TF-IDF 红楼梦关键词提取
目录
一.案例准备
1.数据准备
2.思路
二.案例实施
1.打开红楼梦文件进行分卷
2.获取每个分卷的地址和内容
3.对每个分卷的内容进行jieba分词和删除停用词
4.导入TF-IDF和相关库
5.创建模型,将内容列表传入模型训练
6.得到所有文本关键词并得到关键词在对应文章中的TF-IDF值的表格
7.打印每一分卷中的前十个重要的关键词
8.完整代码
一.案例准备
1.数据准备
首先我们有红楼梦.txt文件,里面写的是红楼梦前120章的内容
部分内容如下
.....
2.思路
①首先我们需要将这120卷的内容一卷一卷的分开来保存,方便我们后面对每一卷分词
②根据每个分卷的保存地址打开文件读取内容并对每一篇的内容进行分词
③对每篇文章分词后的结果进行检查(如果存在停用词即一些无用的词就去除)并写入分词汇总文件中,注意每一篇的分词内容值占一行
④最后对标准格式的分词汇总文件计算TF-IDF值
二.案例实施
1.打开红楼梦文件进行分卷
通过open()方法打开文件,并创建一个红楼梦介绍文件,这里的i为后面文件名做准备
import os.path
file=open('红楼梦.txt','r')
file_out=open('./红楼梦介绍.txt','w')
i=1使用for循环一行一行的遍历文件内容,在没有遇到章节标题前读取的每一行内容都会写入创建的红楼梦需要注意 介绍文件中,然后遇到标题像‘上卷 第一回.....’我们就以该章节名作为文件名新创建一个文件,然后将后面的内容写入该文件中,如果读取到了下一章‘上卷 第二回...’则继续重新创建该章节的文件,反复此流程,直至将120章内容读完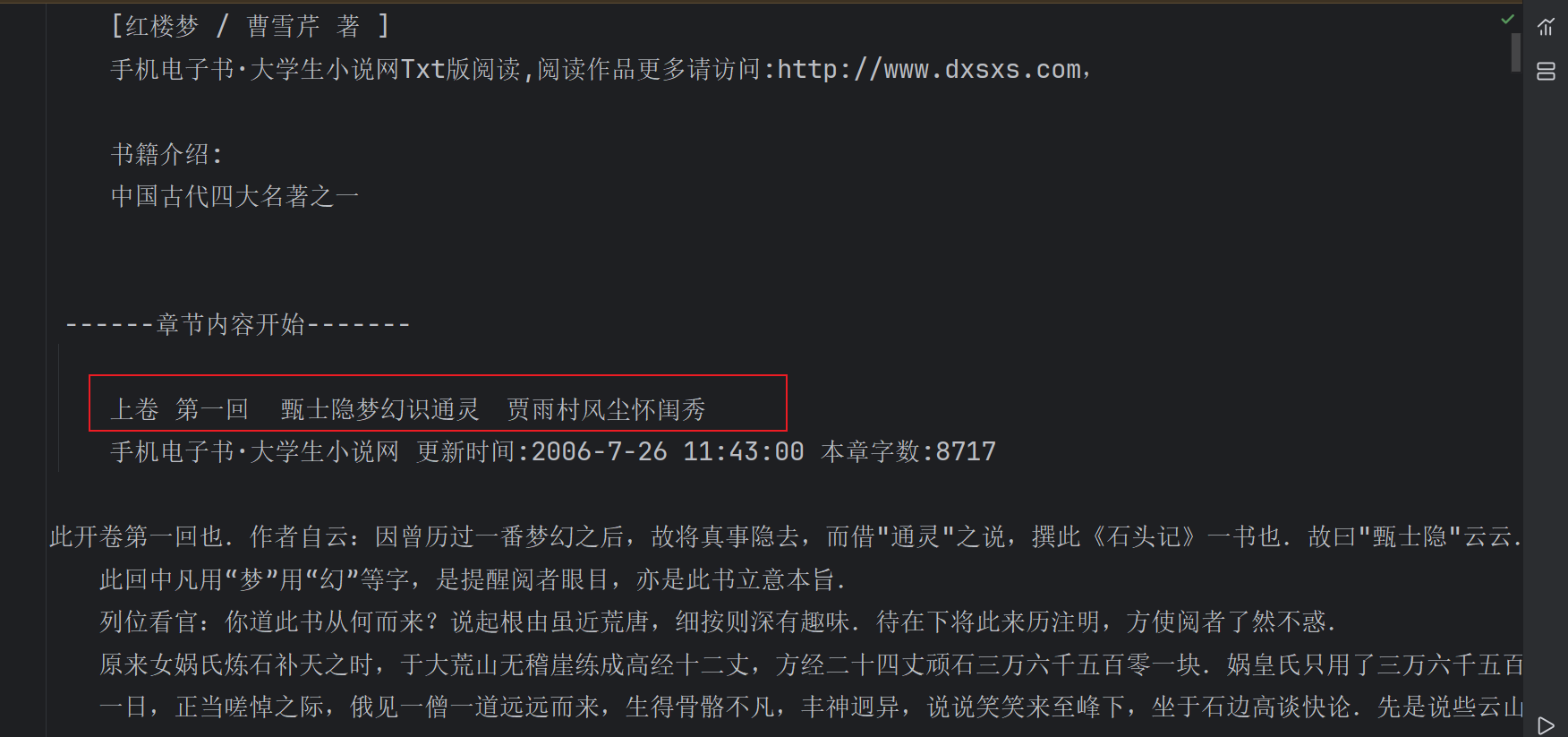
注意我们还需要判断是不是空白行或者无用的介绍如下图,如果是的话就跳过不将该行内容写入
