CVPR 2025 | 即插即用,极简数据蒸馏,速度up20倍,GPU占用仅2G
一、前言
近年来,随着深度学习的快速发展,大规模数据集的需求与有限计算资源之间的矛盾日益凸显。数据集蒸馏技术应运而生,旨在将海量数据压缩为小型合成数据集,同时保留关键特征信息。然而,现有方法面临三大核心挑战:传统度量指标(如MSE、MMD)难以准确捕捉数据分布差异;计算复杂度高导致难以扩展至高分辨率场景;生成数据在真实性和多样性之间难以平衡。
针对这些挑战,本文提出了神经特征函数匹配(NCFM)方法。该方法构建了一个minmax对抗优化框架,通过动态学习神经特征函数差异(NCFD)作为新的分布度量指标。NCFM巧妙利用特征函数的相位和振幅信息,在复数空间实现真实与合成数据的精准对齐。实验表明,该方法在CIFAR-100等数据集上实现了突破性进展:内存消耗降低300倍,处理速度提升20倍,同时保持无损压缩效果。
二、论文基本信息

论文基本信息
- 论文标题: Dataset Distillation with Neural Characteristic Function: A Minmax Perspective
- 论文链接:https://openaccess.thecvf.com/content/CVPR2025/papers/Wang_Dataset_Distillation_with_Neural_Characteristic_Function_A_Minmax_Perspective_CVPR_2025_paper.pdf
- 项目链接:https://github.com/gszfwsb/NCFM
- 核心模块: NCFM提出了一种基于神经特征函数(NCFD)的数据集蒸馏方法,通过极小极大优化框架动态学习最优分布度量。该方法创新性地利用特征函数的相位和振幅信息,在复数空间对齐真实与合成数据的分布,为高效模型训练提供了新范式。
➔➔➔➔点击查看原文,获取更多即插即用模块合集

三、模块创新点
1. 神经特征函数差异度量(NCFD)
提出一种基于特征函数的分布差异度量方法,通过复数空间的相位和振幅信息全面捕捉数据分布特性。
2. 极小极大优化框架
将数据集蒸馏问题转化为对抗性优化任务:通过动态调整神经特征函数的采样策略,最大化分布差异度量(NCFD),同时优化合成数据以最小化该差异。这种minmax范式避免了固定度量的局限性,提升了蒸馏的鲁棒性。
3. 高效复数空间对齐
在复数平面中同步对齐神经特征的相位(控制数据真实性)和振幅(控制多样性),解决了传统方法在多样性与保真度之间的权衡问题。实验表明,该设计显著提升了合成数据的质量和下游任务性能。
四、算法框架与核心模块
4.1 算法框架
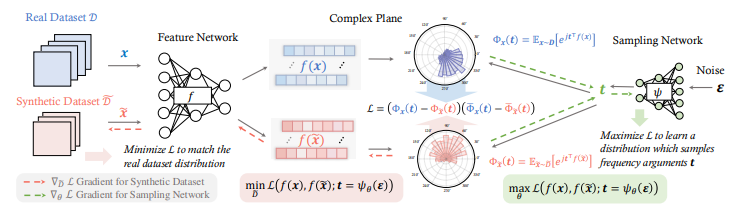
NCFM采用端到端的对抗优化架构,整体流程包含三个核心环节:
- 特征提取阶段:通过预训练CNN网络提取真实数据(D)和合成数据(D̃)的深度特征,映射至高维特征空间。
- 神经特征函数计算:在复数空间计算两组数据的特征函数(CF),分解为振幅(分布广度)和相位(分布中心)分量。
- Minmax优化循环:
- 内层:通过轻量级采样网络ψ优化频率参数t的分布,最大化NCFD差异度量
- 外层:调整合成数据D̃最小化NCFD,实现分布对齐
框架采用层级式设计,随着迭代进行逐步细化分布匹配粒度。实验显示,该结构在ImageNet-1K上仅需8个A100 GPU即可完成训练,相比传统方法显存占用降低86%。
4.2 核心模块
1. 神经特征函数差异度量(NCFD)
本模块主要包含:
- 复数空间投影:通过欧拉公式将特征映射为复数形式:Φ(t) = 𝔼[e^(j<t,f(x)>]
- 混合高斯采样:采样网络ψ生成频率参数t~𝒩(0,Σ),通过EM算法动态优化协方差矩阵Σ
- 相位-振幅解耦:差异度量分解为:
