01数据结构-十字链表和多重邻接表
01数据结构-十字链表和多重邻接表
- 前言
- 1.十字链表
- 1.1十字链表逻辑分析
- 1.2十字链表代码实现
- 2.多重邻接表
- 2.1多重邻接表逻辑实现
- 2.2多重邻接表代码实现
前言
邻接矩阵:很全面包括带权/无权,有向/无向都使用,但是对于顶点较多边很少的稀疏图来讲,空间利用率低。所以人们提出了邻接表
邻接表:主要用于存有向图,正邻接表计算出度简单,但计算入度难,逆邻接表计算入度简单,但计算出度难,要想计算入度出度都简单,人们就把正邻接表和逆邻接表结合起来了,就有了我们今天讲的十字链表
十字链表:主要用于存有向图,计算出度,入度简单,代码量可能会多一点
邻接多重表:主要用于存无向图,删除和插入一条边(如果我们用邻接表存无向图图1,要删除V1和V2这条边,我们是看作V1可以出度到V2,V2可以出度到V1,所以删除的时候我们要删除两次,但是用邻接多重表我们只用删除一次,只是这一次要把V1和V2关系理清,后面我们会讲到)
由上可以看到凡是带表字的都是边利用了链表的方法存储,带矩阵的边利用了数组的方式存储。
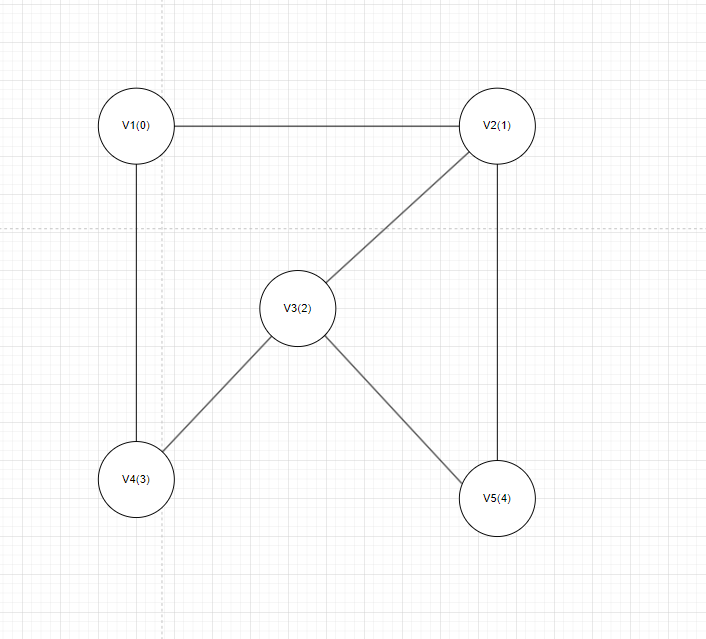
图1
1.十字链表
1.1十字链表逻辑分析
图的十字链表法结构定义:
十字链表(Orthogonal List)是一种用于存储有向图和有向网的链式数据结构,它结合了邻接表和逆邻接表的优点,能够高效地处理顶点的出度和入度查询。
基本概念:
十字链表通过将邻接表和逆邻接表结合起来,使得同一条弧在两种链表中共享同一个结点,从而节省存储空间并提高操作效率。在有向图的十字链表表示中,每条弧对应一个弧结点,每个顶点对应一个顶点结点。
如图2:
定义节点结构(顶点结构):有三个域:顶点信息,如顶点名称或编号,firstIn指向以该顶点为弧头的第一条弧(入边表头指针),firstOut指向以该顶点为弧尾的第一条弧(出边表头指针)
定义弧结构(边结构):有四个域:弧尾顶点在顶点数组中的位置(索引),指向弧尾相同的下一条弧(出边链表指针),弧头顶点在顶点数组中的位置(索引),指向弧头相同的下一条弧(入边链表指针)。
其实很简单,这就相当于两条链表,一条是顶点的出度链表,一条是顶点的入度链表,由上一篇《01数据结构-图的邻接表的深搜和广搜代码实现》的基础很容易理解
先来看V0,V0有一条出到V3的边,于是顶点V0的firstOut指向以该顶点为弧尾的第一条弧,这条弧的head是V3,因为只有一条出度边,没有指向弧尾相同的下一条弧了,所以把这条弧的tNext设为NULL;由于是V0出度到V3,反过来看就是V3的入度,所以操作V3的firstIn指向以该顶点为弧头的第一条弧,这条弧的head是V3,tail是0,由于V3只有一条入度边,所以把这条弧的hNext设为NULL。V3没有初出度,把V3的firstOut设为NULL。
再来看V1,V1可以出度到V0,V0也可以入度到V1,由于V1有两条入度边,所以以V1为tail,V0为head的那条弧的hNext还应该指向以V2为tail,V0为head的那条弧,然后把以V2为tail,V0为head的这条弧的hNext设为NULL。V1还可以出度到V2,所以以V1为tail,V0为head的那条弧的tNext还要指向以V1为tail,V2为head的弧,然后把以V1为tail,V2为head的弧的tNext设为NULL。
同样的道理分析V2是一样,我就不赘述了。
总结,在写代码接口add的时候,出度和入度时的顶点的firstOut,firstIn都要进行操作,然后如果你想一直计算出度就一直操作弧的tNext,如果你想一直计算入度就一直操作弧的hNext。
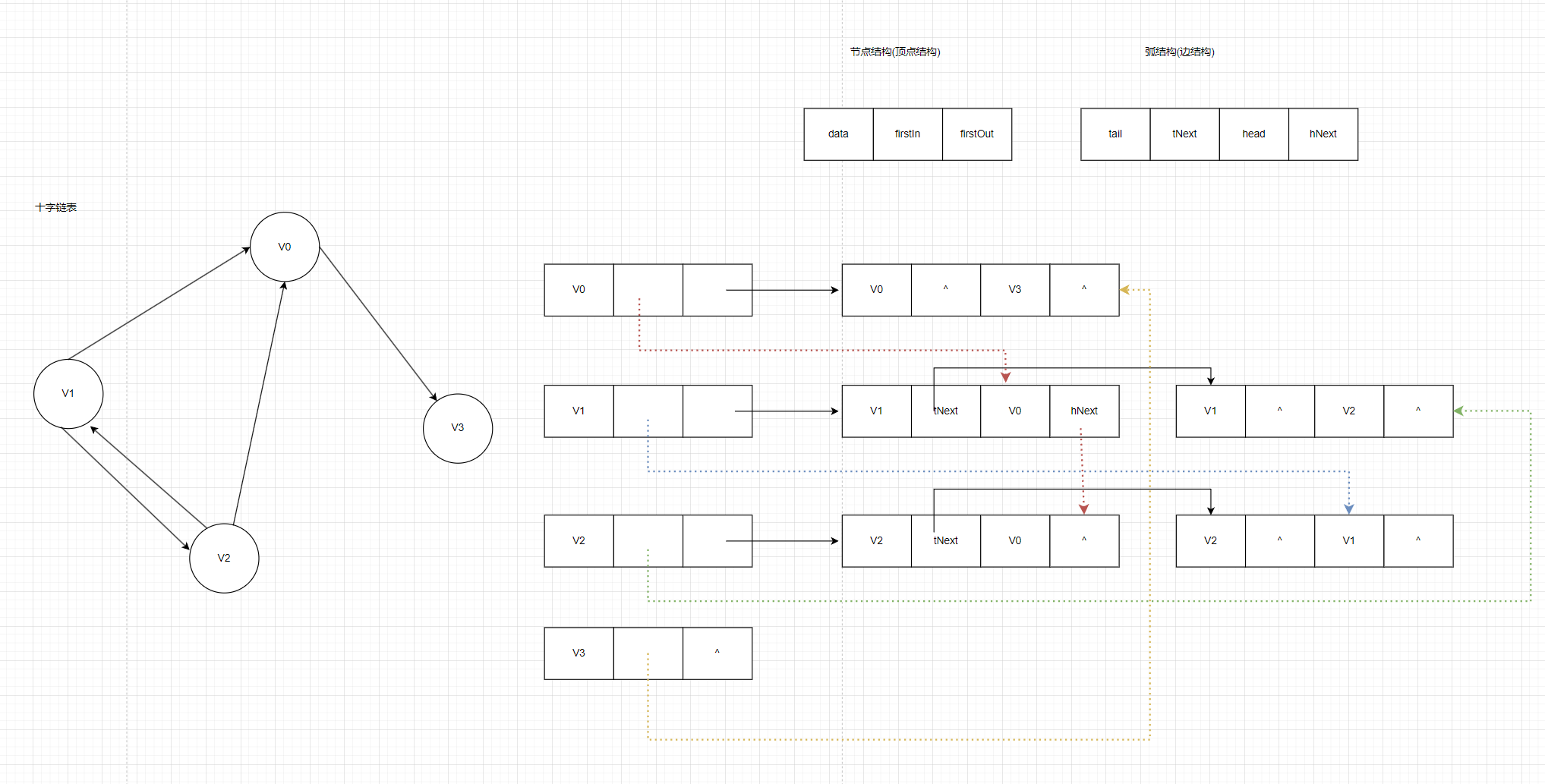
图2
1.2十字链表代码实现
十字链表数据结构的定义:
// 十字链表的边结构
typedef struct arcBox {int tailVertex; // 弧尾编号,tailVertex作为顶点的出度信息struct arcBox *tailNext; // 下一个以tailVertex作为弧尾的下一条边int headVertex; // 弧头编号,以headVertex作为顶点的入度信息struct arcBox *headNext; // 下一个以headVertex作为弧头的下一条边int weight; // 弧权值
} ArcBox;// 十字链表的顶点结构
