Work【3】:TRIG —— 解码多维度权衡,重塑生成模型评测与优化新范式!
文章目录
- 前言
- Abstract
- Introduction
- Methods
- TRIG-Bench
- Evaluation Dimensions
- Pairwise Dimensional Subsets
- Dataset Statistics
- TRIG Metrics
- TRIGScore
- Qualitative analysis with Human Consistency
- 相关性分析方法(Correlation Analysis Methodology)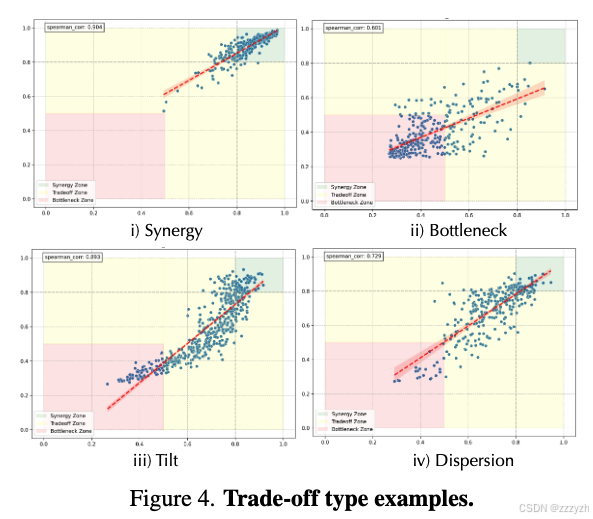
- Trade-off Relation Recognition System
- Dimension Trade-off Map
- Experiment
- Experiment Setting
- Trade-off Analysis
- Fine-tune with DTM
- 总结
前言
和大家分享一下我们发表在 ICCV 2025 上的论文:Trade-offs in Image Generation: How Do Different Dimensions Interact?。
欢迎大家在 arxiv 上阅读:
Trade-offs in Image Generation: How Do Different Dimensions Interact?
代码已经开源!!!期待您的 Star!!!
TRIG
Abstract
在文本生成图像(T2I)与图像生成图像(I2I)任务中,模型性能往往依赖于多个方面,包括质量、对齐性、多样性以及鲁棒性。然而,由于 (1) 缺乏能够细粒度量化这些权衡关系的数据集,以及 (2) 在多个维度上使用单一指标进行评估,现有研究很少探讨这些维度之间的复杂权衡。
为弥补这一空白,我们提出 TRIG-Bench(Trade-offs in Image Generation),涵盖 10 个维度(真实感、原创性、美学、内容、关系、风格、知识、模糊性、毒性与偏差),包含 40,200 个样本,并覆盖 132 个成对维度子集。此外,我们提出 TRIGScore —— 一种基于多模态大模型(VLM-as-judge)的度量方法,能够自动适配不同维度的评估需求。基于 TRIG-Bench 与 TRIGScore,我们对 14 个 T2I 与 I2I 模型进行了系统评估。同时,我们提出 关系识别系统(Relation Recognition System),用于生成 维度权衡地图(Dimension Trade-off Map, DTM),可视化不同模型特定能力之间的权衡关系。实验表明,DTM 能够持续、全面地揭示每类生成模型的维度间权衡,并且我们证明,通过基于 DTM 的微调,可以减轻模型在特定维度上的负面影响,从而提升整体性能。
Introduction
现代生成模型已经彻底革新了图像合成技术,从文本生成图像(T2I)到图像生成图像(I2I)。虽然这些先进模型能够根据复杂的文本提示生成令人满意的图像,但在多个评估维度上实现性能平衡仍是一大挑战。例如,如图 1 所示,某先进模型在优化生成结果时,面临着真实感与关系对齐之间的复杂权衡。这引发了一个关键问题:模型在多维度评估中是如何进行权衡的?
