Nginx(企业高性能web服务器)
一、实验环境
| 名称 | IP |
| webservera | 192.168.159.10 |
二、企业高性能web服务器
1..Web 服务基础介绍
2.Web 服务介绍
a.Apache-经典的 Web 服务端
Apache起初由美国的伊利诺伊大学香槟分校的国家超级计算机应用中心开发
目前经历了两大版本分别是1.X和2.X
其可以通过编译安装实现特定的功能
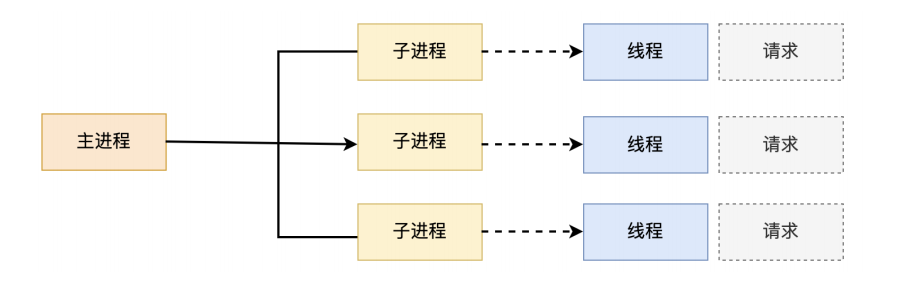
--Apache prefork 模型
- 预派生模式,有一个主控制进程,然后生成多个子进程,使用select模型,最大并发1024
- 每个子进程有一个独立的线程响应用户请求
- 相对比较占用内存,但是比较稳定,可以设置最大和最小进程数
- 是最古老的一种模式,也是最稳定的模式,适用于访问量不是很大的场景
优点:稳定
缺点:每个用户请求需要对应开启一个进程,占用资源较多,并发性差,不适用于高并发场景
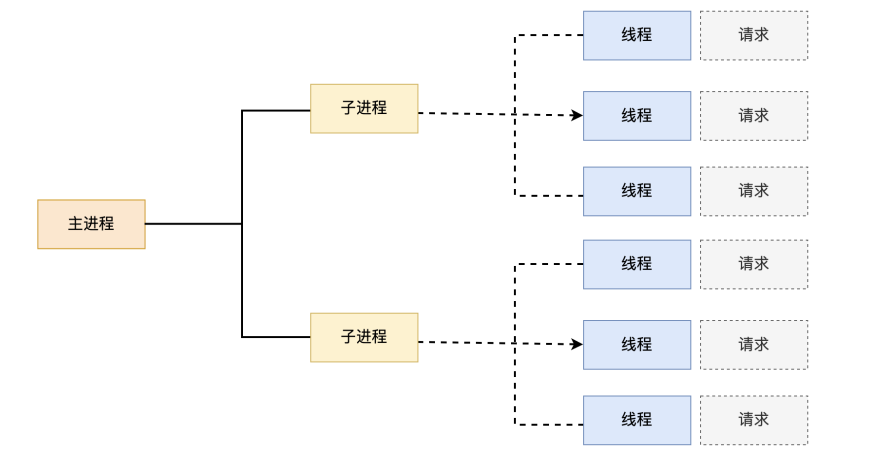
--Apache worker 模型
- 一种多进程和多线程混合的模型
- 有一个控制进程,启动多个子进程
- 每个子进程里面包含固定的线程
- 使用线程程来处理请求
- 当线程不够使用的时候会再启动一个新的子进程,然后在进程里面再启动线程处理请求,
- 由于其使用了线程处理请求,因此可以承受更高的并发
优点:相比prefork 占用的内存较少,可以同时处理更多的请求
缺点:使用keepalive的长连接方式,某个线程会一直被占据,即使没有传输数据,也需要一直等待到超
时才会被释放。如果过多的线程,被这样占据,也会导致在高并发场景下的无服务线程可用(该问题在
prefork模式下,同样会发生)
--Apache event模型
Apache中最新的模式,2012年发布的apache 2.4.X系列正式支持event 模型,属于事件驱动模型(epoll)
每个进程响应多个请求,在现在版本里的已经是稳定可用的模式
它和worker模式很像,最大的区别在于,它解决了keepalive场景下长期被占用的线程的资源浪费问题
(某些线程因为被keepalive,空挂在哪里等待,中间几乎没有请求过来,甚至等到超时)event MPM中,会有一个专门的线程来管理这些keepalive类型的线程
当有真实请求过来的时候,将请求传递给服务线程,执行完毕后,又允许它释放。这样增强了高并发场景下的请求处理能力
优点:单线程响应多请求,占据更少的内存,高并发下表现更优秀,会有一个专门的线程来管理keep
alive类型的线程,当有真实请求过来的时候,将请求传递给服务线程,执行完毕后,又允许它释放
缺点:没有线程安全控制
b.Nginx-高性能的 Web 服务端
Nginx是由1994年毕业于俄罗斯国立莫斯科鲍曼科技大学的同学 伊戈尔·赛索耶夫 为俄罗斯著名搜索网站rambler.ru开发的,开发工作最早从2002年开始,第一次公开发布时间是2004年10月4日,版本号是 0.1.0
官网:https://nginx.org/en/CHANGES
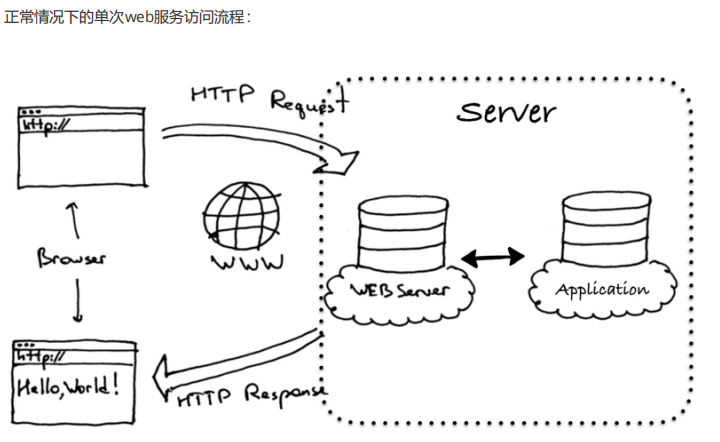
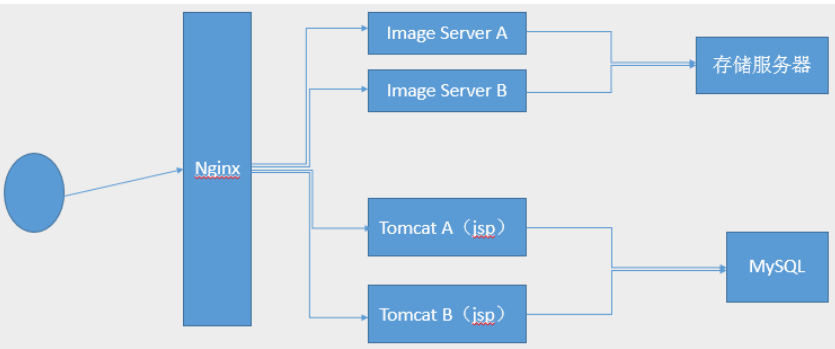
可以作为http服务器,也可以作为反向代理服务器或者邮件服务器能够快速的响应静态网页的请求
基于Nginx的工作场景:
c.用户访问体验统计
互联网存在用户速度体验的1-3-10原则,即1秒最优,1-3秒较优,3~10秒比较慢,10秒以上用户无法接受。用户放弃一个产品的代价很低,只是换一个URL而已。
全球最大搜索引擎 Google:慢500ms = 20% 将放弃访问。
全球最大的电商零售网站亚马逊:慢100ms = 1% 将放弃交易有很多研究都表明,性能对用户的行为有很大的影响:
79%的用户表示不太可能再次打开一个缓慢的网站
47%的用户期望网页能在2秒钟以内加载
40%的用户表示如果加载时间超过三秒钟,就会放弃这个网站
页面加载时间延迟一秒可能导致转换损失7%,页面浏览量减少11%
8秒定律:用户访问一个网站时,如果等待网页打开的时间超过8秒,会有超过30%的用户放弃等待
--影响用户体验的因素
a.客户端
- 客户端硬件配置
- 客户端网络速率
- 客户端与服务端距离
b.服务器
- 服务端网络速率
- 服务端硬件配置
- 服务端架构设计
- 服务端应用程序工作模式
- 服务端并发数量服务端响应文件大小及数量 buffer cache
- 服务端I/O压力1.2.4 服务端 I/O 流程
三、Nginx 架构和安装
1.Nginx 概述
a.Nginx 介绍
Nginx是免费的、开源的、高性能的HTTP和反向代理服务器、邮件代理服务器、以及TCP/UDP代理服务器
解决C10K问题(10K Connections)
Nginx官网:http://nginx.org
b.Nginx 功能介绍
- 静态的web资源服务器html,图片,js,css,txt等静态资源
- http/https协议的反向代理
- 结合FastCGI/uWSGI/SCGI等协议反向代理动态资源请求
- tcp/udp协议的请求转发(反向代理)
- imap4/pop3协议的反向代理
c.基础特性
- 模块化设计,较好的扩展性
- 高可靠性
- 支持热部署:不停机更新配置文件,升级版本,更换日志文件
- 低内存消耗:10000个keep-alive连接模式下的非活动连接,仅需2.5M内存
- event-driven,aio,mmap,sendfile
d.Web 服务相关的功能
- 虚拟主机(server)
- 支持 keep-alive 和管道连接(利用一个连接做多次请求)
- 访问日志(支持基于日志缓冲提高其性能)
- url rewirte
- 路径别名
- 基于IP及用户的访问控制
- 支持速率限制及并发数限制
- 重新配置和在线升级而无须中断客户的工作进程
2.Nginx 架构和进程
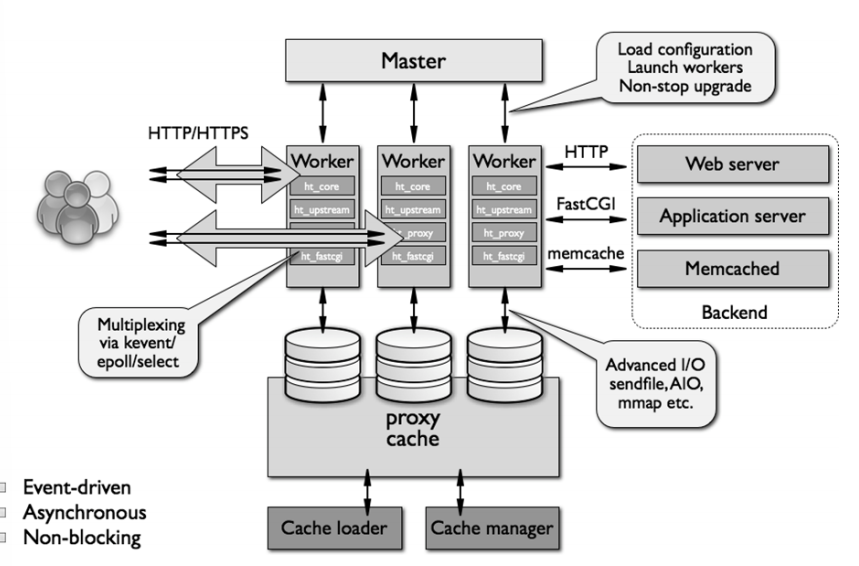
a.Nginx 进程结构
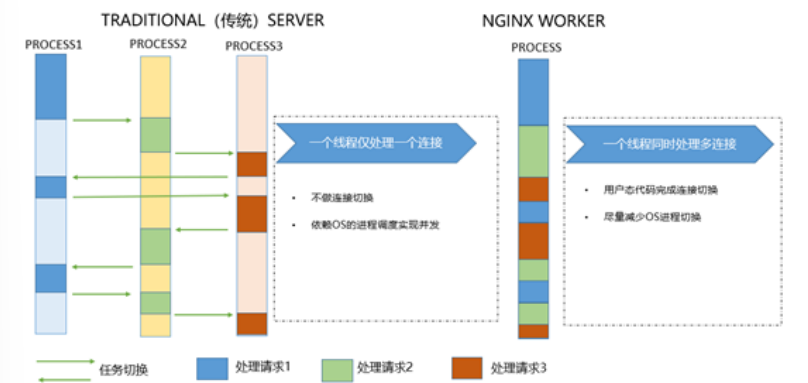
- web请求处理机制
- 多进程方式:服务器每接收到一个客户端请求就有服务器的主进程生成一个子进程响应客户端,直到用户关闭连接,这样的优势是处理速度快,子进程之间相互独立,但是如果访问过大会导致服务器资源耗尽而无法提供请求
- 多线程方式:与多进程方式类似,但是每收到一个客户端请求会有服务进程派生出一个线程和此客户端进行交互,一个线程的开销远远小于一个进程,因此多线程方式在很大程度减轻了web服务器对系统资源的要求,但是多线程也有自己的缺点,即当多个线程位于同一个进程内工作的时候,可以相互访问同样的内存地址空间,所以他们相互影响,一旦主进程挂掉则所有子线程都不能工作了,IIS服务器使用了多线程的方式,需要间隔一段时间就重启一次才能稳定。
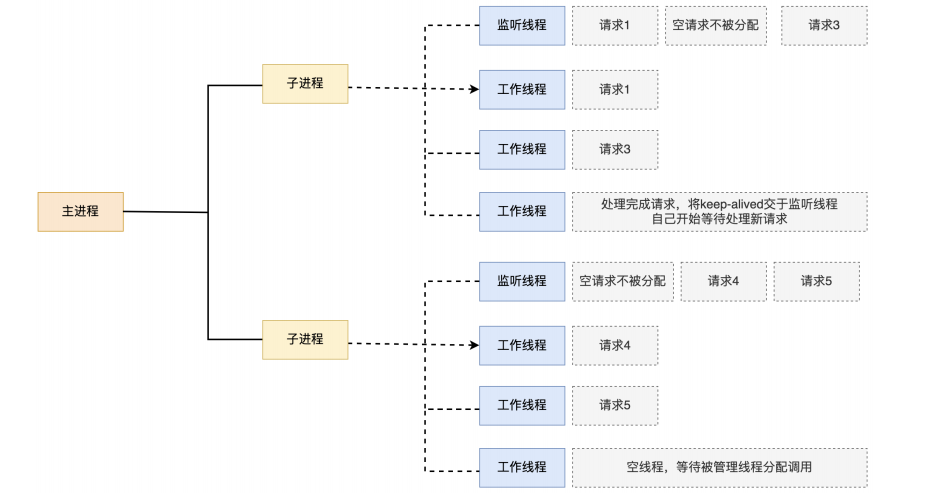
Nginx是多进程组织模型,而且是一个由Master主进程和Worker工作进程组成。
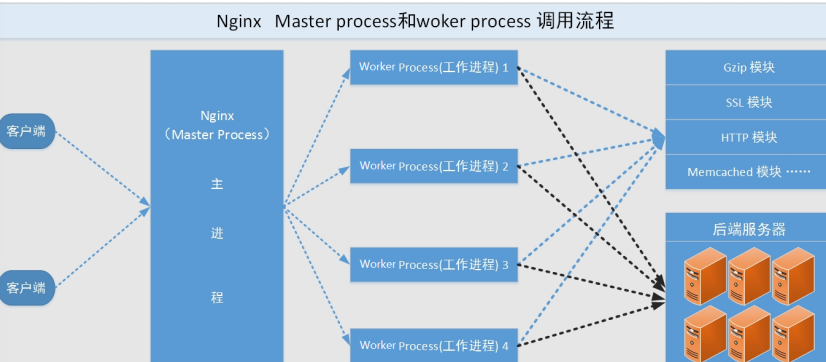
主进程(master process)的功能:
- 对外接口:接收外部的操作(信号)
- 对内转发:根据外部的操作的不同,通过信号管理 Worker
- 监控:监控 worker 进程的运行状态,worker 进程异常终止后,自动重启 worker 进程
- 读取Nginx 配置文件并验证其有效性和正确性
- 建立、绑定和关闭socket连接
- 按照配置生成、管理和结束工作进程
- 接受外界指令,比如重启、升级及退出服务器等指令
- 不中断服务,实现平滑升级,重启服务并应用新的配置
- 开启日志文件,获取文件描述符
- 不中断服务,实现平滑升级,升级失败进行回滚处理
- 编译和处理perl脚本
工作进程(worker process)的功能:
- 所有 Worker 进程都是平等的
- 实际处理:网络请求,由 Worker 进程处理
- Worker进程数量:一般设置为核心数,充分利用CPU资源,同时避免进程数量过多,导致进程竞争CPU资源,
- 增加上下文切换的损耗
- 接受处理客户的请求
- 将请求依次送入各个功能模块进行处理
- I/O调用,获取响应数据
- 与后端服务器通信,接收后端服务器的处理结果
- 缓存数据,访问缓存索引,查询和调用缓存数据
- 发送请求结果,响应客户的请求
- 接收主程序指令,比如重启、升级和退出等
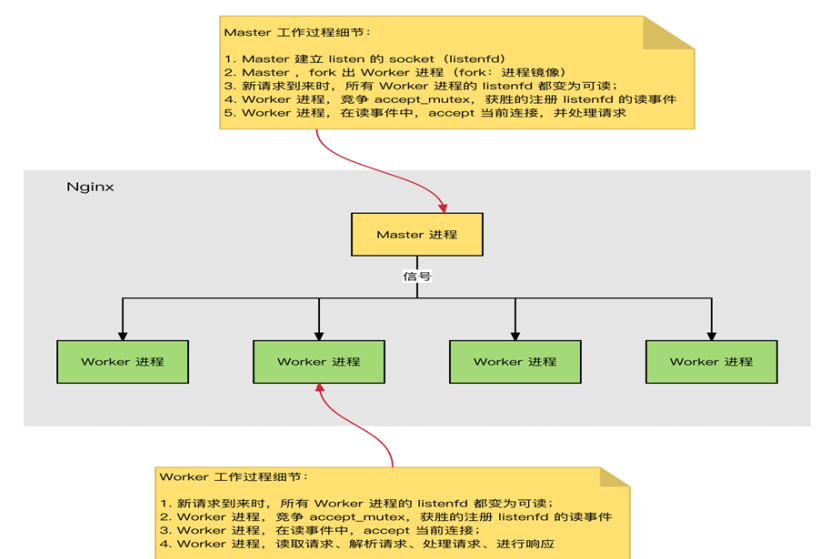
c.Nginx 进程间通信
工作进程是由主进程生成的,主进程使用fork()函数,在Nginx服务器启动过程中主进程根据配置文件决定启动工作进程的数量,然后建立一张全局的工作表用于存放当前未退出的所有的工作进程,主进程生成工作进程后会将新生成的工作进程加入到工作进程表中,并建立一个单向的管道并将其传递给工作进程,该管道与普通的管道不同,它是由主进程指向工作进程的单向通道,包含了主进程向工作进程发出的指令、工作进程ID、工作进程在工作进程表中的索引和必要的文件描述符等信息。
主进程与外界通过信号机制进行通信,当接收到需要处理的信号时,它通过管道向相关的工作进程发送正确的指令,每个工作进程都有能力捕获管道中的可读事件,当管道中有可读事件的时候,工作进程就会从管道中读取并解析指令,然后采取相应的执行动作,这样就完成了主进程与工作进程的交互。
worker进程之间的通信原理基本上和主进程与worker进程之间的通信是一样的,只要worker进程之间能够取得彼此的信息,建立管道即可通信,但是由于worker进程之间是完全隔离的,因此一个进程想要知道另外一个进程的状态信息,就只能通过主进程来实现。
为了实现worker进程之间的交互,master进程在生成worker进程之后,在worker进程表中进行遍历,将该新进程的PID以及针对该进程建立的管道句柄传递给worker进程中的其他进程,为worker进程之间的通信做准备,当worker进程1向worker进程2发送指令的时候,首先在master进程给它的其他worker进程工作信息中找到2的进程PID,然后将正确的指令写入指向进程2的管道,worker进程2捕获到管道中的事件后,解析指令并进行相关操作,这样就完成了worker进程之间的通信。
另worker进程可以通过共享内存来通讯的,比如upstream中的zone,或者limit_req、limit_conn中的zone等。操作系统提供了共享内存机制
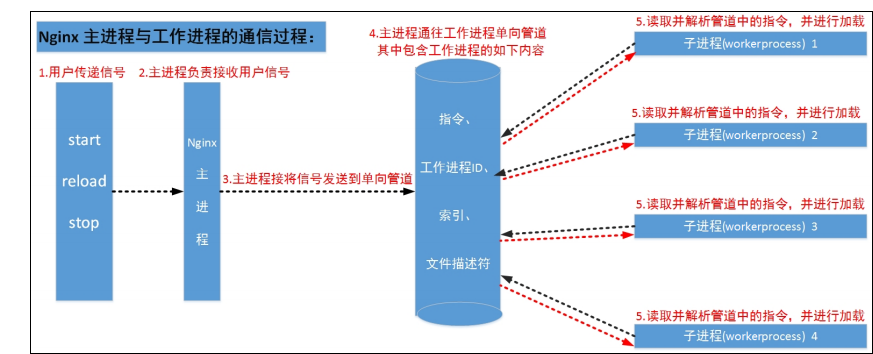
d.Nginx 启动和 HTTP 连接建立
Nginx 启动时,Master 进程,加载配置文件
- Master 进程,初始化监听的 socket
- Master 进程,fork 出多个 Worker 进程
- Worker 进程,竞争新的连接,获胜方通过三次握手,建立 Socket 连接,并处理请求
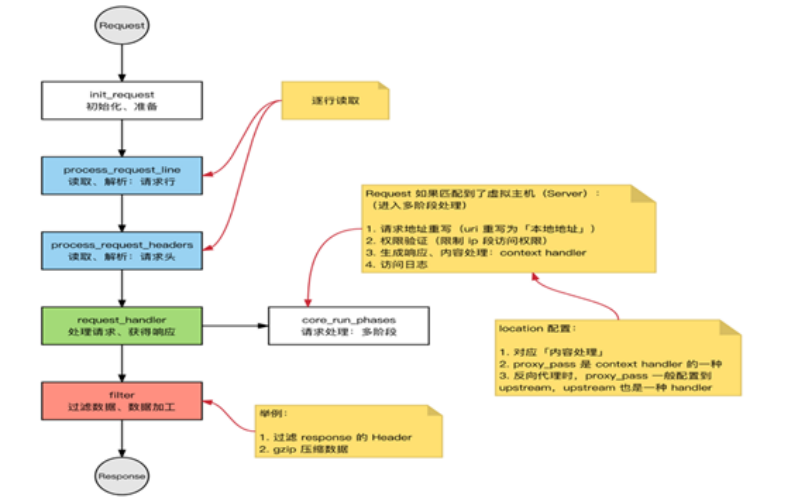
e.HTTP 处理过程
3.Nginx 模块介绍
nginx 有多种模块
- 核心模块:是 Nginx 服务器正常运行必不可少的模块,提供错误日志记录 、配置文件解析 、事件驱动机制 、进程管理等核心功能
- 标准HTTP模块:提供 HTTP 协议解析相关的功能,比如: 端口配置 、 网页编码设置 、 HTTP响应头设置 等等
- 可选HTTP模块:主要用于扩展标准的 HTTP 功能,让 Nginx 能处理一些特殊的服务,比如: Flash
- 多媒体传输 、解析 GeoIP 请求、 网络传输压缩 、 安全协议 SSL 支持等
- 邮件服务模块:主要用于支持 Nginx 的 邮件服务 ,包括对 POP3 协议、 IMAP 协议和 SMTP协议的支持
- Stream服务模块: 实现反向代理功能,包括TCP协议代理
- 第三方模块:是为了扩展 Nginx 服务器应用,完成开发者自定义功能,比如: Json 支持、 Lua 支持等
nginx高度模块化,但其模块早期不支持DSO机制;1.9.11 版本支持动态装载和卸载
模块分类:
核心模块:core module
标准模块:
HTTP 模块: ngx_http_*
HTTP Core modules #默认功能
HTTP Optional modules #需编译时指定
Mail 模块: ngx_mail_*
Stream 模块 ngx_stream_*
第三方模块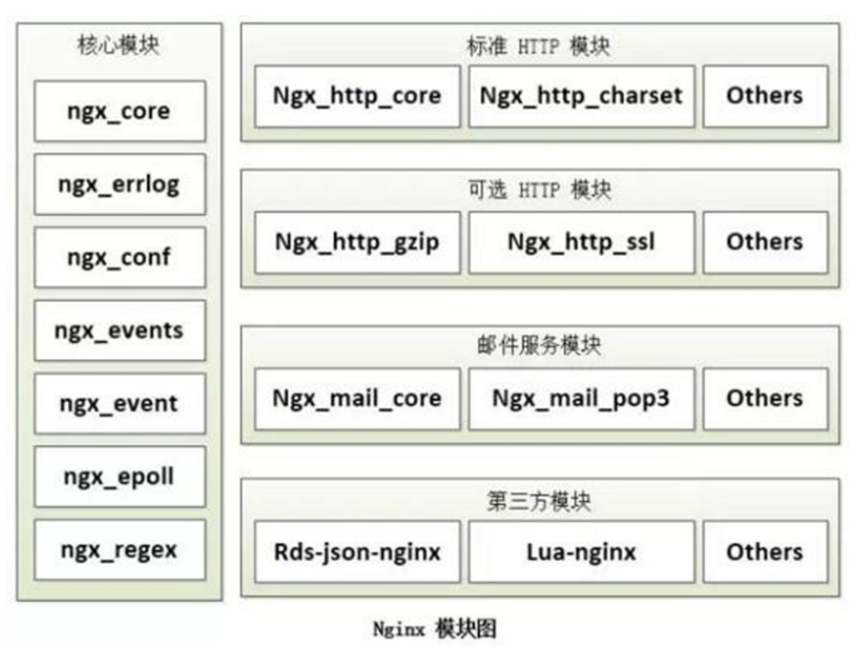
4.Nginx 安装
a.Nginx版本和安装方式
Nginx版本
- Mainline version 主要开发版本,一般为奇数版本号,比如1.19
- Stable version 当前最新稳定版,一般为偶数版本,如:1.20
- Legacy versions 旧的稳定版,一般为偶数版本,如:1.18
Nginx安装可以使用yum或源码安装,但是推荐使用源码编译安装
- yum的版本比较旧
- 编译安装可以更方便自定义相关路径
- 使用源码编译可以自定义相关功能,更方便业务的上的使用
b.Nginx 编译安装
编译器介绍
源码安装需要提前准备标准的编译器,GCC的全称是(GNU Compiler collection),其有GNU开发,并以
GPL即LGPL许可,是自由的类UNIX即苹果电脑Mac OS X操作系统的标准编译器,因为GCC原本只能处理C语
言,所以原名为GNU C语言编译器,后来得到快速发展,可以处理C++,Fortran,pascal,objective C,
java以及Ada等其他语言,此外还需要Automake工具,以完成自动创建Makefile的工作,Nginx的一些模块
需要依赖第三方库,比如: pcre(支持rewrite),zlib(支持gzip模块)和openssl(支持ssl模块)
等。--编译安装 Nginx
官方源码包下载地址:
https://nginx.org/en/download.html1.官网下载安装

