迈向具身智体人工智能:LLM 和 VLM 驱动的机器人自主性和交互性
25年8月来自芬兰 Turku 大学、瑞士应用科学大学和 skya.ai 公司的论文“Towards Embodied Agentic AI: Review and Classification of LLM- and VLM-Driven Robot Autonomy and Interaction”。
基础模型,包括大语言模型 (LLM) 和视觉-语言模型 (VLM),最近为机器人自主和人机界面带来了新方法。与此同时,视觉-语言-动作模型 (VLA) 或大型行为模型 (BLM) 正在提高机器人系统的灵活性和能力。这篇综述论文重点关注这些领域向智体应用和架构的发展。这包括探索 GPT 风格工具接口的初步努力,以及更复杂的系统,其中 AI 智体是协调器、规划器、感知器或通用接口。这种智体架构允许机器人推理自然语言指令、调用 API、规划任务序列或协助操作和诊断。由于该领域的快速发展性质,还重点介绍社区驱动项目、ROS 包和工业框架。
已有多项综述探讨基础模型与机器人技术的更广泛交叉领域 [1]–[5],重点关注多模态架构及其组件,主要强调多模态模型在机器人决策和高级规划中的普遍应用,以及用于特定领域(如操控)低级控制的端到端学习框架。然而,随着近年来具身和通用型 AI 智体的兴起,迄今为止尚无综述研究过 AI 智体与现有控制软件、库或中间件交互的设计模式。此外,许多实用系统(GitHub 托管的项目、ROS 软件包或初创原型)尽管与现实世界的相关性和影响力日益增强,但在文献中仍然鲜有提及。
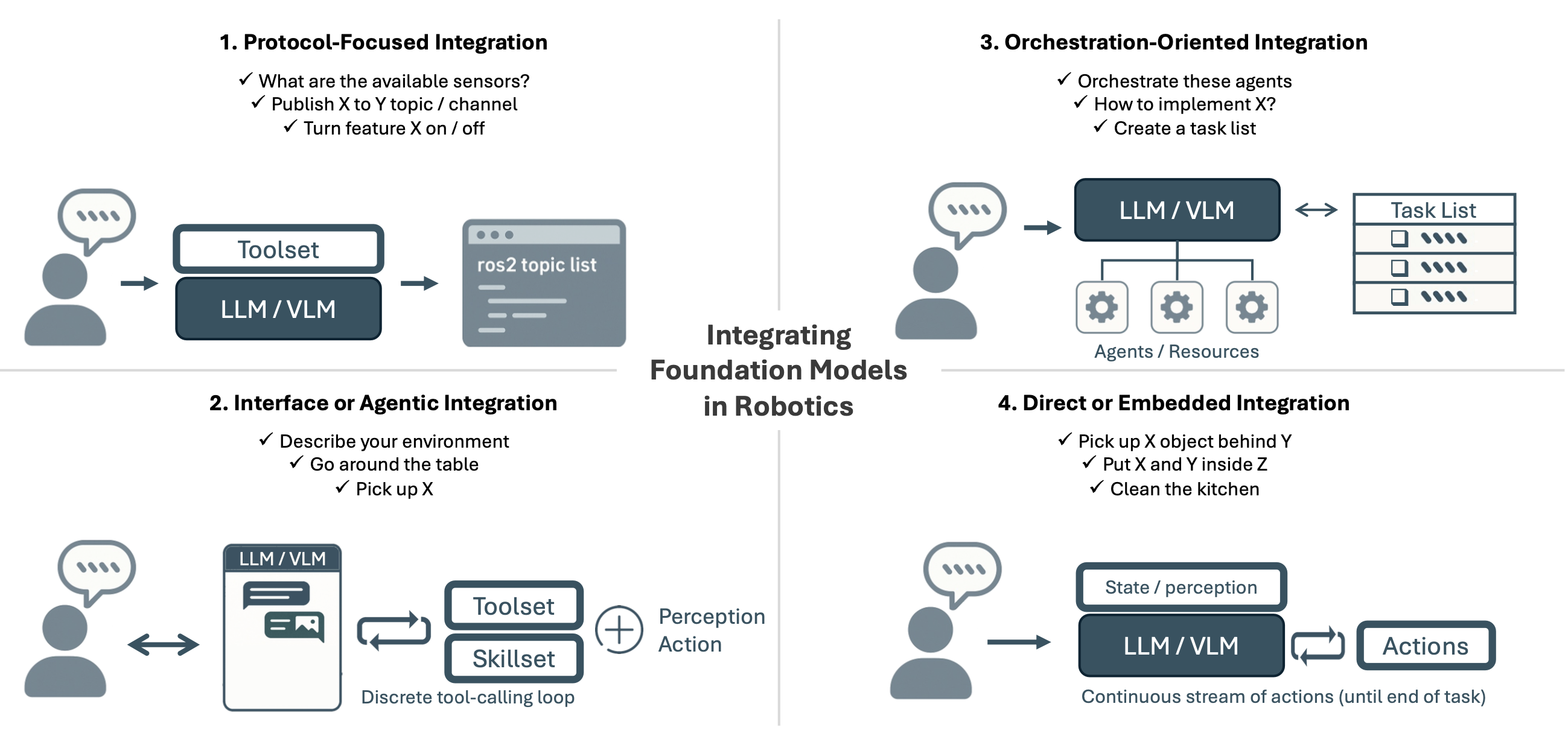
本综述旨在填补这一空白。其回顾近期学术界和社区推动的机器人领域人工智能智体研究,重点关注将 LLM 和 VLM 定位为智能中介而非直接策略生成器的架构。本文提出一种分类法,根据大语言或基础模型集成到机器人系统的方式对迄今为止的研究工作进行分类,主要有四个方向,如图所示:聚焦协议、接口或者智体、面向编排、和直接或者嵌入等四个。
