ForceVLA——将具备力感知的MoE整合进π0的动作专家中:从而融合视觉、语言、力反馈三者实现精密插拔
前言
我在之前的博客里说过,我司目前侧重三大方面的场景落地,一个人形灵巧操作、一个人形展厅讲解,一个工业各种插拔,比如电源插拔、耳机插孔、USB插拔
之前我们看到过在VLM的指引下,装配宜家家居,更看到过在各种RL方法之下的插拔,以及结合ResNet视觉与MLP触觉且带语义增强的电源插拔
今天我们再看一个在VLA下且带触觉的精密插拔工作,即本文要介绍的ForceVLA
第一部分 ForceVLA
1.1 引言、相关工作、预备知识
1.1.1 引言
如ForceVLA原论文所说,π0[10] 仅需少量演示即可高效微调
- 然而,复杂接触的操作不仅需要语义基础和空间规划,更本质上依赖于交互力[12,13]。现有的VLA模型主要依靠视觉和语言线索,往往忽视了力觉感知这一对精确物理交互至关重要的模态
- 相比之下,人类能够自然地整合触觉和本体感觉反馈,从而调整操作策略 [14]。因此,VLA模型在插入、工具使用等任务中常常表现不佳
或在遮挡或视觉条件较差的情况下进行装配,容易导致系统行为脆弱或任务失败
此外,不同任务阶段对力的需求也在不断变化:精细抓取、受控插入和柔顺表面接触——每一阶段都需要不同形式的力调节。目前的方法缺乏感知和适应这些动态变化的机制,限制了其对物理交互进行时序推理的能力
为了解决这些局限性,来自的研究者提出了ForceVLA,其通过引入具备力感知的专家混合(Mixture-of-Experts, MoE)模块来增强VLA模型,从而在高接触操作任务中实现有效推理和具备情境感知、力信息驱动的动作生成,如图1所示
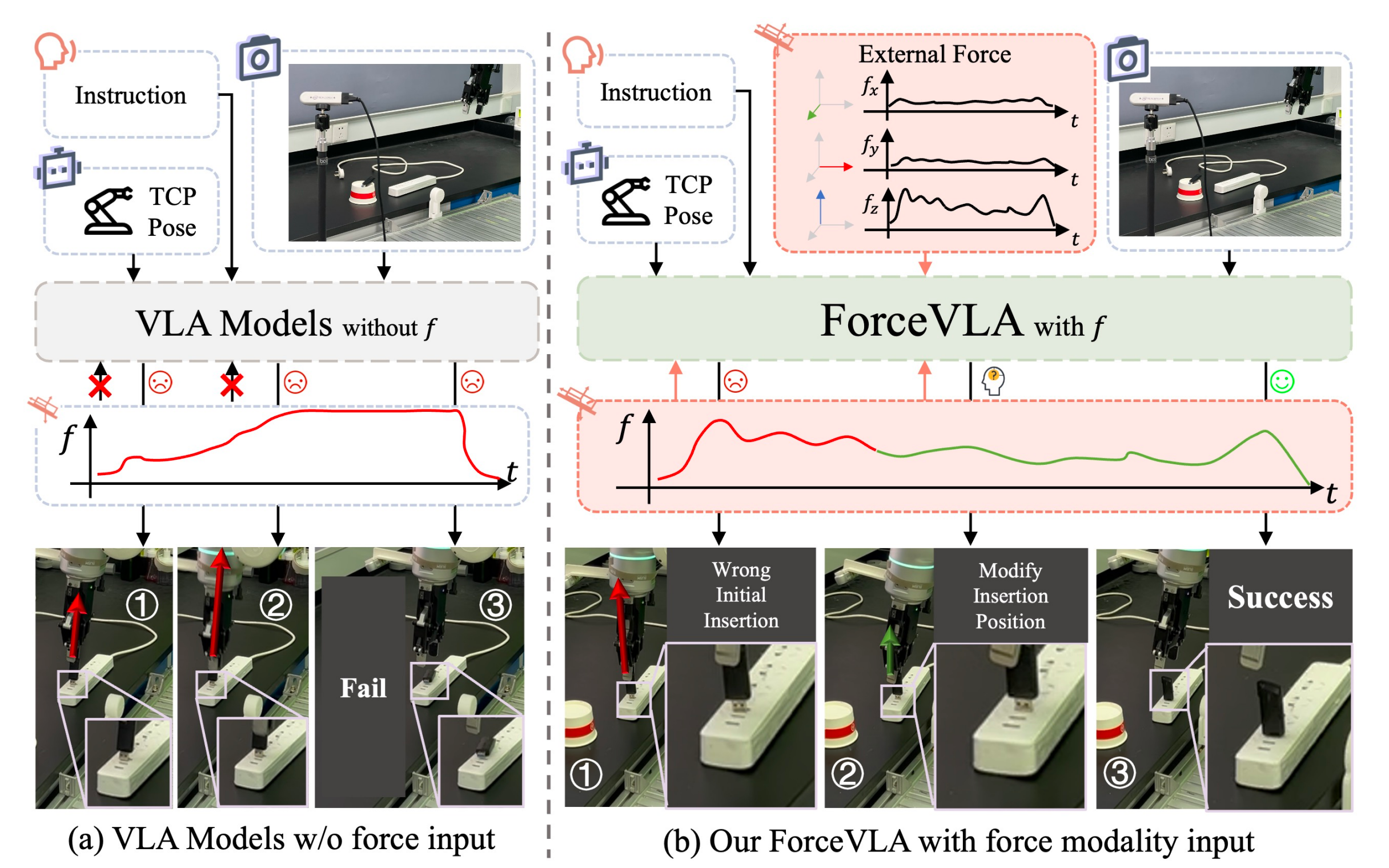