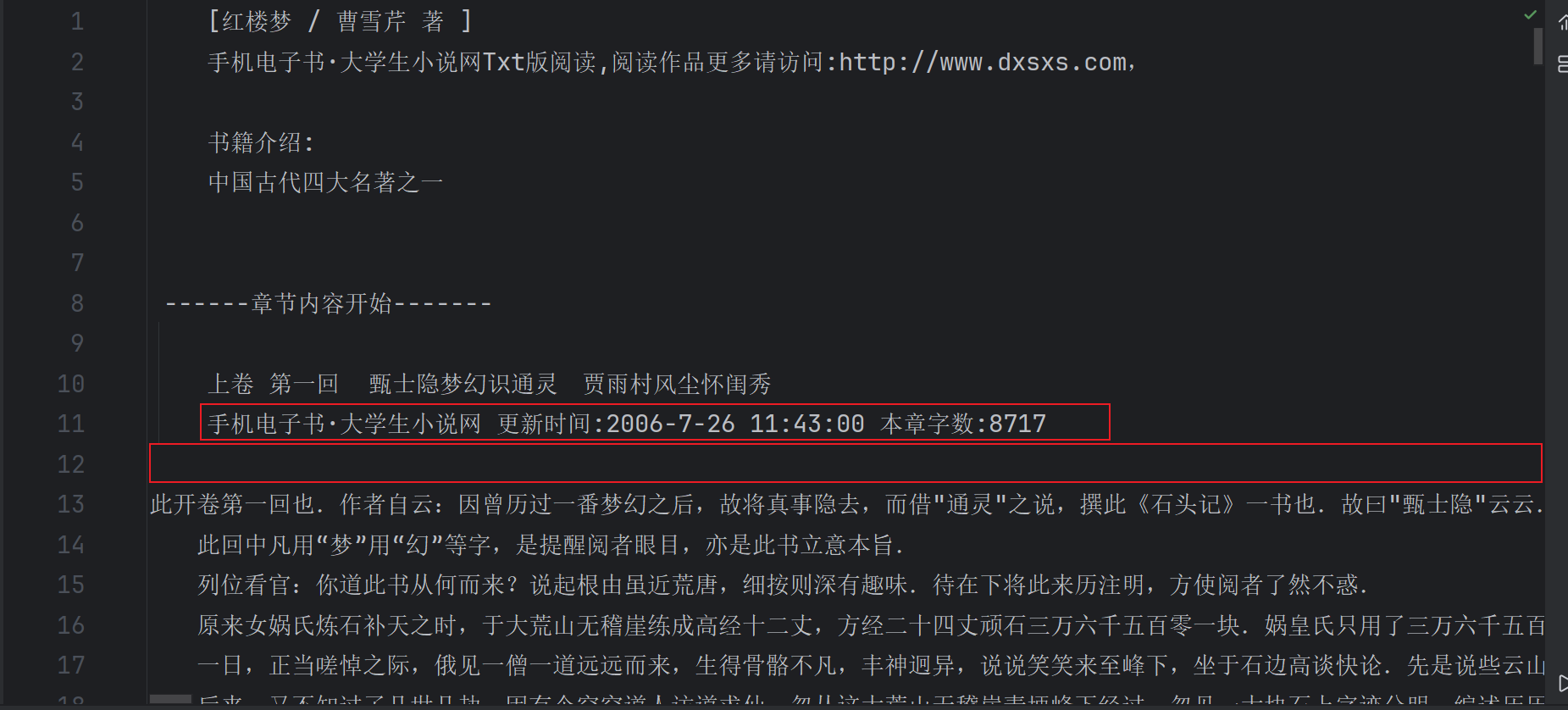
# 分卷
for line in file:stripped_line=line.strip()if not stripped_line:continueif '手机电子书·大学生小说网' in line:continueif '卷 第' in line:title_name='0_{}'.format(i)+line.strip()+'.txt'i+=1file_name=os.path.join('分卷',title_name)file_out = open(file_name, 'w')continue#不将标题写入file_out.write(line)
file_out.close()保存后的文件如下:
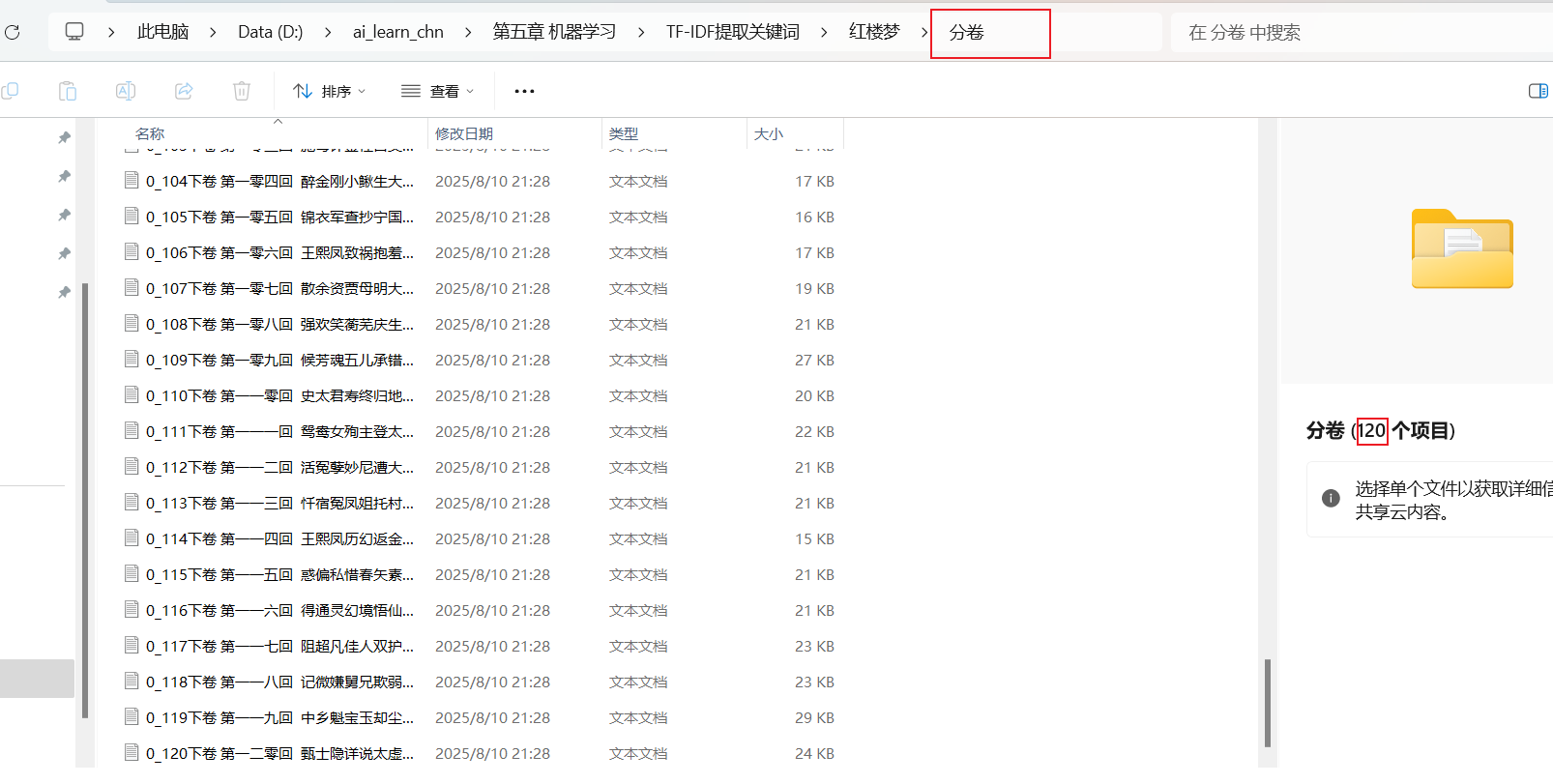
2.获取每个分卷的地址和内容
通过os.walk方法获取./分卷路径下的根目录,文件夹名,和文件名
在对文件名列表进行遍历,通过os.path.join方法获得每个文件的地址,再通过这个地址打开文件获取每个文件的内容,分别写入一个列表中储存起来
最后通过pandas库将两个列表存储的信息转换成表格数据类型,加快计算速率
import os
import pandas as pd
filePaths=[]
fileContents=[]
for root,dir,files in os.walk(r'./分卷'):for file in files:filePath=os.path.join(root,file)filePaths.append(filePath)f=open(filePath,'r')fileContent=f.read()fileContents.append(fileContent)f.close()
