文章目录
- 初阶:MHA: multi-head attention
- [GQA:group query attention](http://arxiv.org/pdf/2305.13245) [2023. 12, Google]
- MQA:multi-query attention(https://arxiv.org/pdf/2305.13245)[2023.12, google]
- 进阶:flash attention
- 高阶:
-
- [Linear Attention](https://arxiv.org/pdf/2310.01082) [MIT&KAIST, 2024.3]
- Sliding Window Attention
- Sparse Attention
初阶:MHA: multi-head attention
- multi head的Q/K/V,分别按头进行计算
- 问题:在推理时,MHA最大的瓶颈是KV Cache的内存占用。每个头都需要独立的K和V矩阵,这在长序列、大批量的推理中非常消耗显存。在自回归推理中,Query 是动态变化的,而 Key 和 Value 是可以被缓存和重复使用的。共享 K/V 能够最大化地利用缓存,从而节省内存和计算。
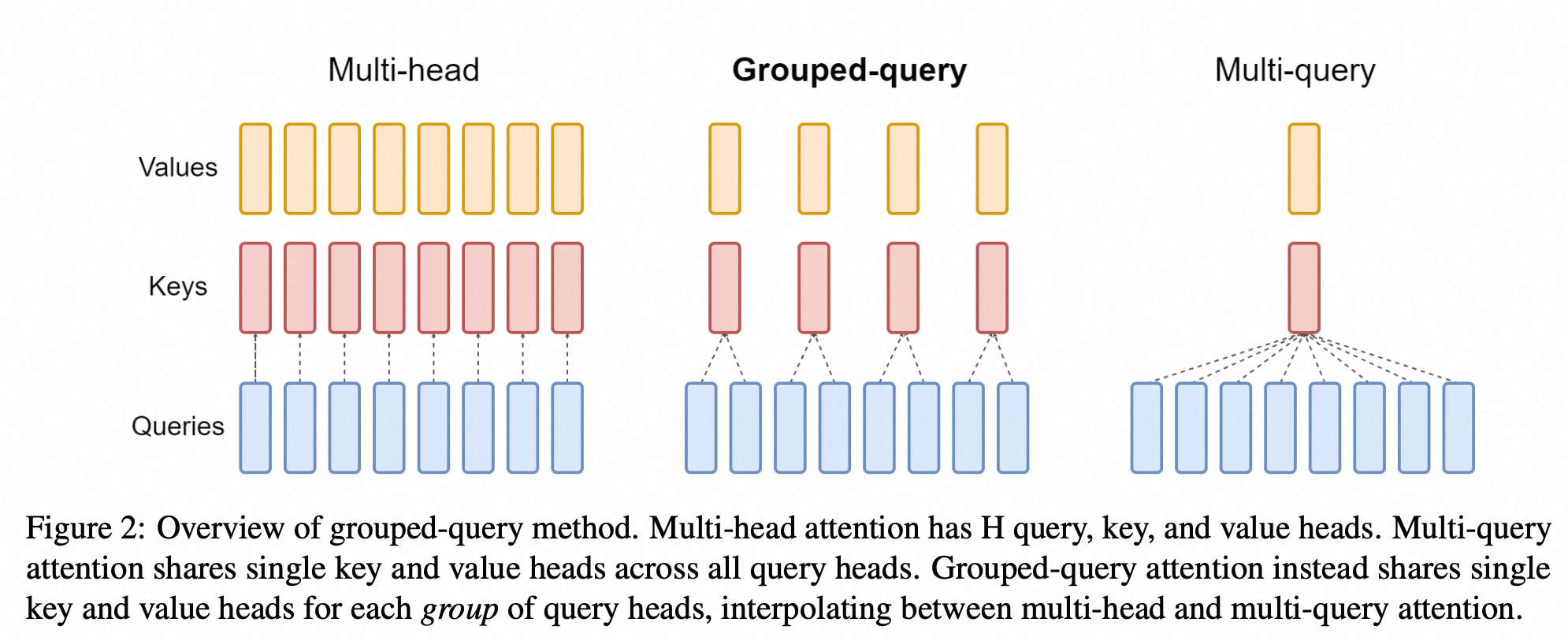
- Llama 2 引入,llama3, qwen2 等都在使用
- GQA旨在显著减少KV Cache的内存占用,同时保持接近MHA的性能。【速度和质量的平衡态】
- 核心思想:
- 它是一种介于MHA和MQA(见下文)之间的折中方案。
- 将Q头分成g个组,每个组内的所有Q头共享同一份K和V头。
- 例如,8个Q头可以分成4组,每2个Q头共享一份K和V。
MQA:multi-query attention(https://arxiv.org/pdf/2305.1324