爬虫与数据分析相结合案例总结
一、案例概述
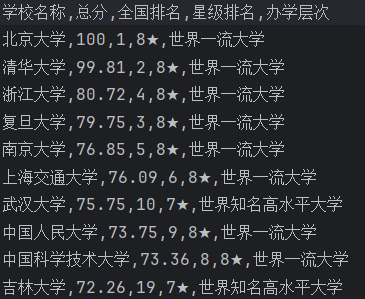
本案例通过爬取“高三网”中国大学排名数据(学校名称、总分、排名、星级等),结合 Python爬虫技术 和 Pandas/Matplotlib数据分析工具,完成以下流程:
数据爬取 → 2. 数据存储(CSV) → 3. 数据预处理 → 4. 数据分析与可视化
二、核心知识点总结
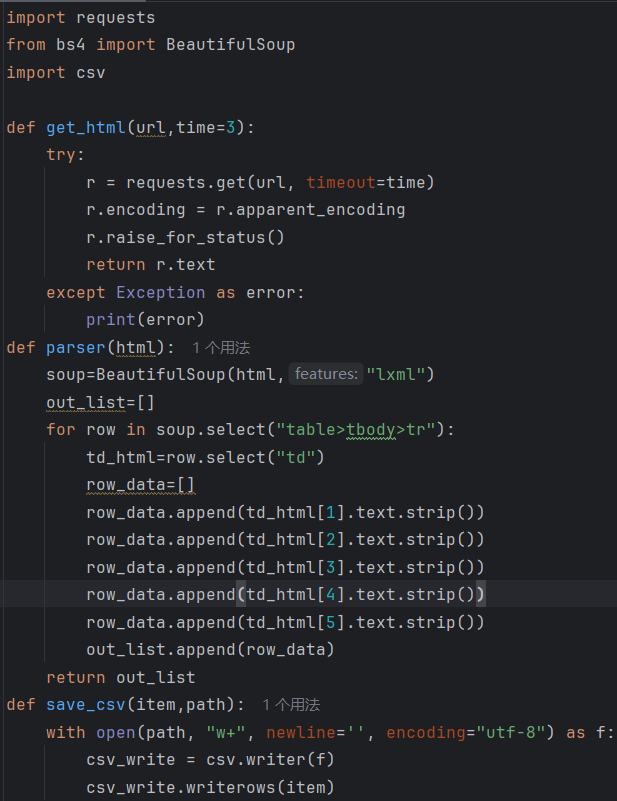
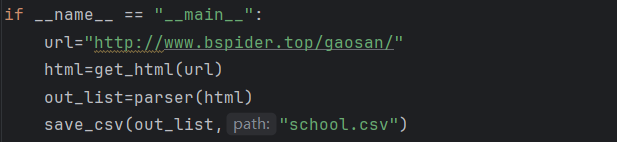
1. 数据爬取(爬虫技术)
代码:
2. 数据预处理(Pandas)
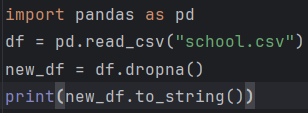
问题:总分列存在空值(NaN)。
解决方法:
删除空行:
df.dropna(subset=["总分"], inplace=True)
代码:
替换空值:
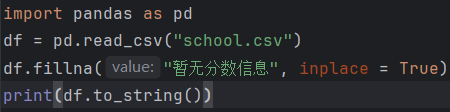
用固定值填充(如"暂无分数"):
df["总分"].fillna("暂无分数", inplace=True) 用均值/中位数填充:
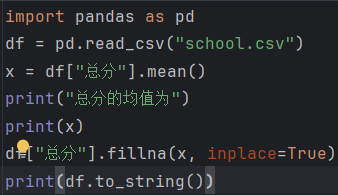
mean_score = df["总分"].mean() df["总分"].fillna(mean_score, inplace=True)
代码:
3. 数据分析与可视化
可视化工具:Matplotlib。
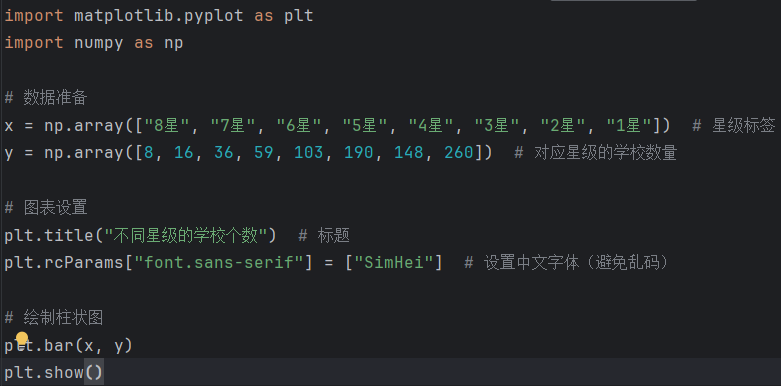
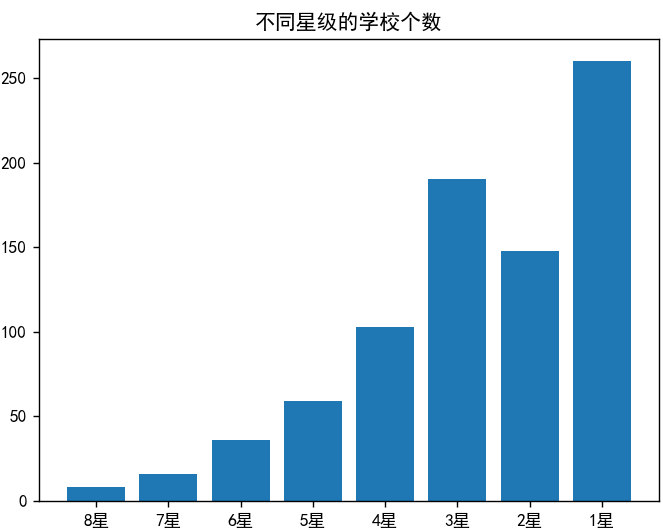
