【20-模型诊断调优】
偏差和方差
bias and variance
观察学习算法的偏差和方差,可以发现下一步如何调优
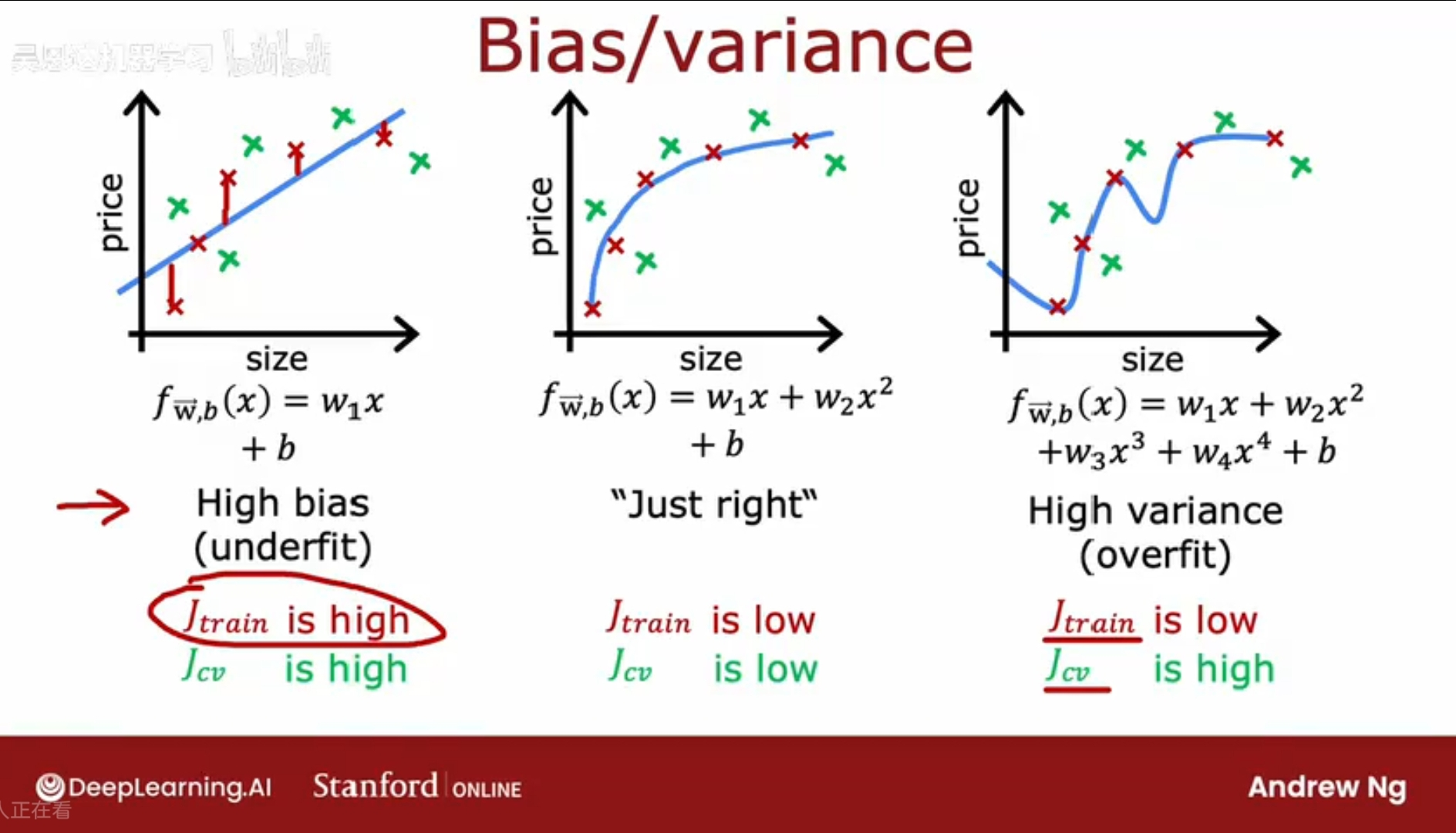
高偏差:欠拟合,训练集上误差太大;
高方差:过拟合,泛化能力太差;
当有更多特征(即更多维度)时,无法画图查看其拟合程度,是欠拟合/过拟合/刚刚好;
而更普遍和通用的方法是,查看模型在训练集和验证集上的表现;
Jtrain 和 Jcv 来体现,具体来说:
高偏差:Jtrain和Jcv都很高;
高方差:Jtrain 很低,Jcv很高;
刚刚好:Jrain较低,Jcv较低;
如何判断模型是高方差/高偏差
另一个视角:Jtrain Jcv如何随着多项式的阶数变化:
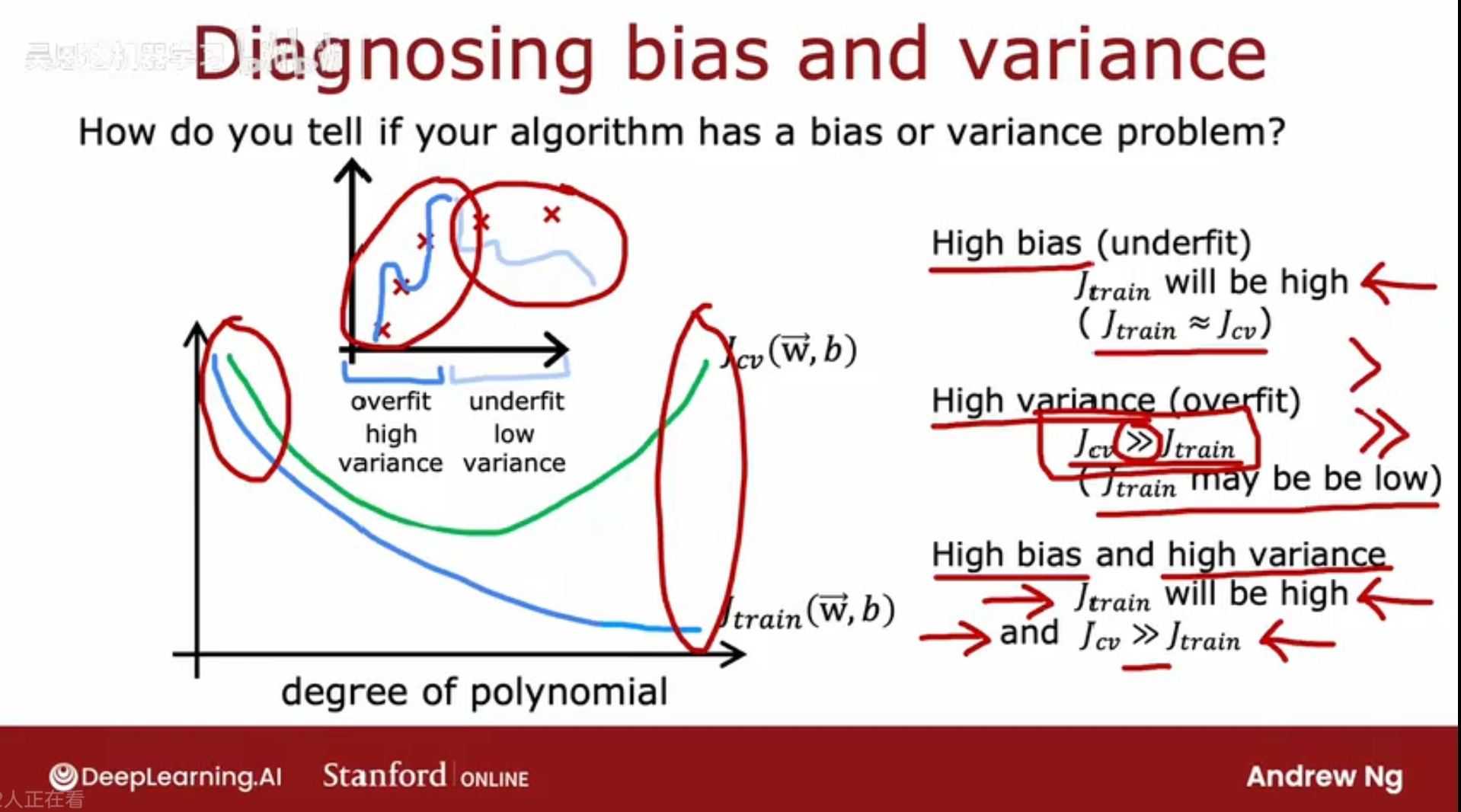
有时会同时出现高方差和高偏差(在线性回归中少见),Jtrain很高,但Jcv还远大于Jtrain(例如:对部分数据过拟合,对部分数据欠拟合)。
正则化参数lambda
前面说过,训练中的成本函数中的正则化项,是为了避免过拟合的问题,避免某一些特征过大地影响预测结果。
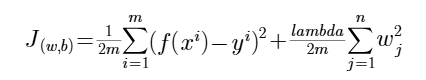
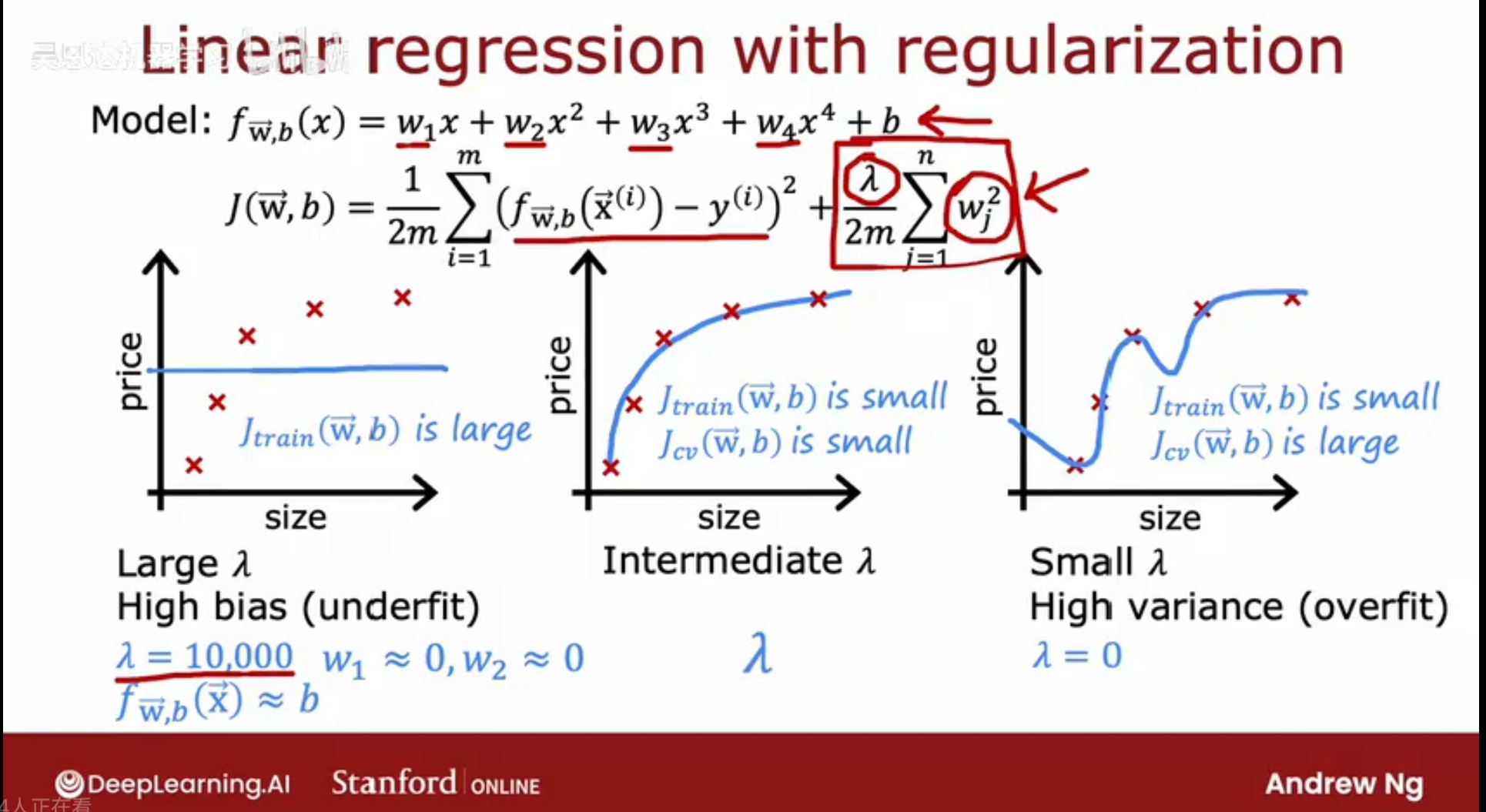
当lambda值选择过小比如0时,该正则化项消失,特征值对预测结果的影响过大,则容易产生过拟合;
当lambda值过大时,特征值的对预测结果的影响极小,容易产生欠拟合,即接近一条直线J(w,b) = b;