corporas=pd.DataFrame({'filePath':filePaths,'fileContent':fileContents
})3.对每个分卷的内容进行jieba分词和删除停用词
我们事先准备了红楼梦词库.txt文件,将红楼梦的专属词库通过jieba.load_userdict()导入jieba中对内容分词,顺便将StopwordsCN.txt中的全部停用词读取出来
再创建一个分词后汇总的文件
import jieba
jieba.load_userdict('./红楼梦词库.txt')
stopwords=pd.read_table('StopwordsCN.txt')
f=open('分词后汇总.txt','w')遍历我们之前存储分卷信息的表格数据,row是每一行存储的filePath和fileContent信息
将每一行的fieContent即分卷内容进行jieba分词,得到分词后的列表,再对该列表遍历检查有无停用词或空格,将剩下的符合条件的列表元素写入juan_ci中用空格分隔开每一个分词元素
遍历完一行内容的所有分词后,将juan_ci写入分词后汇总文件中,要加换行,保证TF-IDF使用的标准格式
for index,row in corporas.iterrows():juan_ci=''filePath=row['filePath']fileContent=row['fileContent']segs=jieba.lcut(fileContent)for seg in segs:if seg not in stopwords.stopword.values and len(seg.strip())>0:juan_ci+=seg+' 'f.write(juan_ci+'\n')
f.close()4.导入TF-IDF和相关库