typedef struct {int no;const char *show;ArcBox *firstIn; // 该节点的入度ArcBox *firstOut; // 该节点的出度
} CrossVertex;// 利用十字链表的结构实现图的结构
typedef struct {CrossVertex *nodes; //顶点集int numVertex; //顶点总数int numEdge; //边总数
}CrossGraph;和前面讲的一样,只是用代码表示了出来
创建十字链表:CrossGraph * createCrossGraph(int n) ;
CrossGraph * createCrossGraph(int n) {CrossGraph * graph = malloc(sizeof(CrossGraph));if (graph==NULL) {fprintf(stderr, "g malloc error\n");return NULL;}graph->nodes=malloc(sizeof(CrossVertex)*n);if (graph->nodes == NULL) {free(graph);return NULL;}graph->numVertex=n;graph->numEdge=0;return graph;
}
初始化十字链表:
void initCrossGraph(CrossGraph *graph, const char *names[], int num) {for (int i = 0; i < num; ++i) {graph->nodes[i].show=names[i];graph->nodes[i].firstIn=graph->nodes[i].firstOut=NULL;graph->nodes[i].no=i;}
}增加边:void addCrossArc(CrossGraph *graph, int tail, int head, int w);
void addCrossArc(CrossGraph *graph, int tail, int head, int w) {ArcBox *arc=malloc(sizeof(ArcBox));if (arc==NULL) {fprintf(stderr, "arc malloc error\n");return;}arc->weight=w;// 从出度关系上进入插入(头插法)arc->tailVertex = tail;arc->tailNext = graph->nodes[tail].firstOut;graph->nodes[tail].firstOut = arc;// 从入度关系上进入插入(头插法)arc->headVertex = head;arc->headNext = graph->nodes[head].firstIn;graph->nodes[head].firstIn = arc;graph->numEdge++;
}这里和前面《01数据结构-图的邻接表的深搜和广搜代码实现》中边的添加一样,只不过要从两个角度添加,一个出度一个入度。
顶点的出度,入度的计算:
int inDegreeCrossGraph(const CrossGraph* graph, int no) {int count = 0;ArcBox *arc = graph->nodes[no].firstIn;while (arc) {count++;arc = arc->headNext;}return count;
}int outDegreeCrossGraph(const CrossGraph* graph, int no) {int count = 0;ArcBox *arc = graph->nodes[no].firstOut;while (arc) {count++;arc = arc->tailNext;}return count;
}
不断地往后走,走一个count++,直到为空。
释放图:void releaseCrossGraph(CrossGraph* graph);