具身智体AI
具身机器人智体的概念于 20 世纪 80 年代末提出,其基础是智能行为源于系统的物理具身及其与环境的持续感觉运动交互 [17]。这为早期端到端神经模型奠定了基础,这些模型将感知直接映射到动作,从而实现了无需显式符号推理的自主控制 [18]–[20]。LLM 的出现显著扩展了自主智体的功能范围,使其从范围狭窄的规则驱动系统转变为更灵活的实体,能够进行泛化、情境推理和自适应行为 [21]。在 ChatGPT 时代之前,“代码即策略”(CaP)[6] 引入了机器人可执行语言模型生成的程序 (LMP),通过代码生成进行间接工具调用,实现了反应式和基于视觉的控制。
OpenAI 于 2022 年 11 月发布的 ChatGPT 标志着具身智体人工智能 (embodied agentic AI) 发展轨迹的重大进展,催化了 LLM 作为机器人系统基础组件的广泛应用。尽管 ROS 长期以来一直是机器人软件集成的标准框架,但最初将 LLM 用作自主智体的努力主要针对的是兼容 ROS 平台。到 2023 年,早期原型开始明确地将 LLM 与机器人框架集成,主要侧重于 LLM 与 ROS 之间的协议集成和双向通信接口。
该领域的早期探索主要集中在 ROS 2 的自然语言接口上,包括 ros2ai [22](一个使用 LLM 增强 ROS 2 命令行接口的扩展)和 ROScribe [23](一个使用 LLM 从高级描述生成 ROS 代码库的工具)(例如,用户描述所需的 ROS 图(传感器、主题和功能),ROScribe 将输出 ROS 节点的 Python 代码并启动文件来实现该规范)。此外,ROS-LLM 框架 [24] 被提出用于实现具身智能应用。它提供一个模板,用于在配置文件中定义机器人的 API,然后处理提示工程并调用 OpenAI API,有效地充当可定制的智体。同时,微软的 ChatGPT for Robotics [7] 引入一种基于 LLM 的机器人控制和编程的模块化方法,为每个机器人定义特定的高级 API,利用提示工程和预定义函数库,实现跨不同任务和模拟环境的自然语言控制。在此阶段,大多数实现都采用聊天机器人风格的设计,部署 LLM 来解释自由格式的文本输入并生成适用于通用机器人集成的命令。
