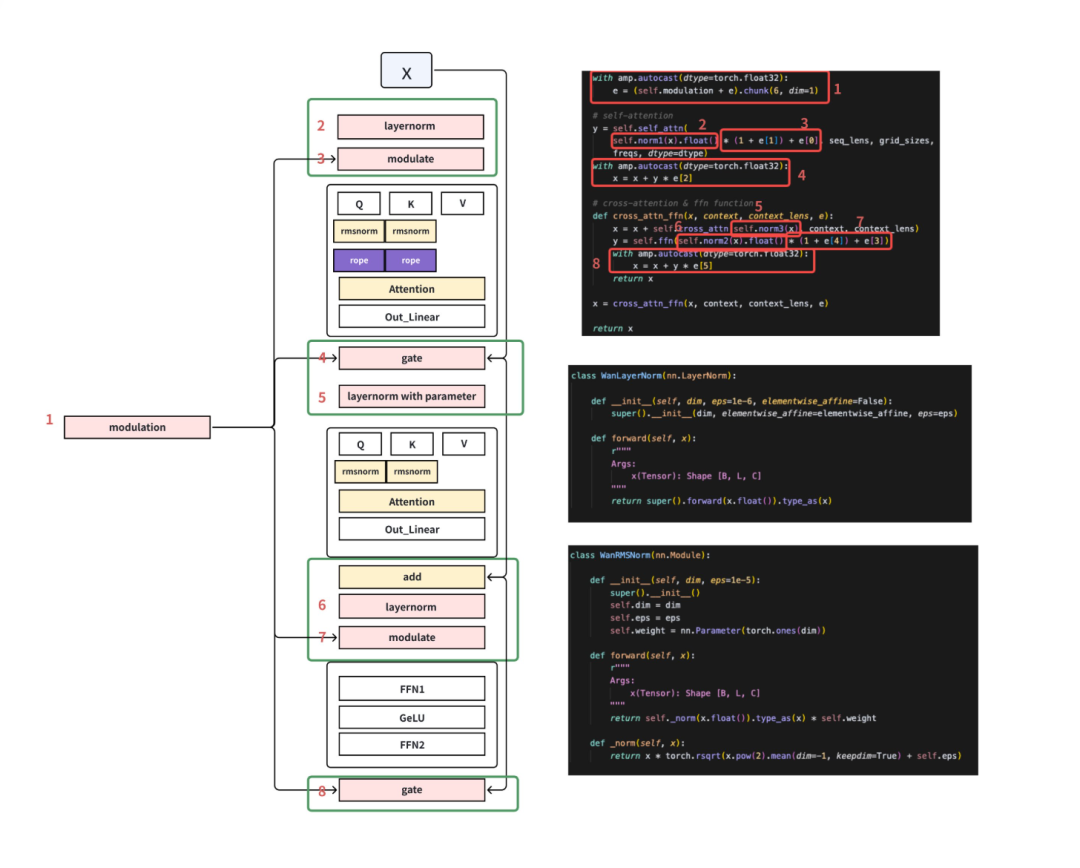
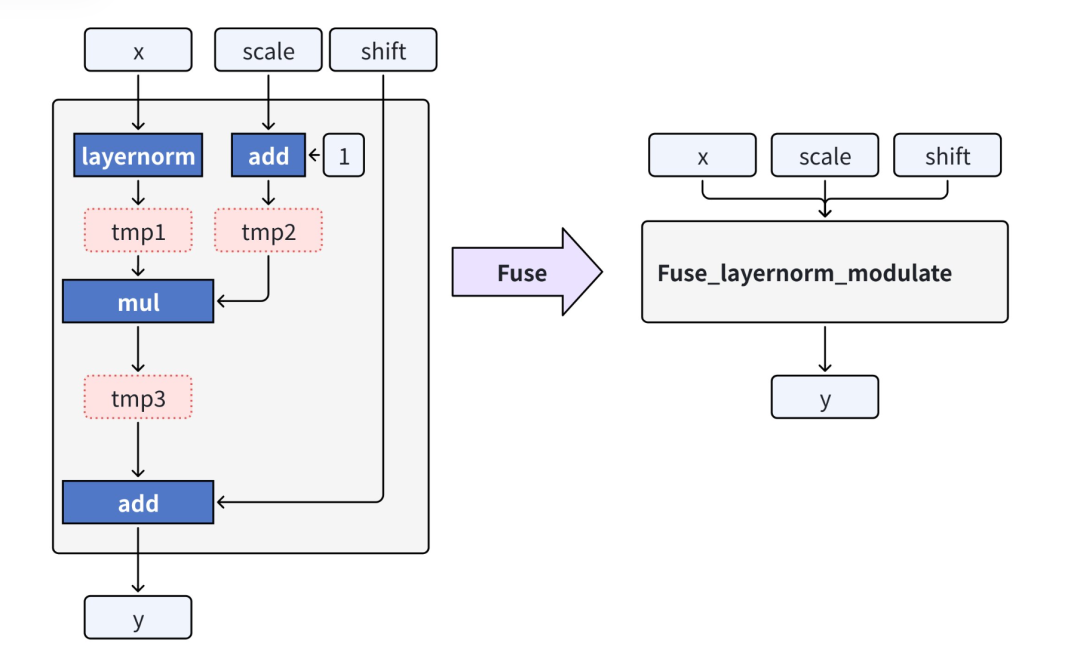
跨模型通吃:LLM/VLM/ 视频生成,一套框架全搞定
VeOmni 的优化不是 “针对性补丁”,而是对 生成式视频模型、千亿级语言模型 与 视觉语言模型 全部生效:
- DiT 训练显存减半;
- LLM 长上下文窗口训练从“手动调显存”变为“自动无感切分”;
- VLM 双塔/单塔架构在 Ring 模式下可线性扩展到更多 GPU,负载均衡无需改代码。
凭借“算子粒度重计算 + 混合并行 + 算子融合/升级”三大引擎,VeOmni 