MySQL进阶——优化、日志
· 优化
1.插入数据
- 批量插入(括号里是按照字段顺序一一对应的值)
insert into table values(col1,col2),(col1,col2);
- 手动开启事务(因为InnoDB默认自动提交事务,每条插入都会独立提交)
start transaction;
insert into table values (...); ……
commit;
- 主键按顺序添加,建议使用auto_increment,不建议使用UUID(无序插入)作为主键
- 大批量导入数据时,建议用“--local-infile”(客户端支持直接从文件导入,不然insert into插入得很慢)
# 客户端连接服务端时,加上参数--local-infile
mysql --local-infile -u root -p
# 设置全局参数local_infile为1,开启从本地加载文件导入数据的开关
set global local_infile = 1;
# 执行load指令将准备好的数据,加载到表结构中
load data local infile '/root/文件名' into table 表名 fields
terminated by ',' lines terminated by '\n';
2.主键优化
- 尽量简短一些
- 主键要按顺序添加,建议使用auto_increment
- 尽量不要使用 UUID 做主键或者是其他自然主键,如身份证号
- 业务操作时,避免对主键的修改
3.order by排序优化(尽量用索引)
- Using filesort:全表扫描——就是不用索引的排序
通过表的索引或全表扫描,读取满足条件的数据行,然后在排序缓冲区sortbuffer中完成排序操作,所有不是通过索引直接返回排序结果的排序都叫FileSort排序。
- Using index:索引排序——建立索引时,默认会进行排序。 给需要排序的列添加单列或联合索引(多列索引)。
注意:
1)多列索引的排序要符合“最左前缀原则”,必须从第一列开始匹配;
2)在使用索引排序时,不要用”select * from ……”,因为*会导致索引失效,变为全文扫描;
3)想一升一降的排序,可以在创建索引时,字段排序的顺序要和order by的升序降序方向一致,如果方向相反,索引就失效了
eg:如果你需要 order by age asc, phone desc(年龄升序,电话降序),索引要这么建:create index idx_age_phone on student(age asc, phone desc)(和排序方向一致),这样才能用上索引。
4.group by分组优化(尽量用索引)
Using temporary:使用临时表来分组,效率低
Using index:使用索引分组
注意:
1.select 应该只出现索引有的字段(如果要查的字段不在索引里,那只能查全表)
2.符合 “最左前缀”原则,可以先用where筛选再group by分组
5.limit分页优化(尽量用索引)
分页查询时用“先通过索引定位目标主键,再关联查询完整数据”
- 通用场景(适合任意分页,包括跳页)
select 表名.字段名 from 表名 inner join (
select 主键字段 from 表名
order by 排序有索引的字段 [asc/desc]
limit 偏移量, 每页条数 -- 偏移量 = (页码-1)*每页条数
) on 表名.主键字段 = 子查询表名.主键字段;
(2)连续分页场景(例如不支持直接跳页,仅适合 “下一页”,效率更高)
select 字段 from 表名
where 排序有索引的字段 > 上一页最后一条数据的排序值
order by 排序字段 [asc/desc]
limit 每页条数;
举例(表名user,上一页最后id=100000,取下一页 10 条):
select *
from user
where id > 100000 -- 以上一页最后一个id为起点
order by id