或

[root@webservera mnt]# tar zxf nginx-1.24.0.tar.gz
[root@webservera mnt]# cd nginx-1.24.0/

示例:

建立nginx用户:
[root@webservera nginx-1.24.0]# useradd -s /sbin/nologin -M nginx
检测所需安装的依赖:
[root@webservera nginx-1.24.0]# ./configure --prefix=/usr/local/nginx --user=nginx --group=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module安装所需依赖:
[root@webservera nginx-1.24.0]# dnf install gcc -y
[root@webservera nginx-1.24.0]# dnf install pcre-devel.x86_64 -y
[root@webservera nginx-1.24.0]# dnf install openssl-devel.x86_64 -y
[root@webservera nginx-1.24.0]# dnf install zlib-devel.x86_64 -y
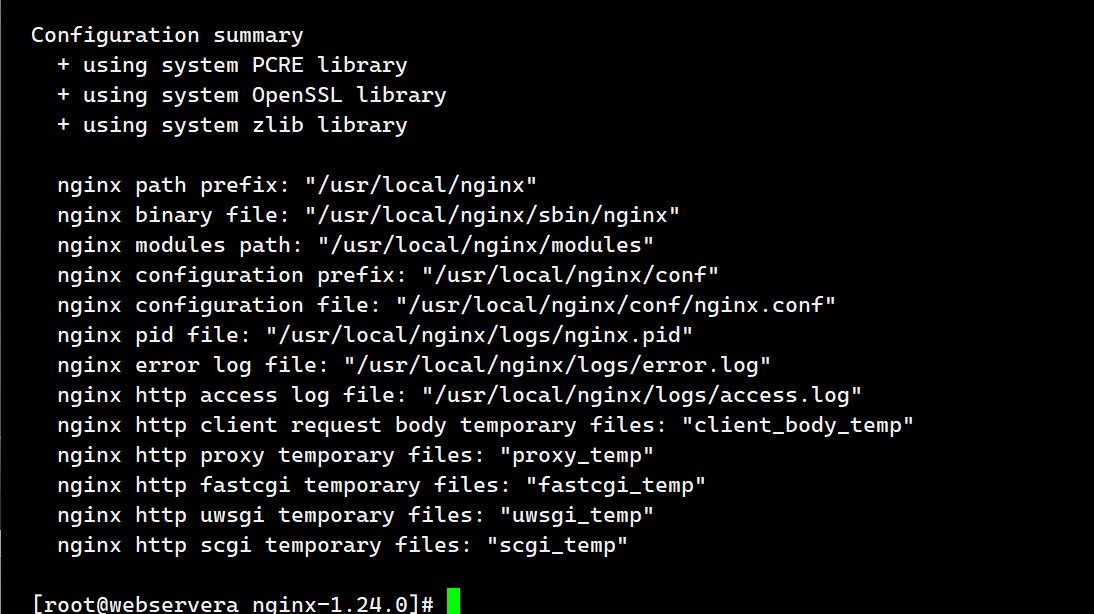
执行make:
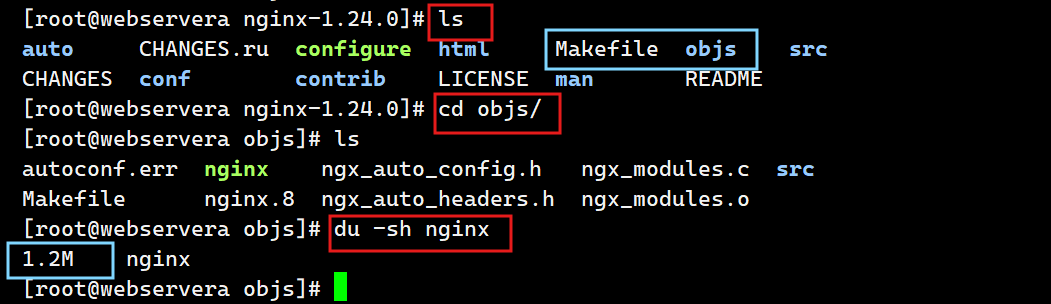
[root@webservera nginx-1.24.0]# make

[root@webservera objs]# du -sh nginx

重新编译:
[root@webservera nginx-1.24.0]# rm -rf Makefile objs
[root@webservera nginx-1.24.0]# cd auto/cc/
[root@webservera cc]# vim gcc
注释掉debug模块:
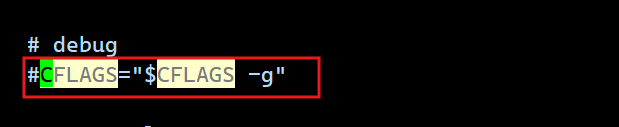
开始编译:
[root@webservera nginx-1.24.0]# ./configure --prefix=/usr/local/nginx --user=nginx --group=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module
[root@webservera nginx-1.24.0]# make
[root@webservera nginx-1.24.0]# make install
启动nginx:
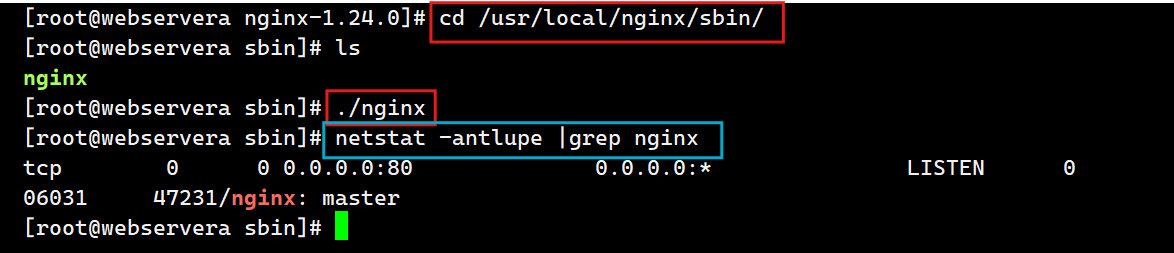
停止nginx:
[root@webservera sbin]# ./nginx -s stop--验证版本及编译参数
[root@webservera sbin]# echo "export PATH=$PATH:/usr/local/nginx/sbin" >> ~/.bash_profile
[root@webservera sbin]# source ~/.bash_profile