- ForceVLA的核心思想在于,将机器人末端执行器感知到的6D外部力视为一类重要模态,并将其正式整合进动作专家模块,以便在物理交互过程中基于力反馈实现具有阶段感知的动作生成
- 为实现这一整合,ForceVLA引入了名为FVL MoE的力感知MoE模块,专为在动作规划过程中,将视觉-语言表征与来自具身交互的实时力反馈进行模态和阶段感知融合而设计
通过门控机制,FVLMoE可针对专家子网络动态计算路由权重,每个子网络专注于任务执行阶段中的不同模态
ForceVLA通过根据高层任务指令和低层交互反馈自适应激活这些专家,从而捕捉物理交互过程中微妙但关键的、依赖阶段的变化,并生成精确、阶段对齐且具备力感知的动作分块
1.1.2 相关工作
第一,对于机器人VLA领域
- 近期在视觉-语言-动作(VLA)模型方面的研究,主要致力于利用大规模多模态预训练,实现机器人策略在不同任务和实体间的泛化能力[4,6,9,15,16,17,18,19,20]。这些模型通常通过端到端学习,将视觉和语言输入映射为低级控制信号
基于流的架构(如π0[10,21])将预训练的视觉-语言编码器与高速动作解码器集成,实现高频率输出 - 其他研究则引入了推理机制[22,23,24,25]、动作空间压缩或三维点云输入[26],以提升指令理解和任务执行能力
基于扩散的模型[5,27,28,29,30]通过引入随机生成,能够实现多样化、长时序行为,但通常伴随较高的训练和推理成本
尽管取得了诸多进展,大多数VLA方法仍然局限于视觉和语言输入,在需要触觉反馈的接触丰富或遮挡操作场景下,其效果有限
第二,对于接触丰富的操作领域
- 传统的仅依赖视觉的方法在需要细粒度反馈的动态交互中表现不佳。为了解决这一问题,近期的研究整合了力觉传感[31,32,33,34],从而提升了运动的稳定性和精度
Xie 等人[35,13]对力反馈在机器人控制中的作用进行了基础性研究 - 触觉传感同样成为一种强大的感知方式:TLA[36]和Tac-Man[37]在精细操作和关节任务中展现了更优的性能
- 多模态融合方法[38,39]在复杂环境中显示出潜力,然而当前的方法往往局限于静态模态融合,缺乏动态路由或统一的建模框架。此外,鲜有研究在现实世界的接触丰富场景下评估跨任务的泛化能力
第三,对于MoE 架构相关工作
- 混合专家(Mixture-of-Experts, MoE)架构通过激活稀疏的专家子网络,提高了模型的可扩展性和效率 [40,41,42,43,44]
后续研究 [45] 提升了 MoE 的训练稳定性和任务迁移能力
在多模态领域,LIMOE [46] 将稀疏专家层集成到视觉-语言联合学习中 - 近期在机器人领域的应用 [47,29] 将 MoE 层引入 VLA 模型,以增强策略泛化和适应能力。然而,这些方法在很大程度上忽略了对力觉/触觉模态的显式建模,并且缺乏在高接触任务中跨多模态信号进行动态路由的机制
1.1.3 预备知识
首先是问题表述
下图图2展示了机器人操作任务的设置
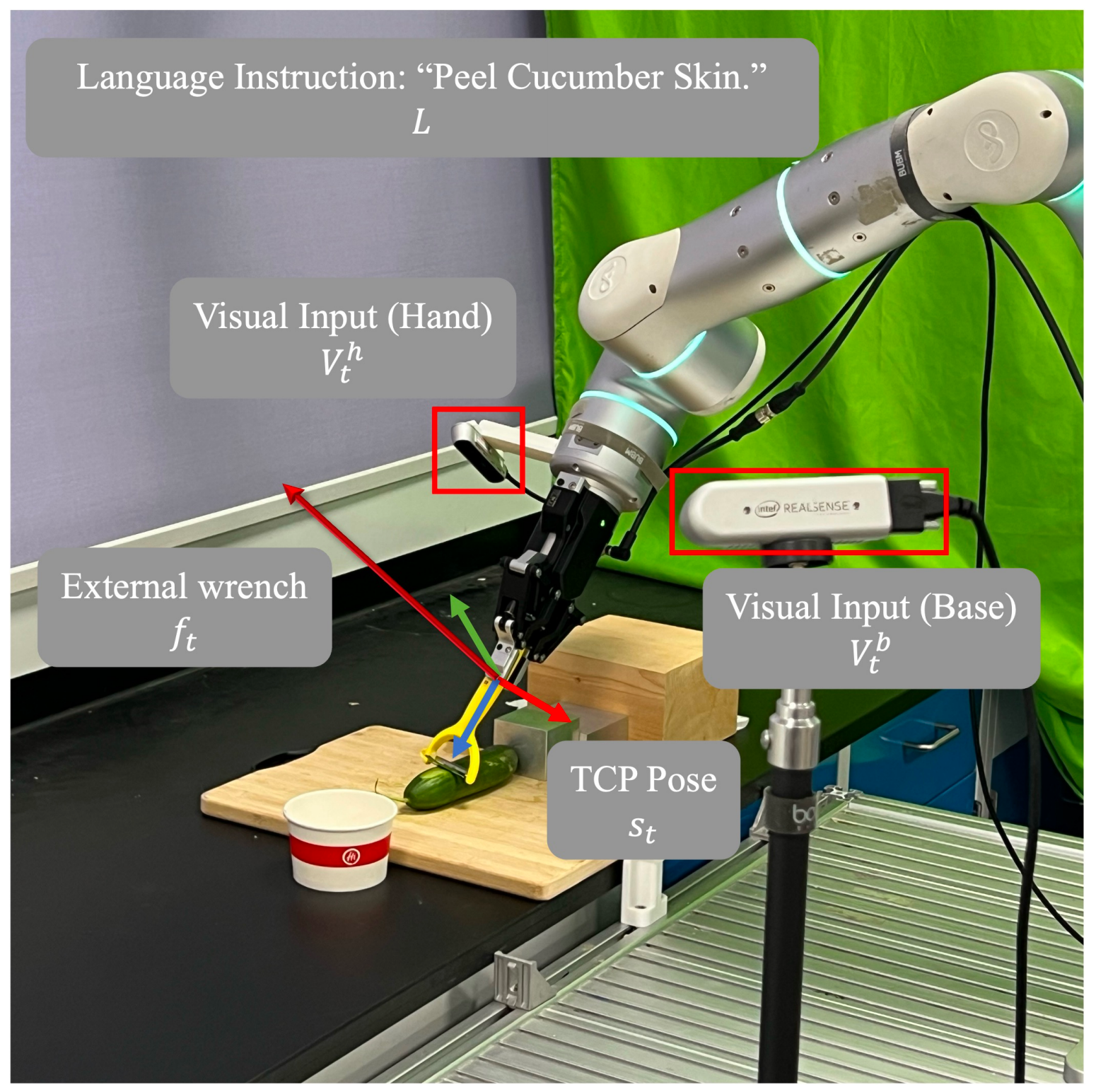
- 在时间步
,机器人的观测包括
底座和手部的视觉输入
和
这些数据被收集统称为 - 给定语言指令
,目标是学习一个端到端的策略
,该策略输出低层次、可执行的动作片段
[10],以最大化完成高接触任务的可能性
其中,是由TCP位姿与夹爪宽度拼接而成的向量
TCP位置由笛卡尔坐标表示,姿态由欧拉角
表示。
是作用在TCP上的外部力矩估计,并以世界坐标系表示,包括
的力和
其次,对于MoE 架构
作者选择了 Mixture-of-专家(MoE) [44, 42] 作为他们的融合层。其核心思想是将不同模态分配给)一组更大但更小型、专门化的” 专家” 子网络,对于任意给定的输入token,只有其中一部分被激活