lambda的选择,要保证w较小的同时也要拟合好训练数据,在特征值对预测结果的影响上要做好平衡,以避免过拟合/欠拟合;
对于lambda的选择,交叉验证提供了一种方式:
尝试一组不同的lambda的值,然后最小化成本函数J,得到一组w,b,然后用交叉验证数据集cross-valid来查看拟合结果,最后选择一个Jcv最小的lambda的值;

查看误差值Jcv/Jtrain,随着lambda参数的大小如何变化,
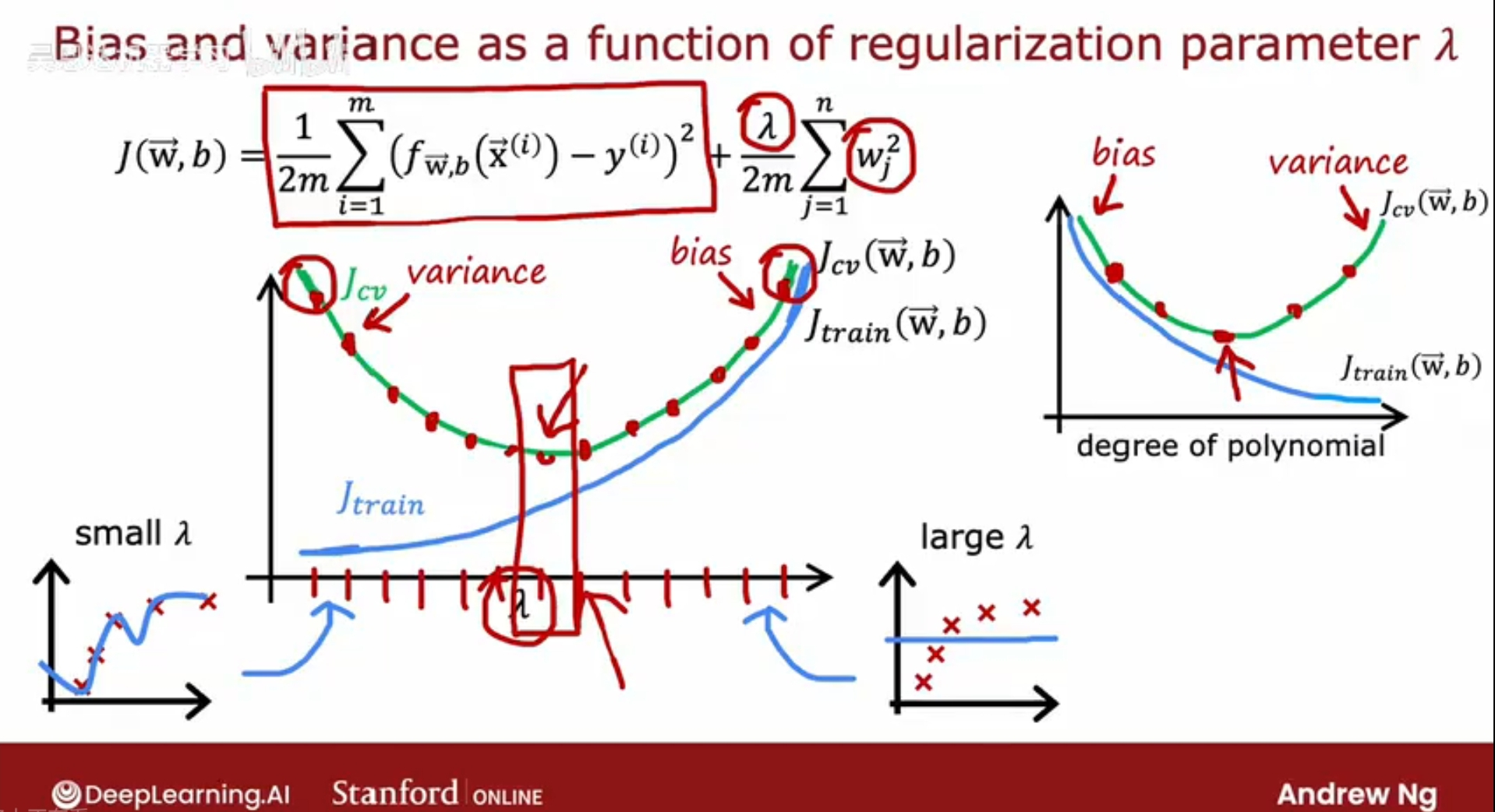
lambda越大,正则化项的权重越大,则特征值对结果的影响就越小,拟合程度就会越来越偏离训练数据,因此Jtrain会越来越大;
lambda很小时,处于过拟合状态,因此模型泛化能力差,Jcv就较大,随着lambda的增加,lambda逐渐走向合理取值,模型去除过拟合,则泛化能力增强,Jcv就变小,当lambda继续增大超出合理范围,则正则化权重过大,特征值影响过于小,模型偏离,此时根据特征值已不能较准确预测结果,泛化能力变差,这时Jcv继续增大;
如何判断Jtrain Jcv值的高低
建立性能的基线水准 baseline level – 基本标准
示例:语音识别
训练语音识别系统并测量训练误差,
训练误差:算法在训练集中的音频片段中没有正确识别转录的百分比,假设为10.8%(看起来相当高);
测量系统在验证集中的误差,即泛化误差,假设为14.8%(看起来更高);
但是需要根据另外一个指标,才能更好地说明这个模型的能力,它就是人类表现水平 Human level performance,即,人类识别这些音频片段的准确率有多少?