5.平滑升级和回滚
有时候我们需要对Nginx版本进行升级以满足对其功能的需求,例如添加新模块,需要新功能,而此时Nginx又在跑着业务无法停掉,这时我们就可能选择平滑升级
a.平滑升级流程
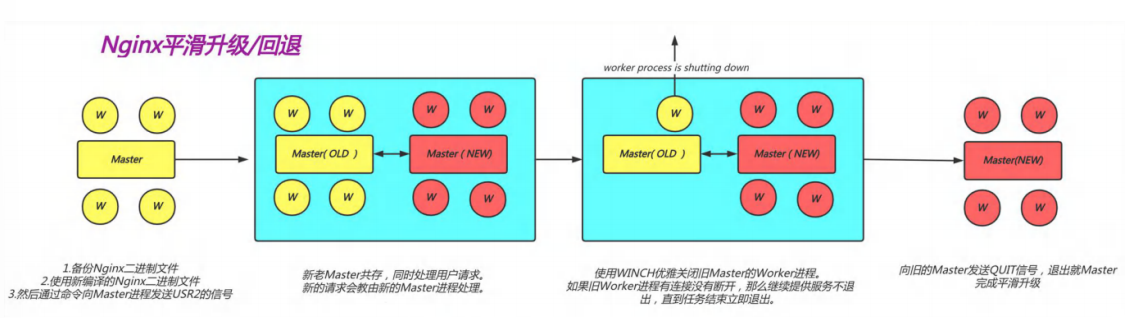
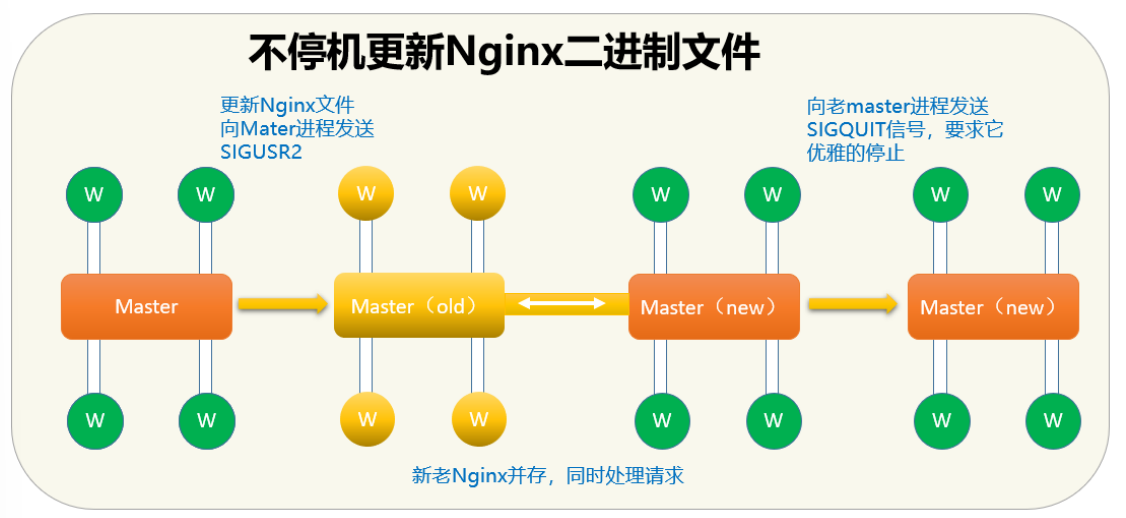
- 将旧Nginx二进制文件换成新Nginx程序文件(注意先备份)
- 向master进程发送USR2信号
- master进程修改pid文件名加上后缀.oldbin,成为nginx.pid.oldbin
- master进程用新Nginx文件启动新master进程成为旧master的子进程,系统中将有新旧两个Nginx主进程共同提供Web服务,当前新的请求仍然由旧Nginx的worker进程进行处理,将新生成的master进程的PID存放至新生成的pid文件nginx.pid
- 向旧的Nginx服务进程发送WINCH信号,使旧的Nginx worker进程平滑停止
- 向旧master进程发送QUIT信号,关闭老master,并删除Nginx.pid.oldbin文件
- 如果发现升级有问题,可以回滚∶向老master发送HUP,向新master发送QUIT
b.平滑升级
- 我的压缩包在/mnt/下
--安装nginx-1.26.1:
[root@webservera mnt]# tar zxf nginx-1.26.1.tar.gz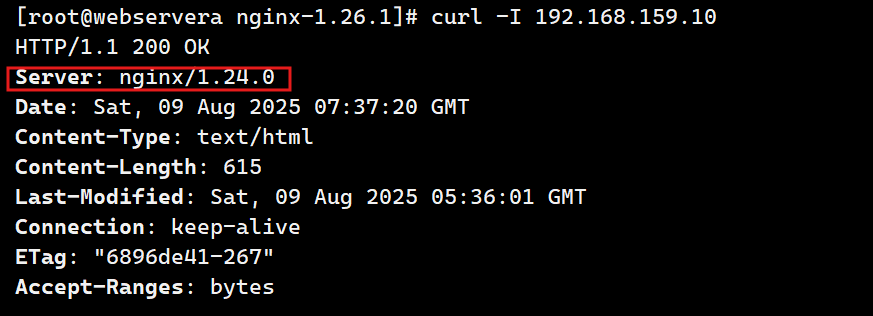
更改nginx编译源码隐藏版本信息:
[root@webservera nginx-1.26.1]# vim src/core/nginx.h


注释掉debug:
[root@webservera nginx-1.26.1]# vim auto/cc/gcc 
检测编译:
[root@webservera nginx-1.26.1]# ./configure --prefix=/usr/local/nginx --user=nginx --group=nginx --with-http_ssl_module --with-http_v2_module --with-http_realip_module --with-http_stub_status_module --with-http_gzip_static_module --with-pcre --with-stream --with-stream_ssl_module --with-stream_realip_module
[root@webservera nginx-1.26.1]# make
关闭防火墙:
[root@webservera nginx-1.26.1]# systemctl disable --now firewalld旧版的nginx命令备份:
[root@webservera objs]# cd /usr/local/nginx/sbin/
[root@webservera sbin]# cp -p nginx nginx.old
把新版本的nginx命令复制过去:
[root@webservera mnt]# /bin/cp -f /mnt/nginx-1.26.1/objs/nginx /usr/local/nginx/sbin/nginx检测是否有问题:
[root@webservera sbin]# nginx -t

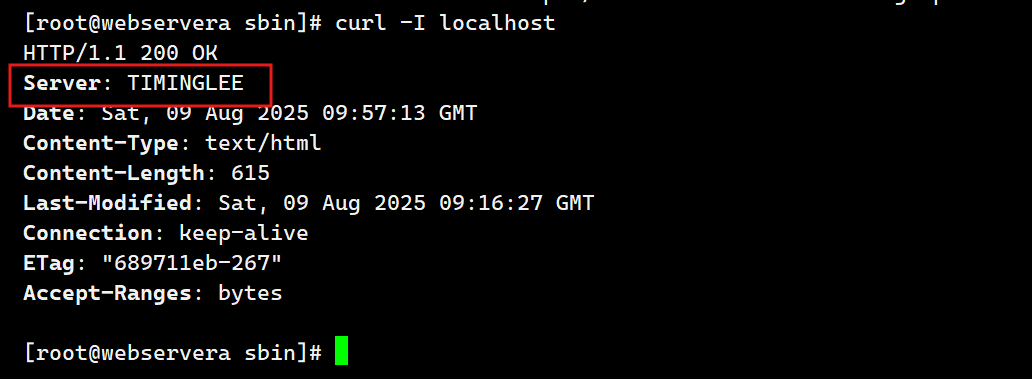
USR2 平滑升级可执行程序,将存储有旧版本主进程PID的文件重命名为nginx.pid.oldbin,并启动新的nginx
此时两个master的进程都在运行,只是旧的master不在监听,由新的master监听80
此时Nginx开启一个新的master进程,这个master进程会生成新的worker进程,这就是升级后的Nginx进程,此时老的进程不会自动退出,但是当接收到新的请求不作处理而是交给新的进程处理。
#此处是旧版本进程ID 21334
[root@webservera sbin]# kill -USR2 21334
[root@webservera sbin]# ps aux | grep nginx

回收旧版本:
[root@webservera sbin]# kill -WINCH 21334

新版本生效:
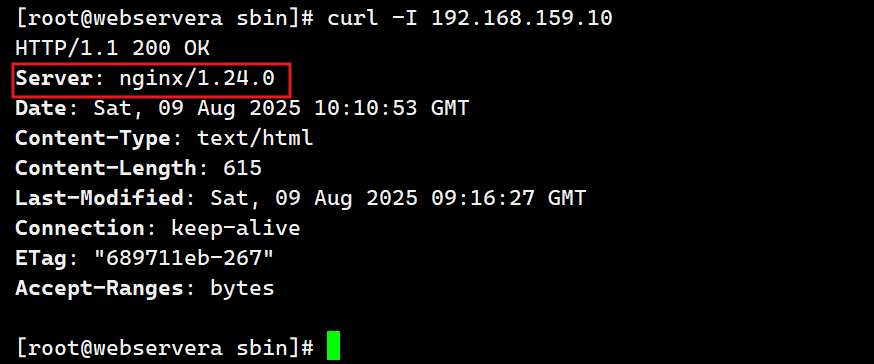
c.回滚:
如果升级的版本发现问题需要回滚,可以重新拉起旧版本的worker
[root@webservera sbin]# cp nginx nginx.new -p
[root@webservera sbin]# mv nginx.old nginx

[root@webservera sbin]# kill -HUP 21334

回收新版本:
[root@webservera sbin]# kill -WINCH 24600
6.编写nginx启动脚本
百度上搜索:
[root@webservera nginx-1.26.1]# cd /usr/local/nginx/sbin/
[root@webservera sbin]# cd /lib/systemd/system
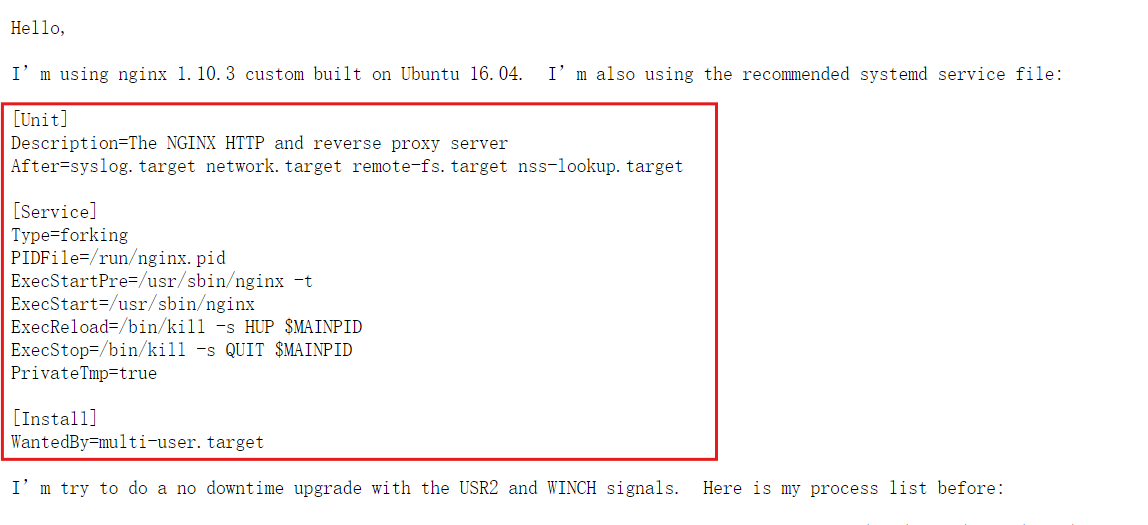
[root@webservera system]# vim nginx.service
[Unit]
Description=The NGINX HTTP and reverse proxy server
After=syslog.target network.target remote-fs.target nss-lookup.target[Service]
Type=forking
PIDFile=/usr/local/nginx/logs/nginx.pid
ExecStartPre=/usr/local/nginx/sbin/nginx -t
ExecStart=/usr/local/nginx/sbin/local
ExecReload=/bin/kill -s HUP $MAINPID
ExecStop=/bin/kill -s QUIT $MAINPID
PrivateTmp=true[Install]
WantedBy=multi-user.target
[root@webservera system]# nginx -s stop

[root@webservera system]# systemctl enable --now nginx.service

[root@webservera system]# systemctl stop nginx.service 
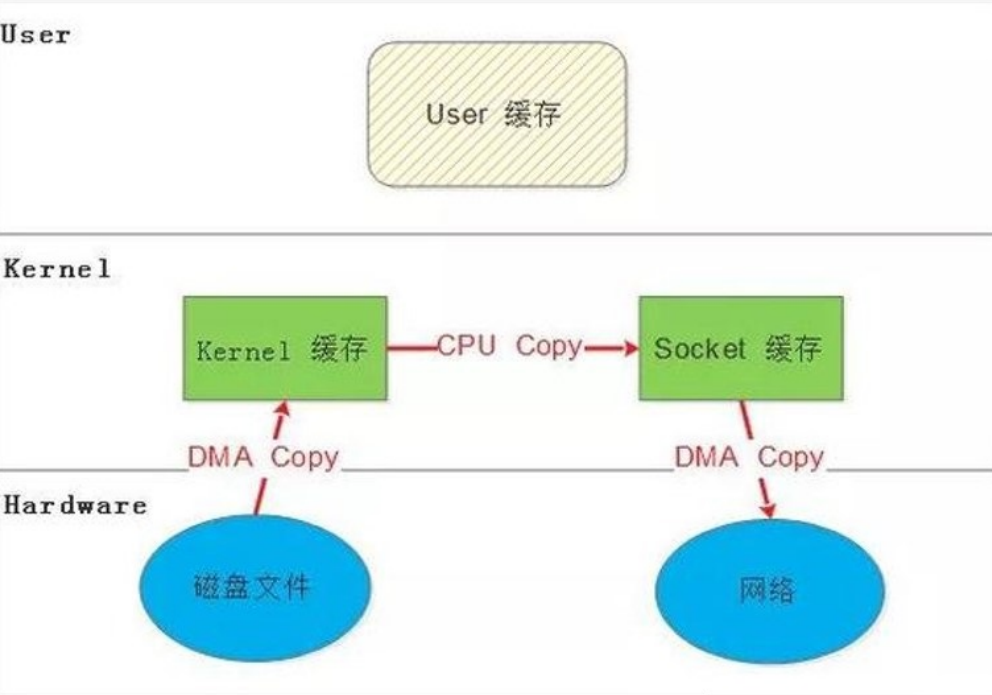
四、服务端 I/O 流程
I/O在计算机中指Input/Output, IOPS (Input/Output Per Second)即每秒的输入输出量(或读写次数),是衡量磁盘性能的主要指标之一。IOPS是指单位时间内系统能处理的I/O请求数量,一般以每秒处理的I/O请求数量为单位,I/O请求通常为读或写数据操作请求。
一次完整的I/O是用户空间的进程数据与内核空间的内核数据的报文的完整交换,但是由于内核空间与用户空间是严格隔离的,所以其数据交换过程中不能由用户空间的进程直接调用内核空间的内存数据,而是需要经历一次从内核空间中的内存数据copy到用户空间的进程内存当中,所以简单说I/O就是把数据从内核空间中的内存数据复制到用户空间中进程的内存当中。
服务器的I/O
- 磁盘I/O
- 网络I/O : 一切皆文件,本质为对socket文件的读写
1.磁盘 I/O
磁盘I/O是进程向内核发起系统调用,请求磁盘上的某个资源比如是html 文件或者图片,然后内核通过相应的驱动程序将目标文件加载到内核的内存空间,加载完成之后把数据从内核内存再复制给进程内存,如果是比较大的数据也需要等待时间
机械磁盘的寻道时间、旋转延迟和数据传输时间:
寻道时间:是指磁头移动到正确的磁道上所花费的时间,寻道时间越短则I/O处理就越快,目前磁盘的寻道时
间一般在3-15毫秒左右。
旋转延迟:是指将磁盘片旋转到数据所在的扇区到磁头下面所花费的时间,旋转延迟取决于磁盘的转速,通常
使用磁盘旋转一周所需要时间的1/2之一表示,比如7200转的磁盘平均训传延迟大约为
60*1000/7200/2=4.17毫秒,公式的意思为 (每分钟60秒*1000毫秒每秒/7200转每分/2),如果是
15000转的则为60*1000/15000/2=2毫秒。
数据传输时间:指的是读取到数据后传输数据的时间,主要取决于传输速率,这个值等于数据大小除以传输速
率,目前的磁盘接口每秒的传输速度可以达到600MB,因此可以忽略不计。
常见的机械磁盘平均寻道时间值:
7200转/分的磁盘平均物理寻道时间:9毫秒
10000转/分的磁盘平均物理寻道时间:6毫秒
15000转/分的磁盘平均物理寻道时间:4毫秒
常见磁盘的平均延迟时间:
7200转的机械盘平均延迟:60*1000/7200/2 = 4.17ms
10000转的机械盘平均延迟:60*1000/10000/2 = 3ms
15000转的机械盘平均延迟:60*1000/15000/2 = 2ms
每秒最大IOPS的计算方法:
7200转的磁盘IOPS计算方式:1000毫秒/(9毫秒的寻道时间+4.17毫秒的平均旋转延迟时
间)=1000/13.13=75.9 IOPS
10000转的磁盘的IOPS计算方式:1000毫秒/(6毫秒的寻道时间+3毫秒的平均旋转延迟时
间)=1000/9=111IOPS
15000转的磁盘的IOPS计算方式:15000毫秒/(4毫秒的寻道时间+2毫秒的平均旋转延迟时
间)=1000/6=166.6 IOPS2.网络 I/O
网络通信就是网络协议栈到用户空间进程的IO就是网络IO
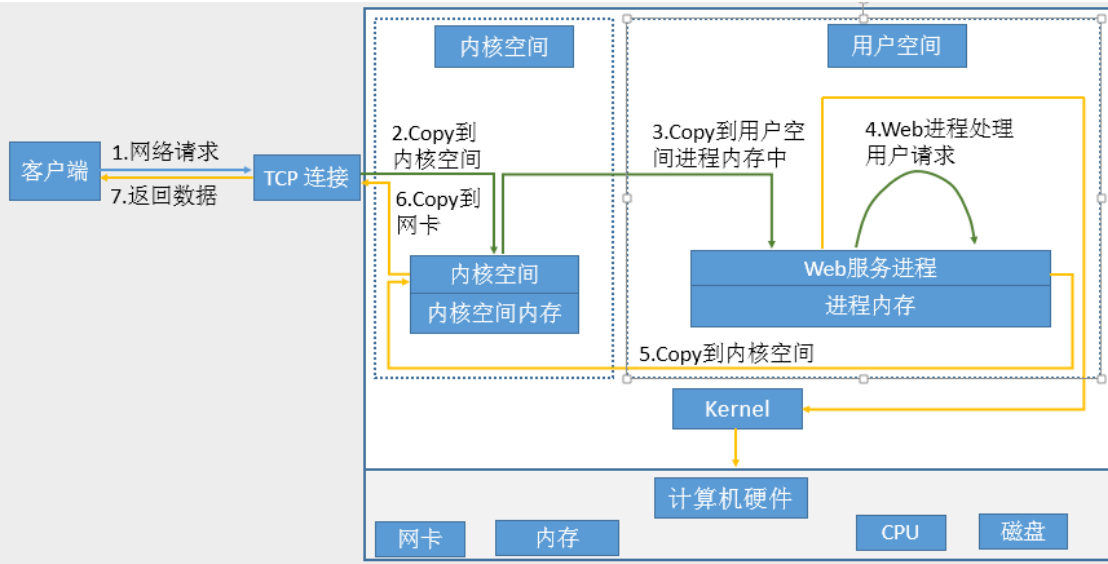
a.网络I/O 处理过程
- 获取请求数据,客户端与服务器建立连接发出请求,服务器接受请求(1-3)
- 构建响应,当服务器接收完请求,并在用户空间处理客户端的请求,直到构建响应完成(4)
- 返回数据,服务器将已构建好的响应再通过内核空间的网络 I/O 发还给客户端(5-7)
不论磁盘和网络I/O:
每次I/O,都要经由两个阶段:
- 第一步:将数据从文件先加载至内核内存空间(缓冲区),等待数据准备完成,时间较长
- 第二步:将数据从内核缓冲区复制到用户空间的进程的内存中,时间较短
五、I/O 模型
1.I/O 模型相关概念
同步/异步:关注的是消息通信机制,即调用者在等待一件事情的处理结果时,被调用者是否提供完成状态的通知。
- 同步:synchronous,被调用者并不提供事件的处理结果相关的通知消息,需要调用者主动询问事情是否处理完成
- 异步:asynchronous,被调用者通过状态、通知或回调机制主动通知调用者被调用者的运行状态