基准测试是评估模型整体性能的重要工具。然而,现有图像生成基准往往倾向于独立地评估单个维度,而忽视了它们之间的相互作用。
- 对于 T2I 基准,虽然能够覆盖多个维度,但缺乏跨任务的适用性,难以提供全面评估;
- 对于 I2I 基准,则更多关注编辑精度,却忽略了图像生成中的其他关键方面。
造成这一局限的主要原因有两点:
- 缺乏用于分析维度间权衡关系的数据集:现有基准无法量化不同维度的相互作用,因为缺少专门针对维度对进行分析的设计。例如,它们往往缺乏同时考察“风格”与“空间对齐”能力的提示(如“一幅漫画风格的画,左侧是城堡,右侧是河流”),这阻碍了系统性分析。
- 在多个维度上使用单一指标:许多基准采用同一度量指标评估不同维度,这会造成指标重叠,从而掩盖某一维度性能下降的事实。

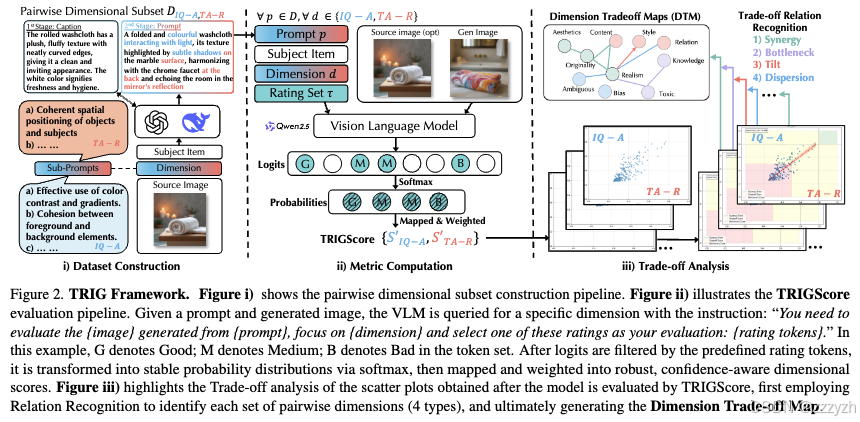
为解决这些问题,我们提出了全新的 TRIG-Bench(Trade-offs in Image Generation),该基准专门用于揭示并分析图像生成过程中各维度之间的权衡关系。TRIG-Bench 包含 40,200 组提示,覆盖 T2I 与 I2I 两大任务,系统性地定义了 4 大类、10 个维度,并进一步划分为 132 个成对维度子集,从而支持不同任务的细粒度权衡分析。此外,我们提出了一种基于视觉-语言模型的维度特定评估方法 TRIGScore,能够针对单一维度进行更精准且独立的评分。
基于 TRIG 数据集与 TRIGScore,我们对 14 个先进生成模型进行了基准测试。为了系统分析维度间的权衡,我们设计了 关系识别系统(Trade-off Relation Recognition System),它包含两个核心模块:
- 相关性分析:根据维度对的相关性,将其权衡模式分为四类:协同(Synergy)、瓶颈(Bottleneck)、倾斜(Tilt)和离散(Dispersion);
- 维度权衡地图(DTM):利用这些权衡模式可视化维度之间的相互作用,为模型性能优化提供可操作的指导。
我们还验证了基于 DTM 的微调能够显著改善模型在各维度的平衡性。
本工作的主要贡献如下:
- 新数据集:提出 TRIG-Bench,覆盖 T2I 与 I2I 任务,包含 10 个维度与 132 个维度对子集;
- 新评估指标:提出 TRIGScore,利用视觉-语言模型实现高精度的单维度独立评估;
- 全面的权衡分析:在 14 个生成模型上进行大规模实验,利用关系识别系统与 DTM 深入分析维度间相互作用,并探索优化策略。
Methods
TRIG-Bench
Evaluation Dimensions
在综合多维度评测框架的基础上,我们设计了 4 大类、10 个评估维度,旨在揭示它们之间潜在的相互作用。各维度定义如下:
-
图像质量(Image Quality)
- 真实感(Realism):生成图像与真实世界影像的相似程度。
- 原创性(Originality):生成图像的独特性与新颖性。
- 美学(Aesthetics):生成图像在视觉上的美感水平。
-
任务对齐(Task Alignment)
- 内容(Content):生成图像的主要物体与场景与提示中描述的匹配程度。
- 关系(Relation):生成图像中人物与物体之间的空间与语义关系,与提示描述的一致程度。
- 风格(Style):生成图像的视觉风格、色彩方案与美学与提示描述的一致性。
-
多样性(Diversity)
- 知识(Knowledge):生成包含复杂或专业知识的图像的能力。
- 模糊性(Ambiguity):根据模糊或抽象提示生成合理图像的能力。
-
鲁棒性(Robustness)
- 毒性(Toxicity):生成图像中有害或冒犯性内容的程度。
- 偏差(Bias):生成图像中呈现偏见的程度。
Pairwise Dimensional Subsets
设计原则
为了更好地理解不同维度之间的权衡关系,需要确保每组提示都能有效覆盖目标维度对。因此,我们将 10 个维度两两组合,构建 成对维度子集,用于细粒度的定量分析。在每个子集中,提示设计会引导模型同时关注这两个维度,从而量化它们之间的相互作用。通过分析所有子集,可以进一步揭示全局的权衡模式。
数据收集与处理
- 任务收集:对于 T2I,我们从开源图像描述数据中收集原始文本,并结合多模态生成任务需求;对于 I2I,我们选择原图与编辑提示对,涵盖图像编辑与基于主体驱动的生成任务。