基于这些进步,2024 年标志着机器人和 VLA 系统专用 LLM 接口的革命性转变,开启了机器人控制系统前所未有的泛化和语义推理能力。这些框架使智体能够处理开放式自然语言指令,将其基于视觉感知,并执行相应的动作 [14]。一项显著的突破是 RT-2 [8],它通过在机器人轨迹数据和互联网规模的视觉语言任务上对预训练的 VLM 进行联合微调,引入了一个 VLA 框架。π0 [12] 通过流匹配的扩散策略引入实时、连续控制,将感知、推理和运动生成统一在一个可微分的框架中,从而推动了该领域的发展。
与此同时,ROSA(机器人操作系统智体)[9]、RAI(机器人人工智能智体)[10]和 BUMBLE [11] 等智体中间件框架应运而生,它们弥合了基于 LLM 的推理与传统机器人中间件之间的差距,以追求具身人工智能。
ROSA 最初于 2023 年底开源,通过实现基于 LangChain 框架和 ReAct(推理和行动)智体范式构建的 LLM 智体,代表了人工智能驱动机器人控制的重大进步。其核心创新是将 ROS 操作抽象为工具支持的 Python 函数——包括列出可用节点、读取传感器数据、移动关节等。这使得 ROSA 能够将自然语言命令转换为经过验证的机器人动作。ROSA 还嵌入了安全机制,例如参数验证、约束强制执行以及关键操作的可选人工批准。其中 [10] 在异构平台上演示 ROSA,包括 JPL 的 NeBula-Spot 四足机器人和 NVIDIA Isaac Sim 环境。然而,其架构仍然与基于 ROS 的中间件紧密耦合,限制与非 ROS 系统的互操作性,并限制其在更广泛场景中的部署。