void releaseCrossGraph(CrossGraph* graph) {int numEdges = 0; //最后释放了多少条边if (graph) {if (graph->nodes) {//从每一个顶点开始free边for (int i = 0; i < graph->numVertex; i++) {ArcBox *box = graph->nodes[i].firstOut;ArcBox *tmp;while (box) {tmp = box;box = box->tailNext;free(tmp);numEdges++;}}printf("released %d edges\n", numEdges);free(graph->nodes);}free(graph);}
}
我们要从每一个顶点开始free边,把边都free完了再free顶点最后free(graph)。
最后来测一下:
#include <stdio.h>
#include <stdlib.h>
#include "crossLinkGraph.h"void setupCrossGraph(CrossGraph *graph) {char *nodeName[] = {"V0", "V1", "V2", "V3"};initCrossGraph(graph, nodeName, 4);addCrossArc(graph, 0, 3, 1);addCrossArc(graph, 1, 0, 1);addCrossArc(graph, 1, 2, 1);addCrossArc(graph, 2, 0, 1);addCrossArc(graph, 2, 1, 1);
}int main() {int n = 4;CrossGraph *graph = createCrossGraph(n);if (graph == NULL) {return -1;}setupCrossGraph(graph);printf("V0的入度:%d\n", inDegreeCrossGraph(graph, 2));printf("V0的出度:%d\n", outDegreeCrossGraph(graph, 2));releaseCrossGraph(graph);return 0;
}结果:
D:\work\DataStruct\cmake-build-debug\03_GraphStruct\CrossLinkGraph.exe
V0的入度:1
V0的出度:2
released 5 edges进程已结束,退出代码为 02.多重邻接表
2.1多重邻接表逻辑实现
邻接多重表(Adjacency Multilist)是一种专门用于存储无向图的链式存储结构,其核心设计目标是解决邻接表中每条边需存储两次的问题,从而提高存储效率并简化边操作(如标记或删除)。以下是其结构定义的详细说明:
1. 顶点结构
数据域(data):存储顶点的信息(如名称、权值等)。
指针域(firstedge):指向该顶点的第一条边的边表结点(EBox),即该顶点边链表的头结点。
2.边结构
每条边的信息通过一个边表结点表示,结点包含以下域:
顶点位置(ivex, jvex):存储该边两个顶点在顶点表中的下标。
链域(ilink, jlink):
ilink:指向下一条依附于顶点ivex的边。
jlink:指向下一条依附于顶点jvex的边。
数据域(info)(可选):存储边的附加信息(如权值)。
如图3:V1和V2有边就把V1顶点结构中的firstEdge指向以V1为iVex,V2为jVex的边(由于多重邻接表存的是无向表,两者也可以交换V1和V2也可以在边中也交换位置),然后看iLink,由于V1和V4 也有边,所以把以V1为iVex,V2为jVex的边中的iLink指向以V1为iVex,V4为jVex的边,由于V1只有这两条边所以把以V1为iVex,V4为jVex的边的iLink设为NULL
因为是无向图,所以顶点V2的firstEdge应该指向以V1为iVex,V2为jVex的边,然后看jLink,由于V2与V5,V3也有边,所以以V1为iVex,V2为jVex的边中的jLink应该指向以V3为iVex,V2为jVex的边,然后以V3为iVex,V2为jVex的边中的jLink应该指向以V5为iVex,V2为jVex的边,然后这条边的jLink指向为NULL
其他顶点也是如此分析,我就不赘述了。
总结:由于是无向图,如果在添加边或者删除边的时候虽然只有一条边但是要从iVex和jVex两头开始找起,需要维护好两边之间的关系
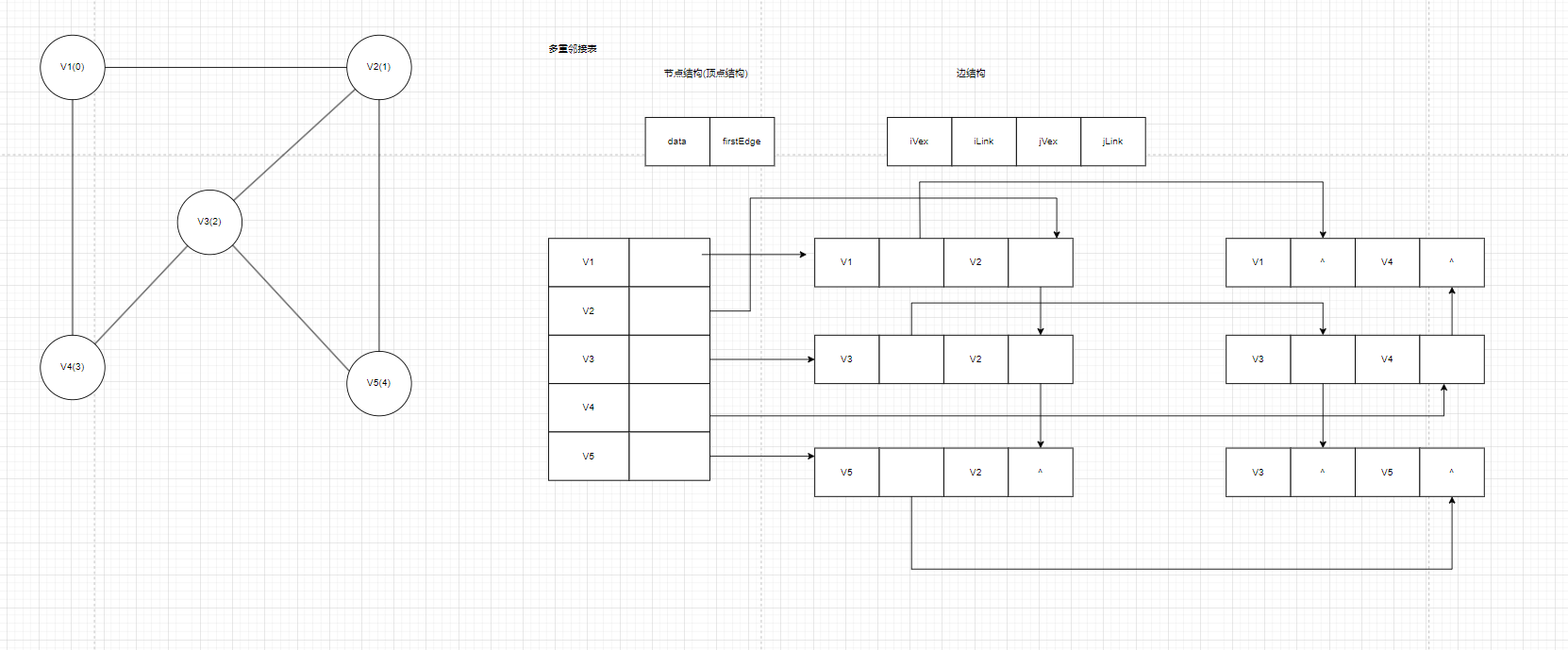
图3
2.2多重邻接表代码实现
多重邻接表和十字链表的部分代码很像,我就不一一讲了,只是把代码放在这里大家自己看。
#ifndef ADJACENCY_MULTI_LIST_H
