大数据架构演变之路
目录
一、各阶段的架构简介
二、各个架构的详细解释
1. 传统离线架构
2.1. Lambda架构-离线数仓分析+实时链路分析
2.2. Lambda架构-离线数仓+实时数仓
3. Kappa/流批一体架构
4. 湖仓一体架构
三、总结
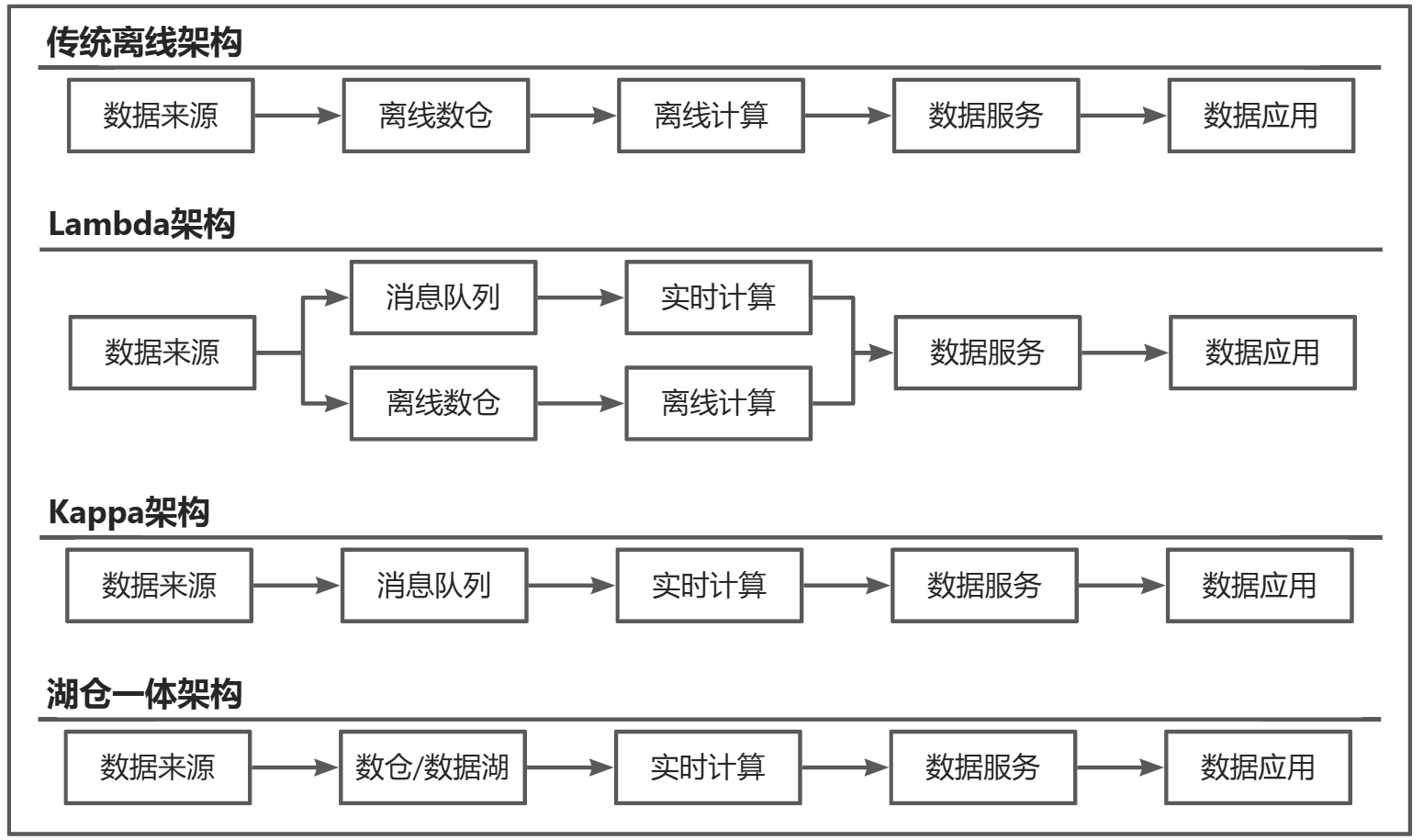
一、各阶段的架构简介
| 技术架构 | 核心驱动(核心需求) | 关键技术 | 特点 | |
| 传统离线架构 | 海量存储需求 | Hadoop生态 | 1.仅支持离线数据分析 | |
| Lambda架构 | 离线数仓分析 +实时链路分析 | 实时分析需求 | 批流双引擎 | 1.支持离线、实时数据分析 |
| 离线数仓 +实时数仓 | 1.支持离线、实时数据分析 | |||
| Kappa/流批一体架构 | 开发效率与一致性 | Flink/Spark 统一API | 1.以实时数据分析为主,适用于离线分析少的场景 | |
| 湖仓一体架构 | 存储治理与灵活性平衡 | Delta Lake /Iceberg | 1.存储中的小文件问题 | |
二、各个架构的详细解释
1. 传统离线架构

核心特点
1. 批处理主导
数据通过周期性ETL(如每日全量同步)导入HDFS等分布式存储,计算依赖MapReduce、Hive等离线引擎。