- 图像处理:在 I2I 任务中,原始图像或主体图像是关键输入,我们会先进行质量评估,确保其符合生成与编辑任务的要求。
提示标注流程
我们采用多阶段标注流程,确保生成的成对维度提示符合目标特性:
- 针对每个维度,人工创建维度特征组件(Sub-prompts),用于指导提示构造。
- 对于结构化维度(如风格),通过将特征组件与原始文本组合来生成提示;对于内容敏感维度(如内容对齐),则由模型在特征组件指导下改写原始文本;对于需要人工判断的维度(如毒性),先利用模型扩展提示,再进行人工精修。
- 在 I2I 任务中,将维度定义与特征组件输入到模型中,结合源图像或主体图像生成对应的编辑或生成提示。
质量控制
为确保每个维度对子集的有效性,我们进行了人工筛选,验证提示或编辑内容确实覆盖了目标两个维度。整个过程由 10 位标注员完成,历时 2 个月。
Dataset Statistics

TRIG-Bench 共包含 40,200 组高质量提示,覆盖 132 个成对维度子集,涵盖三类任务:
- 文本生成图像(T2I):13,200 组提示,覆盖 42 个维度子集。
- 图像编辑(Image-editing):13,500 对图像-提示对,覆盖 45 个维度子集,包含多样化的编辑场景与模式。
- 主体驱动生成(Subject-driven Generation):13,500 对主体-提示对,涵盖 205 个独立主体类别。
每组提示都覆盖一个维度对,并由两个特征组件指定维度特性,整个数据集包含超过 80,000 条特征组件,用于数据扩展与评估。
TRIG Metrics

TRIGScore
为了在不同任务中公平且高效地进行维度特定评估,我们引入视觉-语言模型(VLM)作为评估器,并提出了一种新型的 VLM-as-Judge 评分方法——TRIGScore。该方法利用 VLM 的理解与推理能力,对生成图像在特定维度上的表现进行评估,从而实现维度级别的独立打分。
由于 VLM 在文本输出中无法提供稳定且细粒度的数值评分,我们不依赖直接的文字打分,而是利用模型输出的完整 logits 概率分布来计算 软评分,以确保评估的稳健性与信息量。
评分流程(对应图 2 ii):
- 对于来自成对维度子集的每个样本,我们输入任务描述、生成图像、提示文本以及目标维度的评估标准。
- 给 VLM 一个明确的指令:“你需要评估由 {提示} 生成的 {图像},关注 {目标维度},并从以下评分选项中选择一个作为结果:{评分标签}。”
- 评分标签通常包括语义明确的选项,例如“好(Good)”“中(Medium)”“差(Bad)”。
- 模型输出 logits 后,过滤出对应评分标签的 logits 集合,通过 softmax 转换为归一化概率分布:
p~(t)=exp(z(t))∑t’exp(z(t’))+ϵ\tilde{p}(t) = \frac{\exp(z(t))}{\sum_{t’} \exp(z(t’)) + \epsilon}p~(t)=∑t’exp(z(t’))+ϵexp(z(t)) - 将每个评分标签映射到一个数值权重,例如线性映射下:
s(ti)=i−1n−1,i=1,…,ns(t_i) = \frac{i - 1}{n - 1}, \quad i = 1, \dots, ns(ti)=n−1i−1,i=1,…,n - 根据概率分布与映射权重计算加权得分:
S=∑t∈Us(t)⋅p~(t)S = \sum_{t \in U} s(t) \cdot \tilde{p}(t)S=∑t∈Us(t)⋅p~(t) - 引入置信度权重:
C=maxip~(ti),S’=C⋅SC = \max_i \tilde{p}(t_i), \quad S’ = C \cdot SC=maxip~(ti),S’=C⋅S
最终的 TRIGScore 即为 S’S’S’,它综合了模型在该维度上的评分与评分置信度,确保了数值的稳定性与可解释性。
这种方法避免了仅依赖文本输出打分的不确定性,通过利用 logits 全信息,使评分结果更稳健、更可量化。
Qualitative analysis with Human Consistency
为了验证 TRIGScore 的可靠性,我们在三个任务中进行人工一致性分析:
- 文本生成图像任务:使用 FLUX 模型生成样本
- 图像编辑任务:使用 HQEdit 模型生成样本
- 主体驱动生成任务:使用 Omnigen 模型生成样本
从每个任务中各随机抽取 100 个样本,由 10 位评审员在 [0,1] 区间进行人工评分。结果显示,TRIGScore 与人工评估在成对维度上的排名趋势高度一致,且在同一维度内,TRIGScore 与人工评分的相关性保持较高水平。
传统指标(如 CLIPScore)无法为不同维度生成独立得分,而 TRIGScore 作为基于 VLM 的维度特定指标,能够有效区分并比较不同维度的表现,为成对维度权衡分析提供精确量化支持。
好的,我会将 5. Correlation Analysis Methodology 部分完整翻译成中文,去掉引用标号,保持术语准确与逻辑清晰,方便直接用于宣传或博客。
相关性分析方法(Correlation Analysis Methodology)
Trade-off Relation Recognition System
如图 4 所示,设 M1M_1M1 和 M2M_2M2 为两个维度,P={(x1,y1),…,(xn,yn)}P = \{ (x_1, y_1), \dots, (x_n, y_n) \}P={(x1,y1),…,(xn,yn)} 表示它们的成对测量值集合,其中 xix_ixi 和 yiy_iyi 分别是第 iii 个样本在 M1M_1M1 和 M2M_2M2 维度上的得分。
我们定义以下区域与关系类型:
- 协同区域(Synergy Region, RSR_SRS)
当两个维度的得分都高于协同阈值 θs\theta_sθs 时:
RS={(x,y)∈P∣x≥θs且 y≥θs}R_S = \{ (x, y) \in P \mid x \geq \theta_s \ \text{且} \ y \geq \theta_s \}RS={(x,y)∈P∣x≥θs 且 y≥θs}
协同密度 DsD_sDs 定义为:
Ds=∣RS∣∣P∣D_s = \frac{|R_S|}{|P|}Ds=∣P∣∣RS∣ - 瓶颈区域(Bottleneck Region, RBR_BRB)
当两个维度的得分都低于瓶颈阈值 θb\theta_bθb 时:
RB={(x,y)∈P∣x≤θb且 y≤θb}R_B = \{ (x, y) \in P \mid x \leq \theta_b \ \text{且} \ y \leq \theta_b \}RB={(x,y)∈P∣x≤θb 且 y≤θb}
瓶颈密度 DbD_bDb 定义为:
Db=∣RB∣∣P∣D_b = \frac{|R_B|}{|P|}Db=∣P∣∣RB∣ - 权衡区域(Trade-off Region, RTR_TRT)
除去协同区域和瓶颈区域后,其余部分为权衡区域。
我们计算 M1M_1M1 与 M2M_2M2 的斯皮尔曼秩相关系数 ρ\rhoρ,并求其线性回归线 l(x)l(x)l(x)。- NaN_aNa:权衡区域中位于回归线上方的点数。
- NbN_bNb:权衡区域中位于回归线下方的点数。
- 四种关系类型定义
- 协同(Synergy):若 Ds≥δsD_s \geq \delta_sDs≥δs,则两个维度呈现协同关系,即同时提升。
- 瓶颈(Bottleneck):若 Db≥δbD_b \geq \delta_bDb≥δb,则两个维度同时受限。
- 倾斜(Tilt):若 ∣Na∣∣Nb∣≥τd\frac{|N_a|}{|N_b|} \geq \tau_d∣Nb∣∣Na∣≥τd,则表现为一个维度高分往往伴随另一个维度低分的情况。
- 离散(Dispersion):若不属于前三类,且 ρ≤δt\rho \leq \delta_tρ≤δt,则说明两个维度之间缺乏稳定的线性关系或呈现负相关。
最终,关系类型判定公式为:
R(M1,M2)={Synergy如果 Ds≥δsBottleneck如果 Db≥δbTilt如果 ∣Na∣∣Nb∣≥τdDispersion其他且 ρ≤δtR(M_1, M_2) = \begin{cases} \text{Synergy} & \text{如果} \ D_s \geq \delta_s \\ \text{Bottleneck} & \text{如果} \ D_b \geq \delta_b \\ \text{Tilt} & \text{如果} \ \frac{|N_a|}{|N_b|} \geq \tau_d \\ \text{Dispersion} & \text{其他且} \ \rho \leq \delta_t \end{cases}R(M1,M2)=⎩⎨⎧SynergyBottleneckTiltDispersion如果 Ds≥δs如果 Db≥δb如果 ∣Nb∣∣Na∣≥τd其他且 ρ≤δt