#define ADJACENCY_MULTI_LIST_H
/* 邻接多重表,适用于无向图* 无向图如果使用邻接表存储,一条边会被处理2次,删除较为复杂 */
// 邻接多重表的边结构
typedef struct amlEdge {int iVex; // 边的顶点i编号struct amlEdge *iNext; // 顶点i编号的下一条边int jVex; // 边的顶点j编号struct amlEdge *jNext; // 顶点j编号的下一条边int weight;int mark; // 是否已经显示图的边
}MultiListEdge;
// 邻接多重表的顶点结构
typedef struct {int no; // 顶点编号char *show; // 顶点显示值MultiListEdge *firstEdge; // 该顶点的边头节点
}MultiListVertex;
// 邻接多重表
typedef struct {MultiListVertex *nodes; // 顶点空间int vertexNum; // 约束顶点空间的数量int edgeNum; // 图中边的个数
}AdjacencyMultiList;AdjacencyMultiList *createMultiList(int n); // 产生n个节点的邻接多重表
void releaseMultiList(AdjacencyMultiList *graph);
void initMultiList(AdjacencyMultiList *graph, int n, char *names[]); // 初始化邻接多重表的顶点值
// 插入边
int insertMultiListEdge(AdjacencyMultiList *graph, int a, int b, int w);
// 显示无向图
void showMultiList(AdjacencyMultiList *graph);
// 删除边
int deleteMultiListEdge(AdjacencyMultiList *graph, int a, int b);
#endif多重邻接表的边结构MultiListEdge中的int mark是用来表示边有没有被访问过,因为是无向边,a能到b,b也能到a,如果没有这个标记位,同一条边会被遍历两边。
创建,初始化邻接多重表,给多重邻接表添加边:
#include <stdio.h>
#include <stdlib.h>
#include "adjacencyMultiList.h"
/* 产生邻接多重表的图 */
AdjacencyMultiList *createMultiList(int n) {AdjacencyMultiList *multiList = malloc(sizeof(AdjacencyMultiList));if (multiList == NULL) {fprintf(stderr, "malloc failed!\n");return NULL;}multiList->nodes = (MultiListVertex *) malloc(sizeof(MultiListVertex) * n);if (multiList->nodes == NULL) {fprintf(stderr, "nodes failed!\n");free(multiList);return NULL;}multiList->vertexNum = n;multiList->edgeNum = 0;return multiList;
}
/* 初始化邻接多重表的顶点信息 */
void initMultiList(AdjacencyMultiList *graph, int n, char *names[]) {for (int i = 0; i < n; ++i) {graph->nodes[i].no = i;graph->nodes[i].show = names[i];graph->nodes[i].firstEdge = NULL;}
}
/* 向邻接多重表中,插入a节点编号和b节点编号的边*/
