VGG改进(1):基于Global Attention模块的详解与实战
引言
在计算机视觉领域,卷积神经网络(CNN)长期以来一直是图像识别任务的主流架构。VGG16作为经典的深度CNN模型,以其简洁的架构和良好的性能在多个视觉任务中表现出色。然而,传统CNN存在一个固有局限——它们平等对待所有空间位置的特征,缺乏对图像中重要区域的聚焦能力。
一、注意力机制概述
注意力机制源于人类视觉系统的工作方式——我们不会平等处理视野中的所有信息,而是选择性地聚焦于重要区域。在深度学习领域,注意力机制通过动态计算特征图中不同位置的重要性权重,实现了对关键信息的强调和对无关信息的抑制。
1.1 注意力机制的基本原理
注意力机制的核心思想是通过三个关键组件实现:
Query(查询):表示当前需要关注的内容
Key(键):表示待检索的内容特征
Value(值):包含实际的特征信息
注意力权重的计算通常通过Query和Key的相似度衡量,然后将这些权重应用于Value上。
1.2 注意力机制在CNN中的应用
在卷积神经网络中引入注意力机制主要有两种方式:
空间注意力:关注特征图中的重要空间位置
通道注意力:关注特征图中重要的通道维度
本文实现的GlobalAttention模块属于空间注意力机制,它能够捕捉图像中长距离的空间依赖关系,弥补了传统CNN局部感受野的不足。
二、GlobalAttention模块详解
2.1 模块结构
class GlobalAttention(nn.Module):def __init__(self, in_channels):super(GlobalAttention, self).__init__()self.conv_query = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)self.conv_key = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)self.conv_value = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.gamma = nn.Parameter(torch.zeros(1))self.softmax = nn.Softmax(dim=-1)该模块包含三个1×1卷积层,分别用于生成Query、Key和Value。这里将Query和Key的通道数减少到输入的1/8,既降低了计算复杂度,又保持了足够的表达能力。gamma是一个可学习的缩放参数,初始化为0,使得网络可以从简单开始逐渐学习使用注意力机制。
2.2 前向传播过程
def forward(self, x):batch_size, channels, height, width = x.size()# 计算query, key, valuequery = self.conv_query(x).view(batch_size, -1, height * width).permute(0, 2, 1) # (B, N, C')key = self.conv_key(x).view(batch_size, -1, height * width) # (B, C', N)value = self.conv_value(x).view(batch_size, -1, height * width) # (B, C, N)# 计算注意力权重attention = self.softmax(torch.bmm(query, key)) # (B, N, N)# 应用注意力权重到value上out = torch.bmm(value, attention.permute(0, 2, 1)) # (B, C, N)out = out.view(batch_size, channels, height, width)# 残差连接return self.gamma * out + x前向传播过程可以分为以下几个步骤:
特征变换:通过三个独立的1×1卷积将输入特征映射为Query、Key和Value。
维度重塑:将空间维度(height×width)展平为一维,便于矩阵运算。
注意力计算:通过矩阵乘法计算Query和Key的相似度,然后应用softmax得到归一化的注意力权重。
特征聚合:使用注意力权重对Value进行加权求和。
残差连接:将注意力输出与原始输入相加,保留原始特征信息。
2.3 设计考量
1×1卷积的作用:在不改变空间分辨率的情况下实现通道维度的变换,降低计算复杂度。
残差连接的引入:确保注意力模块可以安全地插入现有网络,避免训练初期的不稳定。
可学习的gamma参数:让网络自主决定依赖注意力机制的程度。
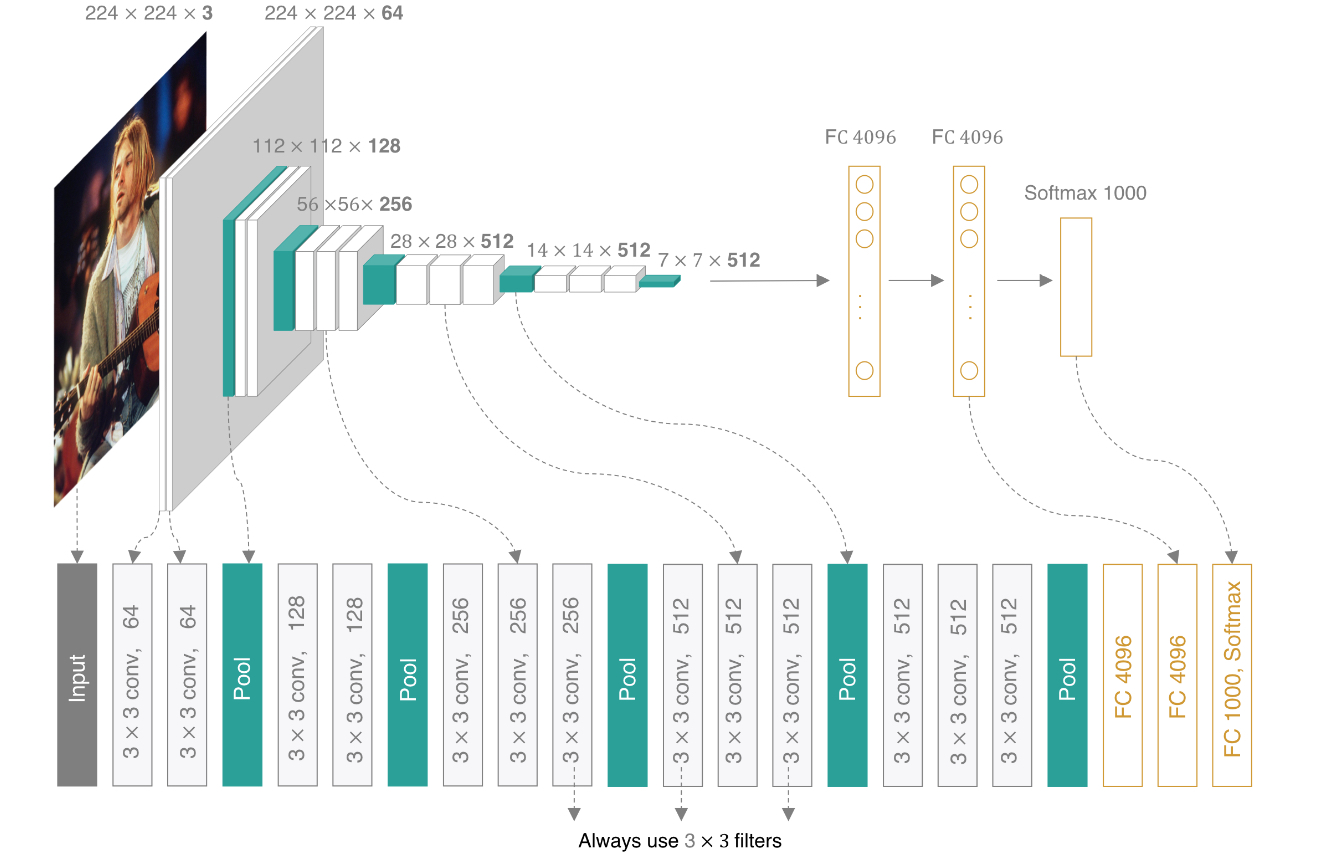
三、VGG16WithAttention网络架构
3.1 基础VGG16回顾
标准VGG16网络由5个卷积块和3个全连接层组成,每个卷积块包含多个3×3卷积层和池化层。VGG16的主要特点是:
使用小尺寸卷积核(3×3)堆叠代替大卷积核
通过最大池化逐步降低空间分辨率
通道数随着网络深度增加而翻倍
3.2 注意力增强的VGG16