RAI 是该领域的另一种方法,它是一个灵活的具身多智体框架,旨在将LLM推理与机器人系统(例如ROS2)集成。其架构引入了一种分布式范式,其中专门的 LLM 智体(包括感知模块、任务规划器、运动控制器和安全监视器)通过明确定义的角色进行协作,以实现并发、实时任务执行,同时保持系统安全性和可靠性。该框架的核心组件(智体、连接器和工具)提供多模型感知和驱动、通过向量存储进行检索增强生成(RAG)以及预配置的智体类型(语音、对话、基于状态)的集成功能。该框架在动态环境中表现出色,具有在线重新规划和故障恢复等功能。已在物理(Husarion ROSBot XL)和模拟(拖拉机和操作器)平台上得到验证。然而,该框架受到基于 LLM 智体有限的空间推理和不可靠的自我校正限制,这反复导致无法理解物理边界、物体交互和任务完成。
BUMBLE(建筑范围的移动操控)是近期的另一项成果,它使用基于 VLM 的统一框架进行建筑范围的移动操控。它集成开放世界感知、双层记忆系统和广泛的运动技能,能够在更广阔的空间和时间范围内进行有效操作。与 ROSA 等严重依赖基于 ROS 中间件集成的框架不同,BUMBLE 通过使用预定义的地标图像,与导航系统实现更紧密的耦合。虽然这提供高效而精确的导航,但也带来一些限制,例如需要事先手动采集地标图像。尽管如此,BUMBLE 将感知和行动能力相结合,在应对现实世界环境的复杂性方面取得了重大进展。
另一个值得注意的进展是 MCP(模型上下文协议)服务器的概念,它推动了新功能的智体使用以及与现有工具(例如 Anthropic 的 Claude 或像 Cursor 这样的 AI 驱动代码编辑器)的快速集成。到目前为止,它们在机器人技术领域的渗透是由社区驱动的,GitHub 上已有多个公开项目。例如,ROS-MCP 库 [25] 可连接到 Claude 等 AI 助手,并支持与已安装的 ROS 2 应用程序进行交互。这些功能包括:(i) 启动 UI 应用程序,包括 Gazebo 模拟器和 RViz 可视化工具;(ii) ROS 资源管理(主题、节点);(iii) ROS 系统交互(发布到主题、调用服务、发送行动目标);(iv) 环境调试;以及 (v) 进程管理(例如,清理正在运行的 ROS2 进程)。