2. 高存储性价比
基于HDFS的廉价存储适合PB级历史数据,但时效性仅为T+1。
技术栈
Hadoop生态(HDFS/Hive)为主,结合关系型数据库作数据源。
2.1. Lambda架构-离线数仓分析+实时链路分析
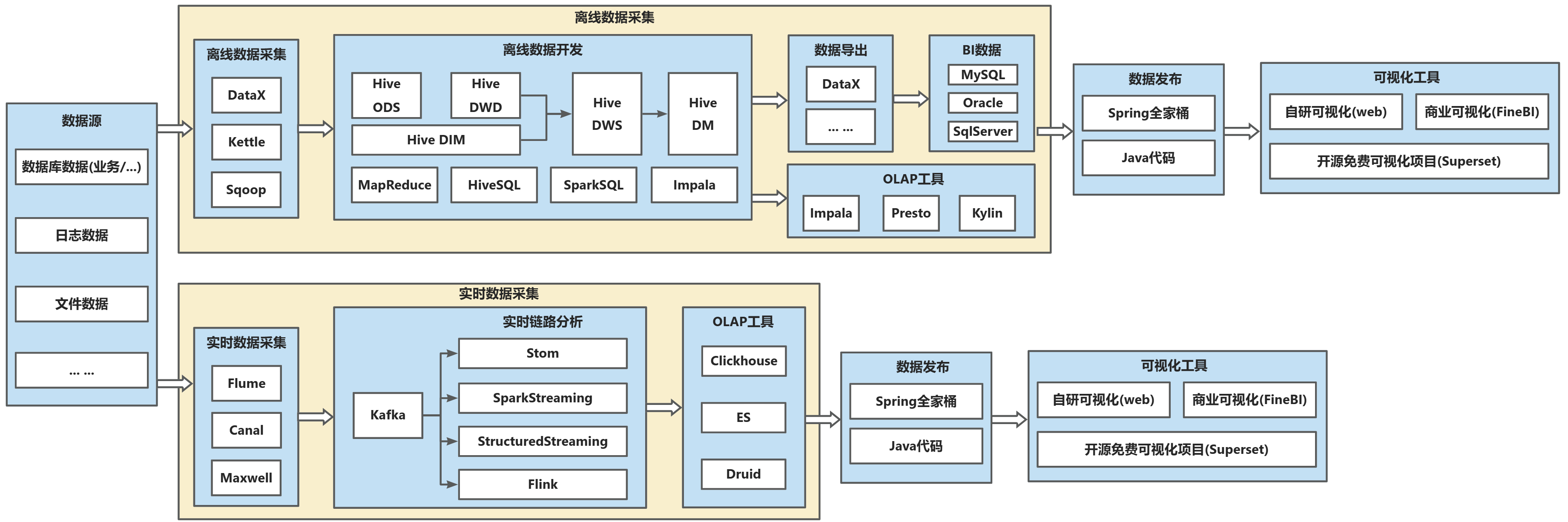
核心特点
1.支持离线、实时两种数据分析
离线数据、实时数据各有一套处理逻辑,能够对关键性指标进行实时数据分析处理。
2.实时数据分析不分层,数据无法复用
实时分析中仅仅是通过Kafka分发消息后通过Flink进行流处理,没有分层的结构,导致每个需求都要单独开发,数据几乎无法复用。
技术栈
Hadoop生态(HDFS/Hive)+ 实时相关生态技术(Kafka + Flink + Sparkstreaming ... ...)。
2.2. Lambda架构-离线数仓+实时数仓
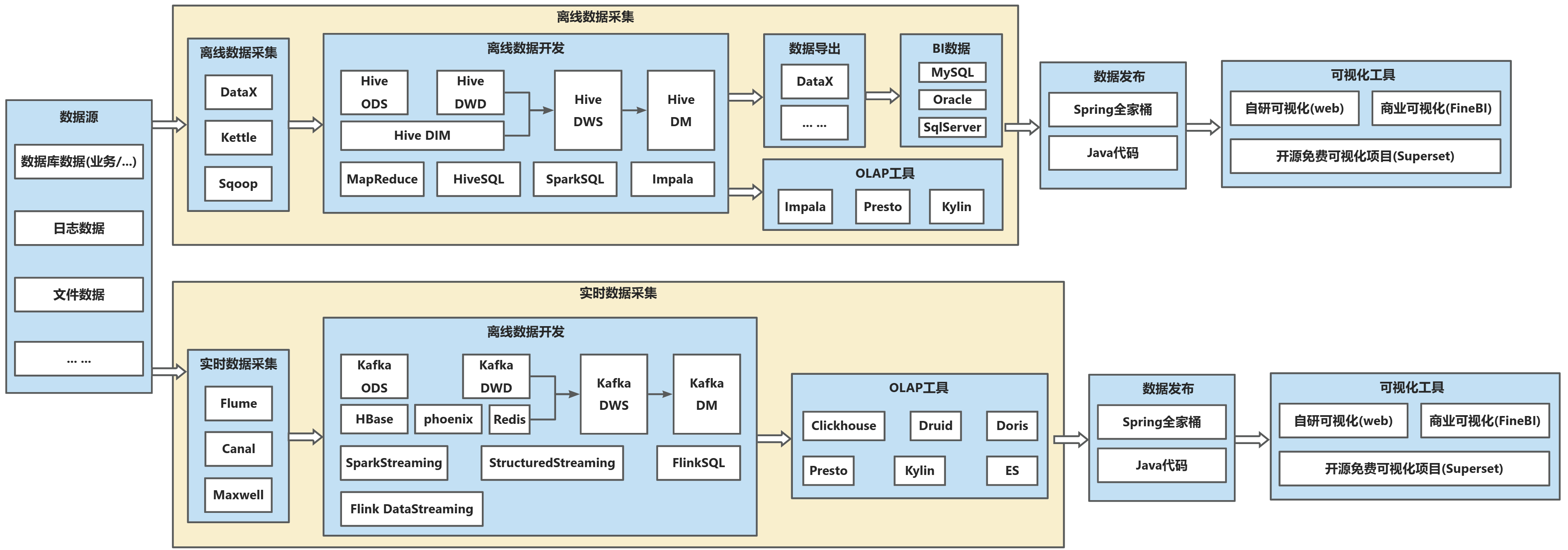
核心特点
1.开发、维护成本高
离线、实时各有一套代码,开发时要开发两套,维护时也要维护两套,成本翻倍。
2.存储成本、计算成本开销大
离线、实时各有一套数仓,数据冗余度高,存储成本、计算成本翻倍。
技术栈