读取分词后汇总文件,返回一行内容作为一个元素的列表
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
file=open('分词后汇总.txt','r')
corpus=file.readlines()5.创建模型,将内容列表传入模型训练
vectorizer=TfidfVectorizer()
tf=vectorizer.fit_transform(corpus)6.得到所有文本关键词并得到关键词在对应文章中的TF-IDF值的表格
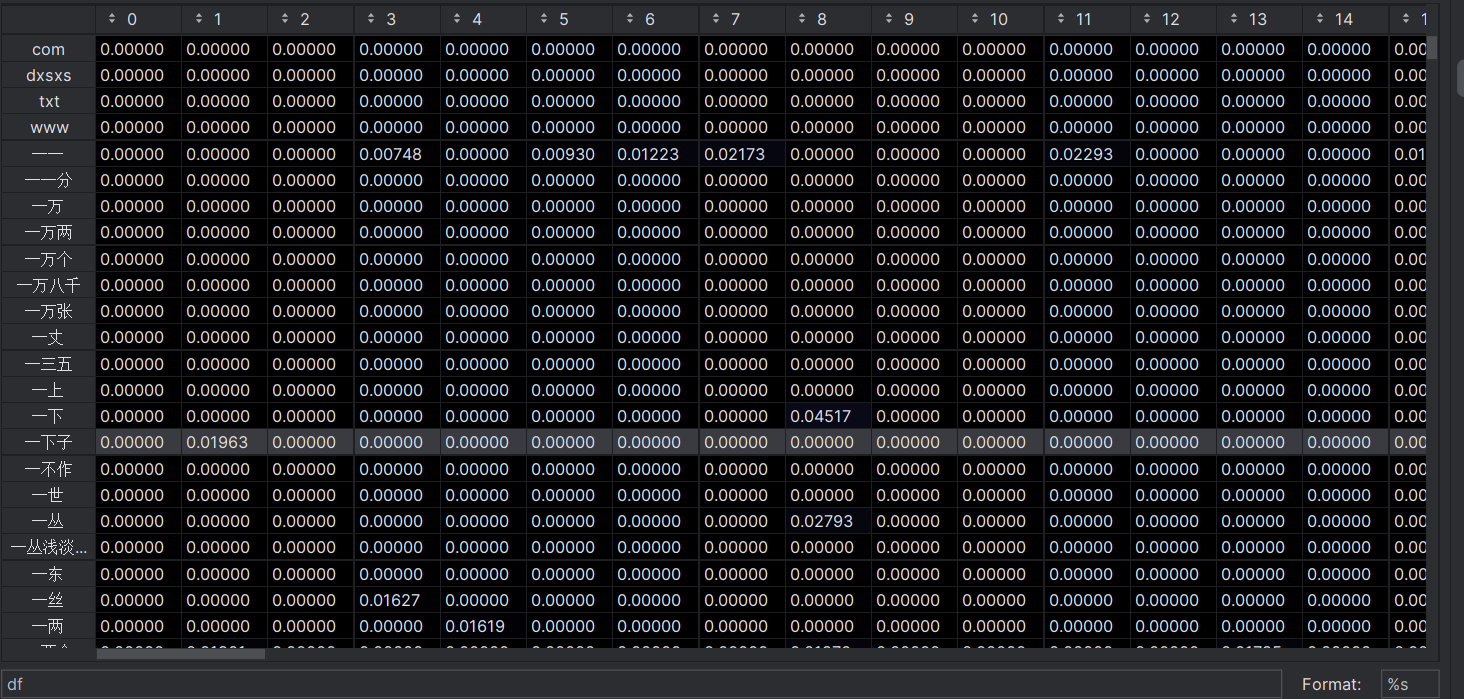
wordlist=vectorizer.get_feature_names()
df=pd.DataFrame(tf.T.todense(),index=wordlist)索引是每个文本关键字,列名是对用的120章分卷,表格数据是关键词在对应文章中的TF-IDF值
7.打印每一分卷中的前十个重要的关键词
利用pandas库的sortvalues()方法对每一列数据进行从大到小排序,再打印
for i in range(len(corpus)):feature=df.sort_values(by=i,ascending=False)# 打印前十个关键词print('{}关键词有:\n{}'.format(corporas.iloc[i,0].split('卷 ')[1].strip('.txt'),feature.iloc[:10,i]))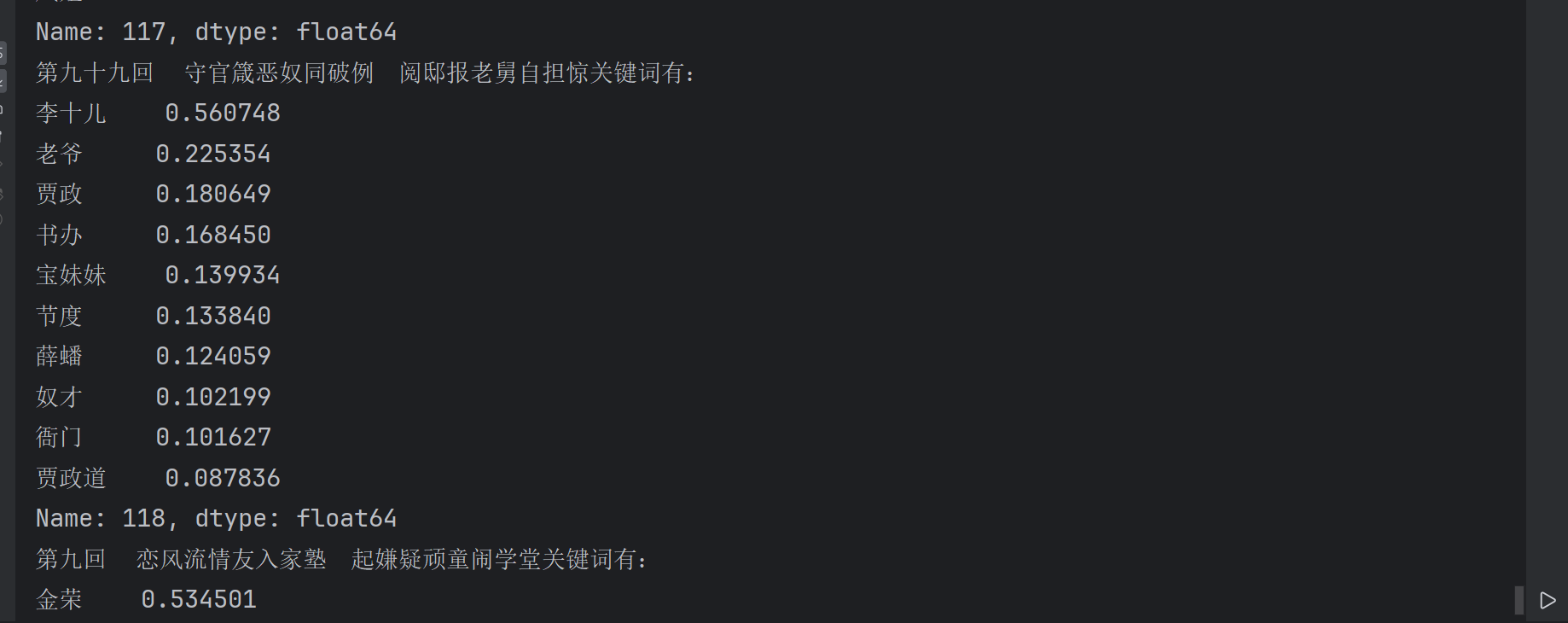
8.完整代码