int insertMultiListEdge(AdjacencyMultiList *graph, int a, int b, int w) {if (a < 0 || b < 0)return -1;// 产生这条边MultiListEdge *edge = malloc(sizeof(MultiListEdge));if (edge == NULL) {fprintf(stderr, "insert malloc failed!\n");return -1;}edge->weight = w;// 处理a节点的连接关系,使用头插法edge->iVex = a;edge->iNext = graph->nodes[a].firstEdge;graph->nodes[a].firstEdge = edge;// 处理b节点的连接关系,使用头插法edge->jVex = b;edge->jNext = graph->nodes[b].firstEdge;graph->nodes[b].firstEdge = edge;graph->edgeNum++;return 0;
}
这里和十字链表的代码逻辑基本一样。
显示无向图:void showMultiList(AdjacencyMultiList *graph);
/* 显示邻接多重表的边关系*/
static void initMark(AdjacencyMultiList *graph) {for (int i = 0; i < graph->vertexNum; ++i) {MultiListEdge *edge = graph->nodes[i].firstEdge;while (edge) {edge->mark = 0;edge = edge->iNext;}}
}
void showMultiList(AdjacencyMultiList *graph) {initMark(graph);for (int i = 0; i < graph->vertexNum; ++i) {MultiListEdge *edge = graph->nodes[i].firstEdge;while (edge && (edge->mark == 0)) { // 边存在,且还未被访问printf("<%s ---- %s>\n", graph->nodes[edge->iVex].show, graph->nodes[edge->jVex].show);edge->mark = 1;edge = edge->iNext;}}
}
在static void initMark(AdjacencyMultiList *graph)中把所有边的标记为设为0,即没有被访问到的。在void showMultiList(AdjacencyMultiList *graph)中开始遍历访问,当边存在,且还未被访问打印出这条边的信息,并把这条边的标记位设位1。
删除边:int deleteMultiListEdge(AdjacencyMultiList *graph, int a, int b);
/* 删除节点编号a到节点编号b的边* 删除边节点,必须找到这个边的前一个节点,* */
int deleteMultiListEdge(AdjacencyMultiList *graph, int a, int b) {// 找到a编号的前一个边节点MultiListEdge *aPreEdge = NULL;MultiListEdge *aCurEdge = graph->nodes[a].firstEdge;while (aCurEdge &&!((aCurEdge->iVex == a && aCurEdge->jVex == b) || (aCurEdge->jVex == a && aCurEdge->iVex == b))) {aPreEdge = aCurEdge;if (aCurEdge->iVex == a) {aCurEdge = aCurEdge->iNext;} else {aCurEdge = aCurEdge->jNext;}}if (aCurEdge == NULL)return -1;// 找到b编号的前一个边结构MultiListEdge *bPreEdge = NULL;MultiListEdge *bCurEdge = graph->nodes[b].firstEdge;while (bCurEdge &&!