- 一个MoE 层通常由一组N 个专家网络组成,记为
,以及一个门控网络(也称为路由器),记为
该网络接收一个输入token,并动态决定由
个专家中的哪些来处理它
在流行的稀疏MoE 实现中,对于输入token会生成分数或logits
——用于从总共N 个专家中选择一个较小的k 个专家子集(通常k = 1 或k = 2,其中k ≪N) - 输入的token x 仅被路由到这
个激活的专家。这些激活专家的输出
随后被聚合,通常通过加权和实现,其中权重
也由门控网络生成
MoE 层的最终输出可以表示为:
其中表示门控网络为输入
1.2 ForceVLA
ForceVLA 是一种面向接触密集型操作的端到端多模态机器人策略。其流程如图 3 所示
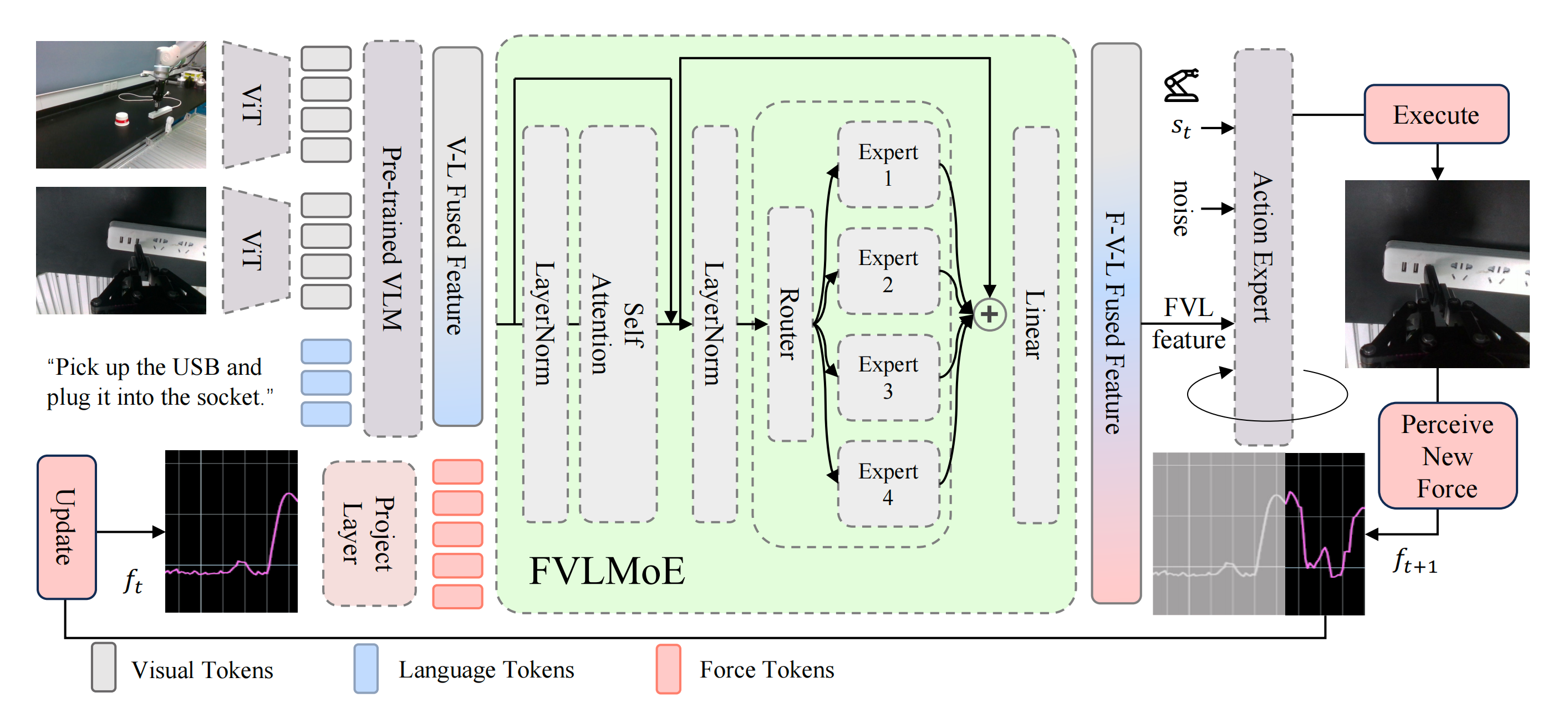
- 在π0 框架 [10] 的基础上,ForceVLA 融合了视觉、语言、本体感知以及六轴力反馈,并通过条件流匹配模型 [48,49] 生成动作
来自多个 RGB 摄像头的视觉输入和任务指令由基于 SigLIP 的视觉-语言模型「基于 PaliGemma [11]」编码为上下文嵌入
这些嵌入与本体感知和力觉信息结合,共同作为条件,指导迭代去噪过程以预测动作轨迹 - FVLMoE是实现高效力整合的核心模块。力传感读数被线性投射为专用的token,并通过专家混合(MoE)模块与视觉-语言嵌入融合
受MoE在多任务和模态特定学习方面优势的启发[51,46],FVLMoE能够自适应地路由并处理多模态输入。其输出为流模型提供了丰富的引导信号,使ForceVLA能够更精确且更具鲁棒性地应对微妙的接触动态以及视觉上模糊的场景
// 待更