把原本困扰开源框架的扩展瓶颈彻底拆解,为字节跳动以及合作伙伴在多模态内容生成和大模型服务化道路上提供了即插即用、极致高效的算力底座。
蒸馏加速:减少推理步数,降低推理成本
在生成式模型的推理中,步数蒸馏是提升效率的关键一环。然而,蒸馏的训练周期极长,需要的计算资源也十分庞大。VeOmni 集成了轨迹蒸馏、分布匹配蒸馏(DMD)、自回归蒸馏等学界前沿方法,并将框架原生的训练加速能力(如显存优化、混合并行等)应用在蒸馏算法上,极大地减少了蒸馏的迭代周期和资源消耗。用户可通过启动脚本指定蒸馏目标:
- 支持 DMD 等效果优秀的蒸馏方法,能将模型稳定蒸馏至 4 步、8 步等目标步数甚至更少;
- 支持蒸馏掉 CFG(无分类器引导)以消除冗余计算;
- 支持用户自由编排蒸馏工作流,例如组合 “轨迹蒸馏预处理 + DMD 精调” 的多阶段蒸馏逻辑。
经由 VeOmni 蒸馏出的模型能够显著减少推理所需步数,同时保持生成结果的高质量,这对于降低计算成本、加速模型部署具有重要意义。
实测性能:比开源方案快 40%,多场景数据说话
VeOmni 的效率不是 “自说自话”,而是用真实模型测试验证的,以 Wan2.1-14B 模型为例(Lora 训练):
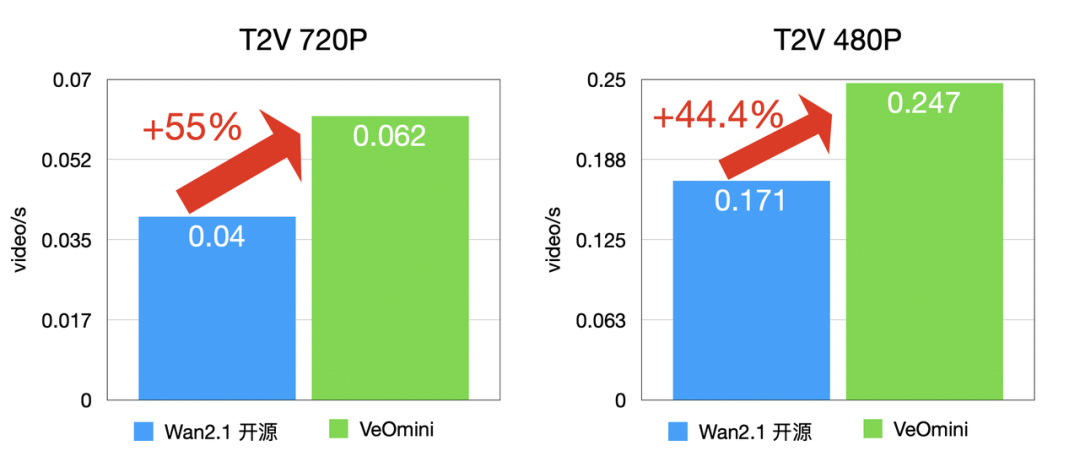
- 计算型大卡:I2V 720P 训练速度比开源方案快 48% 以上,T2V 720P 快 44.4% 以上;