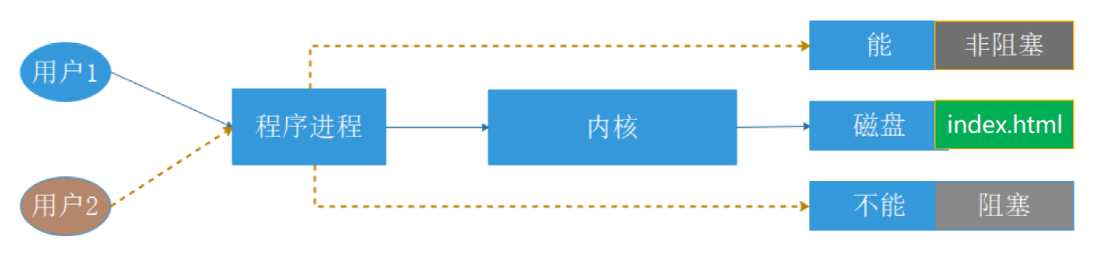
阻塞/非阻塞:关注调用者在等待结果返回之前所处的状态
阻塞:blocking,指IO操作需要彻底完成后才返回到用户空间,调用结果返回之前,调用者被挂
起,干不了别的事情。
非阻塞:nonblocking,指IO操作被调用后立即返回给用户一个状态值,而无需等到IO操作彻底完
成,在最终的调用结果返回之前,调用者不会被挂起,可以去做别的事情。
2.网络 I/O 模型
阻塞型、非阻塞型、复用型、信号驱动型、异步
a.阻塞型 I/O 模型(blocking IO)
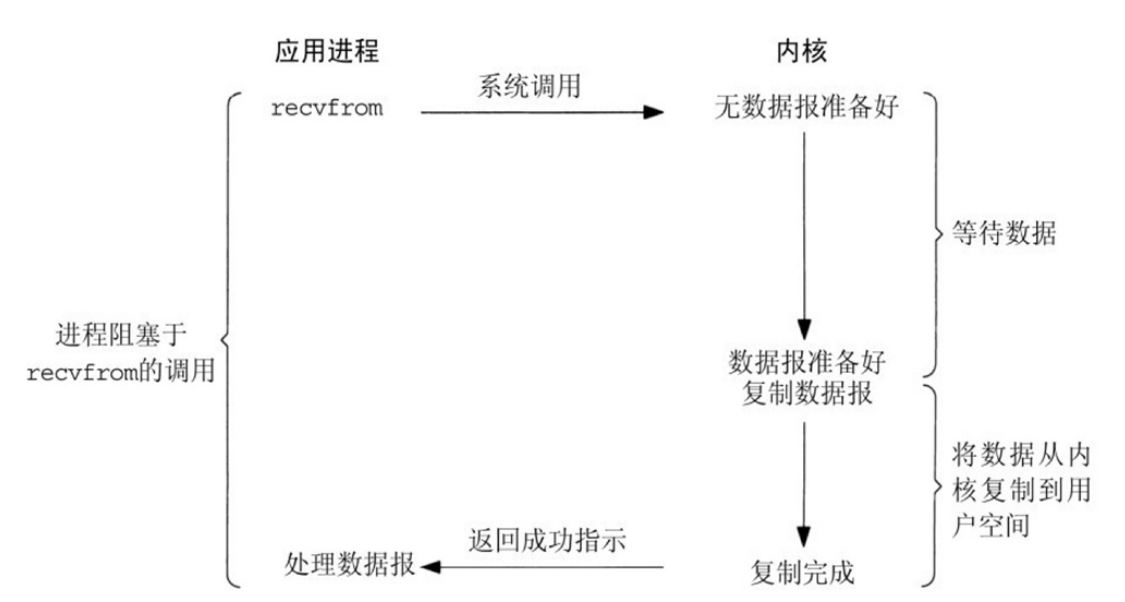
- 阻塞IO模型是最简单的I/O模型,用户线程在内核进行IO操作时被阻塞
- 用户线程通过系统调用read发起I/O读操作,由用户空间转到内核空间。内核等到数据包到达后,然 后将接收的数据拷贝到用户空间,完成read操作
- 用户需等待read将数据读取到buffer后,才继续处理接收的数据。整个I/O请求的过程中,用户线程是被阻塞的,这导致用户在发起IO请求时,不能做任何事情,对CPU的资源利用率不够
优点:程序简单,在阻塞等待数据期间进程/线程挂起,基本不会占用 CPU 资源
缺点:每个连接需要独立的进程/线程单独处理,当并发请求量大时为了维护程序,内存、线程切换开销较apache 的preforck使用的是这种模式。
同步阻塞:程序向内核发送I/O请求后一直等待内核响应,如果内核处理请求的IO操作不能立即返回,则进程将一直等待并不再接受新的请求,并由进程轮询查看I/O是否完成,完成后进程将I/O结果返回给Client,在IO没有返回期间进程不能接受其他客户的请求,而且是有进程自己去查看I/O是否完成,这种方式简单,但是比较慢,用的比较少。
b.非阻塞型 I/O 模型 (nonblocking IO)
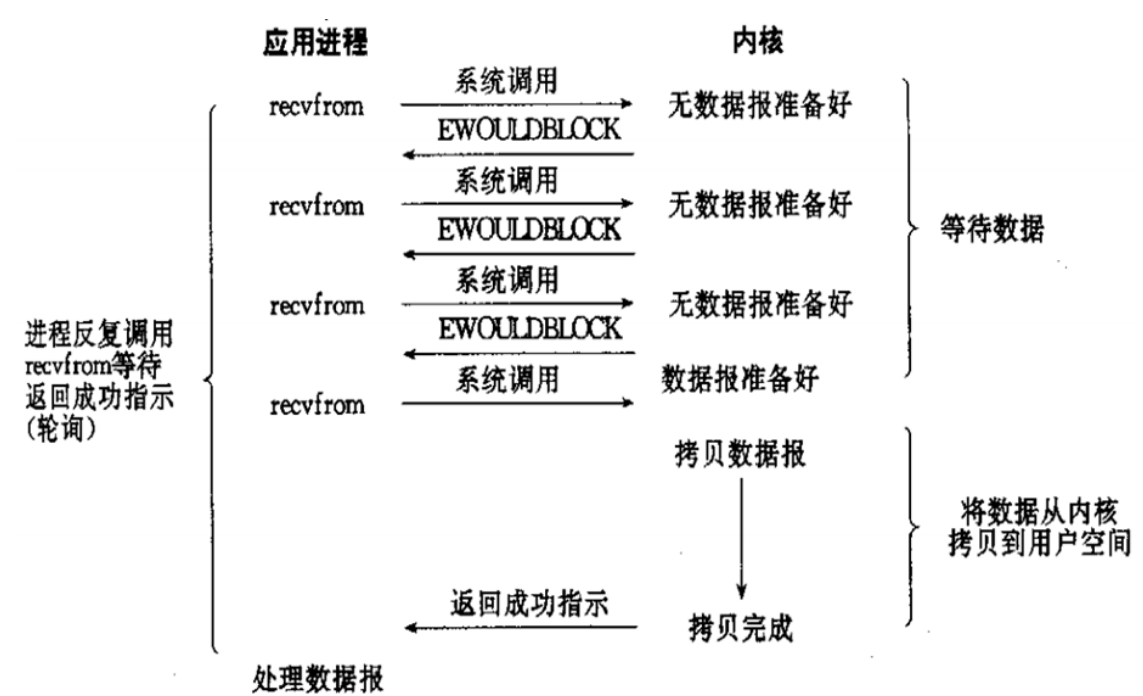
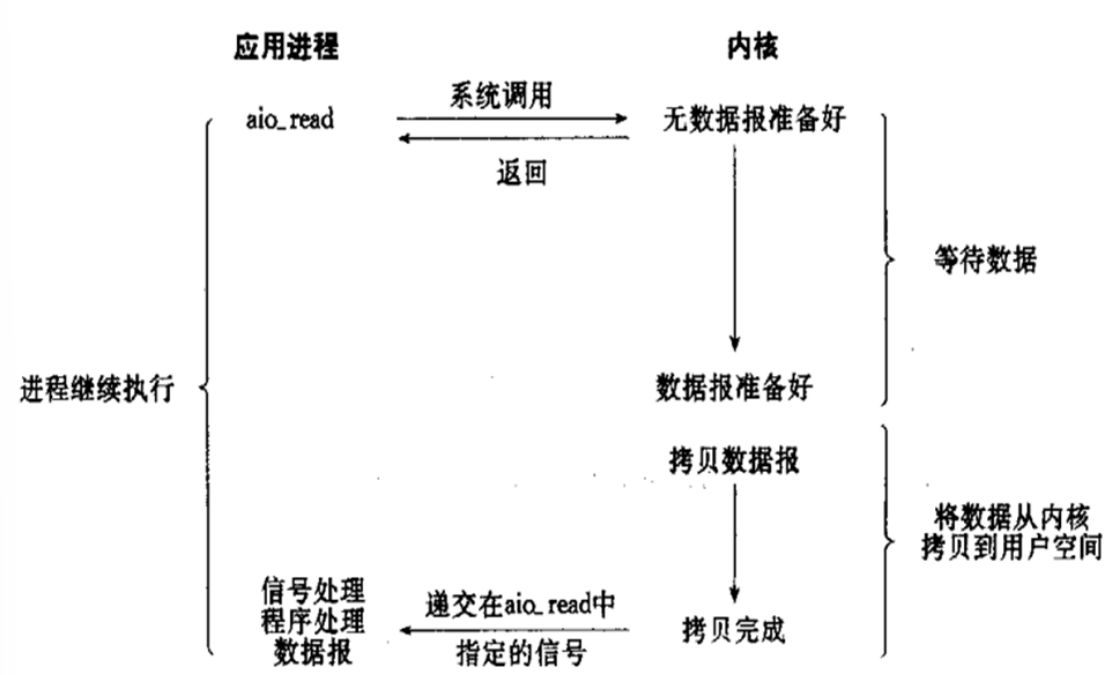
用户线程发起IO请求时立即返回。但并未读取到任何数据,用户线程需要不断地发起IO请求,直到数据到达后,才真正读取到数据,继续执行。即 “轮询”机制存在两个问题:如果有大量文件描述符都要等,那么就得一个一个的read。这会带来大量的Context Switch(read是系统调用,每调用一次就得在用户态和核心态切换一次)。轮询的时间不好把握。这里是要猜多久之后数据才能到。等待时间设的太长,程序响应延迟就过大;设的太短,就会造成过于频繁的重试,干耗CPU而已,是比较浪费CPU的方式,一般很少直接使用这种模型,而是在其他IO模型中使用非阻塞IO这一特性。
非阻塞:程序向内核发送请I/O求后一直等待内核响应,如果内核处理请求的IO操作不能立即返回IO结果,进程将不再等待,而且继续处理其他请求,但是仍然需要进程隔一段时间就要查看内核I/O是否完成。
查看上图可知,在设置连接为非阻塞时,当应用进程系统调用 recvfrom 没有数据返回时,内核会立即返回一个 EWOULDBLOCK 错误,而不会一直阻塞到数据准备好。如上图在第四次调用时有一个数据报准备好了,所以这时数据会被复制到 应用进程缓冲区 ,于是 recvfrom 成功返回数据
当一个应用进程这样循环调用 recvfrom 时,称之为轮询 polling 。这么做往往会耗费大量CPU时间,实际使用很少
c.多路复用 I/O 型(I/O multiplexing)
上面的模型中,每一个文件描述符对应的IO是由一个线程监控和处理
多路复用IO指一个线程可以同时(实际是交替实现,即并发完成)监控和处理多个文件描述符对应各自的IO,即复用同一个线程
一个线程之所以能实现同时处理多个IO,是因为这个线程调用了内核中的SELECT,POLL或EPOLL等系统调用,从而实现多路复用IO
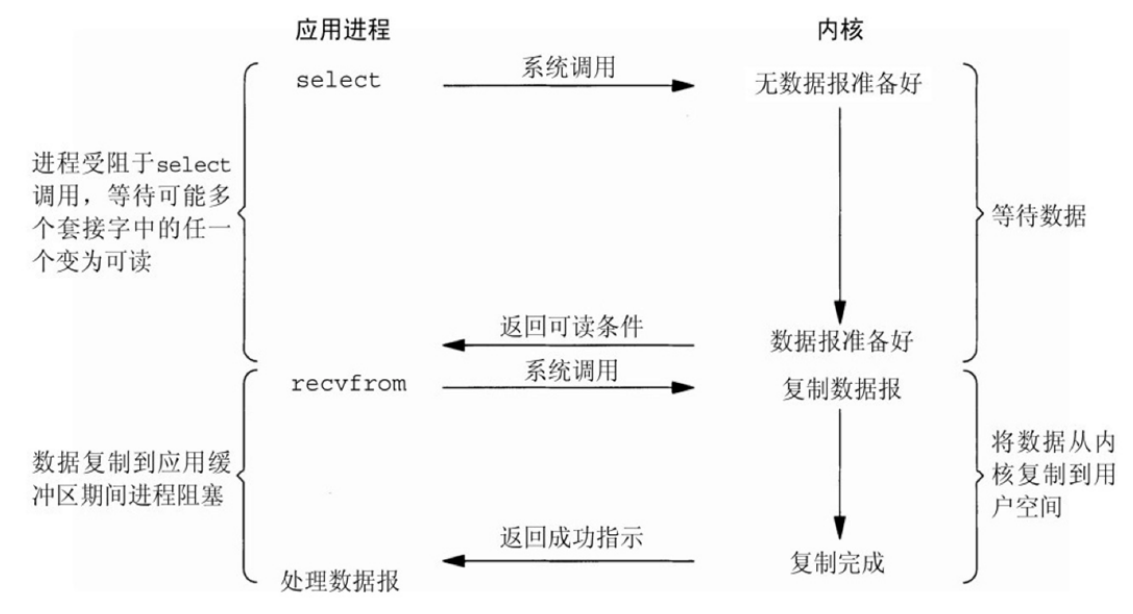
I/O multiplexing 主要包括:select,poll,epoll三种系统调用,select/poll/epoll的好处就在于单个
process就可以同时处理多个网络连接的IO。
它的基本原理就是select/poll/epoll这个function会不断的轮询所负责的所有socket,当某个socket有数据到达了,就通知用户进程。
当用户进程调用了select,那么整个进程会被block,而同时,kernel会“监视”所有select负责的socket,当任何一个socket中的数据准备好了,select就会返回。这个时候用户进程再调用read操作,将数据从kernel拷贝到用户进程。
Apache prefork是此模式的select,worker是poll模式。
IO多路复用(IO Multiplexing) :是一种机制,程序注册一组socket文件描述符给操作系统,表示“我要监视这些fd是否有IO事件发生,有了就告诉程序处理”IO多路复用一般和NIO一起使用的。NIO和IO多路复用是相对独立的。NIO仅仅是指IO API总是能立刻返回,不会被Blocking;而IO多路复用仅仅是操作系统提供的一种便利的通知机制。操作系统并不会强制这俩必须一起用,可以只用IO多路复用 + BIO,这时还是当前线程被卡住。IO多路复用和NIO是要配合一起使用才有实际意义
IO多路复用是指内核一旦发现进程指定的一个或者多个IO条件准备读取,就通知该进程多个连接共用一个等待机制,本模型会阻塞进程,但是进程是阻塞在select或者poll这两个系统调用上,而不是阻塞在真正的IO操作上用户首先将需要进行IO操作添加到select中,同时等待select系统调用返回。当数据到达时,IO被激活,select函数返回。用户线程正式发起read请求,读取数据并继续执行从流程上来看,使用select函数进行IO请求和同步阻塞模型没有太大的区别,甚至还多了添加监视IO,以及调用select函数的额外操作,效率更差。并且阻塞了两次,但是第一次阻塞在select上时,select可以监控多个IO上是否已有IO操作准备就绪,即可达到在同一个线程内同时处理多个IO请求的目的。而不像阻塞IO那种,一次只能监控一个IO虽然上述方式允许单线程内处理多个IO请求,但是每个IO请求的过程还是阻塞的(在select函数上阻塞),平均时间甚至比同步阻塞IO模型还要长。如果用户线程只是注册自己需要的IO请求,然后去做自己的事情,等到数据到来时再进行处理,则可以提高CPU的利用率IO多路复用是最常使用的IO模型,但是其异步程度还不够“彻底”,因它使用了会阻塞线程的select系统调用。因此IO多路复用只能称为异步阻塞IO模型,而非真正的异步IO
优缺点:
- 优点:可以基于一个阻塞对象,同时在多个描述符上等待就绪,而不是使用多个线程(每个文件描述符一个线程),这样可以大大节省系统资源
- 缺点:当连接数较少时效率相比多线程+阻塞 I/O 模型效率较低,可能延迟更大,因为单个连接处理需要 2 次系统调用,占用时间会有增加
IO多路复用适用如下场合:
- 当客户端处理多个描述符时(一般是交互式输入和网络套接口),必须使用I/O复用
- 当一个客户端同时处理多个套接字时,此情况可能的但很少出现
- 当一个服务器既要处理监听套接字,又要处理已连接套接字,一般也要用到I/O复用
- 当一个服务器即要处理TCP,又要处理UDP,一般要使用I/O复用
- 当一个服务器要处理多个服务或多个协议,一般要使用I/O复用
d.信号驱动式 I/O 模型 (signal-driven IO)
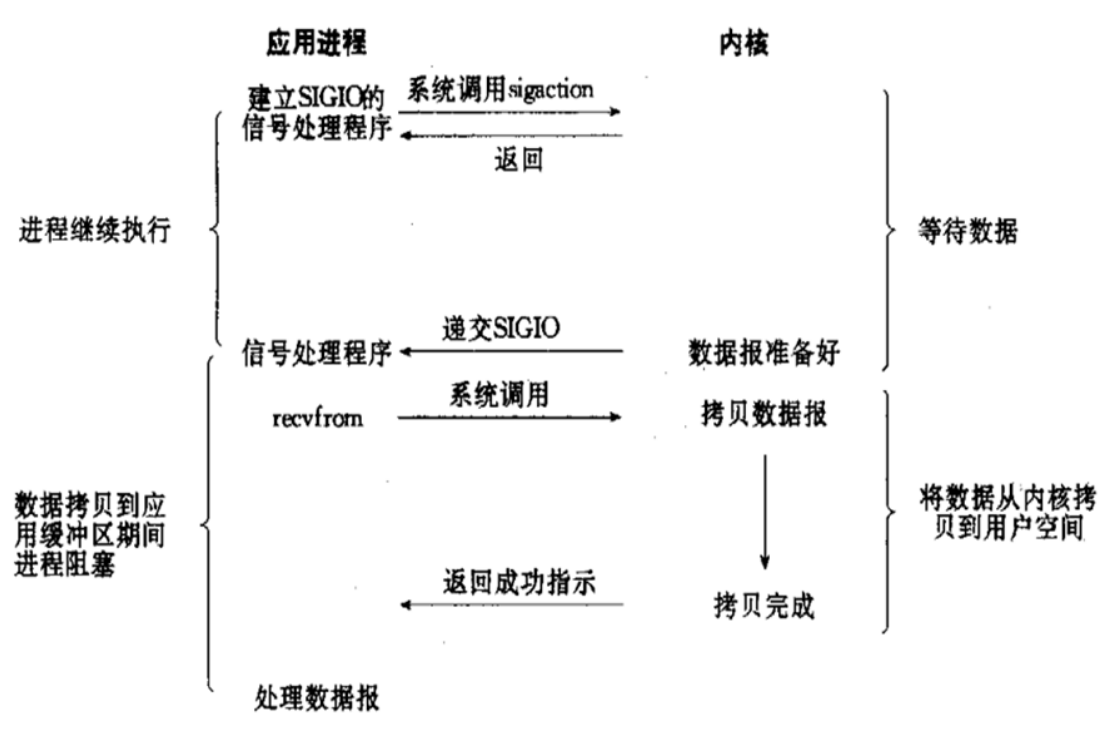
信号驱动I/O的意思就是进程现在不用傻等着,也不用去轮询。而是让内核在数据就绪时,发送信号通知进程。
调用的步骤:通过系统调用 sigaction ,并注册一个信号处理的回调函数,该调用会立即返回,然后主程序可以继续向下执行,当有I/O操作准备就绪,即内核数据就绪时,内核会为该进程产生一个 SIGIO信号,并回调注册的信号回调函数,这样就可以在信号回调函数中系统调用 recvfrom 获取数据,将用户进程所需要的数据从内核空间拷贝到用户空间
此模型的优势在于等待数据报到达期间进程不被阻塞。用户主程序可以继续执行,只要等待来自信号处理函数的通知。
在信号驱动式 I/O 模型中,应用程序使用套接口进行信号驱动 I/O,并安装一个信号处理函数,进程继续运行并不阻塞
在信号驱动式 I/O 模型中,应用程序使用套接口进行信号驱动 I/O,并安装一个信号处理函数,进程继续运行并不阻塞
当数据准备好时,进程会收到一个 SIGIO 信号,可以在信号处理函数中调用 I/O 操作函数处理数据。
优点:线程并没有在等待数据时被阻塞,内核直接返回调用接收信号,不影响进程继续处理其他请求因此可以提高资源的利用率
缺点:信号 I/O 在大量 IO 操作时可能会因为信号队列溢出导致没法通知
异步阻塞:程序进程向内核发送IO调用后,不用等待内核响应,可以继续接受其他请求,内核收到进程请求后
进行的IO如果不能立即返回,就由内核等待结果,直到IO完成后内核再通知进程。
e.异步 I/O 模型 (asynchronous IO)
异步I/O 与 信号驱动I/O最大区别在于,信号驱动是内核通知用户进程何时开始一个I/O操作,而异步I/O是由内核通知用户进程I/O操作何时完成,两者有本质区别,相当于不用去饭店场吃饭,直接点个外卖,把等待上菜的时间也给省了
相对于同步I/O,异步I/O不是顺序执行。用户进程进行aio_read系统调用之后,无论内核数据是否准备好,都会直接返回给用户进程,然后用户态进程可以去做别的事情。等到socket数据准备好了,内核直接复制数据给进程,然后从内核向进程发送通知。IO两个阶段,进程都是非阻塞的。
信号驱动IO当内核通知触发信号处理程序时,信号处理程序还需要阻塞在从内核空间缓冲区拷贝数据到用户空间缓冲区这个阶段,而异步IO直接是在第二个阶段完成后,内核直接通知用户线程可以进行后续操作了
优点:异步 I/O 能够充分利用 DMA 特性,让 I/O 操作与计算重叠
缺点:要实现真正的异步 I/O,操作系统需要做大量的工作。目前 Windows 下通过 IOCP 实现了真正的
异步 I/O,在 Linux 系统下,Linux 2.6才引入,目前 AIO 并不完善,因此在 Linux 下实现高并发网络编程时以 IO 复用模型模式+多线程任务的架构基本可以满足需求
Linux提供了AIO库函数实现异步,但是用的很少。目前有很多开源的异步IO库,例如libevent、libev、libuv。
异步非阻塞:程序进程向内核发送IO调用后,不用等待内核响应,可以继续接受其他请求,内核调用的IO如果不能立即返回,内核会继续处理其他事物,直到IO完成后将结果通知给内核,内核在将IO完成的结果返回给进程,期间进程可以接受新的请求,内核也可以处理新的事物,因此相互不影响,可以实现较大的同时并实现较高的IO复用,因此异步非阻塞使用最多的一种通信方式。
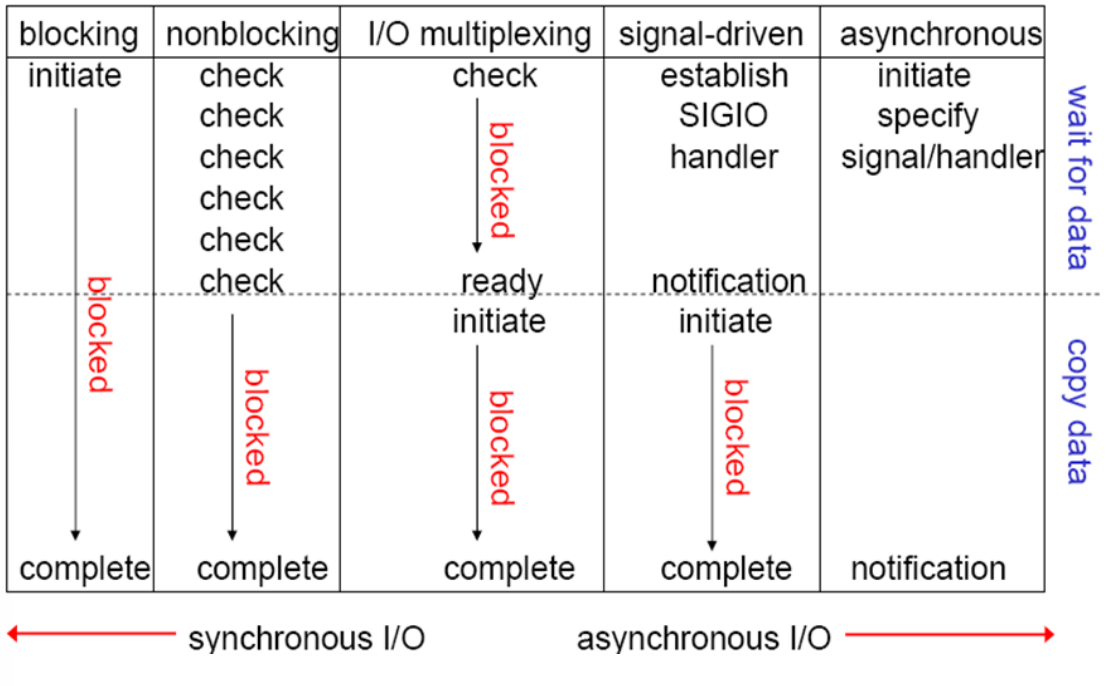
3.五种 IO 对比
这五种 I/O 模型中,越往后,阻塞越少,理论上效率也是最优前四种属于同步 I/O,因为其中真正的 I/O操作(recvfrom)将阻塞进程/线程,只有异步 I/O 模型才与 POSIX 定义的异步 I/O 相匹配
4.I/O 的具体实现方式
a.I/O常见实现
Nginx支持在多种不同的操作系统实现不同的事件驱动模型,但是其在不同的操作系统甚至是不同的系统版本上面的实现方式不尽相同,主要有以下实现方式:
1、select:
select库是在linux和windows平台都基本支持的 事件驱动模型库,并且在接口的定义也基本相同,只是部分参数的含义略有差异,最大并发限制1024,是最早期的事件驱动模型。
2、poll:
在Linux 的基本驱动模型,windows不支持此驱动模型,是select的升级版,取消了最大的并发限制,在编译nginx的时候可以使用--with-poll_module和--without-poll_module这两个指定是否编译select库。
3、epoll:
epoll是库是Nginx服务器支持的最高性能的事件驱动库之一,是公认的非常优秀的事件驱动模型,它和select和poll有很大的区别,epoll是poll的升级版,但是与poll有很大的区别.epoll的处理方式是创建一个待处理的事件列表,然后把这个列表发给内核,返回的时候在去轮询检查这个表,以判断事件是否发生,epoll支持一个进程打开的最大事件描述符的上限是系统可以打开的文件的最大数,同时epoll库的I/O效率不随描述符数目增加而线性下降,因为它只会对内核上报的“活跃”的描述符进行操作。
4、kqueue:
用于支持BSD系列平台的高校事件驱动模型,主要用在FreeBSD 4.1及以上版本、OpenBSD 2.0级以上版本NetBSD级以上版本及Mac OS X 平台上,该模型也是poll库的变种,因此和epoll没有本质上的区别,都是通过避免轮询操作提供效率。
5、Iocp:
Windows系统上的实现方式,对应第5种(异步I/O)模型。
6、rtsig:
不是一个常用事件驱动,最大队列1024,不是很常用
7、/dev/poll:
用于支持unix衍生平台的高效事件驱动模型,主要在Solaris 平台、HP/UX,该模型是sun公司在开发Solaris系列平台的时候提出的用于完成事件驱动机制的方案,它使用了虚拟的/dev/poll设备,开发人员将要见识的文件描述符加入这个设备,然后通过ioctl()调用来获取事件通知,因此运行在以上系列平台的时候请使用/dev/poll事件驱动机制。
8、eventport:
该方案也是sun公司在开发Solaris的时候提出的事件驱动库,只是Solaris 10以上的版本,该驱动库看防止内核崩溃等情况的发生。
5.零拷贝
零拷贝就是上述问题的一个解决方案,通过尽量避免拷贝操作来缓解 CPU 的压力。零拷贝并没有真正做到“0”拷贝,它更多是一种思想,很多的零拷贝技术都是基于这个思想去做的优化
a.MMAP ( Memory Mapping )
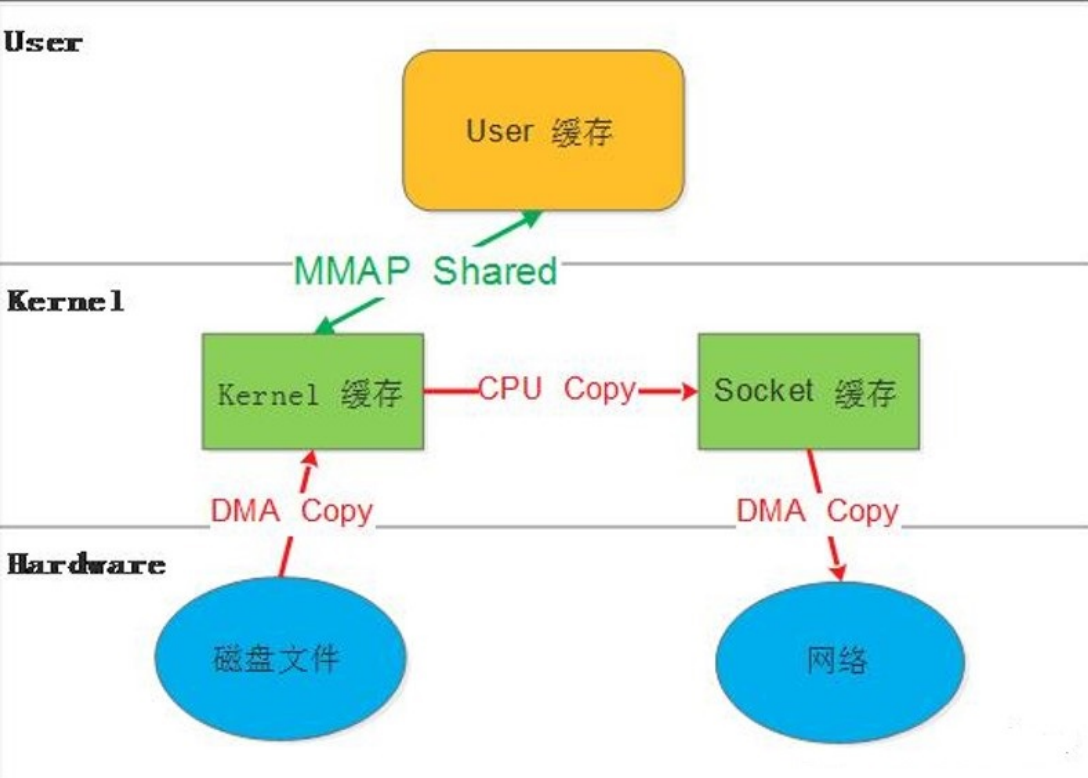
mmap()系统调用使得进程之间通过映射同一个普通文件实现共享内存。普通文件被映射到进程地址空间后,进程可以向访问普通内存一样对文件进行访问。
mmap是一种内存映射文件的方法,即将一个文件或者其它对象映射到进程的地址空间,实现文件磁盘地址和进程虚拟地址空间中一段虚拟地址的一一对映关系。
实现这样的映射关系后,进程就可以采用指针的方式读写操作这一段内存,而系统会自动回写脏页面到对应的文件磁盘上,即完成了对文件的操作而不必再调用read,write等系统调用函数。相反,内核空间对这段区域的修改也直接反映用户空间,从而可以实现不同进程间的文件共享。
内存映射减少数据在用户空间和内核空间之间的拷贝操作,适合大量数据传输
b.SENDFILE
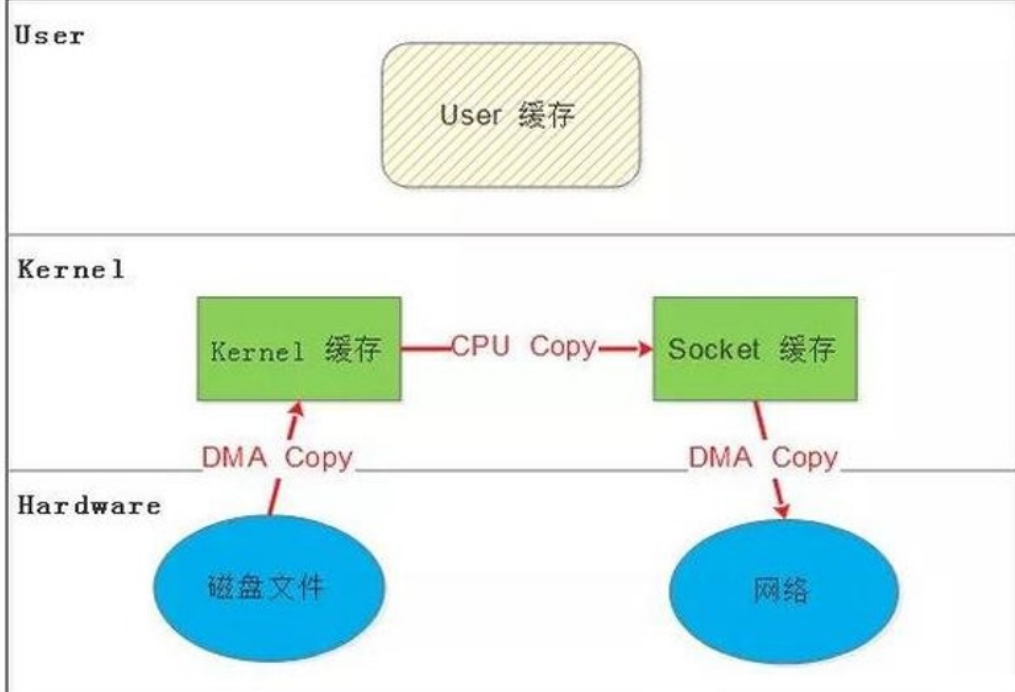
c.DMA 辅助的 SENDFILE
六、nginx解决高并发问题(全局配置)
user nginx nginx; | #启动Nginx工作进程的用户和组 |
worker_processes [number | auto]; | #启动Nginx工作进程的数量,一般设为和CPU核心数相同 |
worker_cpu_affinity 00000001 00000010 00000100 00001000 | auto ; | #将Nginx工作进程绑定到指定的CPU核心,默认Nginx是不进行进程绑定的,绑定并不是意味着当前nginx进 程独占以一核心CPU,但是可以保证此进程不运行在其他核心上,这就极大减少了nginx的工作进程在不同的 cpu核心上的来回跳转,减少了CPU对进程的资源分配与回收以及内存管理等,因此可以有效的提升nginx服务 器的性能。 |
CPU MASK: | 00000001:0号CPU 00000010:1号CPU 10000000:7号CPU |
daemon off; | #前台运行Nginx服务用于测试、docker等环境。 |
master_process off|on; | #是否开启Nginx的master-worker工作模式,仅用于开发调试场景,默认为 on |
events{}中:
worker_connections 65535; | #设置单个工作进程的最大并发连接数 |
use epoll; | #使用epoll事件驱动, #Nginx支持众多的事件驱动, #比如:select、poll、epoll,只能设置在events模块中设置 |
accept_mutex on; | #on为同一时刻一个请求轮流由work进程处理, #而防止被同时唤醒所有worker #避免多个睡眠进程被唤醒的设置,默认为off #新请求会唤醒所有worker进程,此过程也称为"惊群" #因此nginx刚安装完以后要进行适当的优化。建议设置为on |
multi_accept on; | #on时Nginx服务器的每个工作进程可以同时接受多个新的网络连接 #此指令默认为off, #即默认为一个工作进程只能一次接受一个新的网络连接 #打开后几个同接受多个。建议设置为on |
1.全局配置
[root@webservera ~]# cd /usr/local/nginx/conf/
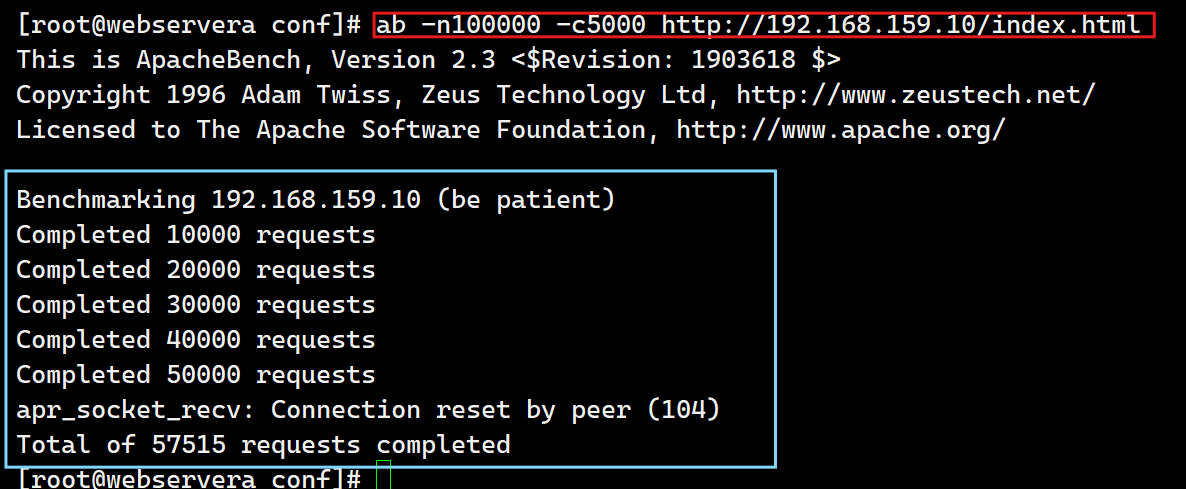
[root@webservera conf]# dnf install httpd-tools -y
-n 请求总量
-c 请求并发量
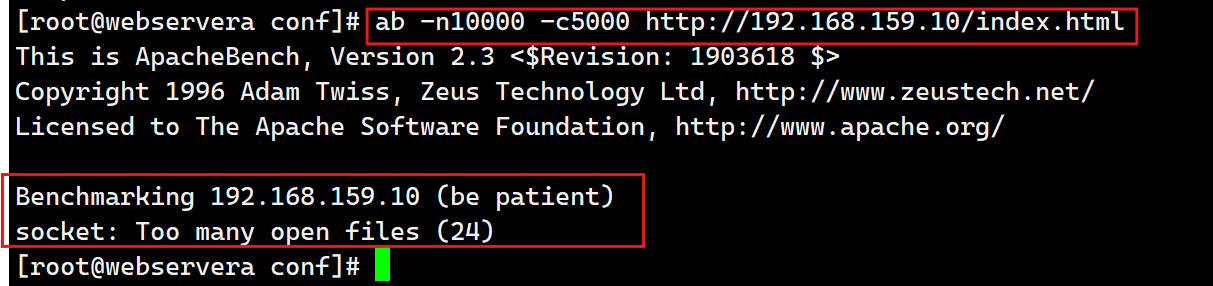
[root@webservera conf]# vim nginx.conf
修改可允许通过访问量:
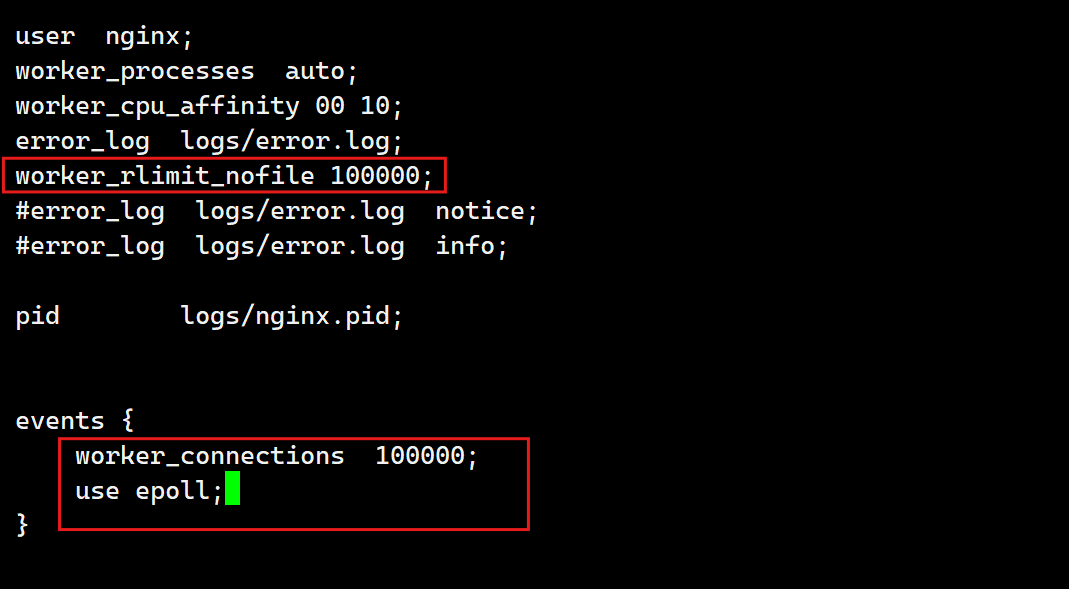