((bCurEdge->iVex == a && bCurEdge->jVex == b) || (bCurEdge->iVex == b && bCurEdge->jVex == a))) {bPreEdge = bCurEdge;if (bCurEdge->iVex == b) {bCurEdge = bCurEdge->iNext;} else {bCurEdge = bCurEdge->jNext;}}if (bCurEdge == NULL)return -1;if (aPreEdge == NULL) { // 说明头节点指向的边就是要删除的边,处理a编号的边if (aCurEdge->iVex == a) { // 当前边从i出发是agraph->nodes[a].firstEdge = aCurEdge->iNext;} else { // 当前边从j出发是agraph->nodes[a].firstEdge = aCurEdge->jNext;}} else {if (aPreEdge->iVex == a && aCurEdge->iVex == a) { // 是通过i出发找到a节点的aPreEdge->iNext = aCurEdge->iNext;} else if (aPreEdge->iVex == a && aCurEdge->jVex == a){ // 是通过j出发找到a节点的aPreEdge->iNext = aCurEdge->jNext;} else if (aPreEdge->jVex == a && aCurEdge->iVex == a) {aPreEdge->jNext = aCurEdge->iNext;} else {aPreEdge->jNext = aCurEdge->jNext;}}if (bPreEdge == NULL) {if (bCurEdge->iVex == b) {graph->nodes[b].firstEdge = bCurEdge->iNext;} else {graph->nodes[b].firstEdge = bCurEdge->jNext;}} else {if (bPreEdge->iVex == b && bCurEdge->iVex == b) {bPreEdge->iNext = bCurEdge->iNext;} else if (bPreEdge->iVex == b && bCurEdge->jVex == b){bPreEdge->iNext = bCurEdge->jNext;} else if (bPreEdge->jVex == b && bCurEdge->iVex == b) {bPreEdge->jNext = bCurEdge->iNext;} else {bPreEdge->jNext = bCurEdge->jNext;}}free(aCurEdge);graph->edgeNum--;return 0;
}在《01数据结构-单向链表的操作及实现》中要删除链表中的元素,需要定义两个辅助指针一个要找到待删除位置的前一个元素,一个要找到待删除的位置,这里多重邻接表的思路其实和链表删除的思路是一样的,只是由于a可能在iVex也可能在jVex上,我们需要分多种情况讨论。
// 找到a编号的前一个边节点MultiListEdge *aPreEdge = NULL;MultiListEdge *aCurEdge = graph->nodes[a].firstEdge;while (aCurEdge &&!((aCurEdge->iVex == a && aCurEdge->jVex == b) || (aCurEdge->jVex == a && aCurEdge->iVex == b))) {aPreEdge = aCurEdge;if (aCurEdge->iVex == a) {aCurEdge = aCurEdge->iNext;} else {aCurEdge = aCurEdge->jNext;}}if (aCurEdge == NULL)return -1;// 找到b编号的前一个边结构MultiListEdge *bPreEdge = NULL;MultiListEdge *bCurEdge = graph->nodes[b].firstEdge;while (bCurEdge &&!((bCurEdge->iVex == a && bCurEdge->jVex == b) || (bCurEdge->iVex == b && bCurEdge->jVex == a))) {bPreEdge = bCurEdge;if (bCurEdge->iVex == b) {bCurEdge = bCurEdge->iNext;} else {bCurEdge = bCurEdge->jNext;}}if (bCurEdge == NULL)return -1;