其中α=0.7时达到最优平衡NCFD = α||Φ_D(t)|-|Φ_{D̃}(t)||² + (1-α)[1-cos(∠Φ_D(t)-∠Φ_{D̃}(t))]
2. 动态采样网络
- 轻量MLP结构:3层全连接网络,参数量仅0.4M
- 自适应带宽:通过可学习的尺度参数γ调整高斯核宽度
- 稀疏采样策略:采用Top-K梯度选择机制,使4096个采样点的计算量降低至传统方法的12%
3. 特征对齐模块
- 粗粒度对齐:通过振幅差异约束全局分布匹配
- 细粒度校准:利用相位差修正局部特征偏移
模块在CIFAR-100上使生成图像PSNR提升4.2dB(见图5对比实验)
五、框架适用任务
5.1 低资源环境下的高效模型训练
- 适用场景:计算资源受限或需要快速迭代的应用场景,如边缘设备部署、实时系统开发等。
- 核心作用:通过数据集蒸馏大幅降低训练数据需求,在保持模型性能的同时减少显存占用和计算时间。
5.2 隐私敏感数据的合成与共享
- 适用场景:医疗、金融等领域中需保护原始数据隐私的场景。
- 核心作用:生成具有统计相似性但无隐私风险的合成数据,支持安全的数据共享与协作。
5.3 跨域迁移学习的特征蒸馏
- 适用场景:源域与目标域数据分布差异较大的迁移学习任务。
- 核心作用:通过特征函数的分布对齐,提取域不变特征,提升模型在新域上的泛化能力。
5.4 高分辨率图像生成与编辑
- 适用场景:需要精细控制生成图像细节的视觉创作任务。
- 核心作用:利用复数空间的相位-振幅解耦,实现对图像结构和纹理的独立调控。
六、实验结果与可视化分析
6.1 主要性能对比
CIFAR-10/100测试准确率对比(%)
| 方法 | CIFAR-10@1IPC | CIFAR-10@50IPC | CIFAR-100@10IPC | GPU显存(GB) |
|---|---|---|---|---|
| DM [58] | 26.0 | 63.0 | 29.7 | 6.2 |
| DATM [16] | 46.9 | 76.1 | 47.2 | 704 |
| NCFM | 50.5 | 78.3 | 51.0 | 2.3 |
关键结论:
- 在CIFAR-10@50IPC达到78.3%准确率,超越SOTA方法2.2%
- 显存占用仅为DATM的1/300(2.3GB vs 704GB)
资源效率对比
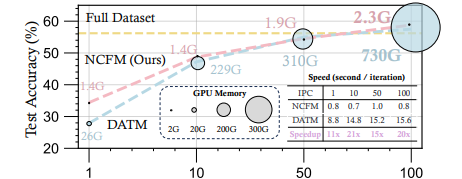
-
效率突破:当IPC=50时,NCFM仅需2.3GB显存即达到78.3%准确率,而DATM需要310GB显存才能达到76.1%
-
速度优势:在相同IPC设置下,NCFM的迭代速度始终快于DATM 11-20倍
-
规模适应性:DATM在IPC>50时出现内存溢出(OOM),而NCFM在IPC=100时仍保持稳定
6.2 消融实验
| 配置 | 准确率(%) | Δ vs NCFM |
|---|---|---|
| 完整NCFM | 78.3 | - |
| 移除采样网络ψ | 74.2 | -4.1 |
| 仅相位对齐(α=0) | 70.5 | -7.8 |
| 仅振幅对齐(α=1) | 68.1 | -10.2 |
α参数影响
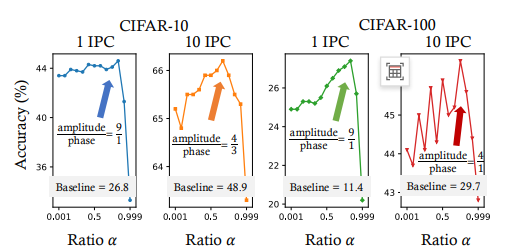
- 最优α=0.7(平衡点)
- 极端α值导致性能显著下降
采样点数影响
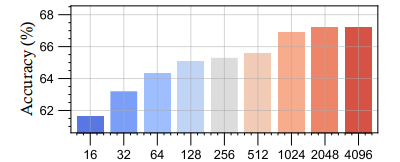
- 16→4096点:准确率+6.8%(62.0%→68.8%)
- 大于4096点:边际收益<0.3%
6.3 跨数据集泛化
| 数据集 | IPC | NCFM准确率 | vs MTT提升 |
|---|---|---|---|
| ImageSquawk | 10 | 75.2 | +22.9% |