这代表着与提供完整应用程序系统的其他框架(例如 ROSA 和 RAI)的范式转变,MCP 服务器采用基于插件的方法,需要标准的 AI 助手应用程序。另一个例子是 ros-mcp-server [25],它使用 rosbridge 通过 WebSockets 连接到 ROS 1 或 ROS 2 系统,并包含针对里程计和速度控制主题的特定接口。利用 Claude 等助手的优势在于,它们已经拥有其他内置工具,例如 Web 搜索,并且能够在沙盒环境中内部运行代码。这为无需额外实现的更高级行为提供了可能性。
初创公司 OpenMind [16] 推动了机器人领域智体 AI 的最终也是较新的开源框架。OpenMind 的 OM1 引入一个模块化、与硬件无关的 AI 运行时,旨在用于各种机器人平台。与 ROSA 和 RAI 等早期主要针对与基于 ROS 的中间件集成的框架相比,OM1 凭借其去中心化的 FABRIC 协调协议脱颖而出。 FABRIC 实现异构机器人系统之间的安全身份管理和互操作性,这与早期系统中常见的集中式编排有所不同。OM1 采用基于 Python 的配置,并融入类似于 RT-2 等 VLA 驱动系统的感知-行动循环,但它尤其强调去中心化。总而言之,OM1 代表着迈向更具协作性和灵活性的机器人生态系统的一步。
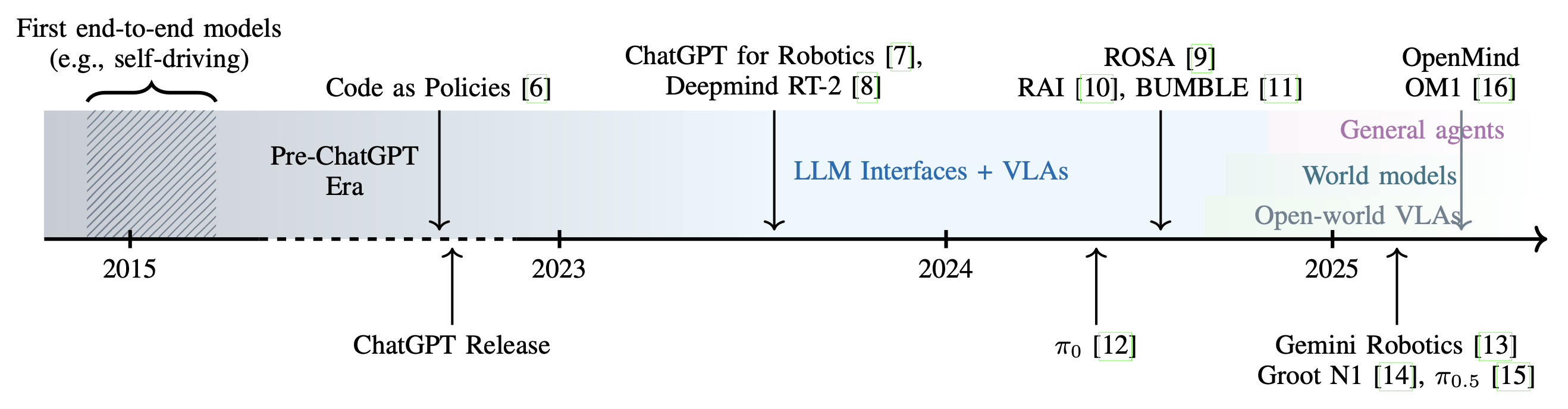
如图所示以时间轴的形式展现过去三年中一些重要的里程碑和最具代表性的研究成果。图的上半部分重点介绍面向智体的方法,下半部分则列出塑造该领域进步的其他相关模型。
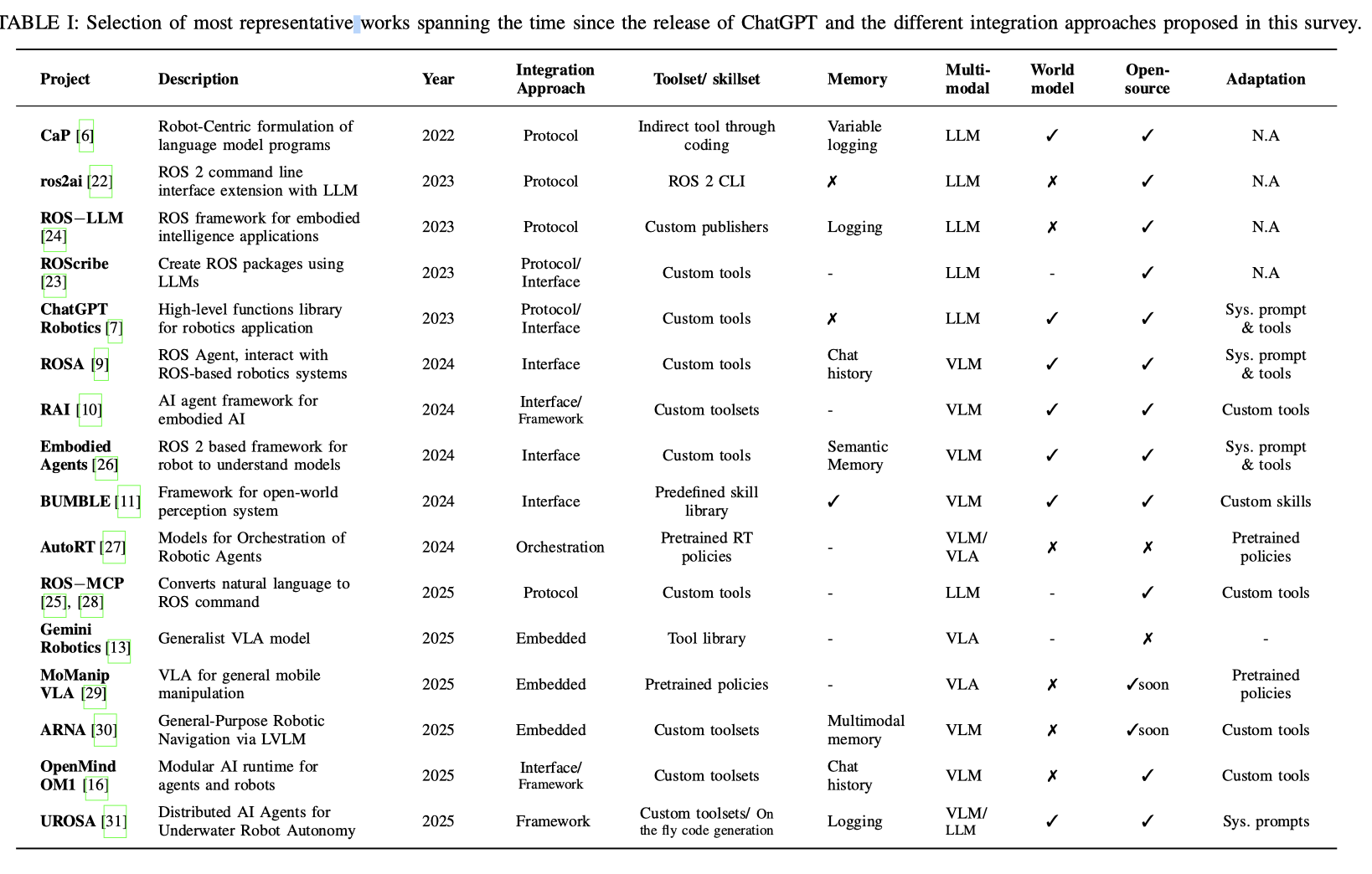
下面的表提供更全面的研究成果列表,包括学术论文和社区项目。