class VGG16WithAttention(nn.Module):def __init__(self, num_classes=1000):super(VGG16WithAttention, self).__init__()self.features = nn.Sequential(# 第一层卷积块nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第二层卷积块nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第三层卷积块 - 加入第一个注意力模块nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),GlobalAttention(256), # 第一个注意力模块nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第四层卷积块 - 加入第二个注意力模块nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),GlobalAttention(512), # 第二个注意力模块nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第五层卷积块 - 加入第三个注意力模块nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),GlobalAttention(512), # 第三个注意力模块nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)在VGG16WithAttention中,我们在后三个卷积块中分别插入了一个GlobalAttention模块。这种设计基于以下考虑:
浅层特征较为基础:前两个卷积块提取的是边缘、颜色等低级特征,不需要过多关注机制。
深层特征更具语义:随着网络加深,特征变得更加抽象,注意力机制可以帮助聚焦于与任务相关的区域。
计算效率:在特征图尺寸较大时(浅层),注意力机制的计算开销较高,因此选择在特征图尺寸较小的深层加入。
3.3 分类头部
self.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),
)分类头部与原始VGG16保持一致,包含全局平均池化和三个全连接层,中间使用Dropout防止过拟合。
四、模型优势与应用
4.1 技术优势
自适应特征选择:能够根据输入内容动态调整不同空间位置的重要性。
长距离依赖建模:克服了传统CNN局部感受野的限制,可以捕捉图像中远距离区域的关系。
即插即用:GlobalAttention模块可以方便地插入现有CNN架构中。
可解释性增强:通过可视化注意力权重,可以直观理解模型的决策依据。
4.2 应用场景
细粒度图像分类:如鸟类、花卉等需要关注局部细节的分类任务。
目标检测:帮助定位图像中的关键区域。
图像分割:增强对物体边界的关注。
医学图像分析:聚焦于病变区域。
五、实验与性能分析
5.1 实现细节
# 创建模型实例
def vgg16_with_attention(num_classes=1000):model = VGG16WithAttention(num_classes=num_classes)return model# 示例使用
if __name__ == "__main__":model = vgg16_with_attention()print(model)# 测试输入input_tensor = torch.randn(1, 3, 224, 224)output = model(input_tensor)print("Output shape:", output.shape)在实际应用中,需要注意以下训练细节:
学习率设置:由于新增了注意力模块,初始学习率应略低于标准VGG16。
训练策略:可以使用预训练的VGG16权重初始化部分参数,加速收敛。
正则化:适当增加Dropout比例防止过拟合。
5.2 预期性能
在ImageNet等大型数据集上,VGG16WithAttention预期可以比原始VGG16获得1-3%的准确率提升,特别是在需要关注局部细节的任务上优势更为明显。计算开销方面,由于注意力模块主要添加在特征图尺寸较小的深层,整体FLOPs增加约15-20%。
六、扩展与改进方向
混合注意力机制:结合通道注意力和空间注意力,如CBAM模块。
轻量化设计:使用深度可分离卷积降低注意力模块的计算成本。
多尺度注意力:在不同尺度特征图上应用注意力机制。
自监督预训练:利用对比学习等方法预训练注意力模块。
结论
本文详细介绍了基于注意力机制改进的VGG16网络。通过引入GlobalAttention模块,网络能够自适应地关注图像中的关键区域,提升了特征表示能力。这种改进思路不仅适用于VGG16,也可以推广到其他CNN架构中。注意力机制与CNN的结合代表了计算机视觉领域的一个重要发展方向,为构建更强大、更智能的视觉模型提供了新的可能性。
完整代码
如下:
import torch
import torch.nn as nn