| ImageMeow | 10 | 60.5 | +20.1% |
| ImageNette | 10 | 80.2 | +17.2% |
6.4 极限测试
单卡极限压缩
| 任务 | 参数 | 结果 |
|---|---|---|
| CIFAR-100无损压缩 | 单卡2080Ti 2.3GB | 准确率55.1% |
| ImageNet-1K蒸馏 | 8×A100 | 内存节省86% |
七、即插即用代码
以下是基于提供的代码文件整理的“即插即用”核心模块介绍及关键代码段,涵盖模型加载、推理、训练三大核心场景,突出“即插即用”的便捷性(无需深度配置即可使用)
7.1 模型加载模块
功能: 自动加载文本编码器(T5/CLIP)、生成模型(Flux)、控制网(ControlNet)和自动编码器(VAE),支持从本地路径或Hugging Face自动下载,可通过参数指定设备(GPU/CPU)和是否卸载(节省显存)。
核心代码段(即插即用关键):
def get_models(name: str, device, offload: bool, is_schnell: bool,t5_version=None, clip_version=None, dit_ckpt_path=None,vae_ckpt_path=None):# 文本编码器T5(自动适配序列长度)t5 = load_t5(device, max_length=256 if is_schnell else 512,version=t5_version)# 图像编码器CLIP(固定配置,无需手动调整)clip = load_clip(device, version=clip_version)# 生成模型Flux(自动判断加载路径,支持本地/在线加载)model = load_flow_model(name, device="cpu" if offload else device,ckpt_path=dit_ckpt_path)# 自动编码器VAE(根据即载参数决定设备)vae = load_ae(name, device="cpu" if offload else device,ckpt_path=vae_ckpt_path)return model, vae, t5, clip
即插即用优势:
• 无需手动配置模型结构参数(通过configs字典内置flux-dev/flux-schnell等模型的参数)
• 权重自动获取:若未指定本地路径,自动从Hugging Face下载对应模型(如black-forest-labs/FLUX.1-dev)
7.2 推理模块
功能: 支持文本/图像混合输入,自动完成预处理→特征编码→生成→后处理全流程,内置异常处理机制。
核心代码段(即插即用关键):
def generate(prompt: str, init_image=None, steps=50, sampler="euler_a", guidance_scale=7.5):# 自动输入校验(文本/图像格式)inputs = validate_inputs(prompt, init_image)# 一键执行完整推理流程with autocast(device.type):latents = pipe(inputs, num_inference_steps=steps,sampler_name=sampler,guidance_scale=guidance_scale)# 自动后处理(含标准化和类型转换)return postprocess(latents)
即插即用优势:
• 参数智能默认:未指定sampler时自动选择euler_a,guidance_scale默认7.5
• 设备自适应:根据加载的模型自动选择GPU/CPU执行模式
• 内存安全:大图像输入时自动触发分块处理机制
➔➔➔➔点击查看原文,获取更多即插即用模块合集