对于近期集成 LLM 的机器人系统,许多系统之间的差异并非在于它们执行的任务,而在于它们如何构建决策、控制和模块化。为了捕捉这些架构上的区别,根据智体的功能设计而非应用领域对其进行分组。这种视角能够更清晰地比较不同系统如何推理、如何排序动作、如何调用工具或技能以及如何与低级控制器交互。如图所示概述了这些智体类型。
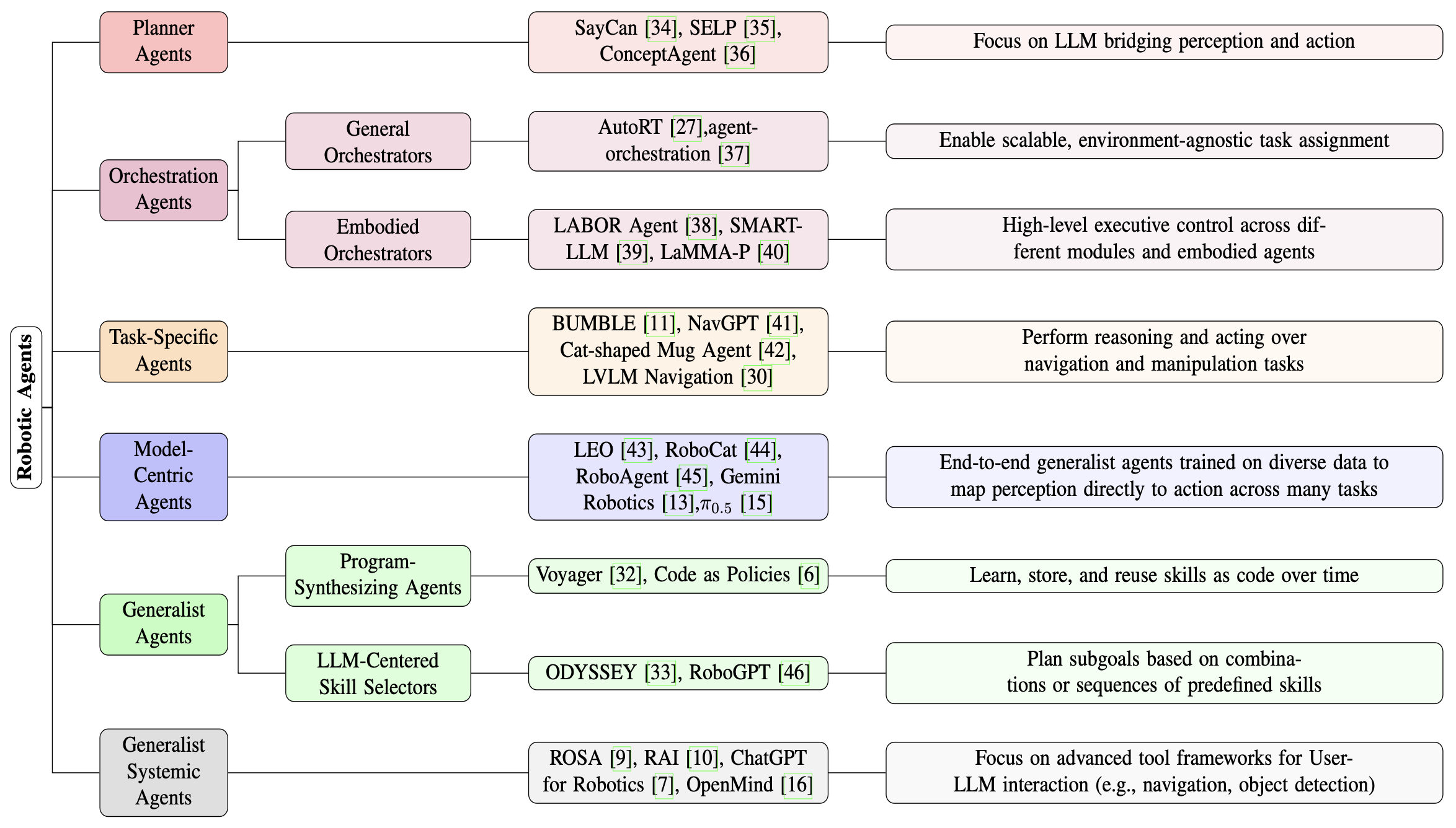
- 规划智体:在此范式中,LLM 通常通过选择或排序离散技能来为机器人规划一系列动作。LLM 不直接控制执行器;而是输出由低级控制器执行的高级规划。这种设计使 LLM 能够专注于推理和分解,同时通过独立的模块确保安全性和可行性。
与持续与感知、记忆和工具 API 实时交互的编排智体相比,规划智体会预先生成规划或迭代地对其进行改进,在执行过程中 API 交互有限。编排智体充当主动的运行时管理器,而规划智体则专注于任务结构化,将执行监控留给其他组件。
2)编排智体:随着机器人系统日益模块化且技能丰富,一类新智体应运而生。其中,LLM 不再充当单个机器人的规划器,而是充当协调器,管理多种技能、组件甚至智体之间的交互。这些系统将 LLM 视为中央控制器,负责解释高级任务指令,并将任务委托给可执行的子系统或外部工具。
在这种情况下,LLM 本身并不执行物理动作,也不仅仅规划单个序列。相反,它执行决策级控制,例如调用哪种技能、哪个机器人应该行动,或者何时在行为之间切换。这种架构实现了模块化、可扩展性和适应性,尤其是在多智体或高技能数量的环境中。
在分类中,编排智体主要指处理高级任务规划和分配的系统,它们要么协调单个机器人内的多个内部智体 [37],要么在多个实体智体(即多个机器人)之间分配任务 [39]。虽然它们依赖于预定义的功能,但编排逻辑仍然保持灵活性,能够自适应地响应新的目标、环境或智体配置组合。
-
任务特定智体:任务特定智体旨在解决定义狭窄的问题,这些问题过去依赖于专门的训练数据或特定领域的策略。然而,最近的研究探索大型语言和视觉-语言模型如何通过针对特定目标启用零样本推理或动态规划来提升特定任务的性能。
-