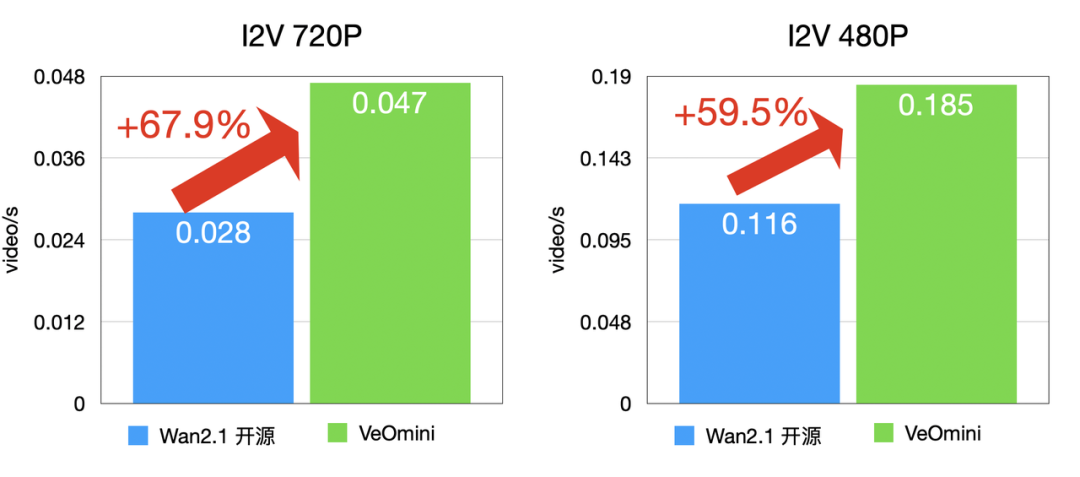
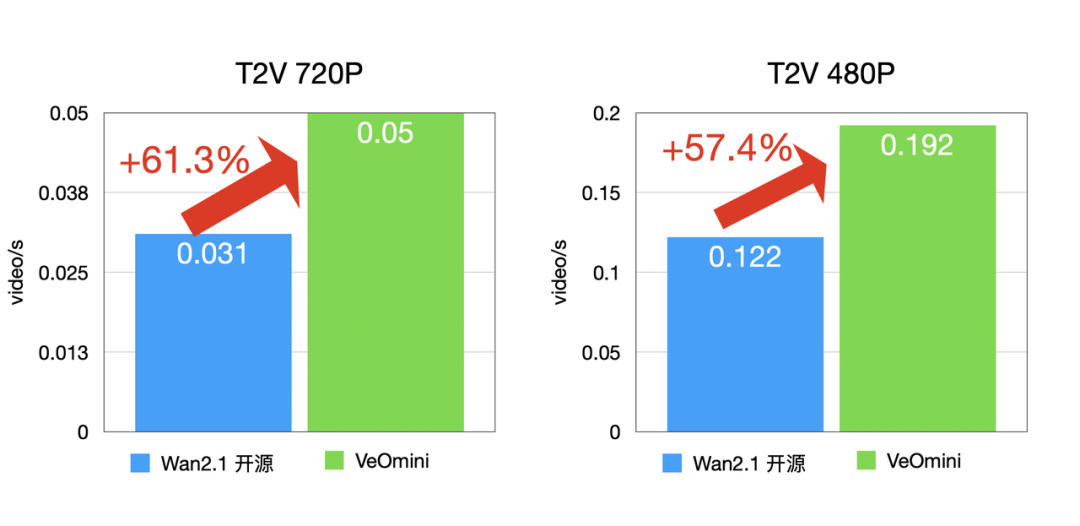
- 访存型大卡:I2V 720P 快 59.5% 以上,T2V 720P 快 57.4% 以上;
- 小参数量模型(Wan2.1-1.3B):T2V 480P 训练速度提升 51% 以上。
卡型 1(计算型大卡)
I2V 训练速度:
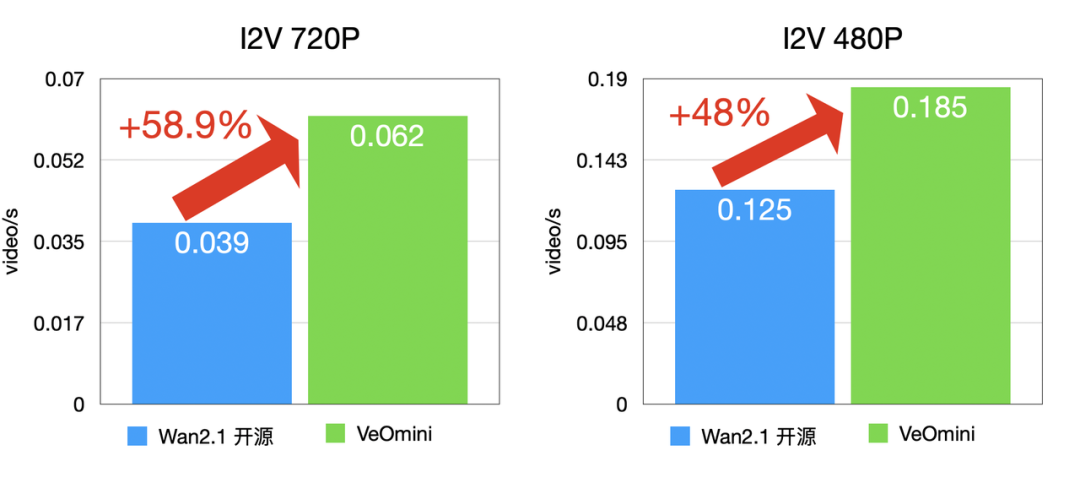
T2V 训练速度:
卡型 2(访存型大卡)
I2V 训练速度:
T2V 训练速度:
不管是大模型还是小模型,不管是计算型还是访存型硬件,VeOmni 都能让算力发挥到极致!