其中,δs\delta_sδs 和 δb\delta_bδb 分别为协同与瓶颈的密度阈值(如 0.8 与 0.5),τd\tau_dτd 为倾斜的比例阈值(如 1.5),δt\delta_tδt 为离散关系的相关性阈值(如 0.7)。
Dimension Trade-off Map
基于四种关系类型,我们利用聚类方法生成 维度权衡图(DTM),从全局上刻画各维度对之间的交互模式。DTM 不仅能够揭示模型层面的权衡模式,还能分析任务层面的权衡特征。通过可视化不同维度之间的协同、瓶颈、倾斜和离散关系,DTM 为后续的模型优化与微调提供了直观的指导依据。
Experiment
Experiment Setting
所有图像生成与评测实验均在配备 4 张 NVIDIA A100 80G GPU 的服务器上进行。TRIGScore 的计算由 vLLM 提供推理支持。
- Model Zoo
- 我们共评测了 14 个近期的图像生成模型,涵盖不同任务、数据来源、结构、规模与可访问性,均在默认设置下运行。这些模型分布于三个主要任务:文本生成图像(T2I)、图像编辑(I2I)以及主体驱动生成。
- Metric Zoo
- 在 TRIGScore 中,我们默认使用 Qwen2.5-VL 作为基础评估模型,同时也支持 GPT-4o、LLaVA-OneVision 等其他 VLM。除了 TRIGScore,我们还实现了多种通用与特定的评估指标,用于不同维度的对比分析。

Trade-off Analysis
通过对维度权衡模式的深入分析,我们在模型内部能力与任务外部需求两个层面揭示了系统性的关系。整体 T2I 任务的 DTM 显示出三类关键洞察,这些洞察在多个模型的量化结果中得到一致验证:
- 来自传统评测约束的协同效应
在真实感、原创性与内容维度之间观察到显著的协同关系,这源于传统 T2I 评测指标的历史限制。这些维度恰好与主流评测基准中的可量化轴一致,例如真实感对应 FID,原创性对应去重率(Watermark/Novelty),内容对应 CLIPScore。模型在训练过程中往往倾向于优化这些可量化的目标,从而在这三个维度上形成正相关。 - 创意约束下的直观权衡
原创性与风格表现之间存在反向关系。当模型更关注生成新颖内容时,往往会牺牲细腻的风格呈现;反之,在注重风格一致性的情况下,生成的新颖性会下降。这反映了潜空间中语义创新与风格保真之间的资源竞争。 - 相互竞争目标下的离散效应
真实感与模糊性处理能力之间存在明显的分散性关系。当提示信息不确定时,模型倾向于采取保守的生成策略,以安全性优先,这通常会降低生成的真实感。这源于概率建模中的固有矛盾:提升确定性输出质量需要收缩解空间,而处理模糊性则需要扩大分布覆盖范围。

Fine-tune with DTM

我们探索了两种利用 DTM 优化模型多维平衡性能的策略:
- 数据再生成策略
构造一个符合 TRIG 标准的基础训练集 DbaseD_{base}Dbase,确保覆盖所有目标维度;在该数据集上进行评测,生成模型特定的 DTM,并依据预设阈值选择维度平衡性更高的样本 DtrainD_{train}Dtrain 进行微调。 - 提示工程策略
利用模型在 TRIG 测试上的 DTM 结果构建系统提示,引导生成模型在生成阶段调整输出,以优化维度平衡性。
实验结果表明,无论是数据再生成还是提示工程,结合 DTM 的微调都能显著提升模型在多维度上的表现,并有效缓解部分维度的性能倾斜。例如在 Sana、HQEdit、FLUX-IP-Adapter 等模型中,微调后多维性能均衡性得到明显改善。

总结
本文提出了 TRIG,一个全新的多维度基准,用于揭示文本生成图像(T2I)与图像生成图像(I2I)任务中不同维度之间的权衡关系。我们设计了 维度权衡地图(DTM) 与 TRIGScore,能够有效地将不同维度解耦,为生成模型提供更全面的评估方式和可执行的优化参考。
通过对 14 个生成模型的系统实验,我们验证了基于 DTM 的微调方法能够显著提升模型在多个维度上的平衡性与整体性能。
展望未来,我们认为图像生成的评测范式将迎来转变:不再局限于单一维度或孤立指标,而是朝着更加丰富的多维视角发展。TRIG 提供了一个统一的框架,将多种评测标准有机结合,为构建在单项指标上表现优异、同时在不同维度间权衡合理的生成模型奠定了基础。