# import os.path
# file=open('红楼梦.txt','r')
# file_out=open('./红楼梦介绍.txt','w')
# i=1
# # 分卷
# for line in file:
# stripped_line=line.strip()
# if not stripped_line:
# continue
# if '手机电子书·大学生小说网' in line:
# continue
# if '卷 第' in line:
# title_name='0_{}'.format(i)+line.strip()+'.txt'
# i+=1
# file_name=os.path.join('分卷',title_name)
# file_out = open(file_name, 'w')
# continue#不将标题写入
# file_out.write(line)
# file_out.close()# 分词 卷词
import os
import pandas as pd
filePaths=[]
fileContents=[]
for root,dir,files in os.walk(r'./分卷'):for file in files:filePath=os.path.join(root,file)filePaths.append(filePath)f=open(filePath,'r')fileContent=f.read()fileContents.append(fileContent)f.close()
corporas=pd.DataFrame({'filePath':filePaths,'fileContent':fileContents
})# import jieba
# jieba.load_userdict('./红楼梦词库.txt')
# stopwords=pd.read_table('StopwordsCN.txt')
# f=open('分词后汇总.txt','w')
# for index,row in corporas.iterrows():
# juan_ci=''
# filePath=row['filePath']
# fileContent=row['fileContent']
# segs=jieba.lcut(fileContent)
# for seg in segs:
# if seg not in stopwords.stopword.values and len(seg.strip())>0:
# juan_ci+=seg+' '
# f.write(juan_ci+'\n')
# f.close()#计算TF-ITF值
from sklearn.feature_extraction.text import TfidfVectorizer
import pandas as pd
file=open('分词后汇总.txt','r')
corpus=file.readlines()vectorizer=TfidfVectorizer()
tf=vectorizer.fit_transform(corpus)
wordlist=vectorizer.get_feature_names()
df=pd.DataFrame(tf.T.todense(),index=wordlist)
for i in range(len(corpus)):feature=df.sort_values(by=i,ascending=False)# 打印前十个关键词print('{}关键词有:\n{}'.format(corporas.iloc[i,0].split('卷 ')[1].strip('.txt'),feature.iloc[:10,i]))
print('========================')