以模型为中心的智体:传统的 VLA 模型通常需要单独的组件来实现感知、推理和动作,并且每个组件都需要独立训练或调整。而以模型为中心的智体则采用统一的架构,由单个模型负责处理多模态输入(例如图像、语言、本体感觉)并直接生成动作输出。例如,LEO [43] 利用仅包含解码器的大型语言模型,将二维自我中心视觉、三维点云和文本整合在一起,以实现 3D 环境中的指令遵循和物理交互;RoboCat [44] 使用目标条件决策transformer,通过大规模训练和自我改进,在机器人具身和任务之间进行泛化;RoboAgent [45] 则通过在统一策略模型中进行语义增强和动作分块,实现高数据效率和广泛的任务泛化。
5)通用智体:这类智体反映机器人技术向基础架构转型的趋势,其中集中式推理模型(通常是 LLM 或多模态transformer)可以灵活地与基础的可执行组件进行交互。尽管每个系统在工具的创建、选择或执行方式上可能有所不同,但它们拥有一个共同的理念:在特定任务的专用能力之上构建通用推理。
通用智体通常专为多任务、多领域操作而构建。它们的架构在设计上采用模块化:高级模型解释目标,将其分解为子任务,并将执行委托给一组低级模块,这些模块通常是预定义的技能、学习到的动作模型或自定义工具。这些执行模块可以是静态的(预训练的),也可以是动态的(在部署期间创建和扩展)。
这些智体的独特之处不仅在于它们的任务广度,还在于它们能够通过模块化推理和灵活的技能集成进行跨任务泛化——这种架构模式对于可扩展机器人智能的未来日益重要。
6)通用系统智体:通用系统智体专注于构建可重用的模块化框架,以简化基于LLM的机器人系统的开发和编排。这些方法(例如ROSA和RAI)并非针对特定任务,而是强调系统级设计,其中感知、推理和动作模块清晰分离且易于组合。许多此类智体基于通用LLM框架(例如LangChain)构建,从而支持灵活的内存、工具集成和对话界面。值得注意的是,此类智体与智体框架范式紧密重叠,因为这些系统依赖于结构化接口,LLM可以通过这些接口调用机器人功能。