上面这个部分就是分别从a和b开始找到a编号的前一个边结构和b编号的前一个边结构,具体循环的逻辑,拿找到a编号的前一个边节点举例,在while循环中循环条件当边存在时并且1。并且当前边不是从a到b或从到a的边时,进入循环体,更新aPreEdge到aCurEdge,如果找到了aCurEdge->iVex == a,根据多重邻接表的性质,一直aCurEdge = aCurEdge->iNext;,就一定会找到ab边的。如果没有找到aCurEdge->iVex == a,那么就aCurEdge = aCurEdge->jNext;如果都没有找到,那就退出。
if (aPreEdge == NULL) { // 说明头节点指向的边就是要删除的边,处理a编号的边if (aCurEdge->iVex == a) { // 当前边从i出发是agraph->nodes[a].firstEdge = aCurEdge->iNext;} else { // 当前边从j出发是agraph->nodes[a].firstEdge = aCurEdge->jNext;}} else {if (aPreEdge->iVex == a && aCurEdge->iVex == a) { // 是通过i出发找到a节点的aPreEdge->iNext = aCurEdge->iNext;} else if (aPreEdge->iVex == a && aCurEdge->jVex == a){ // 是通过j出发找到a节点的aPreEdge->iNext = aCurEdge->jNext;} else if (aPreEdge->jVex == a && aCurEdge->iVex == a) {aPreEdge->jNext = aCurEdge->iNext;} else {aPreEdge->jNext = aCurEdge->jNext;}}if (bPreEdge == NULL) {if (bCurEdge->iVex == b) {graph->nodes[b].firstEdge = bCurEdge->iNext;} else {graph->nodes[b].firstEdge = bCurEdge->jNext;}} else {if (bPreEdge->iVex == b && bCurEdge->iVex == b) {bPreEdge->iNext = bCurEdge->iNext;} else if (bPreEdge->iVex == b && bCurEdge->jVex == b){bPreEdge->iNext = bCurEdge->jNext;} else if (bPreEdge->jVex == b && bCurEdge->iVex == b) {bPreEdge->jNext = bCurEdge->iNext;} else {bPreEdge->jNext = bCurEdge->jNext;}}
上面这段代码用于处理两边的关系了,拿从a边开始找的举例,如果aPreEdge == NULL说明没有进入循环体,头节点指向的边就是要删除的边,处理a编号的边当前边从i出发是a,如果aCurEdge->iVex == a,那就graph->nodes[a].firstEdge = aCurEdge->iNext;,因为 aCurEdge->iNext存的是顶点i编号的下一条边,如果aCurEdge->jVex == a,那就graph->nodes[a].firstEdge = aCurEdge->jNext;,因为 aCurEdge->jNext存的是顶点j编号的下一条边。
如果删除的不是头节点指向的边,由于是无向图,a和b可以在i,j的任意位置,所以处理逻辑的时候需要分四个情况讨论
- aPreEdge->iVex == a && aCurEdge->iVex == a
- aPreEdge->iNext = aCurEdge->iNext;
- aPreEdge->iVex == a && aCurEdge->jVex == a
- aPreEdge->iNext = aCurEdge->jNext;
- aPreEdge->jVex == a && aCurEdge->iVex == a
- aPreEdge->jNext = aCurEdge->iNext;