Hadoop生态(HDFS/Hive)+ 实时相关生态技术(Kafka + Flink + Sparkstreaming ... ...)。
注:2.2相较于2.1其实就是引入了数仓的概念到实时链路中。
3. Kappa/流批一体架构

核心特点
1. 以实时分析为主,离线分析少
2. 放弃离线批处理,直接通过实时数据分析进行数据处理。
2. Kafka在流批一体场景下存在一定的缺陷
- Kafka 无法存储海量数据
- 数据治理平台无法迁移使用
- Kafka 不支持数据的更新操作
技术栈
Flink/Spark统一API
流批一体架构的思想
- 架构角度:一套架构既能完成流处理也能完成批处理
- 计算框架:一个框架既可以处理批数据也可以处理流数据
- SQL 层面:一套 SQL 可以处理批也可以处理流数据
- 存储层面:离线数据和实时数据只需要存储一份
4. 湖仓一体架构

核心特点
1. 数据孤岛与整合难题
统一存储结构化、半结构化和非结构化数据,消除传统架构中数据仓库与数据湖的割裂,减少数据冗余和迁移成本。
2. 小文件问题
传统离线数仓,HDFS中其实也会存在类似的问题。
3. 实时数据处理慢
索引机制(如Bloom索引假阳性)和写入模式(COW小文件问题)可能导致实时数据处理延迟。
技术栈
HDFS、Delta Lake 、Iceberg
三、总结