假设音频片段中可能存在杂音或其他干扰,人类错误率为10.6%;
这样来看,这个模型在训练集上表现的似乎已经很不错了。
所以,衡量模型的表现水平是要基于一个基线水准的,在上述例子中人类表现水平就是基线水准。
而验证误差14.8%比训练误差10.8%高出的4%,是远大于训练误差10.8%和基线水平10.6%的差值0.2%的,就可以认为是much higher,因此这样来看该模型是有着低偏差,但是高方差,可能是过拟合了。

判断训练误差是否较高,通常建立一个基线水平,即你所期望的算法的错误率为多少,通常是测量人类表现水平。
基线水平的建立:
1、人类表现水平;
2、竞品算法的表现水平;
3、通过经验猜测;
假设,基线误差10.6%,训练误差15.0%,验证误差15.5%,则属于高偏差问题;
结论:基线水平和训练误差的差值来判断是否是高偏差问题;训练误差和验证误差的差值来判断高方差问题;
假设:基线误差10.6%,训练误差15.0%,验证误差19.5%,则属于高偏差和高方差问题;
学习曲线——衡量学习算法表现
学习曲线-learning curve
可以帮助理解学习算法在不同数据量下的表现
随着训练集的大小的变化,训练误差Jtrain和验证误差Jcv有何变化。
Jtrain = training error; Jcv = cross validation error;
事实证明,随着训练集的增大,Jtrain逐渐变大,因为拟合的曲线不可能完美地通过每一个训练集的数据点(否则就可能是严重的过拟合),所以随着训练集的增大,未完美通过的数据点的数目会不断增加,因此会导致Jtrain变大。
注意,Jcv交叉验证误差通常会比Jtrain更高,因为它是泛化拓展得到的,而训练集是直接用来拟合模型的。
高偏差/欠拟合模型的学习曲线
训练误差曲线会随着数据量m的增加增大,但会逐渐变平,当获得越来越多的训练样本时,在拟合简单的线性函数时,模型实际上不会发生太大变化,即每增加一个训练数据点,它所带来的平均误差几乎是不变的,对于线性函数而言,增加数据点,其平均训练误差会越来越趋向于一个固定的值。
同样的,验证误差也会趋于一个固定的值。
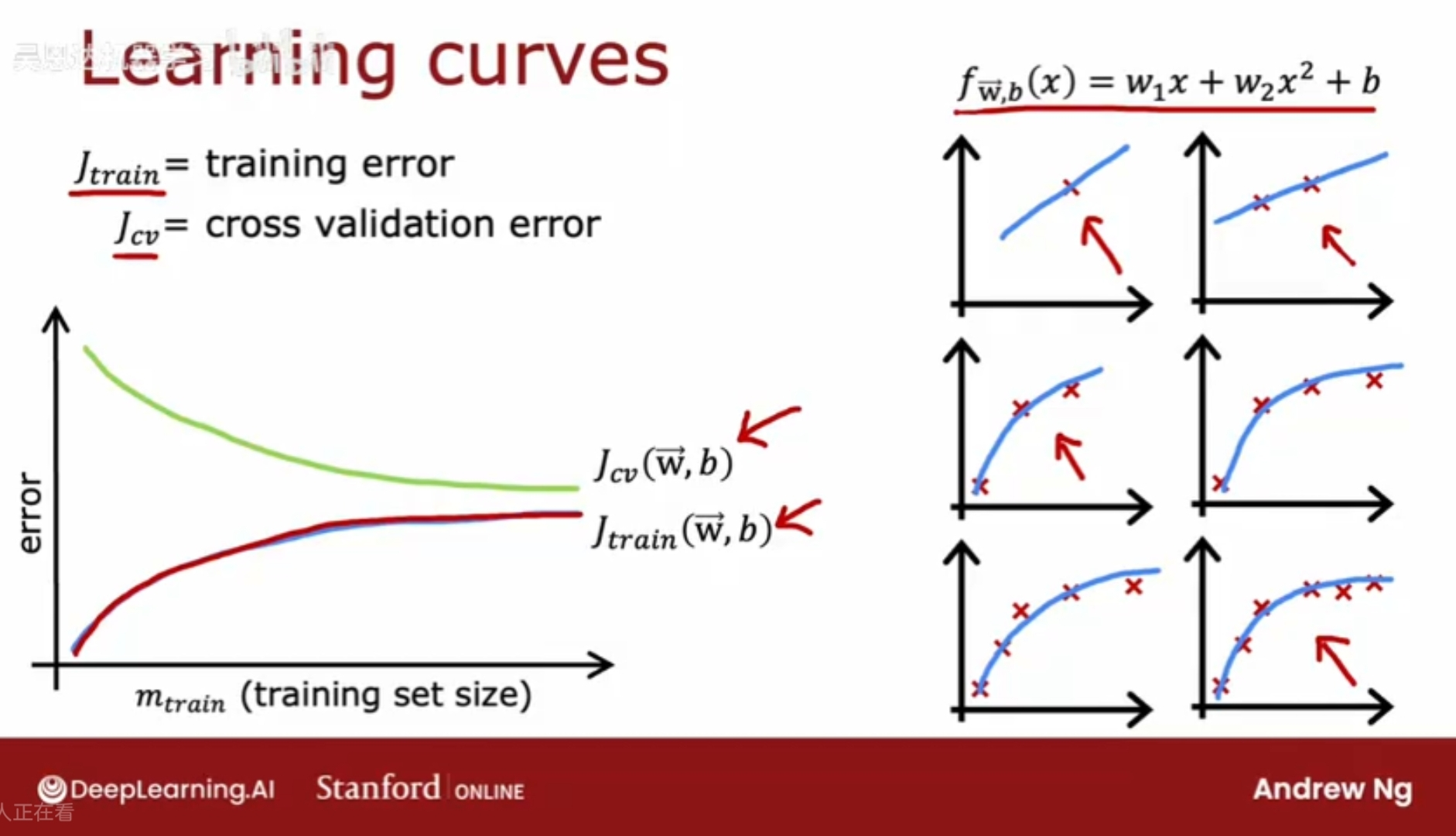
结论:如果一个模型本身具有高偏差,增加更多的训练集数据几乎不会对训练模型有帮助。
在投入大量数据到训练模型之前,要检查一下该模型是否有高偏差。
高方差/过拟合模型的学习曲线
在训练集上的表现远好于在验证集上的表现。
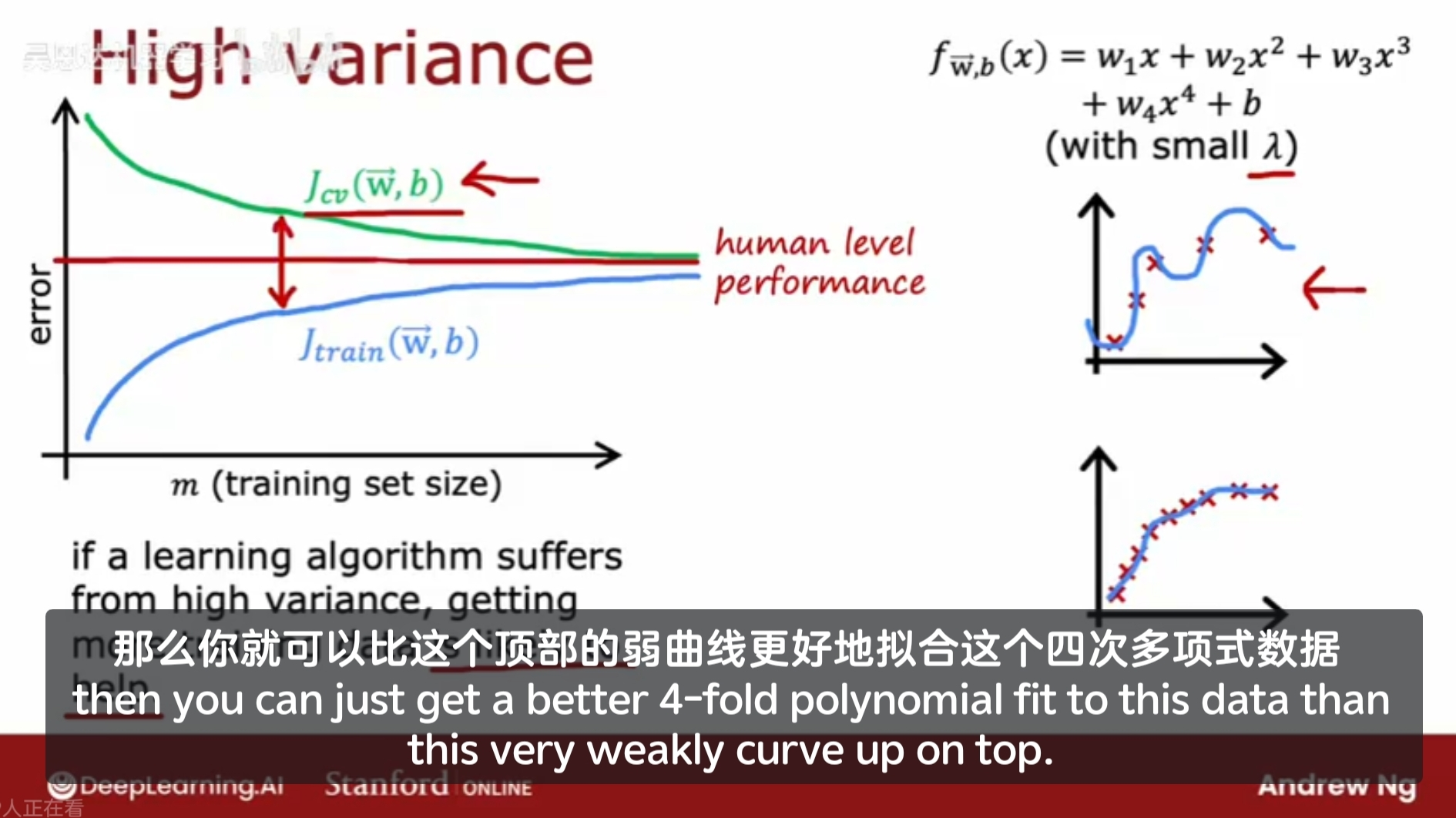
如果模型具有高方差,增加训练数据集有希望能提升模型的表现;
偏差和方差指导下一步
调试学习算法
1、获取更多训练集,解决高方差问题;
2、增加lambda,解决高方差问题;
3、减小lambda,解决高偏差问题;
4、更少的特征集,解决高方差问题;
5、更多的特征集,解决高偏差问题;
6、增加多项式特征,解决高偏差问题;
当特征集过多,会赋予算法过多的灵活性,去拟合非常复杂的模型;
当特征集过少,信息太少不足以去预测结果,模型过于简单,无法拟合好数据;

如果模型有高方差问题,解决方案主要是:
获取更多的训练数据;
简化模型:使用更少的特征集/增大正则化参数lambda;
如果模型有高偏差问题,则:
复杂化模型:获取更多的特征集/增加多项式特征/减小正则化参数lambda;
偏差/方差权衡;试图去评价模型是高偏差还是高方差,但实际上可能会复杂一些;
偏差/方差在神经网络训练中的作用
模型太简单会有高偏差,模型太复杂会有高方差;
在高偏差和高方差之间存在一个平衡点,如何做好方差和偏差之间的权衡;选择合适的多项式的阶数或正则化参数lambda;使得方差和偏差都不太高;

事实证明,神经网络提供了一种方法,可以摆脱偏差和方差之间进行权衡的困境。
神经网络,在小到中等大小的数据集上进行训练时,是低偏差的机器;
如果神经网络足够大,几乎总是可以很好地拟合训练集(除非训练集特别大);
步骤:
1、模型在训练集上是否表现良好?若不好,则有高偏差,可以使用更大的神经网络(更多的隐藏层或神经元);
2、模型在验证集上是否表现良好?若有高方差,去获取更多训练数据,重新训练模型,检查训练误差,若不好则重复步骤1。
不断循环步骤1和2,直到Jtrain 和 Jcv都比较低;
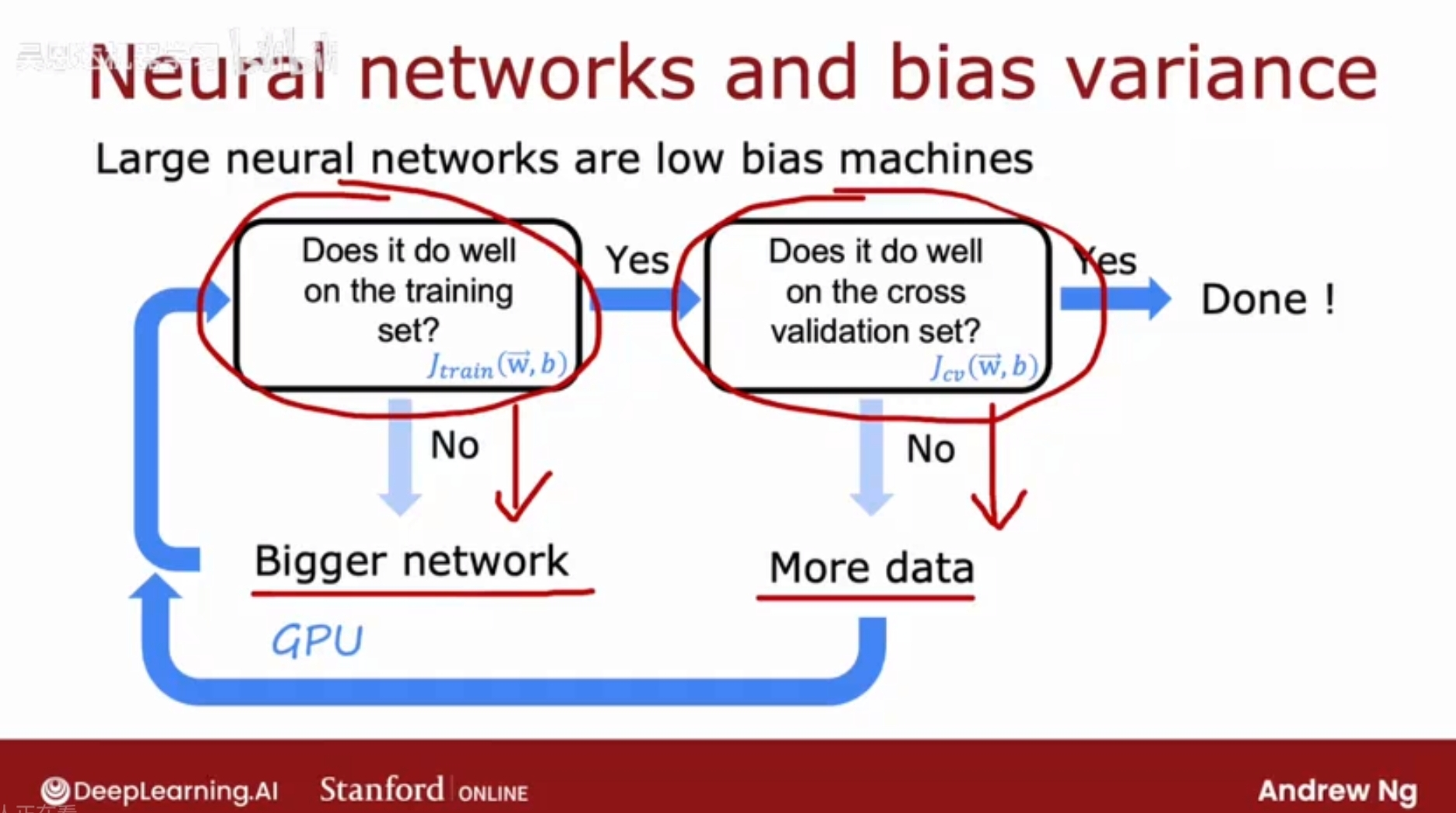
缺点1:训练更大的神经网络确实可以减少偏差,但是计算成本会越来越高,即便有GPU的加持,到了一定程度,计算成本依然十分昂贵;
缺点2:无法无限获取更多的训练集数据,它们往往是有限的。
ps: 神经网络的兴起和能够进行快速计算处理的计算机硬件出现相关,特别是GPU(graphics processor units)的发展,加速了神经网络的计算;
神经网络太大怎么办?会导致高方差吗?
事实证明,经过适当的正则化,大的神经网络可以表现地和较小的一样伸直更好,只要正则化适当。主要的影响是较大的神经网络会减慢训练和推理过程。
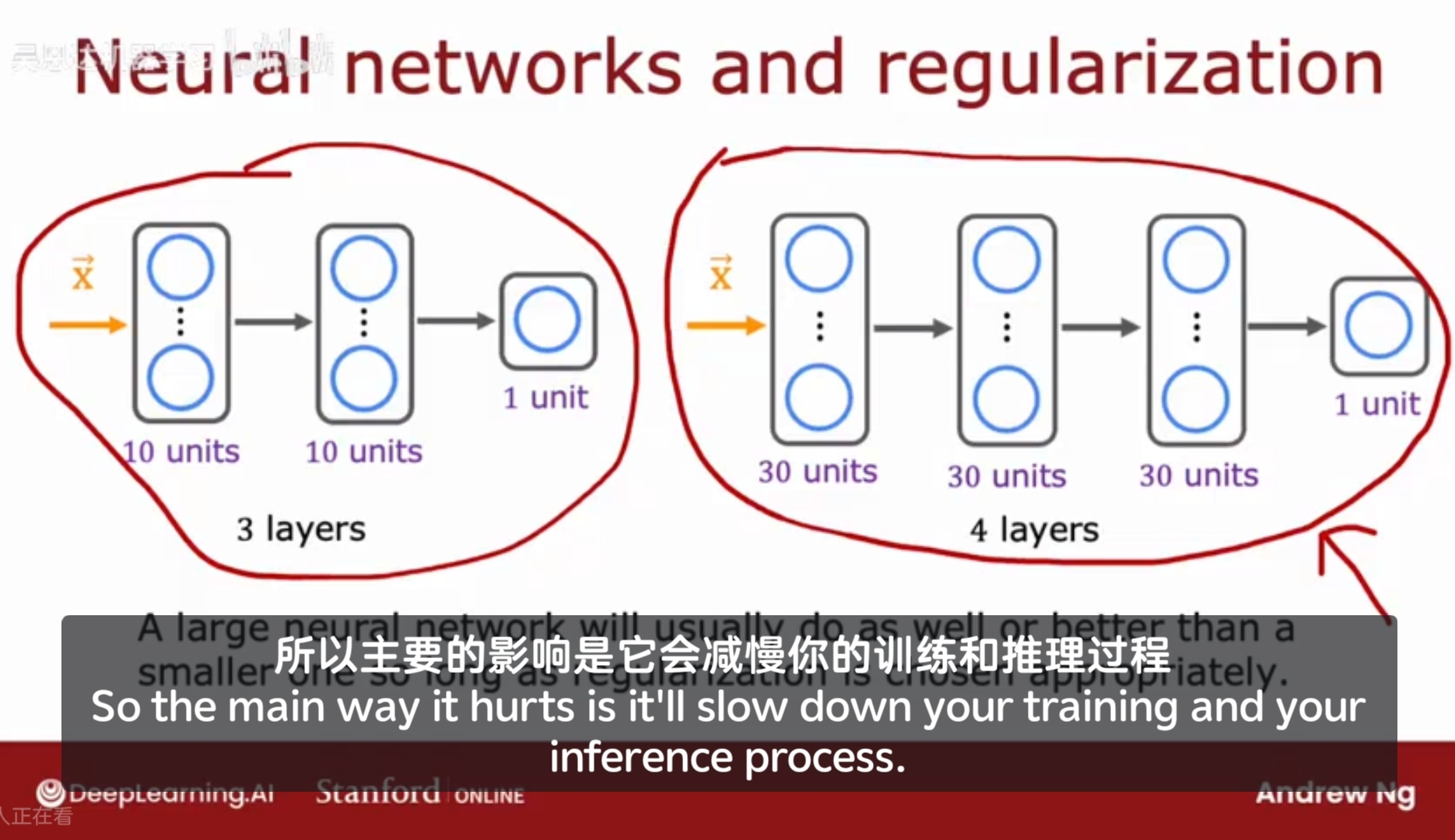
结论:
1、只要适当的正则化,更大的神经网络几乎不会有坏处;计算和推理变慢;但性能通常更好;
2、只要训练集不是太大,大的神经网络通常是一个低偏差的模型,非常适合拟合复杂函数,通常是处理高方差的问题;
正则化:

在开发机器学习系统中的应用
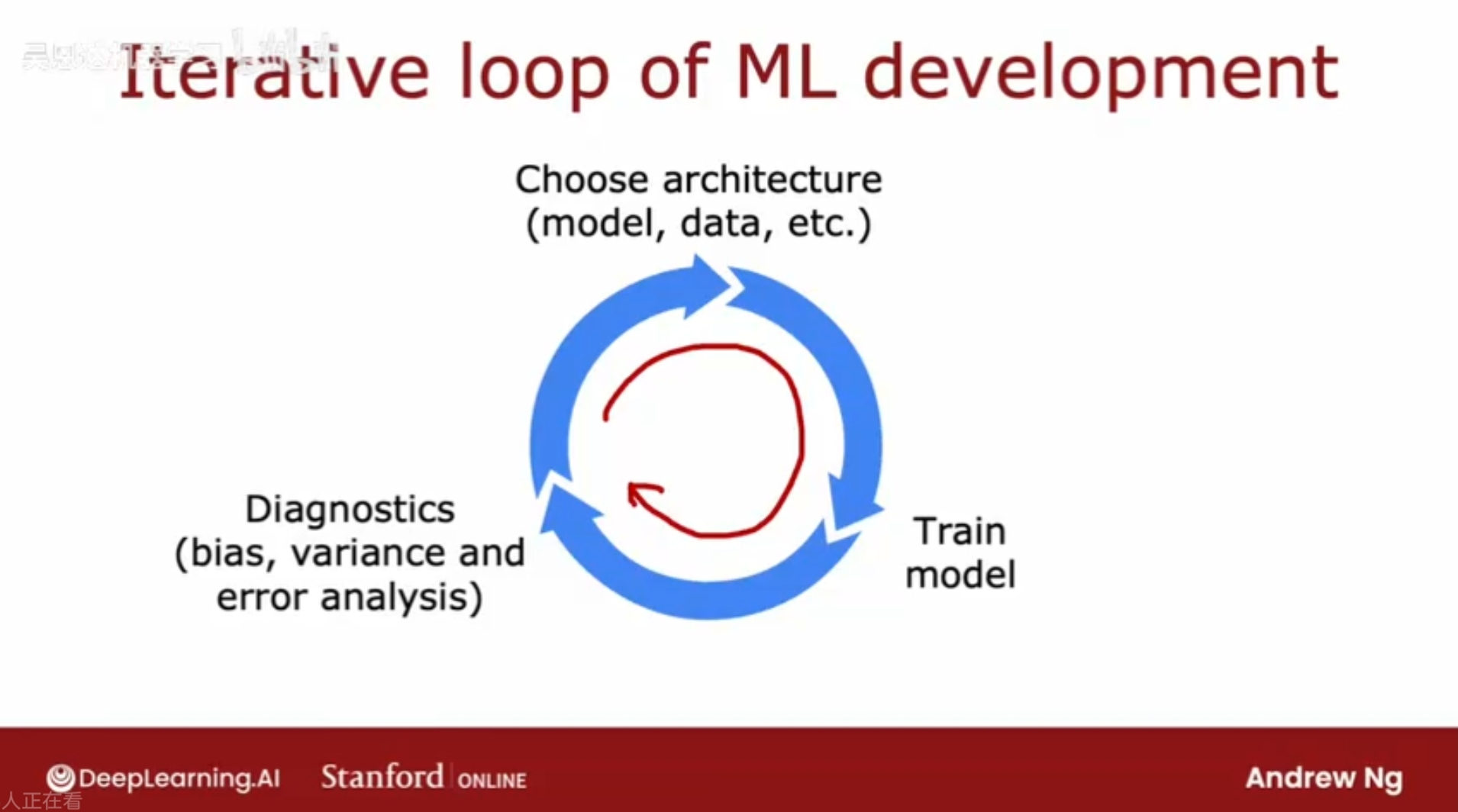
机器学习系统的开发过程
选择架构/模型 - 训练模型 - 诊断调优(高方差高偏差) - 调整模型 - 训练模型 - 诊断调优 - - 调整模型 - 训练模型 - 诊断调优 …
垃圾邮件分类识别;
构建邮件的特征x,输出是否为垃圾邮件y;
构建邮件特征的方法:
取某字典中前10000个单词,用它们来定义特征矢量x: x1,x2,…,x10000;
然后根据这些词出现与否,将这些特征值设置为0/1,另外一种方法:对某个单词出现的次数计数;

给出一些训练集数据,有了输入和输出,就可以用来训练神经网络模型;
更复杂的特征:电子邮件路由分析;文本中提取出的其他特征;
选择使用什么方法,即提取什么样的特征用来区分垃圾邮件,对其后续具体的训练是十分重要的;
错误分析的过程
错误分析-选择模型架构的思想之二(区别于用偏差和方差来选择);
模型选择考虑的因素:
1、偏差-方差
2、错误分析;
例如:在交叉验证集中有500组数据;算法的预测结果中,100个被错误分类,错误分析是指,手动检查这100个例子,尝试发现算法哪里搞错了;
找到预测错误的例子,基于普遍的特征来将他们分类,例如分类后:推销药的 - 21,故意拼写错误的单词(w4tch) - 3,异常邮件路由-7,钓鱼邮件或窃取密码 - 18,嵌入图片的 - 5,其他等;
这些分类可能并不是互斥的,是互相覆盖的。
具体方案:对于推销药品,可以找到几个特征来描述这些邮件/特定的药品名称;对钓鱼邮件,检查url生成额外特征/收集更多钓鱼邮件的数据;
通过手动检查一组算法错误分类的示例,可以帮助下一步来优化调整算法;
总的来说,如何减少垃圾邮件分类错误:
1、收集更多数据(基于偏差和方差)
2、构建新特征,更复杂的特征;
添加数据的技巧(高方差时)
在神经网络中,总是希望数据越多越好,希望能获取到不同类型的数据,而通过错误分析,可以更有针对性地寻找特定特征的数据,以能较明显地提高模型的能力;
数据增强
除了获取全新的训练集数据XY,有一种技术,数据增强 data augmentation,拿一条现有的训练数据来创建一个新的训练样本,尤其对于图片和音频数据,可以显著增加其数据集;
例如,用OCR optical character recognition 光学字符识别,可以通过对图片做 旋转/放大/缩小/网格扭曲/改变对比度 来创建新的训练数据,这样的额外示例有助于算法更好地识别图像;
对于音频数据,可以对音频做 增加噪音/变速/转为录音效果/间断 等;
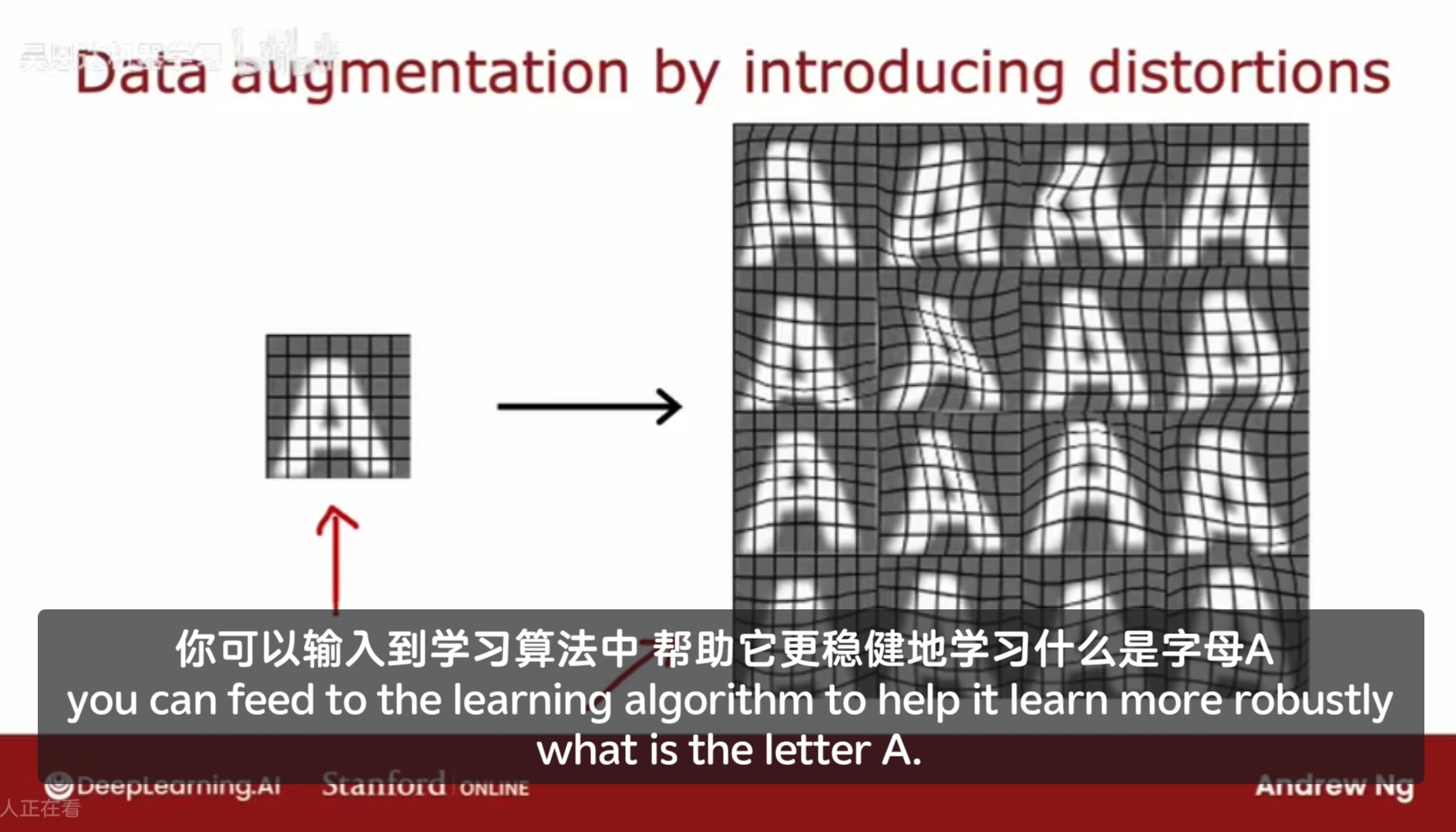
需要注意的是,你对图片/音频做出的处理,代表了你预期在测试集中期望可能遇到的数据内容;
对于添加随机的无意义的噪音,通常没有太大帮助。通过更改数据,使其在测试集中的内容相似,这样的表现才会好,
数据合成
从零开始创建/编造数据,以OCR算法为例,可以用文本编辑器写一些文本(用不同的字体、颜色等),然后截图,就造出了数据;
合成数据生成大多用于计算机视觉,很少用于其他应用场景。
小结
机器学习系统/AI系统 = Code(algorithm/model) + Data; 得益于这种机器学习研究范式,线性回归、逻辑回归、神经网络、决策树等模型,在很多场景下的表现已经很不错,因此注重数据驱动时,反而更有成效,即着重在数据的工程处理上;
迁移学习-机器学习发展过程
Transfer learning: 使得模型能够使用来自不同任务的数据;
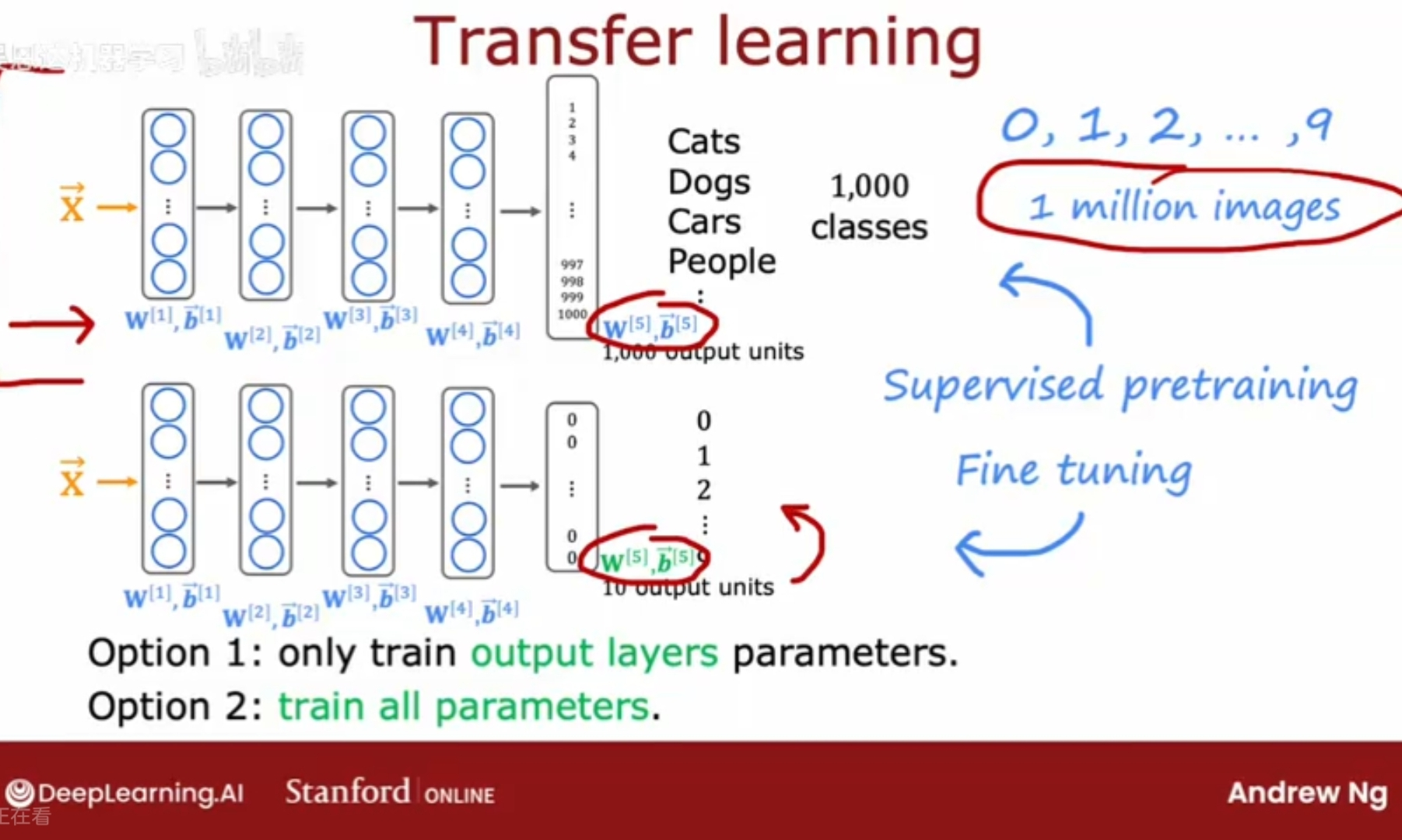
例子:现在需要训练一个数字识别的模型,但手头没有足够多的手写数字图片的数据;假设现在有一个包含了猫、狗、人、汽车等一共1000个类别的100万张照片的数据集,可以先通过这一百万张照片数据集训练一个神经网络,训练算法通过输入的图像来识别其类别,最终能训练出各层的各参数矢量w,b;复制这个神经网络,保留参数w,b(除了最后的输出层的),然后将输出层替换为0-9的十个类别,最后一层的参数w,b需要重新训练得到,在迁移学习transfer learning中,将除了输出层的其他各层的w,b作为参数的起点,然后运行优化算法(如梯度下降/Adam优化),具体来说,有两个方法来训练神经网络的参数:
只训练输出层的参数,其他层的w,b参数保持不变;(适合非常小的数据集)
训练所有的参数,所有层的w,b都更新;(适合稍大的数据集)
这个算法被称为迁移学习,因为在直觉上通过学习猫、狗、车、人等,有希望为前几层处理图像输入的学习到一些合理的参数集,通过将这些参数转移到新的神经网络,而新的神经网络在开始时参数处于更优的位置,因此只要稍加学习,就很有希望得到一个相当好的模型。
先在大数据集上做训练,然后在较小的数据集上进一步调整参数(tuning parameters);
这两个步骤中的在大数据集上训练的第一步叫做有监督预训练supervised pre-training,第二步在小数据集上进一步调整参数叫做微调fine tuning;
即便你只有几百几千张图片,小的数据集,也能能够从这百万张不相关的任务图片中学习,实际上可以帮助你的学习算法提升很多。
好处:不需要亲自监督预训练,对于许多神经网络,已有研究人员在大型数据集上用大量图片训练了神经网络,并且开源发布在网上;即,你可以下载别人训练好的神经网络,即第一步有监督预训练已有做好了的,只需要替换输出层,并进行微调。