limit 10; -- 取10条
说明:
·两种格式都依赖 “排序字段有索引”(如主键id或其他索引字段),否则无法优化。
·通用场景中,子查询.主键字段 即子查询里select的主键(如示例中的id),直接和表的主键关联即可。
·连续分页场景需记录 “上一页最后一条数据的排序值”(如最后一个id),作为下一页的查询条件。
6.count优化(尽量用索引)
Count( )的作用是统计满足条件的行数
count(*) ≈ count(1) > count(主键) > count(字段)
用法 | 逻辑 |
count(*) | 直接统计所有行数,MySQL对count(*)有特殊优化,直接返回表的行数(不管是不是null)速度最快 |
count(1) | 统计所有行数,1是“非null常量”,无需判断,直接计数(InnoDB优化后效率高) |
count(主键) | 统计“主键非null”的行数(主键必非null),利用主键索引扫描,无需判断null |
count(字段) | 统计“字段非null”的行数,需逐行判断字段是否为null,若字段无索引,需全表扫描 |
7.update优化(尽量用索引)
若要更新的列有索引,则是行锁,快速定位;没有索引,则是全表扫描+表锁
·update的where条件尽量用有索引的字段(比如主键、唯一索引),避免全表扫描和表锁。
EXPLAIN
用法:在select前加上explain,会返回一个结果集,展示查询执行的详细计划。
最核心的10个字段详解:
列名 | 含义 | 解释 |
id | 查询序号 | 查询中操作执行的顺序标识,值越大越先执行,值相同则按顺序执行(特殊情况如union可能有相同值) |
select _type | 查询类型 | 描述查询的性质(如simple、primary、subquery、union等) |
table | 当前操作的表 | 显示操作涉及的表名(派生表可能显示为<derivedN>,N对应id值) |
type | 访问类型 | 表示数据库如何访问表中的数据,从差到好:ALL(全表扫描)<index(索引全扫描)<range(索引范围查询)<ref(索引等值查询)<eq_ref(唯一索引匹配)<const(常量匹配,通过唯一索引精确匹配一条记录)<system(系统表,极少见)) |
possible _keys | 可能使用的索引 | 理论上可能用到的索引,如果该列为NULL则表示没有可用索引 |
key | 实际使用的索引 | 实际查询时用到的索引,若为NULL,说明未使用索引(可能是possible_keys中的索引未生效,或优化器认为全表扫描更快)。 |
key_len | 索引的有效长度 | 使用的索引长度(字节数),可判断索引是否完全利用 |
ref | 索引匹配列或常量 | 显示与索引比较的列或常量(如const、关联表的列名等) |
rows | 行数 | MySQL估计需要检查的行数(估计值,行数越少性能越好) |
Extra | 额外信息 | 额外执行信息(如Using index覆盖索引、Using where需要在结果集里再筛选条件、Using filesort需临时文件排序、Using temporary需临时表存储中间结果等) |
· 日志
·MySQL 日志是记录 MySQL 数据库运行过程中各种操作和事件的文件,对于数据库的管理、维护、故障排查、性能优化等都起着至关重要的作用。
·MySQL的日志体系可分为服务器层日志(适用于所有存储引擎)和存储引擎层日志(如InnoDB特有)
日志类型
日志类型 | 所属层级 | 核心作用 | 适用场景 |
错误日志(Error Log) | 服务器层 | 记录服务启动/运行/关闭的异常信息 | 排查服务启动失败、崩溃等问题 |
查询日志(General Log) | 服务器层 | 记录所有客户端的连接及SQL操作 | 临时调试(如追踪异常SQL来源) |
慢查询日志(Slow Query Log) | 服务器层 | 记录执行时间超过阈值的SQL | 性能优化(定位低效查询) |
二进制日志(Binary Log) | 服务器层 | 记录数据变更操作 | 主从复制、数据恢复 |
中继日志(Relay Log) | 服务器层(从库) | 存储主库同步的二进制日志,供从库执行 | 主从复制场景 |
重做日志(Redo Log) | InnoDB引擎 | 记录数据页修改,保障事务持久性 | 崩溃恢复、事务提交 |
回滚日志(Undo Log) | InnoDB引擎 | 记录事务前数据状态,支持回滚和MVCC | 事务回滚、读写不阻塞 |
1、错误日志(Error Log)
·记录MySQL服务异常,用于解决服务器故障。
作用:1)排查启动失败、连接问题、磁盘空间不足等服务器故障
2)服务启动/关闭的详细信息
3)严重错误(如权限不足、内存溢出、表损坏)
4)警告信息(如配置参数不推荐使用)
·配置方法:默认强制启用,仅需配置存储路径
·日志路径:
步骤1、修改配置文件
# linux系统修改配置文件:
vim /etc/my.cnf 或 vim /etc/mysql/my.cnf
# windows系统修改配置文件:
D:\MySQL\my.ini
# 添加修改参数
############
[mysqld]
log-error = /var/log/mysql/mysql-error.log # Linux路径示例
# log-error = "C:/ProgramData/MySQL/MySQL Server 8.0/data/mysql-error.log" # Windows路径示例
#############
步骤2、重启服务生效
# 重启服务生效
systemctl restart mysqld
# 动态查看配置(无需重启):
SHOW VARIABLES LIKE 'log_error'; -- 查看错误日志路径
# 查看与分析——错误日志为文本格式,可直接用文本工具查看:
## 查看最新10行错误日志
tail -n 10 /var/log/mysql/mysql-error.log
## 搜索关键词(如"error")
grep -i "error" /var/log/mysql/mysql-error.log
# 查看自定义路径
show variables like 'log_error';
# 自定义路径
log_error = /var/log/mysql/error.log
# 日志详细级别(0-3,默认2)
log_error_verbosity = 3
常见错误场景:
·启动失败:检查端口占用(Port 3306 is already in use)、权限不足(Permission denied)
·崩溃日志:搜索mysqld got signal 11(段错误),通常与内存或引擎异常相关
=========================================================
日志轮转:通过 logrotate(Linux)定期切割日志,避免单个文件过大:
# 创建logrotate配置(/etc/logrotate.d/mysql-error)
vim /etc/logrotate.d/mysql-error
############
/var/log/mysql/mysql-error.log {
daily # 每天轮转
rotate 7 # 保留7天日志
compress # 压缩旧日志
missingok # 日志不存在时不报错
postrotate # 轮转后重启服务(可选)
systemctl restart mysqld > /dev/null 2>&1
endscript
}
############
# 权限设置:确保日志文件属主为mysql用户
chown mysql:mysql /var/log/mysql/*
2、通用查询日志(General Log)
作用:记录所有客户端的连接行为(连接/断开)及执行的所有SQL语句(包括select、insert等),可用于追踪异常操作(如误删数据)。
注意事项
·默认关闭(因高并发场景下会产生大量IO,严重影响性能)。
·仅建议在临时调试时开启(如定位某条SQL的执行来源),调试完成后立即关闭。
1、永久启用:在配置文件中添加 general_log = ON
# 配置文件修改
vim /etc/my.cnf
##########
[mysqld]
general_log = ON # 开启查询日志
general_log_file = /var/log/mysql/mysql-general.log #日志路径
##########
# 重启生效
systemctl restart mysqld
# 查看当前状态
SHOW VARIABLES LIKE 'general_log';
SHOW VARIABLES LIKE 'general_log_file';
# 实时查看日志
tail -f /var/log/mysql/mysql-general.log
2、临时启用:动态开启,无需重启,临时生效
# 临时启用,重启失效
set global general_log = ON;
# 自定义日志文件
set global general_log_file = '/var/log/mysql/general.log';
# 动态关闭
set global general_log = OFF;
注意:生产环境中慎用,因会产生大量日志,影响性能。
用途:审计 SQL 执行(如误操作追踪),开发/测试环境调试。
3、慢查询日志(Slow Query Log)
·作用:记录执行时间超过阈值(默认10秒)的SQL语句,是性能优化的核心工具,可快速定位低效查询(如未加索引、全表扫描的SQL)。
·配置方法
1、永久生效
# 修改配置文件
vim /etc/my.cnf
##########
[mysqld]
slow_query_log = ON
slow_query_log_file = /var/log/mysql/mysql-slow.log
long_query_time = 1 #阈值设为1秒(根据业务调整)
log_queries_not_using_indexes = ON #记录未用索引的查询
log_slow_admin_statements = ON #记录慢管理语句
##########
2、临时生效
# 开启慢查询日志
set global slow_query_log = on;
# 修改阈值为0.5秒
set global long_query_time = 0.5;
# 开启未用索引记录
set global log_queries_not_using_indexes = on;
3、使用专业工具(mysqldumpslow(MySQL自带))分析:
# 按时间排序,取前10条最慢查询
mysqldumpslow -s t -t 10 slow.log
# 查看平均时间最长的10条慢查询
mysqldumpslow -s t -t 10 /var/log/mysql/mysql-slow.log
4、专业工具pt-query-digest(Percona Toolkit,推荐)
# 安装(CentOS示例)
yum install percona-toolkit -y
# 分析慢查询日志并生成报告
pt-query-digest /var/log/mysql/mysql-slow.log > slow_analysis.report
·管理策略:
①阈值调整:根据业务场景设置合理的long_query_time(如OLTP系统建议0.1-1秒)。
②日志轮转:同错误日志,使用logrotate定期切割,避免文件过大。
③定期分析:结合业务低峰期(如凌晨)运行pt-query-digest,输出优化清单。
4、二进制日志(Binary Log)
·作用:记录所有数据变更操作(如INSERT/UPDATE/DELETE、CREATE/DROP等),不记录纯查询(SELECT)。
·核心用途:
主从复制:主库通过binlog将变更同步到从库,保证数据一致性。
数据恢复:通过回放binlog中指定时间段的操作,恢复误删/误改的数据。
·配置文件
vim /etc/my.cnf
###############
[mysqld]
log_bin = /var/log/mysql/mysql-bin # 开启binlog
binlog_format = row #记录行级变更(避免主从数据不一致)
expire_logs_days = 7 #7天后自动删除旧日志
max_binlog_size = 500M #单个文件最大500MB
server-id = 1 #主从架构中必须设置唯一ID(主库1,从库2,3...)
###############
# 重启服务生效
systemctl restart mysqld
·关键操作:
# 查看binlog列表:
# 列出所有binlog文件及大小
show binary logs;
# 查看当前正在写入的binlog:
show master status;
l 查看binlog内容(需用mysqlbinlog工具):
# 查看指定binlog的文本格式内容(包含时间、SQL操作)
mysqlbinlog --base64-output=decode-rows -v /var/log/mysql/mysql-bin.000001
# 按时间筛选(如2025-08-14 08:00到09:00的操作)
mysqlbinlog --start-datetime="2025-08-14 08:00:00" --stop-datetime="2025-08-14 09:00:00" /var/log/mysql/mysql-bin.000001
l 手动删除binlog(谨慎操作):
-- 删除指定文件之前的所有binlog(保留mysql-bin.000005及之后)
PURGE BINARY LOGS TO 'mysql-bin.000005';
-- 删除3天前的binlog
PURGE BINARY LOGS BEFORE DATE_SUB(NOW(), INTERVAL 3 DAY);
l 数据恢复实战
假设误删了users表的数据,可通过binlog恢复:
1.找到误操作时间点(如2025-08-14 10:30)。
2.确定对应binlog文件(通过SHOW BINARY LOGS和时间匹配)。
3.提取误操作前的SQL并回放:
# 导出2025-08-14 10:20到10:30(误操作前)的操作
mysqlbinlog --start-datetime="2025-08-14 10:20:00" --stop-datetime="2025-08-14 10:30:00" /var/log/mysql/mysql-bin.000001 > recover.sql
# 执行恢复SQL(注意先备份当前数据)
mysql -u root -p < recover.sql
5、中继日志(Relay Log)
·作用:仅存在于从库,是主从复制的"中间载体":
从库的IO线程读取主库binlog,写入本地中继日志。
从库的SQL线程读取中继日志,执行其中的SQL操作,实现数据同步。
·配置管理
# 默认路径:
从库数据目录(如/var/lib/mysql/),文件名格式为host-relay-bin.xxxxxx。
# 核心参数:
# 配置文件
##############
[mysqld]
relay_log = /var/lib/mysql/relay-bin #自定义中继日志路径
relay_log_purge = ON #自动清理已执行的中继日志(默认开启,避免占用空间)
relay_log_recovery = ON #从库崩溃后重启时,自动重新同步主库binlog(推荐开启)
##############
·查看中继日志状态:
show slave status\G #查看中继日志相关信息(如Relay_Log_File、Relay_Log_Pos)
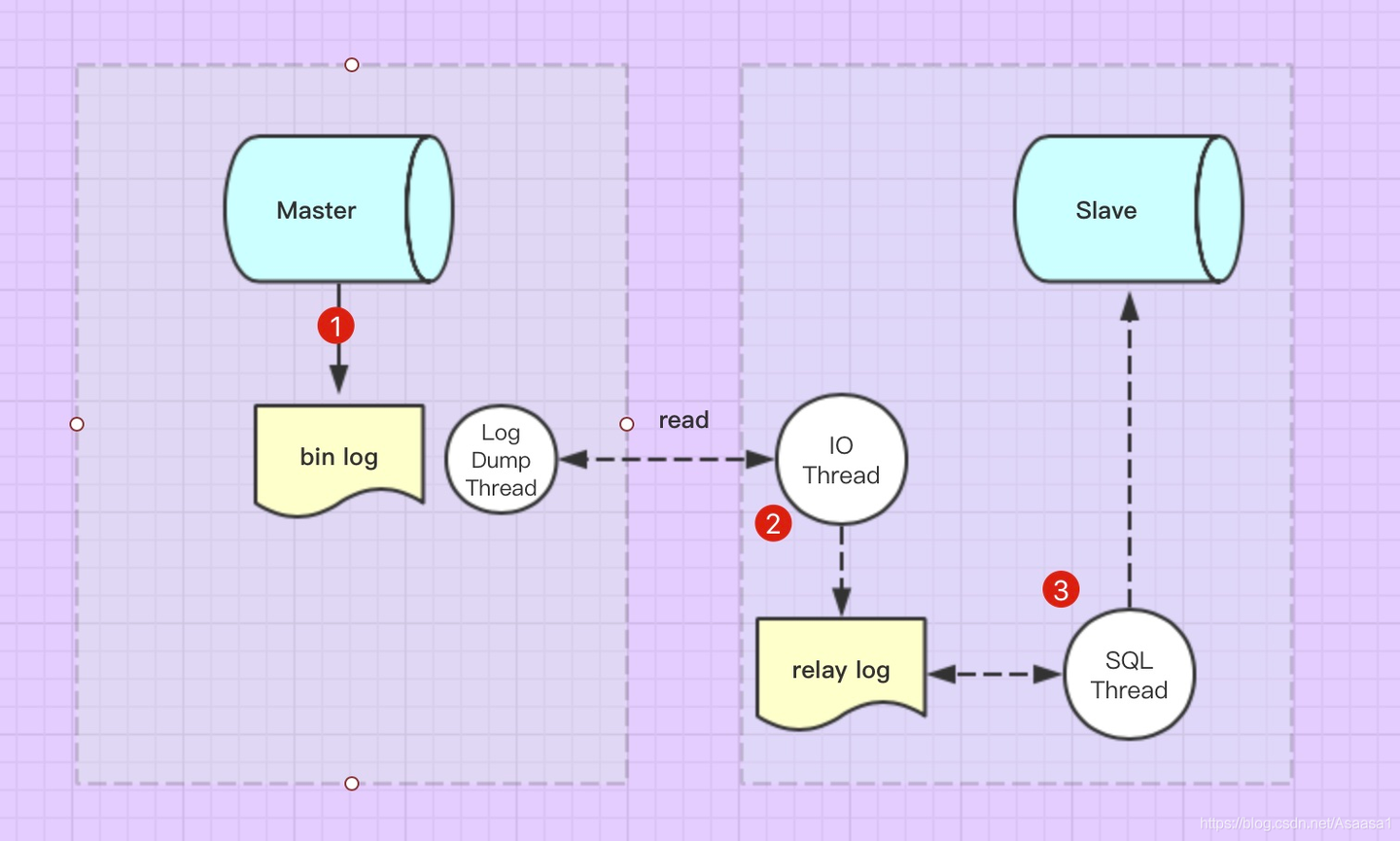
·两个日志(master的bin-log日志和slave的relay log)
·三个线程(master的dump线程、slave的io线程和sql线程)
- master(主服务器)执行DDL或DML语句时,会记录bin-log
- bin-log写入成功后,dump线程会通知slave(从服务器)节点
- slave使用io线程读取master的bin-log日志,并写入relay log中
- slave使用sql线程将relay log中新添加的内容转换为SQL语句,并执行,从而实现从节点(slave)与主节点(master)的数据一致。
实时备份,替补,读取分离,集群
线程是进程中任务最小执行单元,一个进程中可以包含多个线程,执行相同或不同的功能,实现多线程并发执行。
6、InnoDB引擎日志(Redo Log & Undo Log)
日志类型 | Redo Log(重做日志) | Undo Log(回滚日志) |
核心作用 | 记录数据页的修改,确保事务持久性(崩溃后可恢复) | 记录事务前的数据状态,支持回滚和MVCC |
与事务的关联 | 事务提交时写入,支持预写日志(WAL)机制 | 事务执行中动态生成,提交后仍需保留(供 MVCC 或异步清理) |
配置与管理 | [mysqld] # 单个redo log文件大小(默认48M,建议设为512M-2G) innodb_log_file_size = 512M # 日志文件数量(默认2个,如ib_logfile0、ib_logfile1) innodb_log_files_in_group = 2 # 日志路径(默认数据目录)innodb_log_group_home_dir = ./ | [mysqld] # undo log存储路径 innodb_undo_directory = ./ # undo日志段数量(默认128) innodb_undo_logs = 128 # 独立undo表空间数量(避免共享表空间膨胀)innodb_undo_tablespaces = 3 |
工作原理 / 特性要点 | 记录数据页的物理修改(如 “某数据页偏移量 X 改为值 Y” ),与具体 SQL 逻辑无关; | 记录逻辑操作的反向指令(如:插入 → 记录 “删除”;更新 → 记录 “字段值回退” ); |
存储与清理机制 | 存储在独立的 redo log 文件(如 ib_logfile0 ); | 存储在表空间文件(ibdata1 或独立表空间 .ibd 文件); |
日志管理最佳实践
1.按需开启日志:
必须开启:错误日志、二进制日志(主从或需恢复场景)、InnoDB日志(默认开启)。
按需开启:慢查询日志(长期开启)、查询日志(仅临时调试)。
2.性能与存储平衡:
日志文件存储在独立磁盘(避免与数据盘IO竞争)。
高并发场景下,long_query_time不宜设得过小(如<0.1秒),避免慢查询日志写入频繁。
3.自动化管理:
所有日志配置logrotate轮转(切割、压缩、删除旧日志)。
监控日志目录磁盘使用率(如通过Prometheus+Grafana),避免占满磁盘。
4.安全与权限:
日志文件权限设为600(仅mysql用户可读写),避免敏感信息泄露(如binlog包含数据变更)。
定期备份二进制日志(用于数据恢复),并加密存储。
常见问题与解决方案
问题场景 | 排查步骤 | 解决方案 |
服务启动失败 | 查看错误日志,搜索"error"关键词 | 检查端口占用、权限、配置文件语法错误 |
慢查询日志无记录 | 确认slow_query_log=ON,且SQL执行时间≥阈值 | 调整long_query_time,检查log_queries_not_using_indexes |
主从同步延迟 | 从库执行SHOW SLAVE STATUS\G,查看中继日志 | 优化从库SQL线程(如slave_parallel_workers) |
binlog文件过大 | 检查max_binlog_size和expire_logs_days | 调小单个文件大小,设置自动过期时间 |