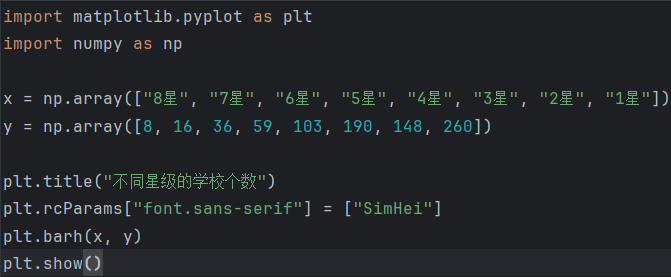
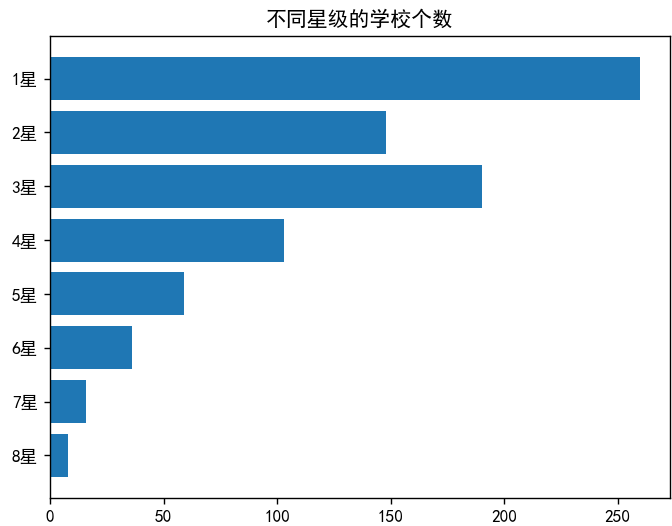
柱状图(直观对比数量):
plt.bar(["8星", "7星", ...], [8, 16, ...])
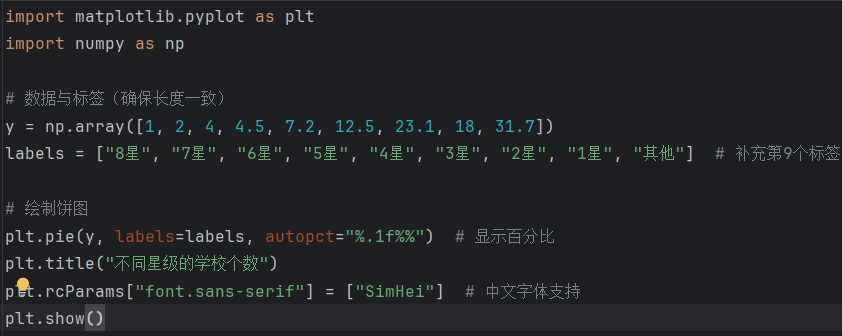
plt.title("不同星级学校数量分布") 饼图(展示占比):
plt.pie([8, 16, ...], labels=["8星", "7星", ...], autopct="%.1f%%")
代码:
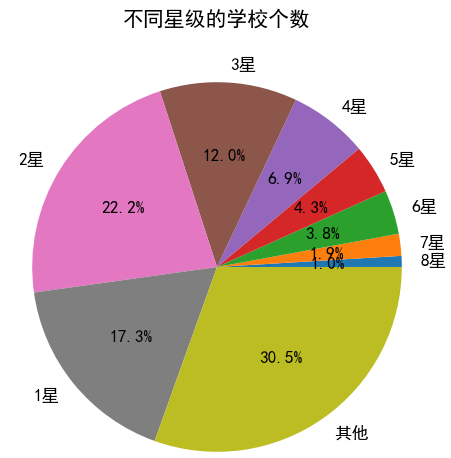
4. 关键注意事项
中文显示问题:
plt.rcParams["font.sans-serif"] = ["SimHei"] # 解决Matplotlib中文乱码
数据一致性:
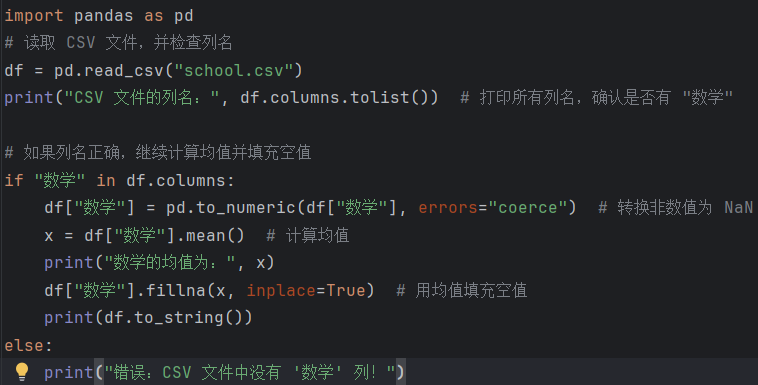
确保爬取字段与CSV列名匹配(如总分列名需一致)。
可视化时,数据与标签长度必须一致(避免 ValueError)。
三、案例技术栈
| 步骤 | 工具/库 | 关键方法/函数 |
|---|---|---|
| 数据爬取 | requests, BeautifulSoup | requests.get(), soup.find_all() |
| 数据存储 | pandas | pd.to_csv() |
| 数据预处理 | pandas | fillna(), dropna(), mean() |
| 数据可视化 | matplotlib | plt.bar(), plt.pie() |