BM25算法记忆
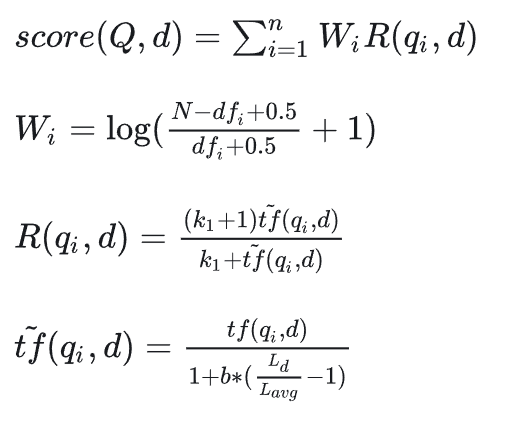
公式1:query和document的关联性得分;
公式2:单个query中的关键词对应的权重,关键词出现在很多文档中,说明它不关键,可能是句号、的、是,等等;
公式3:document和Qi关联性,与query中的关键词在document出现频率有关,但不是线性关系;
公式4:加权的词频,权衡文章长短对词频的影响;
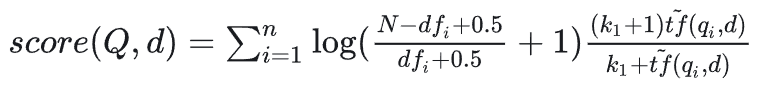
公式5:综合关键词在所有文档中的词频和在单个文档中的词频考虑最终得分,得分要高,需要在别的文档很少出现,在本文档高频出现;

它非常适合对大量文档(如数字图书馆)进行分类,而不会偏向较长的文档或过度使用的词语。
BM25 算法是一个强大、高效且在实践中表现良好的基线检索算法。它的优点在于对词频饱和度和文档长度的有效处理,以及计算效率高。然而,它的主要缺点在于缺乏对语义的理解,这使得它在面对复杂、口语化或语义相关的查询时,性能可能不如基于深度学习的语义检索方法。因此,在现代信息检索系统中,BM25 常常与向量搜索(语义搜索)结合使用,形成混合搜索,以弥补各自的不足。
OpenSearch 官方教程中的 BM25 与语义搜索基础讲解