迁移学习的原理
为什么迁移学习能够起到作用呢?对于完全不同的任务数据;
如从图像中识别不同的物体,在神经网络的不同层,担任了不同的处理任务,第一层检测边缘,第二层检测角,第三层校测曲线/基本形状,训练一个神经网络取检测分类猫狗等事物,实际上是训练它检测一些通用的图像特征,如发现边缘,角点,曲线,基本形状,这些对于其他许多计算机视觉任务都是有用的;
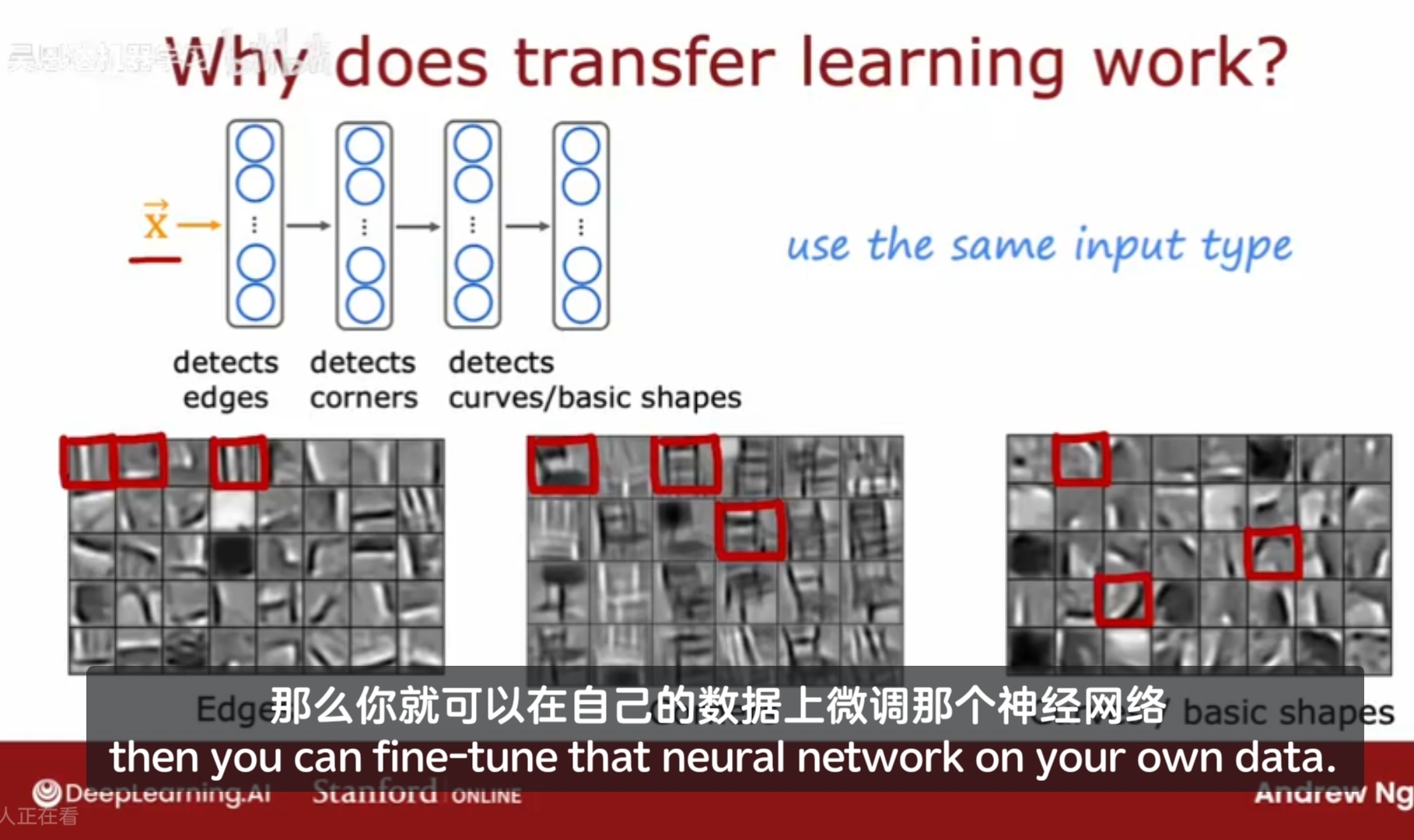
预训练的限制:对于预训练和微调步骤的图像类型X必须是相同的;
如果任务是计算机视觉任务,那么预训练也必须是一个在相同类型输入上训练的神经网络,即期望维度的图像;
如果是音频识别,那么在图像上训练的神经网络对音频几乎没有帮助,就需要用大量音频来预训练;文本任务就用大量文本来预训练;
迁移学习Transfer learning的两个步骤

1、预训练,往往是从网上下载别人已用海量数据训练过的模型;
2、微调,用自己的数据;
GPT-3 BERT ImageNet
迁移学习:是机器学习社区的一种交互共享方式,开放共享;
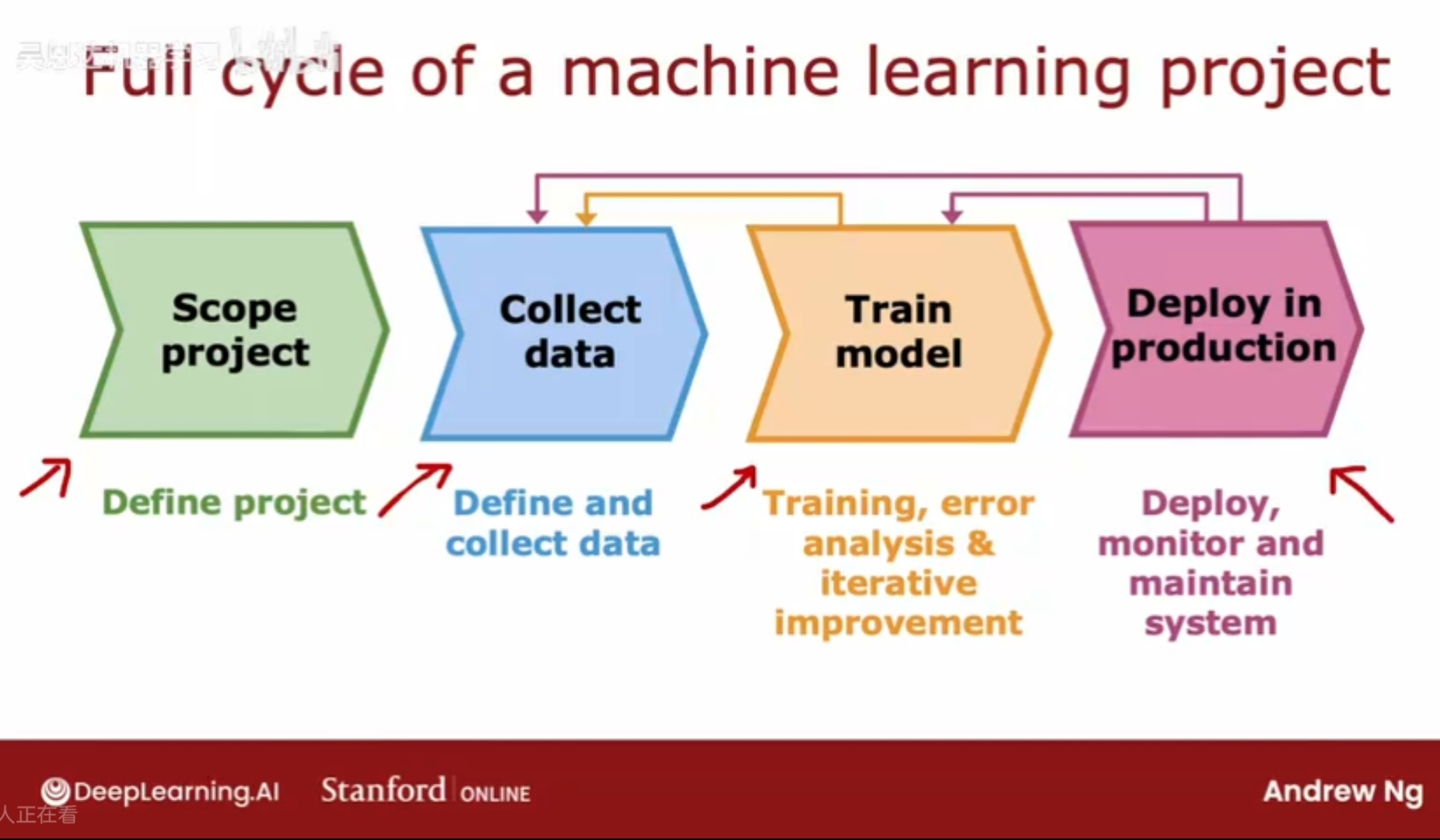
机器学习项目完整周期
如何构建一个可用的机器学习项目
确定项目范围 - 如语音识别;
定义和收集数据;
训练模型 - 误差分析/偏差方差分析 - 返回收集特定数据 - 循环迭代;
部署到生产环境 - 部署,监控性能,维护功能;
常见的部署方式:将机器学习模型放在服务器上,并且运行起来,用户的app执行api调用;
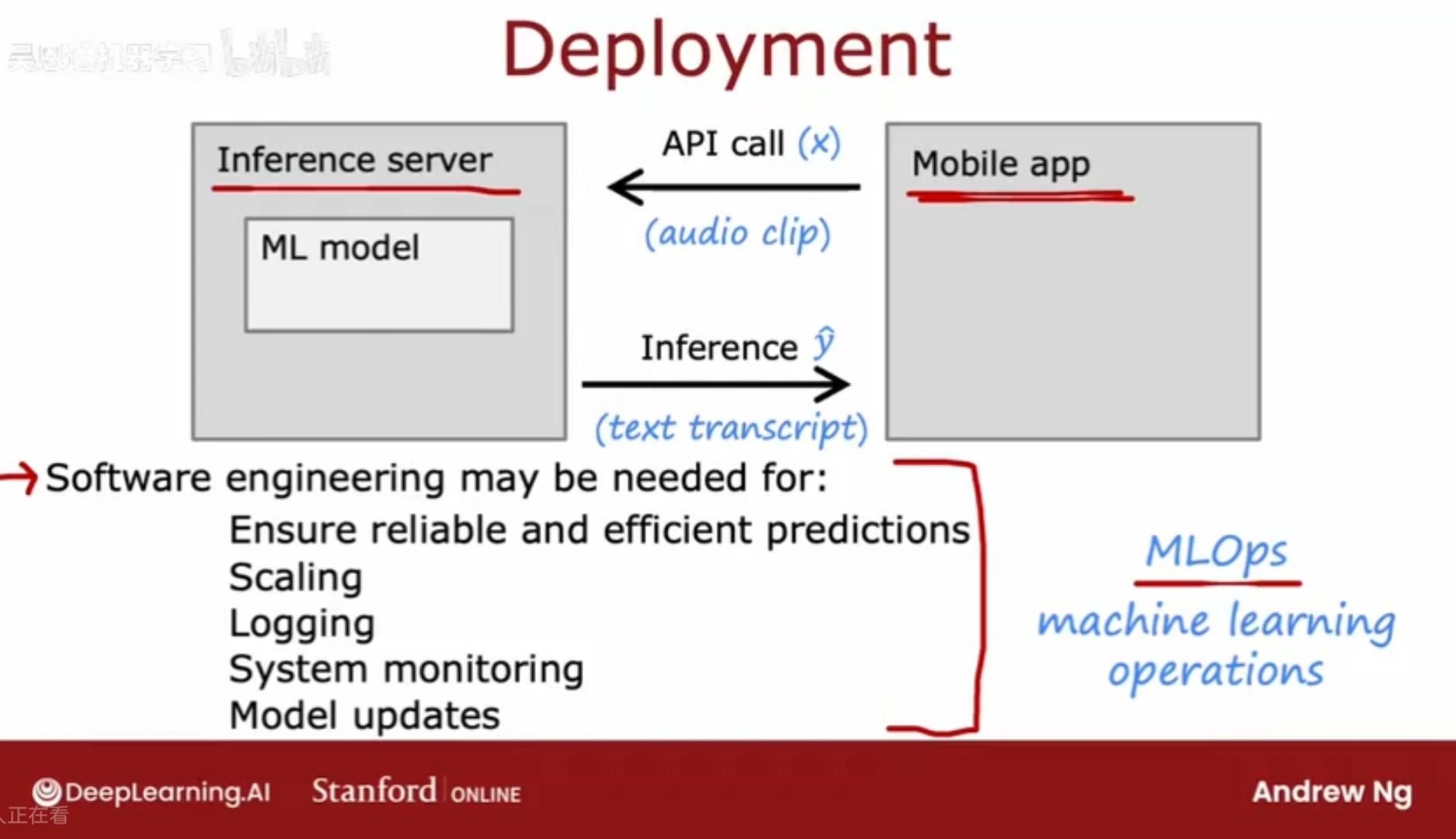
MLOps: mechine learning operations 机器学习操作;
指如何系统构建、部署和维护机器学习系统的实践,以便做到监控、日志、维护、更新知识,确保模型可靠。