- aPreEdge->jVex == a && aCurEdge->jVex == a
- aPreEdge->jNext = aCurEdge->jNext;
始终记住如果a是存在的iVex,那么iNext存的是a边的下一条边,如果a是存在的jVex,那么jNext存的是a边的下一条边,想清楚这一点就能知道是aPreEdge的iNext还是aPreEdge的jNex该指向aCurEdge的iNext还是aCurEdge的jNext。
注意此时只处理要a和b的关系,我只说了处理a的时候代码逻辑,处理b的代码逻辑和处理a的时候代码逻辑一样就不做分析。
free(aCurEdge);graph->edgeNum--;return 0;
最后这点直接free掉就行,free的时候只需要free一次,只是处理关系时两边都要处理。
最后free的代码我和删除的代码大同小异,注意的是一条边不能被free两次,所以我只free当i是较小的顶点编号时释放边,避免重复释放
void releaseMultiList(AdjacencyMultiList *graph) {if (graph == NULL) {return;}// 遍历所有节点,释放每条边(确保每条边只被释放一次)for (int i = 0; i < graph->vertexNum; i++) {MultiListEdge *current = graph->nodes[i].firstEdge;// 保存下一个边的指针(当前边释放后就无法访问了)MultiListEdge *next = NULL;while (current != NULL) {if (current->iVex == i) {next = current->iNext;} else {next = current->jNext;}// 只在i是较小的顶点编号时释放边,避免重复释放int otherVex = (current->iVex == i) ? current->jVex : current->iVex;if (i < otherVex) {free(current);}current = next;}// 清空节点的边指针graph->nodes[i].firstEdge = NULL;}// 释放节点数组(如果是动态分配的)if (graph->nodes != NULL) {free(graph->nodes);graph->nodes = NULL;}// 释放图结构本身free(graph);
}最后测一下:
#include <stdio.h>
#include "adjacencyMultiList.h"int main() {int n = 5;char *nodeNames[] = {"V1", "V2", "V3", "V4", "V5"};AdjacencyMultiList *graph = createMultiList(n);if (graph == NULL)return -1;initMultiList(graph, n, nodeNames);insertMultiListEdge(graph, 0, 1, 1);insertMultiListEdge(graph, 0, 3, 1);insertMultiListEdge(graph, 1, 2, 1);insertMultiListEdge(graph, 1, 4, 1);insertMultiListEdge(graph, 2, 3, 1);insertMultiListEdge(graph, 2, 4, 1);deleteMultiListEdge(graph, 1, 4);printf("insert %d edges!\n", graph->edgeNum);showMultiList(graph);releaseMultiList(graph);return 0;
}
结果:
D:\work\DataStruct\cmake-build-debug\03_GraphStruct\AdjacencyMultiList.exe
insert 5 edges!
<V1 ---- V4>
<V1 ---- V2>
<V2 ---- V3>
<V3 ---- V5>
<V3 ---- V4>进程已结束,退出代码为 0
这里的代码大家能写尽量写,其实能看懂就行,后面我们讲算法基本还是用的前面邻接矩阵,邻接表的思路。大概先写这些吧,今天的博客就先写到这,谢谢您的观看。