上手超简单:火山平台一键训练,性能分析可视化
VeOmni 不是 “专家专属工具”,而是开箱即用。目前,火山引擎在机器学习平台和 AI 云原生训练套件 TrainingKit 上都提供了 VeOmni 训练的最佳实践。下面我们以机器学习平台实践为例,介绍基于 VeOmni 训练框架对开源模型 Wan 进行 lora 训练,后续我们将推出基于 TrainingKit 的 VeOmni 部署实践。
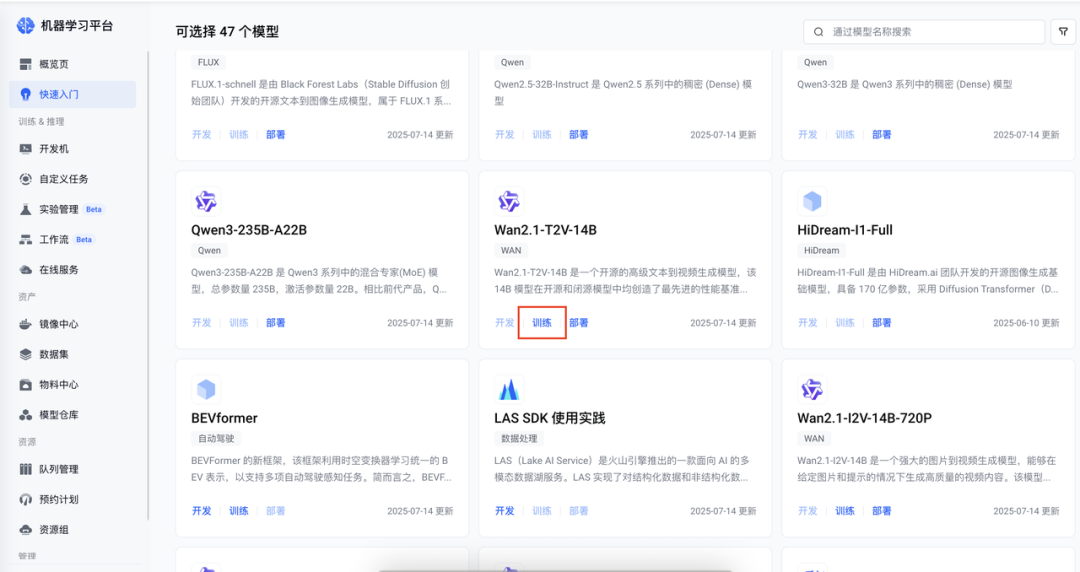
创建训练任务
在快速入门选择需要训练的模型,并且配置实例规格及模型输出路径。

查看训练任务详情
创建任务后可在「任务详情-日志」中查看训练详情。
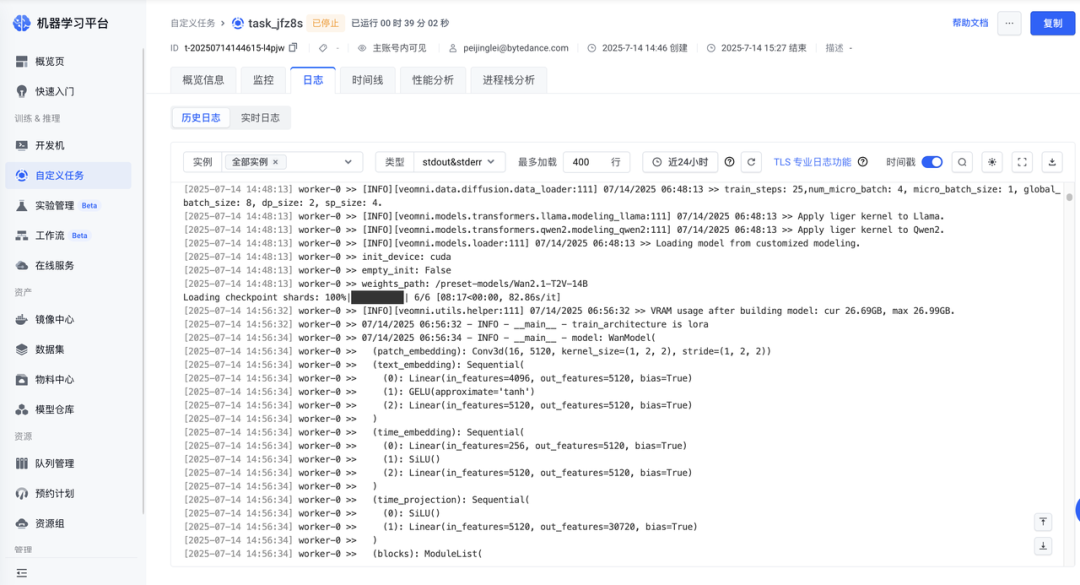
GPU 性能分析
1.导航到 自定义任务 > 任务详情 页面,在目标任务的管理页面单击 创建性能分析。
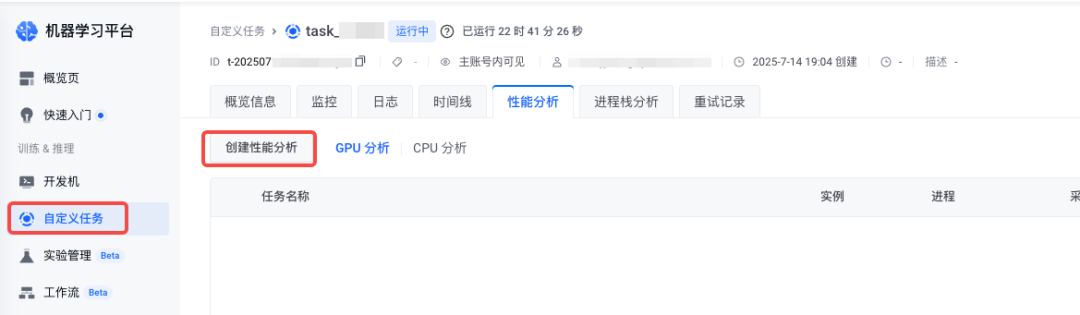
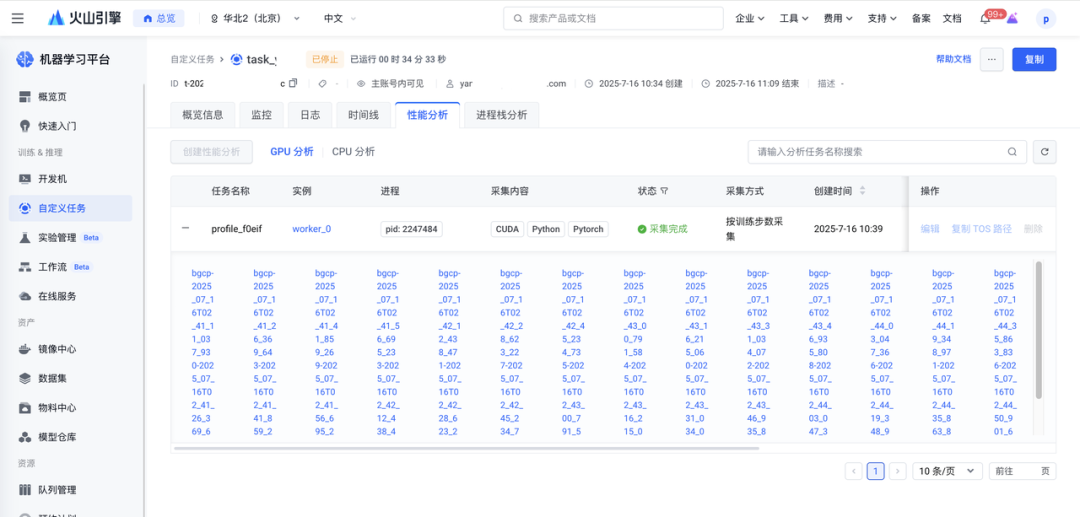
2.完成采集后,可在性能分析结果列表页面管理所有分析任务。点击「查看详情」将跳转至 perfetto 中展示性能分析火焰图。
每个 Worker 节点会根据其拥有的 GPU 数量或进程数生成多个进程文件。平台会将这些文件聚合成一个单一的结果文件,并根据 perfetto 的限制进行自动分片。
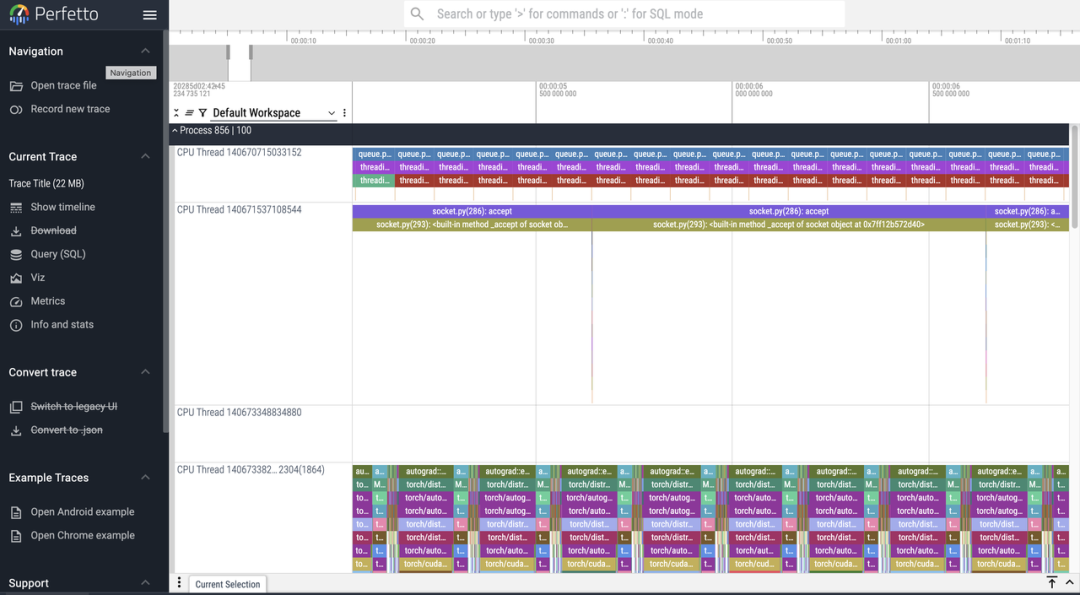
从训练到推理,全链路打通
目前火山引擎机器学习平台提供的数据集是用来训练飞天效果的 Lora 数据集,客户也可以自己选择合适的数据集进行预处理后来进行训练,具体使用方法随后更新。