[root@webservera conf]# vim /etc/security/limits.conf 
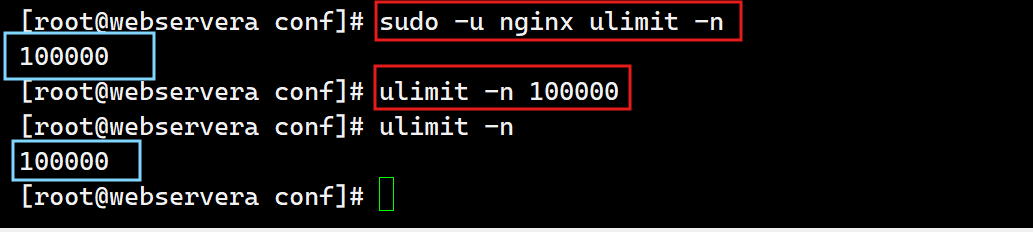
测试:
七、核心配置
1.建设基于域名的虚拟站点
基于不同的IP、不同的端口以及不用得域名实现不同的虚拟主机,依赖于核心模块
ngx_http_core_module实现。
[root@webservera conf]# vim nginx.conf
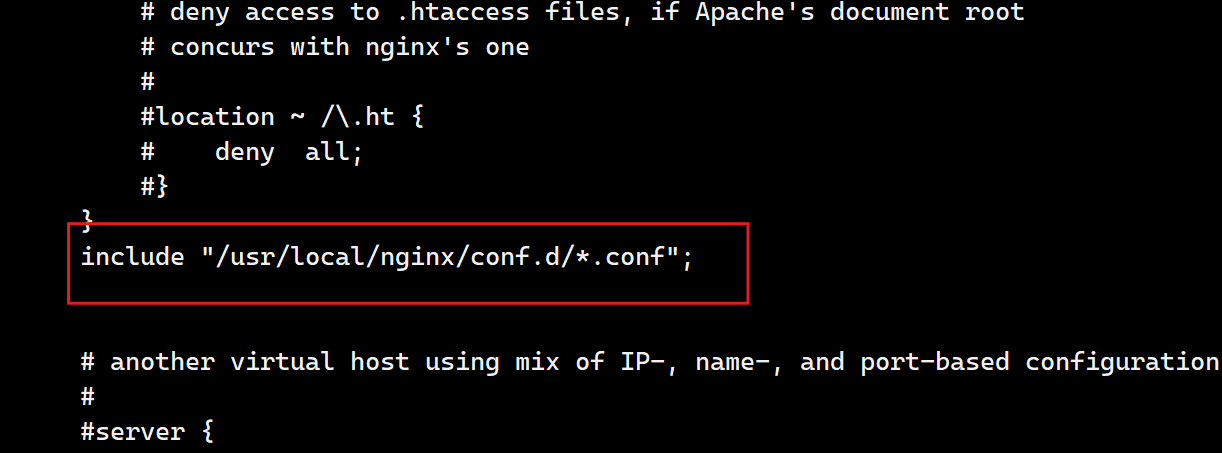
- 注意位置
[root@webservera conf]# mkdir -p /usr/local/nginx/conf.d
[root@webservera conf.d]# mkdir -p /web/html
[root@webservera conf.d]# echo web_html > /web/html/index.html
[root@webservera conf.d]# nginx -s reload
[root@webservera conf.d]# vim /etc/hosts