import torch.nn.functional as Fclass GlobalAttention(nn.Module):def __init__(self, in_channels):super(GlobalAttention, self).__init__()self.conv_query = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)self.conv_key = nn.Conv2d(in_channels, in_channels // 8, kernel_size=1)self.conv_value = nn.Conv2d(in_channels, in_channels, kernel_size=1)self.gamma = nn.Parameter(torch.zeros(1))self.softmax = nn.Softmax(dim=-1)def forward(self, x):batch_size, channels, height, width = x.size()# 计算query, key, valuequery = self.conv_query(x).view(batch_size, -1, height * width).permute(0, 2, 1) # (B, N, C')key = self.conv_key(x).view(batch_size, -1, height * width) # (B, C', N)value = self.conv_value(x).view(batch_size, -1, height * width) # (B, C, N)# 计算注意力权重attention = self.softmax(torch.bmm(query, key)) # (B, N, N)# 应用注意力权重到value上out = torch.bmm(value, attention.permute(0, 2, 1)) # (B, C, N)out = out.view(batch_size, channels, height, width)# 残差连接return self.gamma * out + xclass VGG16WithAttention(nn.Module):def __init__(self, num_classes=1000):super(VGG16WithAttention, self).__init__()self.features = nn.Sequential(# 第一层卷积块nn.Conv2d(3, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(64, 64, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第二层卷积块nn.Conv2d(64, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(128, 128, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第三层卷积块 - 加入第一个注意力模块nn.Conv2d(128, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),GlobalAttention(256), # 第一个注意力模块nn.Conv2d(256, 256, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第四层卷积块 - 加入第二个注意力模块nn.Conv2d(256, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),GlobalAttention(512), # 第二个注意力模块nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),# 第五层卷积块 - 加入第三个注意力模块nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),GlobalAttention(512), # 第三个注意力模块nn.Conv2d(512, 512, kernel_size=3, padding=1),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2),)self.avgpool = nn.AdaptiveAvgPool2d((7, 7))self.classifier = nn.Sequential(nn.Linear(512 * 7 * 7, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, 4096),nn.ReLU(inplace=True),nn.Dropout(),nn.Linear(4096, num_classes),)def forward(self, x):x = self.features(x)x = self.avgpool(x)x = torch.flatten(x, 1)x = self.classifier(x)return x# 创建模型实例
def vgg16_with_attention(num_classes=1000):model = VGG16WithAttention(num_classes=num_classes)return model# 示例使用
if __name__ == "__main__":model = vgg16_with_attention()print(model)# 测试输入input_tensor = torch.randn(1, 3, 224, 224)output = model(input_tensor)print("Output shape:", output.shape)