获取输出结果
在一键训练的时候客户指定了训练的模型结果保存的地方,如下图所示。
- 输出模型结果保存文件路径类似下图
checkpoints/
├── global\_step\_xxx/ # 每次保存的权重快照
│ ├── extra\_state/ # 训练状态(按 rank 切分)
│ │ └── extra\_state\_rank\_*.pt
│ ├── hf\_ckpt/ # HuggingFace 兼容格式
│ │ ├── config.json
│ │ └── diffusion\_pytorch\_model.safetensors
│ ├── model/ # 模型参数分片
│ │ └── \_\_*\_*.distcp
│ └── optimizer/ # 优化器状态分片
│ └── \_\_*\_*.distcp
└── latest\_checkpointed\_iteration.txt # 记录最新步数 - 客户可以到 hf_ckpt下看到保存的 Lora 训练权重,得到的路径为 checkpoints/global_step_xxx/hf_ckpt/diffusion_pytorch_model.safetensors
使用脚本进行权重格式转换
- 将下列代码保存为 convert.py
#!/usr/bin/env python # convert.py —— 把 “blocks.…default.weight” → “diffusion\_model.blocks.…weight” from pathlib import Path
from safetensors.torch import load\_file, save\_file
import sys if len(sys.argv) != 2: sys.exit(f"用法: python {Path(\_\_file\_\_).name} <input.safetensors>") inp = Path(sys.argv[1]).expanduser().resolve()
out = inp.with\_name(inp.stem + "\_styleB.safetensors") tensors = load\_file(str(inp))
converted = {} for k, v in tensors.items(): # 若无前缀则加 diffusion\_model. ifnot k.startswith("diffusion\_model."): k = "diffusion\_model." + k # 去掉 .default. k = k.replace(".default.", ".") converted[k] = v save\_file(converted, str(out))
print(f"✓ 已保存: {out}")
- 执行下面的命令,得到转换后的权重
python convert.py
yourpath/checkpoints/global\_step\_xxx/hf\_ckpt/diffusion\_pytorch\_model.safetensors
使用 Vefuser 推理
训练完的模型,用火山 veFuser 推理更高效 ——veFuser 是火山引擎的扩散模型服务框架,针对 VeOmni 训练的 LoRA / 全量微调模型做了优化,能实现 “超低延迟” 视频生成。从训练到部署,全链路流畅!