测试:

2.root 与 alias
root:指定web的家目录,在定义location的时候,文件的绝对路径等于 root+location
root示例:
server {
listen 80;
server_name lee.timinglee.org;
location / {
root /webdata/nginx/timinglee.org/lee/html;
}
location /dirtest { #必须建立/mnt/dirtest才能访问
root /mnt;
}
}
alias:定义路径别名,会把访问的路径重新定义到其指定的路径,文档映射的另一种机制;仅能用于
location上下文,此指令使用较少
alias示例:
Note
location中使用root指令和alias指令的意义不同
[root@Nginx ~]# mkdir /mnt/dirtest/
[root@Nginx ~]# echo dirtest page > /mnt/dirtest/index.html
[root@Nginx ~]# nginx -s reload
#重启Nginx并访问测试
[root@node100 ~]# curl lee.timinglee.org/dirtest/
dirtest pagealias:定义路径别名,会把访问的路径重新定义到其指定的路径,文档映射的另一种机制;仅能用于
location上下文,此指令使用较少
alias示例:
server {
listen 80;
server_name lee.timinglee.org;
location / {
root /webdata/nginx/timinglee.org/lee/html;
}
location /dirtest {
root /mnt;
}
location /alias { #注意about后不要加/
#使用alias的时候uri后面如果加了斜杠,则下面的路径配置
必须加斜杠,否则403
alias /mnt/dirtest; #当访问alias的时候,会显示alias定义的/mnt/dirtest
里面的内容
}
}
#重启Nginx并访问测试
[root@node100 ~]# curl lee.timinglee.org/alias/
dirtest page
[root@webservera conf.d]# vim /mnt/test.html

[root@webservera conf.d]# vim vhosts.conf
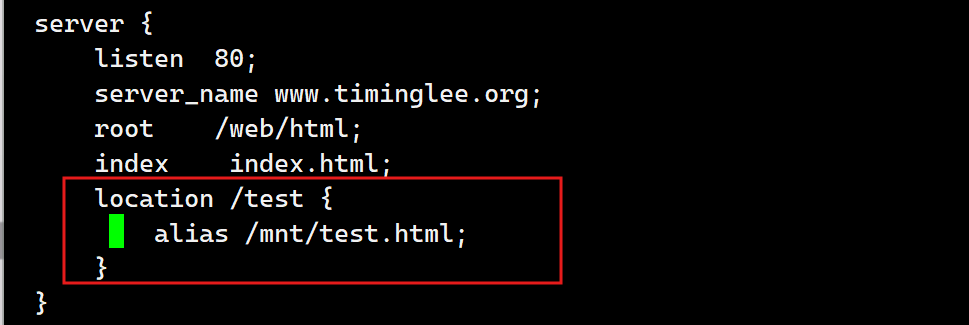 测试:
测试:

location中使用root指令和alias指令的意义不同
root | #给定的路径对应于location中的/uri左侧的/ |
alias | #给定的路径对应于location中的/uri的完整路径 |
3.location
- 在一个server中location配置段可存在多个,用于实现从uri到文件系统的路径映射;
- ngnix会根据用户请求的URI来检查定义的所有location,按一定的优先级找出一个最佳匹配,
- 而后应用其配置在没有使用正则表达式的时候,nginx会先在server中的多个location选取匹配度最高的一个uri
- uri是用户请求的字符串,即域名后面的web文件路径
- 然后使用该location模块中的正则url和字符串,如果匹配成功就结束搜索,并使用此location处理此请求。
| = | #用于标准uri前,需要请求字串与uri精确匹配,大小敏感,如果匹配成功就停止向下匹配并立 即处理请求 |
| ^~ | #用于标准uri前,表示包含正则表达式,并且匹配以指定的正则表达式开头 #对uri的最左边部分做匹配检查,不区分字符大小写 |
| ~ | #用于标准uri前,表示包含正则表达式,并且区分大小写 |
| ~* | #用于标准uri前,表示包含正则表达式,并且不区分大写 |
| 不带符号 | #匹配起始于此uri的所有的uri |
| \ | #用于标准uri前,表示包含正则表达式并且转义字符。可以将 . * ?等转义为普通符号 |
a.精确匹配(=)
在server部分使用location配置一个web界面,例如:当访问nginx 服务器的/logo.jpg的时候要显示指定html文件的内容,精确匹配一般用于匹配组织的logo等相对固定的URL,匹配优先级最高
[root@webservera conf.d]# /usr/local/nginx/conf.d
[root@webservera conf.d]# vim vhosts.conf
[root@webservera conf.d]# nginx -s reload
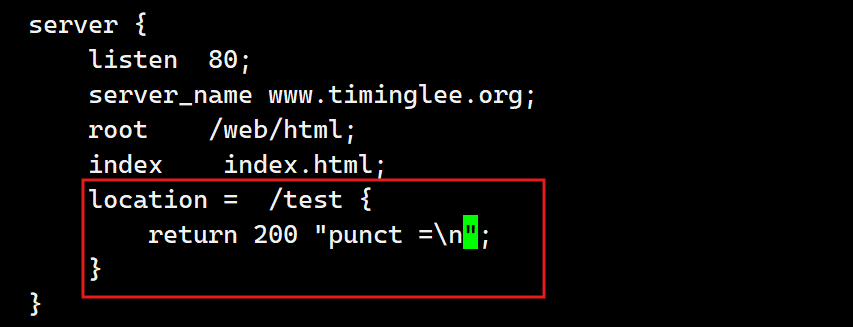
测试:

b.区分大小写
~ 实现区分大小写的模糊匹配. 以下范例中, 如果访问uri中包含大写字母的logo.PNG,则以下location匹配logo.png条件不成功因为 ~ 区分大小写,当用户的请求被执行匹配时发现location中定义的是小写的png本次访问的uri匹配失败,后续要么继续往下匹配其他的location(如果有),要么报错给客户端
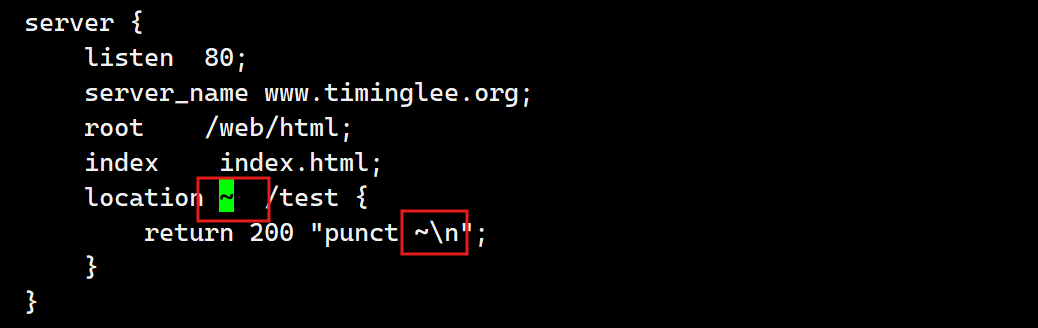
测试:
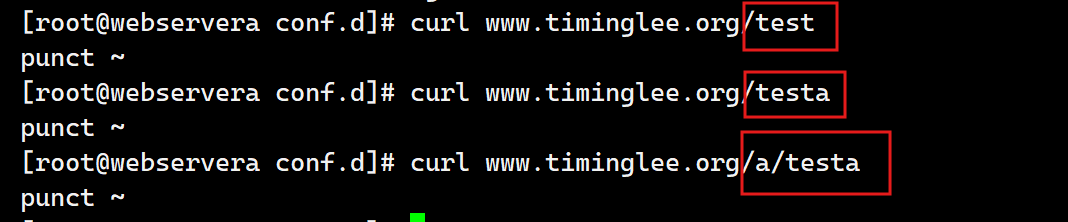
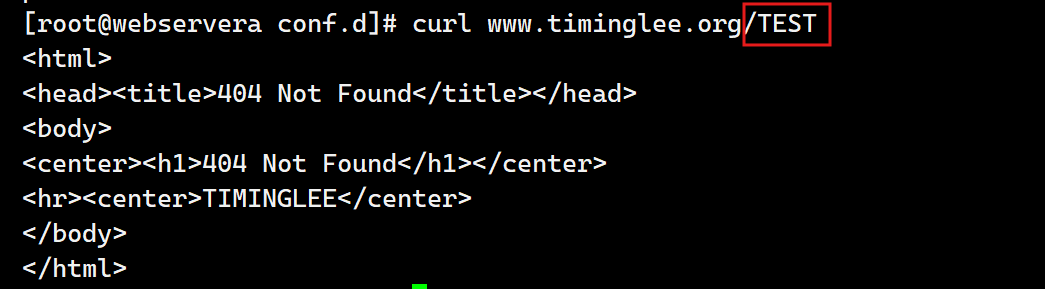
c.不区分大小写
~* 用来对用户请求的uri做模糊匹配,uri中无论都是大写、都是小写或者大小写混合,此模式也都会匹配,通常使用此模式匹配用户request中的静态资源并继续做下一步操作,此方式使用较多
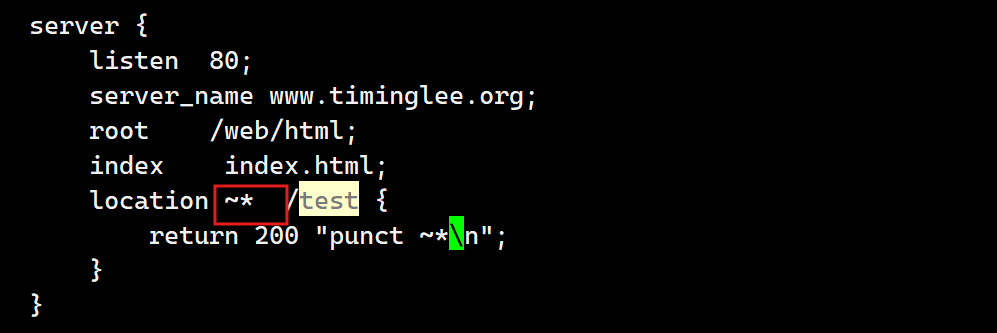
测试:

d.URI开始(^~ 区分大小写)
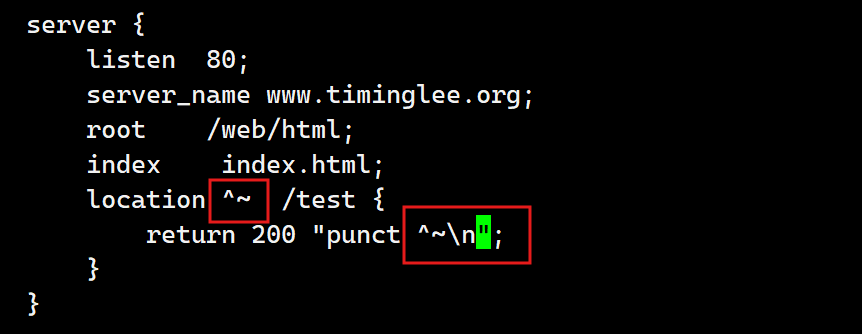
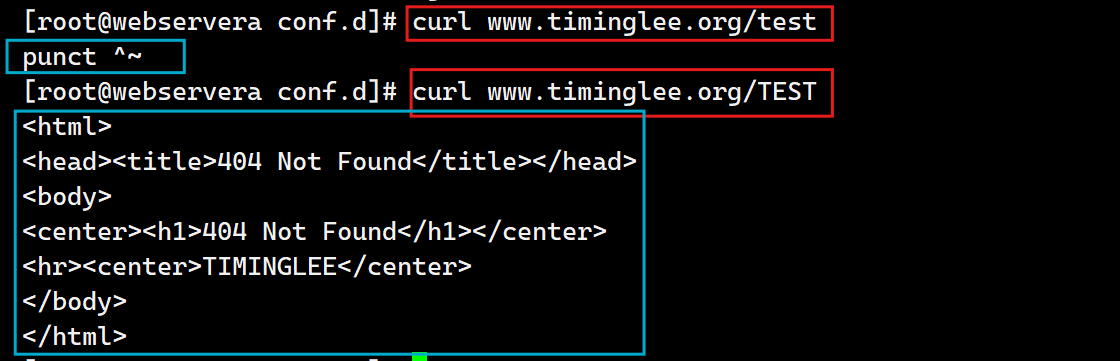
测试:
4.Nginx 账户认证功能
由 ngx_http_auth_basic_module 模块提供此功能
[root@webservera ~]# cd /usr/local/nginx/conf.d/
[root@webservera conf.d]# mkdir -p /web/login
[root@webservera conf.d]# echo login > /web/login/index.html
创建nginx所需认证文件:
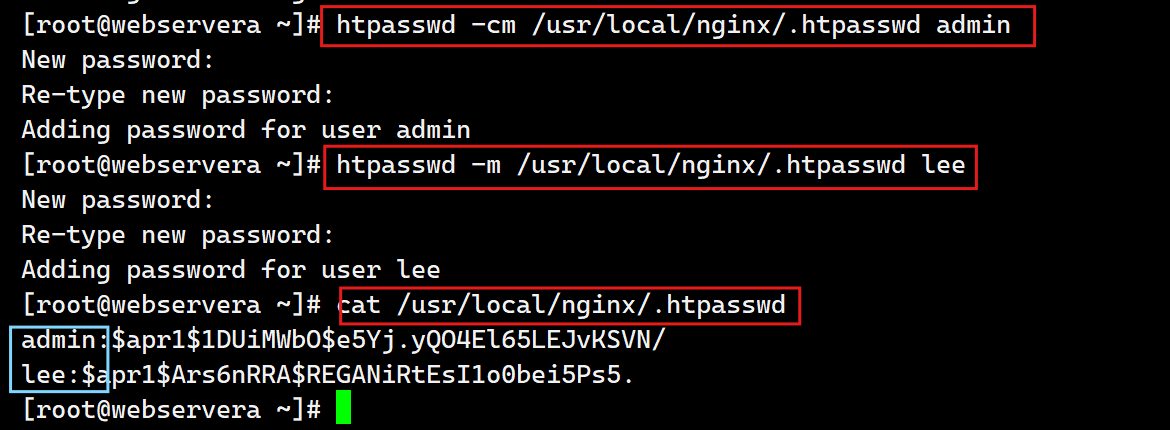
[root@webservera ~]# htpasswd -cm /usr/local/nginx/.htpasswd admin
[root@webservera ~]# htpasswd -m /usr/local/nginx/.htpasswd lee
- 当认证文件不存在时加-c建立,当认证文件存在时,加-c会覆盖原认证文件内容
[root@webservera ~]# vim /usr/local/nginx/conf.d/vhosts.conf 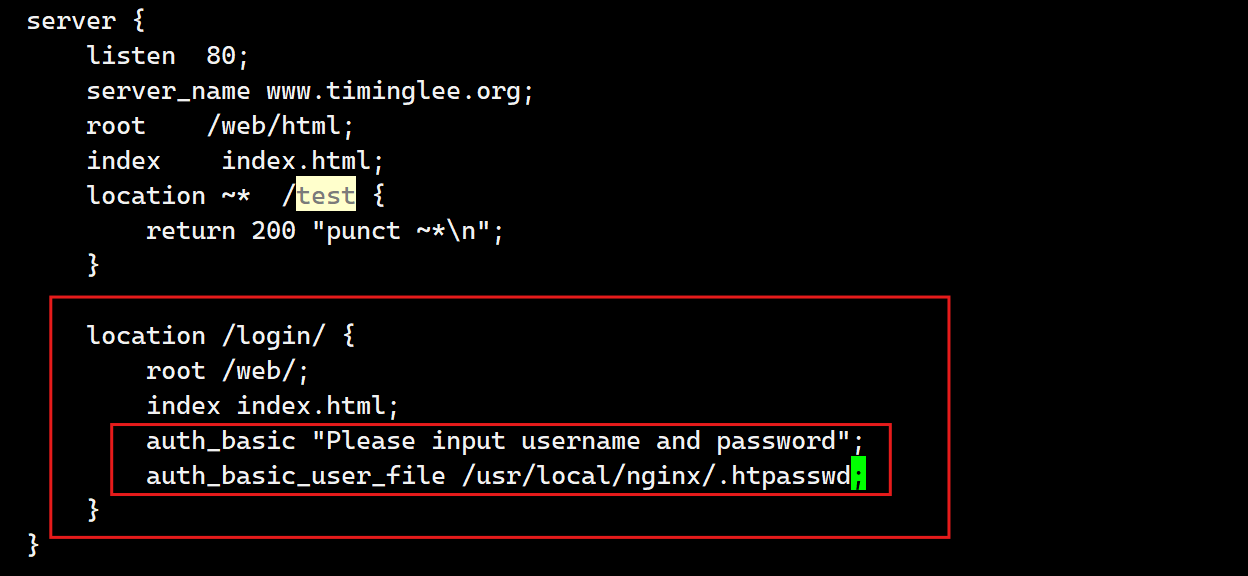
测试:
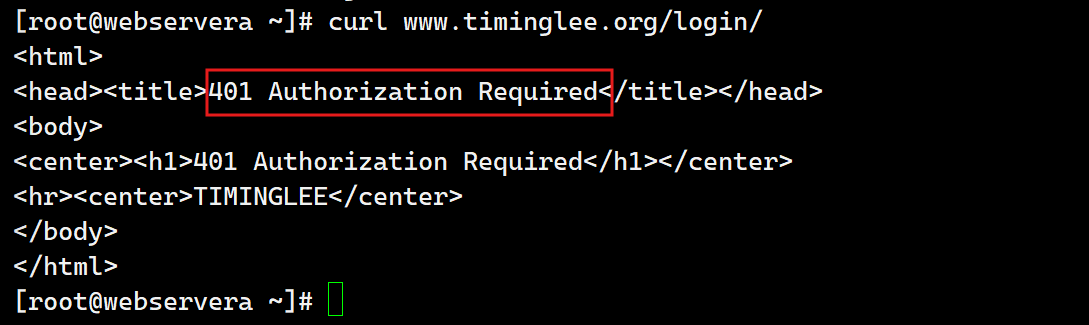

5.自定义错误页面
[root@webservera ~]# cd /usr/local/nginx/conf.d/
[root@webservera conf.d]# mkdir /web/errorpage
[root@webservera conf.d]# echo "出错误了" > /web/errorpage/error.html
[root@webservera conf.d]# vim vhosts.conf 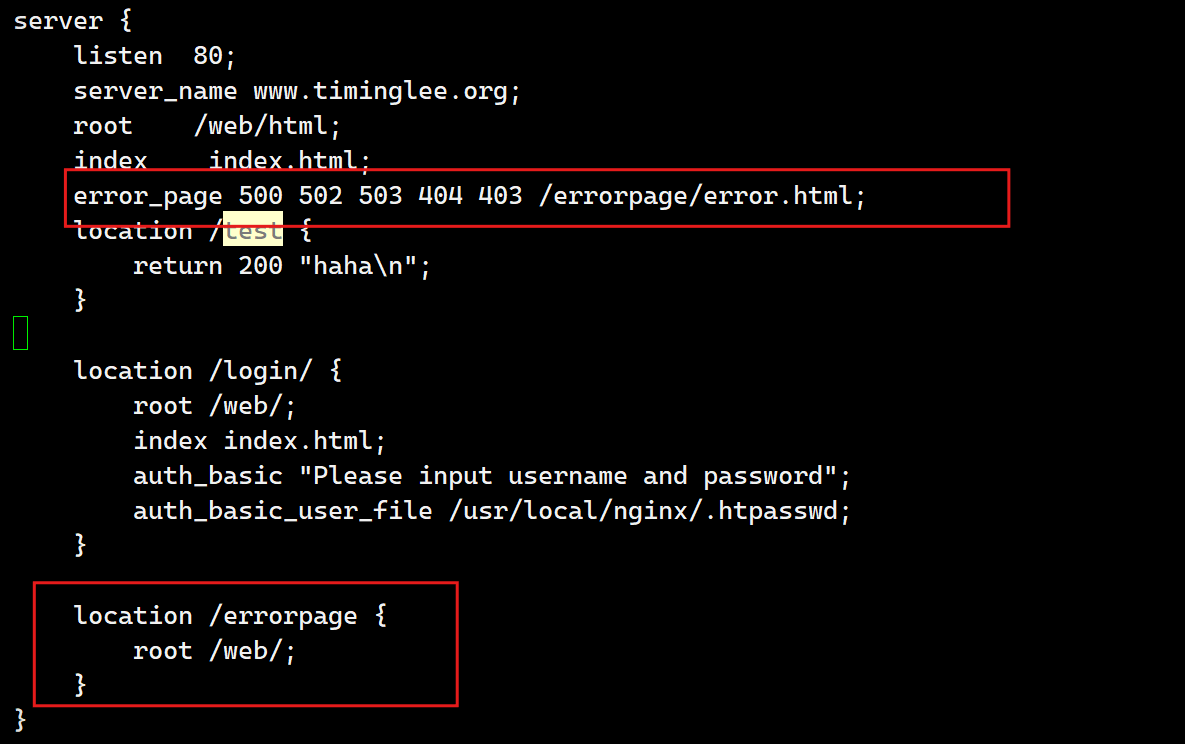
[root@webservera conf.d]# nginx -t
测试:

6.自定义错误日志
Syntax: error_log file [level]; Default: error_log logs/error.log error; Context: main, http, mail, stream, server, location level: debug, info, notice, warn, error, crit, alert, emerg |
[root@webservera logs]# cd /usr/local/nginx/conf.d/
[root@webservera conf.d]# vim vhosts.conf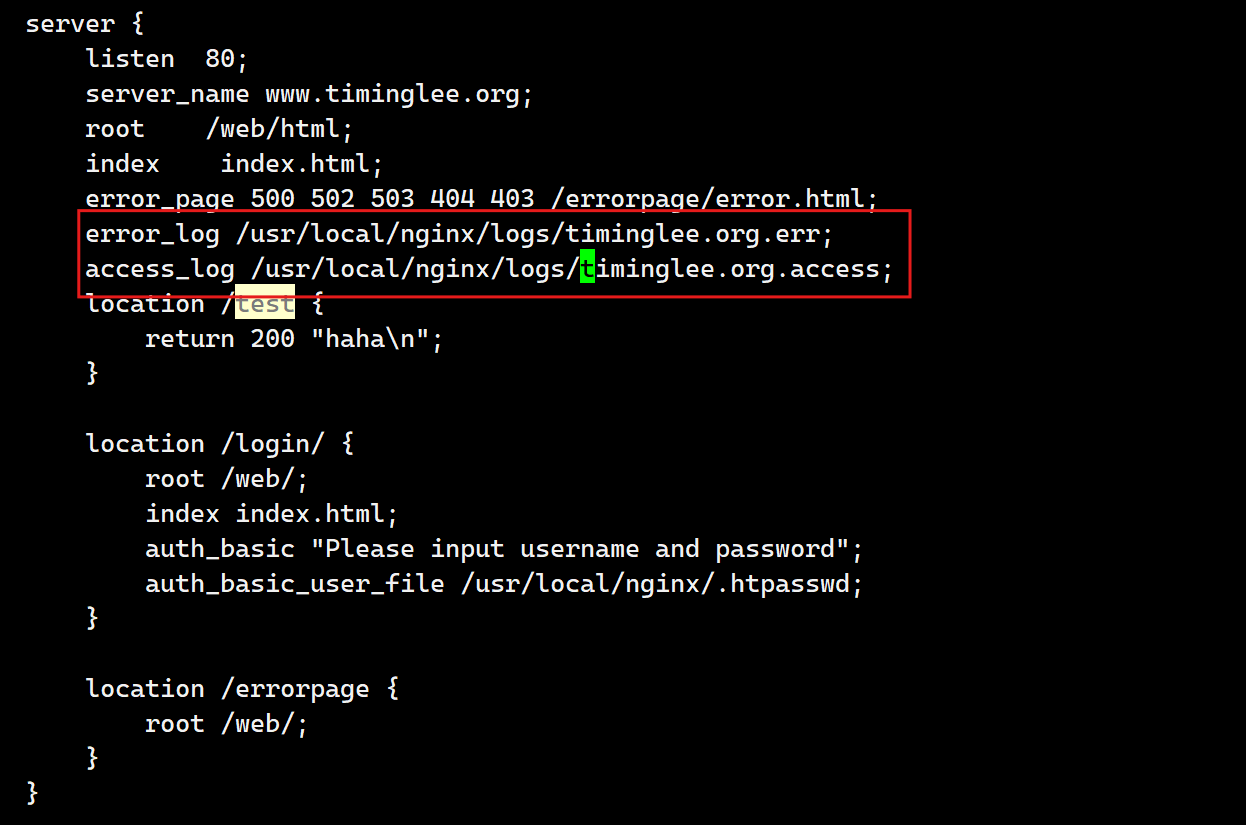
[root@webservera conf.d]# nginx -s reload

测试:
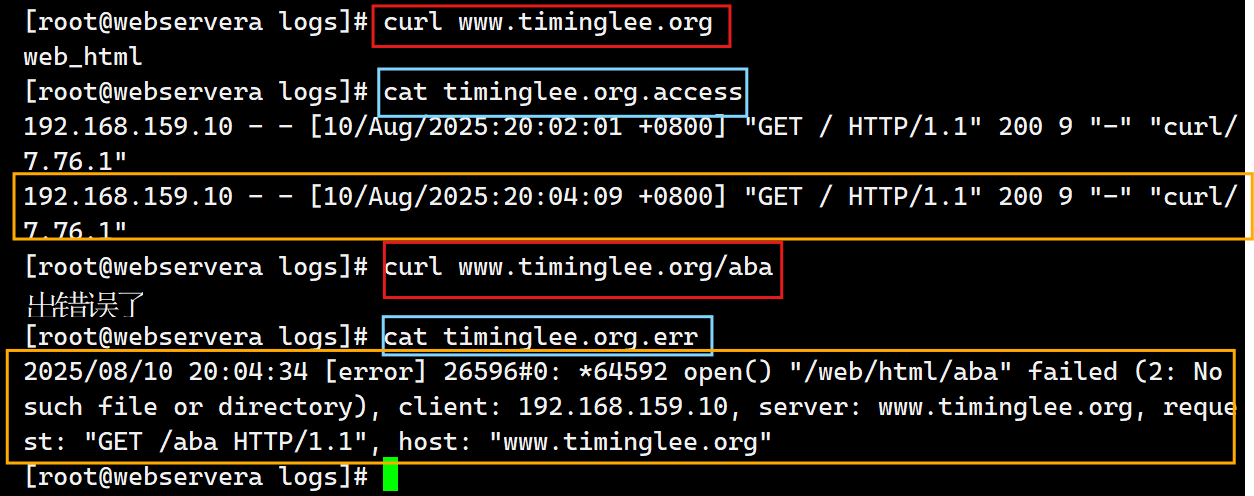
7.检测文件是否存在
Syntax: try_files file ... uri; try_files file ... =code; Default: — Context: server, location |
[root@webservera logs]# cd /usr/local/nginx/conf.d/
[root@webservera conf.d]# vim vhosts.conf- 当检测所有指定文件不存在时访问default.html
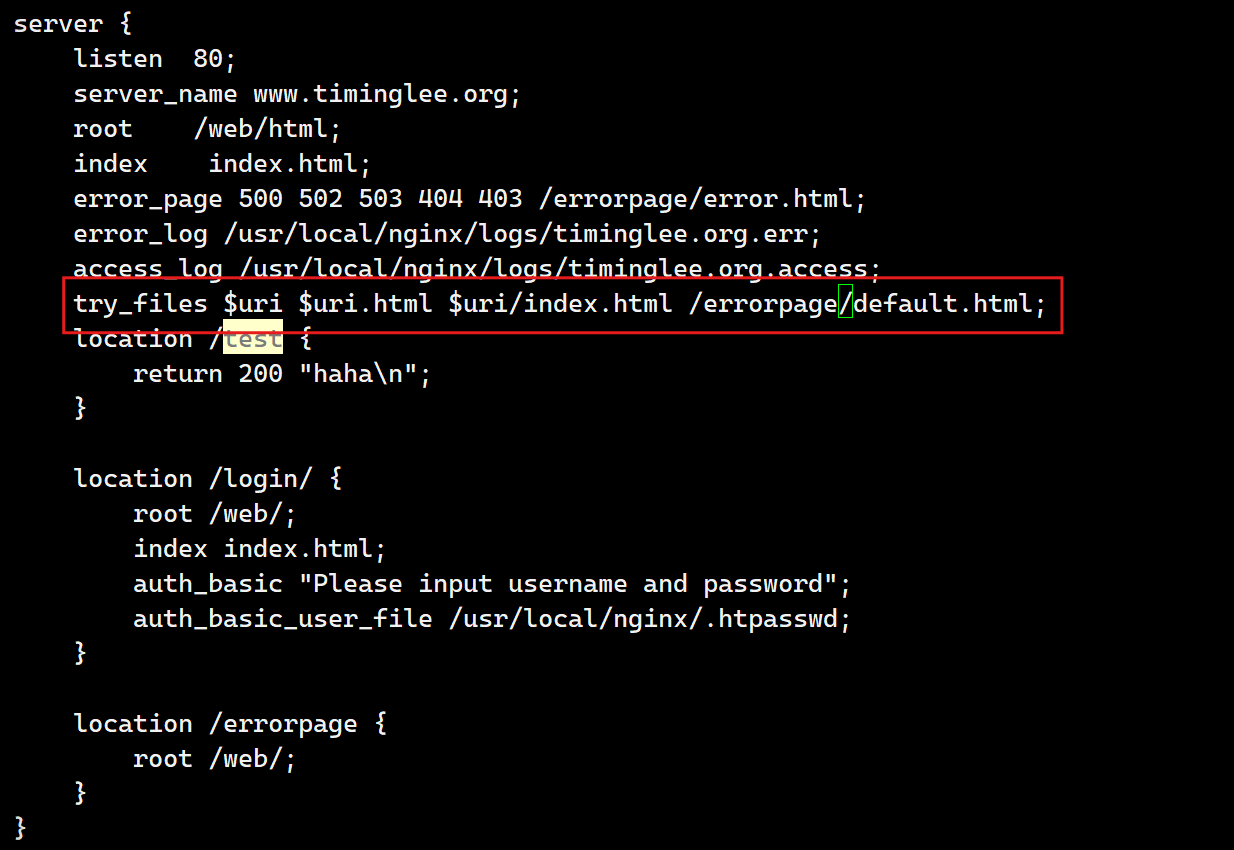
[root@webservera conf.d]# echo default > /web/errorpage/default.html
[root@webservera conf.d]# nginx -s reload

测试:

8.长连接配置
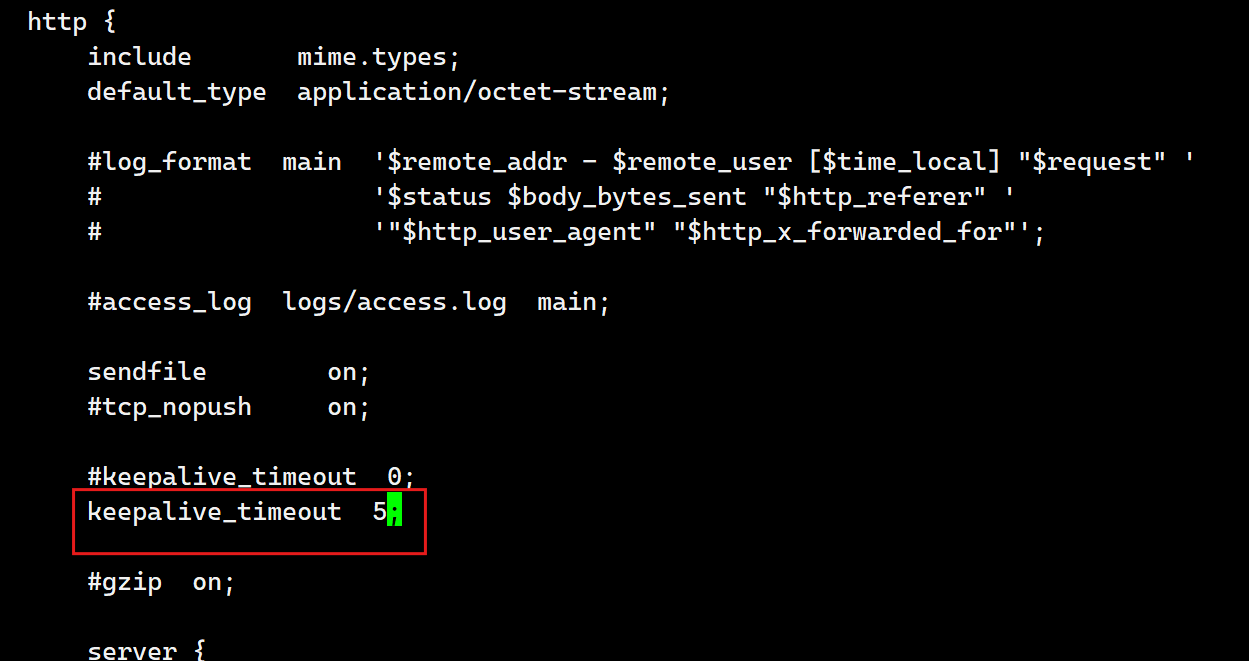
keepalive_timeout timeout [header_timeout]; | #设定保持连接超时时长,0表示禁止长连接,默认为75s #通常配置在http字段作为站点全局配置 |
keepalive_requests 数字; | #在一次长连接上所允许请求的资源的最大数量 #默认为100次,建议适当调大,比如:500 |
[root@webservera ~]# cd /usr/local/nginx/conf
[root@webservera conf]# vim nginx.conf
- 5s后自动断开长链接
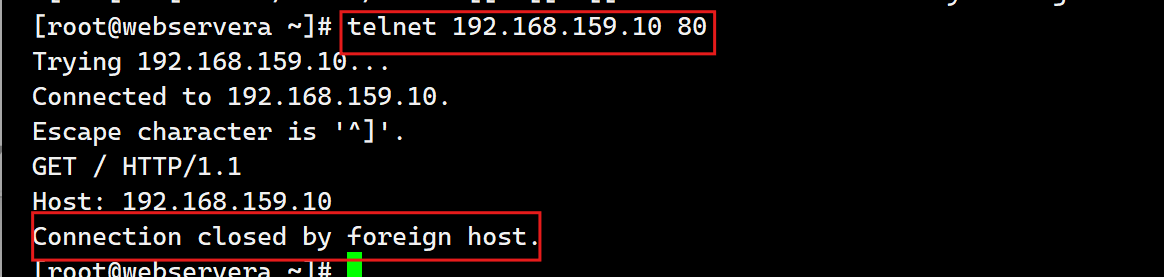
测试:
安装测试软件:
[root@webservera ~]# dnf install telnet -y
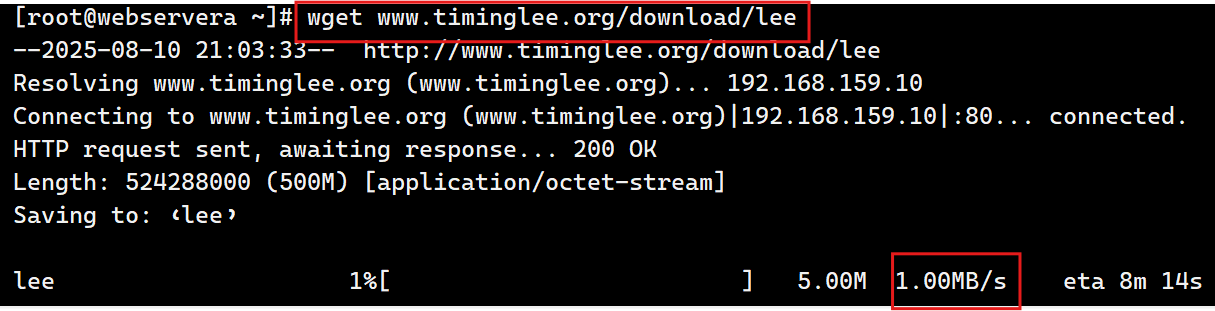
9.作为下载服务器配置
autoindex on | off; | #自动文件索引功能,默为off |
autoindex_exact_size on | off; | #计算文件确切大小(单位bytes),off 显示大概大小(单位K、 M),默认on |
autoindex_localtime on | off ; | #显示本机时间而非GMT(格林威治)时间,默认off |
autoindex_format html | xml | json | jsonp; | #显示索引的页面文件风格,默认html |
limit_rate rate; | #限制响应客户端传输速率(除GET和HEAD以外的所有方法),单位 B/s,bytes/second, #默认值0,表示无限制,此指令由 ngx_http_core_module提供 |
set $limit_rate 4k; | #也可以通变量限速,单位B/s,同时设置,此项优级高 |
创建共享资源的存放目录:
[root@webservera ~]# mkdir /web/download
建立对应目录下的资源文件:
[root@webservera ~]# dd if=/dev/zero of=/web/download/lee bs=1M count=500

[root@webservera ~]# vim /usr/local/nginx/conf.d/vhosts.conf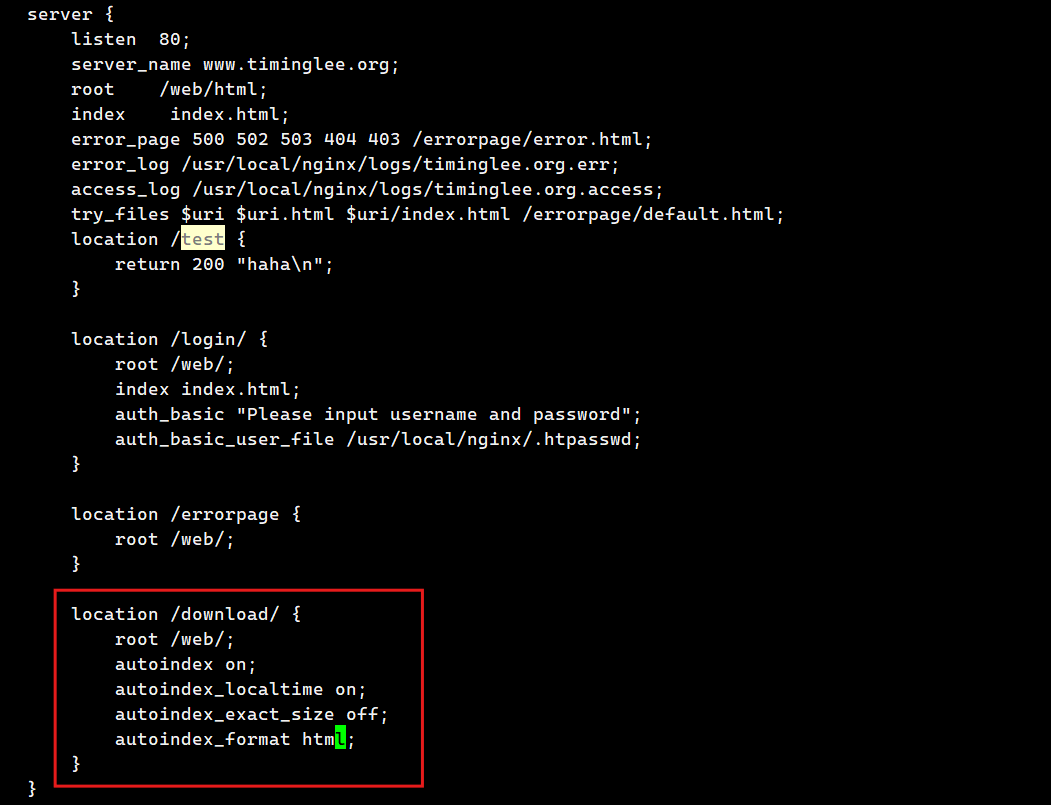
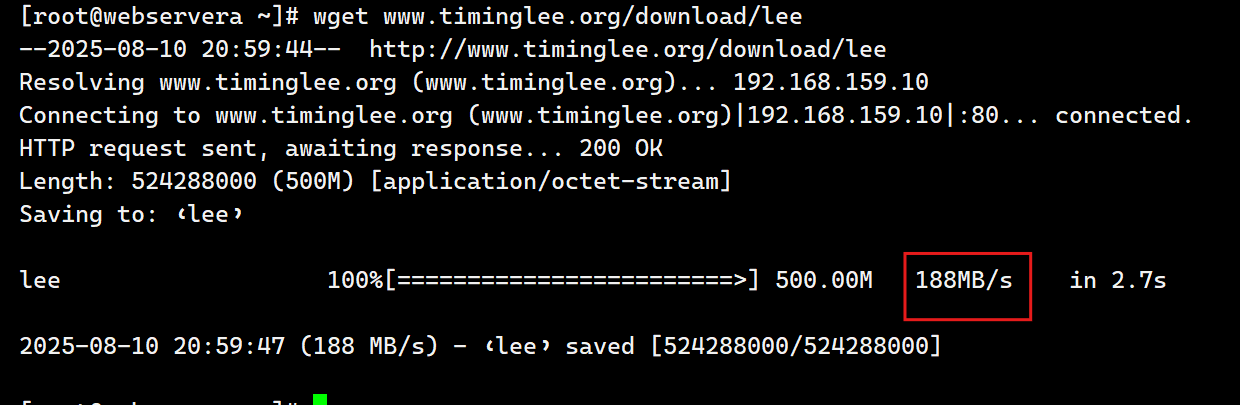
[root@webservera ~]# nginx -s reload
测试:

当文件内容下载过快时设置限速:
[root@webservera ~]# vim /usr/local/nginx/conf.d/vhosts.conf 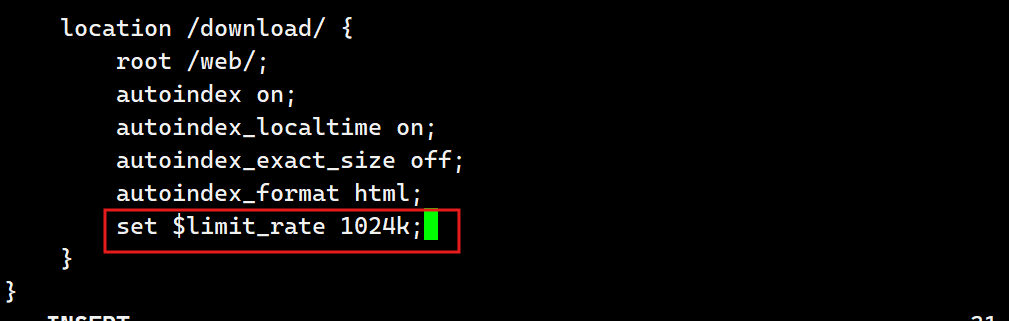
测试: