[LLM 应用评估] 评估指标 | 评估协调器 | 测试集生成组件
第四章:评估指标
在第一章:大语言模型与向量嵌入中,我们掌握了Ragas的"大脑"与"翻译器";第二章:提示词工程探讨了如何为AI裁判编写指令手册;第三章:评估样本与数据集则准备了待评估的"案例卷宗"。
本章我们将揭秘量化AI表现的"专项检查"——评估指标(Metrics)。
什么是评估指标?
想象医生问诊时不会仅凭直觉判断健康状态,而是通过血压测量、X光扫描等专项检查获取量化数据。在Ragas中,评估指标正是这样的专项检测工具,用于量化AI系统的各项表现维度。
例如:
- 生成答案的准确性如何?
- 响应内容是否与问题相关?
- 输出结果是否严格基于检索依据(忠实性)?
每个指标聚焦特定质量维度,输出0-1或0-5的量化分数。值越接近1(或5)代表质量越优。评估指标为AI表现提供数据化证明,精准定位系统强项与短板。
Ragas 如何运用评估指标
Ragas通过指标对评估样本(单次交互记录)进行量化评分。例如使用忠实度(Faithfulness)指标验证响应内容是否严格基于检索上下文:
- 从
单轮样本(SingleTurnSample)提取系统响应(response)和检索上下文(retrieved_contexts) - 调用配置的大语言模型作为"AI裁判",通过特定提示词分析响应与上下文的关联性
- 返回该次交互的忠实度分数
通过对数据集运行多维度指标,Ragas生成全面评估报告,呈现AI系统的综合表现。
指标应用实例:忠实度检测
以下演示如何使用Faithfulness指标评估RAG系统的响应忠实性:
步骤1:初始化评估组件
# 配置评估用LLM(参照第一章)
from ragas.llms import LangchainLLMWrapper
from langchain_openai import ChatOpenAI
# 注意设置OPENAI_API_KEY环境变量!
评估用LLM = LangchainLLMWrapper(ChatOpenAI(model="gpt-4o"))# 创建待评估样本(参照第三章)
from ragas import SingleTurnSample
待评估样本 = SingleTurnSample(user_input="《泰坦尼克号》中Jack的扮演者是谁?",retrieved_contexts=["莱昂纳多·迪卡普里奥在电影《泰坦尼克号》中饰演Jack Dawson。"],response="Jack Dawson由莱昂纳多·迪卡普里奥扮演。",reference="莱昂纳多·迪卡普里奥"
)
步骤2:调用忠实度指标
from ragas.metrics import Faithfulness# 初始化指标并绑定LLM
忠实度检测器 = Faithfulness(llm=评估用LLM)# 执行异步评分(推荐用于生产环境)
评分结果 = await 忠实度检测器.single_turn_ascore(待评估样本)print(f"忠实度得分:{评分结果}") # 预期输出接近1.0
当响应内容完全基于检索上下文时(如本例),忠实度得分趋近1.0。若响应包含虚构信息(如"由汤姆·汉克斯扮演"),得分将显著降低。
底层机制
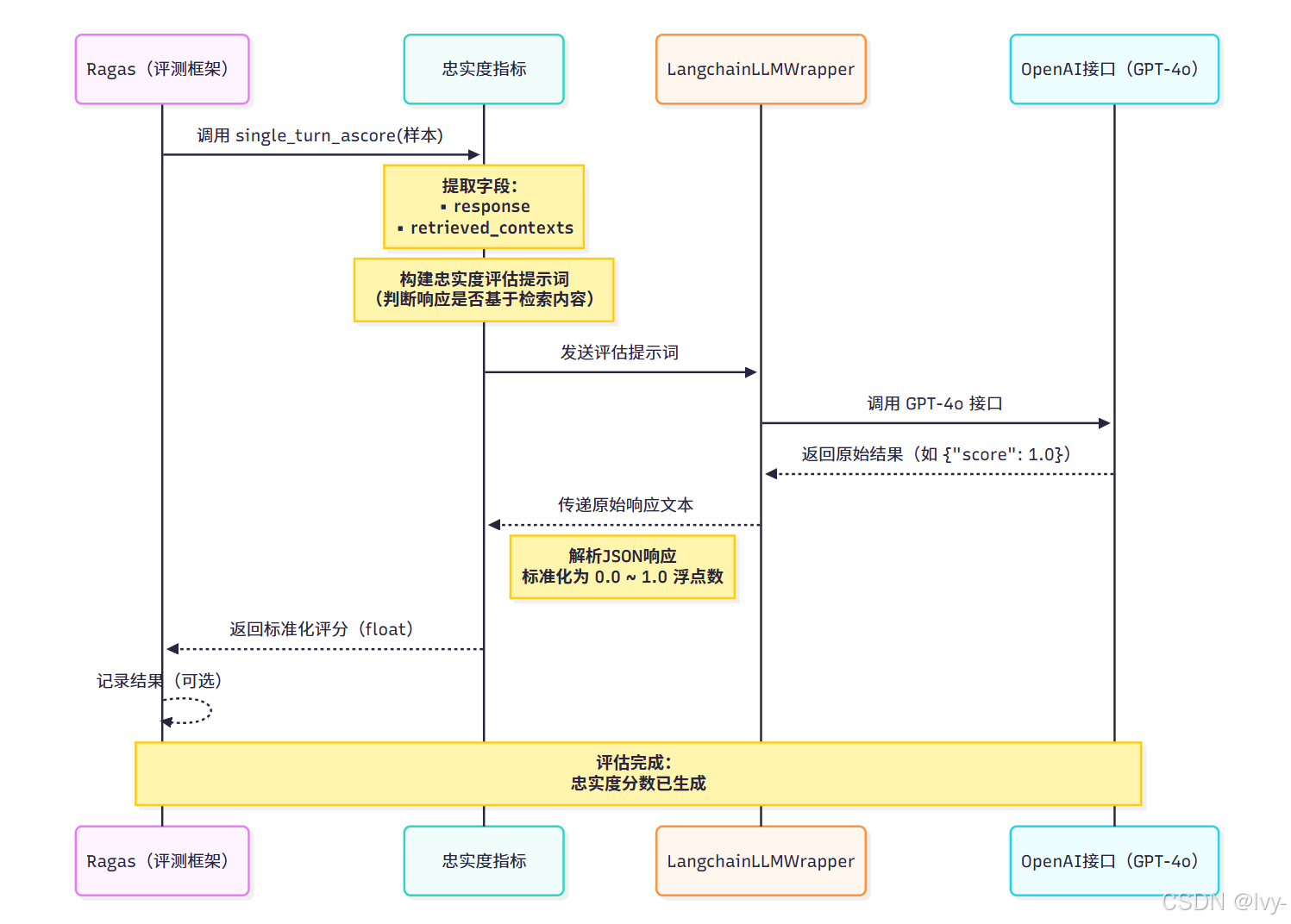
当调用single_turn_ascore()时,Ragas执行以下核心流程:
- 指标解析请求:提取样本中的关键数据(响应内容与检索上下文)
- 构建评估提示:生成结构化提示词,要求LLM判断响应与上下文的关联性
- LLM裁判判决:通过配置的LLM服务商获取原始评估结果
- 分数标准化处理:将LLM输出解析为0-1区间的量化分数
处理流程时序图
代码架构
Ragas通过分层类结构实现指标系统的扩展性:
指标基类(base.py)
# 简化自ragas源码
from abc import ABC, abstractmethodclass 指标基类(ABC):@abstractmethodasync def 单轮评分(self, 样本: 单轮样本) -> float:"""抽象方法:子类需实现具体评分逻辑"""class 需LLM的指标(指标基类):def __init__(self, llm: 大语言模型):self.llm = llm # 绑定评估用LLMclass 忠实度指标(需LLM的指标):async def 单轮评分(self, 样本: 单轮样本) -> float:提示词 = 构建提示(样本.response, 样本.retrieved_contexts)llm响应 = await self.llm.生成(提示词)return 解析分数(llm响应)
此设计允许灵活扩展新指标,同时保障评估流程的一致性。
小结
- 专项量化检测:评估指标如同医学检测,为AI表现提供数据化诊断
- 核心指标类型:忠实度、准确性、相关性等维度构成评估体系
- 可扩展架构:通过继承基类可快速开发定制化评估指标
- 异步高效处理:支持异步评分机制,适配大规模数据集评估
掌握评估指标后,我们将见证Ragas如何协调各组件完成系统化评估。下一章将深入评估协调器,解析全流程自动化评估的运作机制。
第五章:评估协调器
在第一章:大语言模型与向量嵌入中,我们掌握了Ragas的"大脑"与"翻译器";第二章:提示词工程探讨了如何为AI裁判编写指令手册;第三章:评估样本与数据集准备了待评估的"案例卷宗";第四章:评估指标则揭秘了量化检测的"专项检查"。
本章我们将见证如何通过**评估协调器(Evaluation Orchestrator)**实现全流程自动化评估。
什么是评估协调器?
ragas.evaluate() 函数是Ragas评估流程的"中央控制台",如同交响乐团的指挥家,协调各组件完成复杂乐章。其核心职能包括:
加载评估数据集- 对每个样本执行选定的评估指标
检测 - 统一
调度大语言模型与向量嵌入服务 - 实现
并发处理加速评估流程 - 汇总各指标得分生成
综合分析报告
该函数是用户执行全量评估的核心入口,实现各模块的无缝协同。
评估协调器实战应用
通过三步即可完成端到端评估:
步骤1:配置基础模型
# 配置评估用LLM与Embeddings(参照第一章)
from ragas.llms import LangchainLLMWrapper
from ragas.embeddings import LangchainEmbeddingsWrapper
from langchain_openai import ChatOpenAI, OpenAIEmbeddings# 确保已设置OPENAI_API_KEY环境变量
评估用LLM = LangchainLLMWrapper(ChatOpenAI(model="gpt-4o"))
评估用Embeddings = LangchainEmbeddingsWrapper(OpenAIEmbeddings(model="text-embedding-ada-002")
)
步骤2:准备数据集与指标
# 构建微型数据集(参照第三章)
from ragas import SingleTurnSample, EvaluationDataset样本1 = SingleTurnSample(user_input="法国的首都是哪里?",retrieved_contexts=["巴黎是法国的首都。"],response="法国的首都是巴黎。",reference="巴黎"
)样本2 = SingleTurnSample(user_input="泰坦尼克号何时沉没?",retrieved_contexts=["泰坦尼克号于1912年4月15日沉没。"],response="泰坦尼克号于1912年4月15日沉没。",reference="1912年4月15日"
)数据集实例 = EvaluationDataset(samples=[样本1, 样本2])# 初始化评估指标(参照第四章)
from ragas.metrics import faithfulness, answer_relevancyfaithfulness.llm = 评估用LLM
answer_relevancy.llm = 评估用LLM
answer_relevancy.embeddings = 评估用Embeddings
步骤3:执行全量评估
from ragas import evaluate评估结果 = evaluate(dataset=数据集实例,metrics=[faithfulness, answer_relevancy]
)print("综合评估结果:")
print(评估结果) # 示例输出:{'faithfulness': 0.98, 'answer_relevancy': 0.95}
详细结果分析
import pandas as pd详细结果表 = 评估结果.to_pandas()
print("\n样本级评估明细:")
print(详细结果表)
输出示例:

底层架构解析
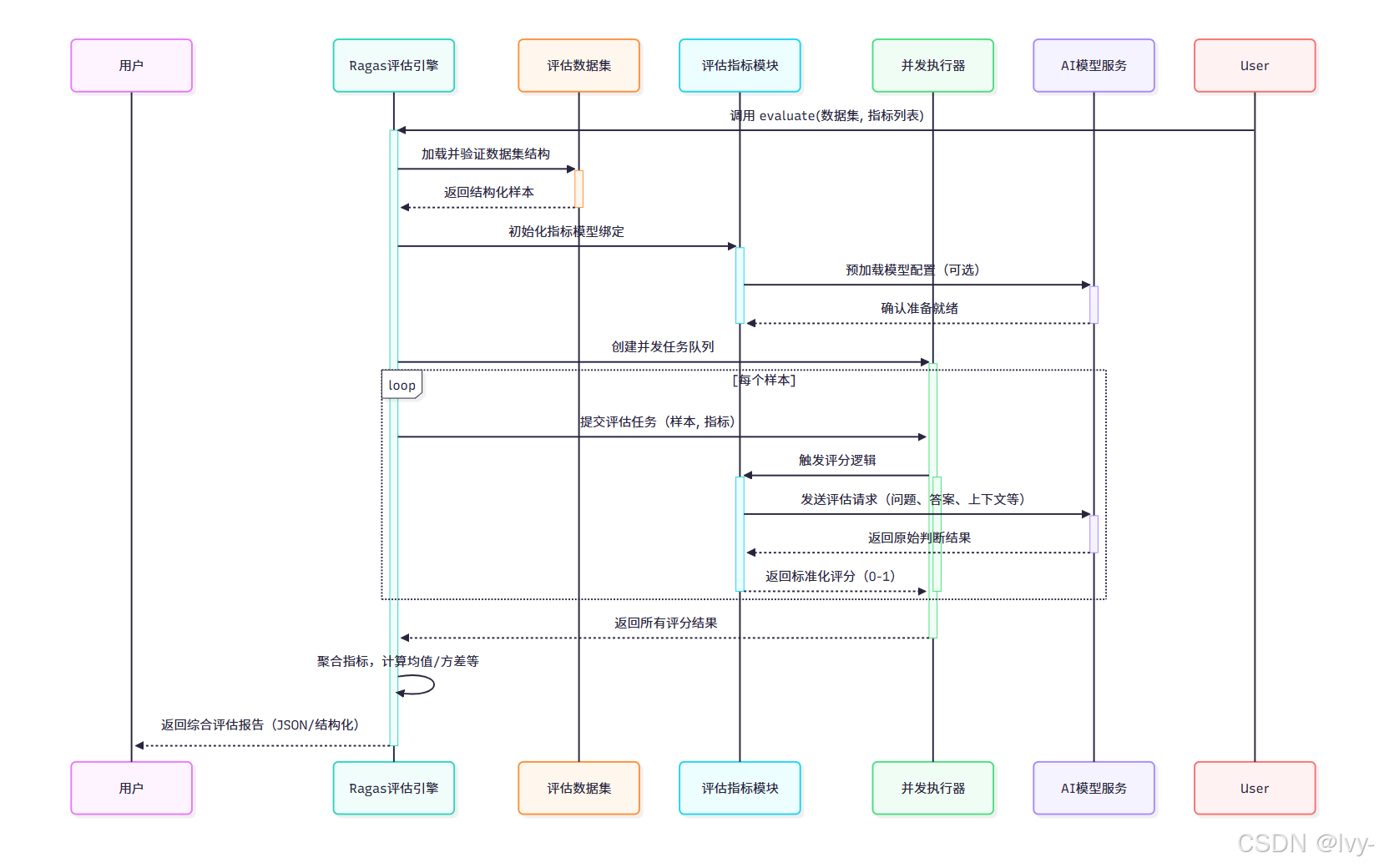
evaluate() 函数内部通过六阶段实现高效评估
处理流程时序图
代码结构(evaluation.py)
# 简化自ragas源码
from concurrent.futures import ThreadPoolExecutorclass 评估协调器:def 执行评估(self, 数据集: 数据集类,指标列表: list[指标基类]) -> 评估结果类:# 初始化并发执行器with ThreadPoolExecutor() as 执行池:# 遍历样本创建评估任务任务队列 = []for 样本 in 数据集:for 指标 in 指标列表:任务 = 执行池.submit(指标.异步评分方法, 样本)任务队列.append(任务)# 收集并处理结果原始结果 = [任务.result() for 任务 in 任务队列]# 结构化结果数据return 评估结果类(原始结果, 数据集)
此设计通过线程池实现高并发处理,显著提升大规模数据集评估效率。
⭕线程池实现高并发
资源复用
通过 ThreadPoolExecutor 创建线程池,避免频繁创建/销毁线程的开销。线程池默认复用固定数量的工作线程(CPU核心数*5),减少线程上下文切换成本。
任务并行
-
submit()方法将每个(样本×指标)组合提交为独立任务,线程池自动分配空闲线程执行。 -
任务队列的异步提交使得计算密集型或IO密集型操作可以并发执行,而非串行等待。
结果收集
任务队列 存储所有 Future 对象,通过列表推导式 [task.result() for task in 任务队列] 阻塞等待所有任务完成。
线程池自动处理线程同步,开发者无需手动管理线程锁。
细节:
上下文管理器自动清理
with 语句确保线程池在执行结束后自动关闭,回收系统资源。避免线程泄漏或资源未释放问题。
无状态任务设计
每个任务调用 指标.异步评分方法(样本) 时,指标和样本作为参数传入。这种设计符合函数式编程思想,避免多线程环境下的状态共享问题。
结果聚合解耦
原始结果收集与结构化处理分离。线程池仅负责并发执行,结果组装由 评估结果类 独立完成,符合单一职责原则。
小结
- 一站式评估入口:
evaluate()函数整合数据集、指标与模型服务,实现自动化评估流水线 - 高效并发机制:基于线程池的并发执行器加速处理速度,支持百万级样本评估
- 结果多维分析:提供全局统计与样本级明细,支持精确问题定位
- 弹性扩展架构:通过指标基类与执行器抽象,方便接入新型评估指标
掌握评估协调器后,我们已具备完整能力对AI系统进行全面体检。当缺乏真实交互数据时,可借助第六章:测试集生成组件创建合成数据集,完善评估体系。
第六章:测试集生成组件
在第五章:评估协调器中,我们掌握了如何整合Ragas各组件(AI裁判、提示词、评估数据集与指标)实现全流程评估。但当缺乏真实交互数据时,如何高效生成高质量测试集?本章将揭秘测试集生成组件,实现评估数据的自动化构建。
测试集生成组件
想象需为新任图书馆管理员(AI系统)创建测试题库,要求涵盖简单查询、跨文档推理等复杂场景。Ragas的测试集生成组件正是这样的智能工厂,能够:
- 将原始文档转化为结构化知识图谱
- 通过转换器提取关键信息并建立关联
- 利用合成器生成多样化测试用例
三大核心组件协同工作,显著降低人工构建测试集的成本。
1. 知识图谱:数据智能地图
知识图谱(KnowledgeGraph)将文档解构为**节点(Nodes)与关系(Relationships)**,构建语义网络。例如:
- 节点:存储"2023年营收数据"段落
- 关系:连接"公司X产品"与"2023年营收"节点(若存在语义关联)
节点构建示例
from ragas.testset.graph import Node# 创建包含爱因斯坦相对论内容的节点
节点1 = Node(properties={"page_content": "阿尔伯特·爱因斯坦提出了相对论。"}
)
print(节点1.properties["page_content"]) # 输出:阿尔伯特·爱因斯坦提出了相对论。
关系建立示意
from ragas.testset.graph import Relationship# 假设存在节点2(内容关于"相对论应用")
# 关系实例 = Relationship(源节点=节点1, 目标节点=节点2, 类型="概念关联")
知识图谱容器
from ragas.testset.graph import KnowledgeGraph知识图谱实例 = KnowledgeGraph(nodes=[节点1])
print(知识图谱实例) # 展示图谱结构摘要
2. 转换器:知识图谱增强引擎
转换器(Transforms)是文档处理流水线,包含三类核心操作:
- 文档分割器:将长文档切分为语义节点
- 信息提取器:识别命名实体、关键短语等
- 关系构建器:建立节点间的语义关联
实体提取示例
from ragas.testset.transforms.extractors import NERExtractor实体提取器 = NERExtractor()
# 应用后节点将新增entities属性:
# 节点1.properties['entities'] = {'PER': ['阿尔伯特·爱因斯坦'], 'MISC': ['相对论']}
转换流水线应用
from ragas.testset.transforms import apply_transforms, Parallel
import asyncio# 初始化包含两个节点的知识图谱
知识图谱实例 = KnowledgeGraph(nodes=[Node(properties={"page_content": "阿尔伯特·爱因斯坦提出了相对论。"}),Node(properties={"page_content": "E=mc²是相对论中的著名公式。"})
])# 定义转换步骤(实体提取与关键短语提取并行)
转换步骤 = [Parallel(NERExtractor(),KeyphraseExtractor() # 关键短语提取器)
]# 执行转换
asyncio.run(apply_transforms(知识图谱实例, 转换步骤))
print("知识图谱增强完成!") # 节点已包含entities与keyphrases属性
3. 合成器:测试用例智能设计器
合成器(Synthesizers)基于知识图谱生成多样化测试用例,主要类型包括:
- 单跳查询:单节点可解答的问题(“相对论提出者是谁?”)
- 多跳查询:需跨节点推理的问题(“公司X产品的核心技术如何影响2023营收?”)
- 抽象查询:需总结归纳的问题(“简述相对论的核心贡献”)
用例生成示例
from ragas.testset.synthesizers.testset_schema import SingleTurnSample# 合成器生成的理想输出(实际由LLM自动生成)
生成样本 = SingleTurnSample(user_input="相对论的提出者是谁?",retrieved_contexts=["阿尔伯特·爱因斯坦提出了相对论。"],response="阿尔伯特·爱因斯坦",reference="阿尔伯特·爱因斯坦"
)
print("合成器生成样本示例:")
print(生成样本)
全流程整合:测试集生成器
测试集生成器(TestsetGenerator)是实现端到端测试集生成的核心入口:
配置基础模型
from ragas.llms import LangchainLLMWrapper
from langchain_openai import ChatOpenAI生成用LLM = LangchainLLMWrapper(ChatOpenAI(model="gpt-4o"))
准备示例文档
from langchain_core.documents import Document as LCDocument文档集合 = [LCDocument(page_content="埃菲尔铁塔位于法国巴黎。"),LCDocument(page_content="巴黎是法国的首都。"),LCDocument(page_content="塞纳河流经巴黎。"),
]
执行测试集生成
from ragas.testset.synthesizers import TestsetGenerator生成器 = TestsetGenerator(llm=生成用LLM)
生成测试集 = asyncio.run(生成器.generate_with_langchain_docs(文档集合, testset_size=3)
)# 结果展示
import pandas as pd
结果表 = 生成测试集.to_pandas()
print(结果表[['user_input', 'retrieved_contexts', 'reference']])
输出示例:

底层架构
测试集生成流程通过五阶段实现:
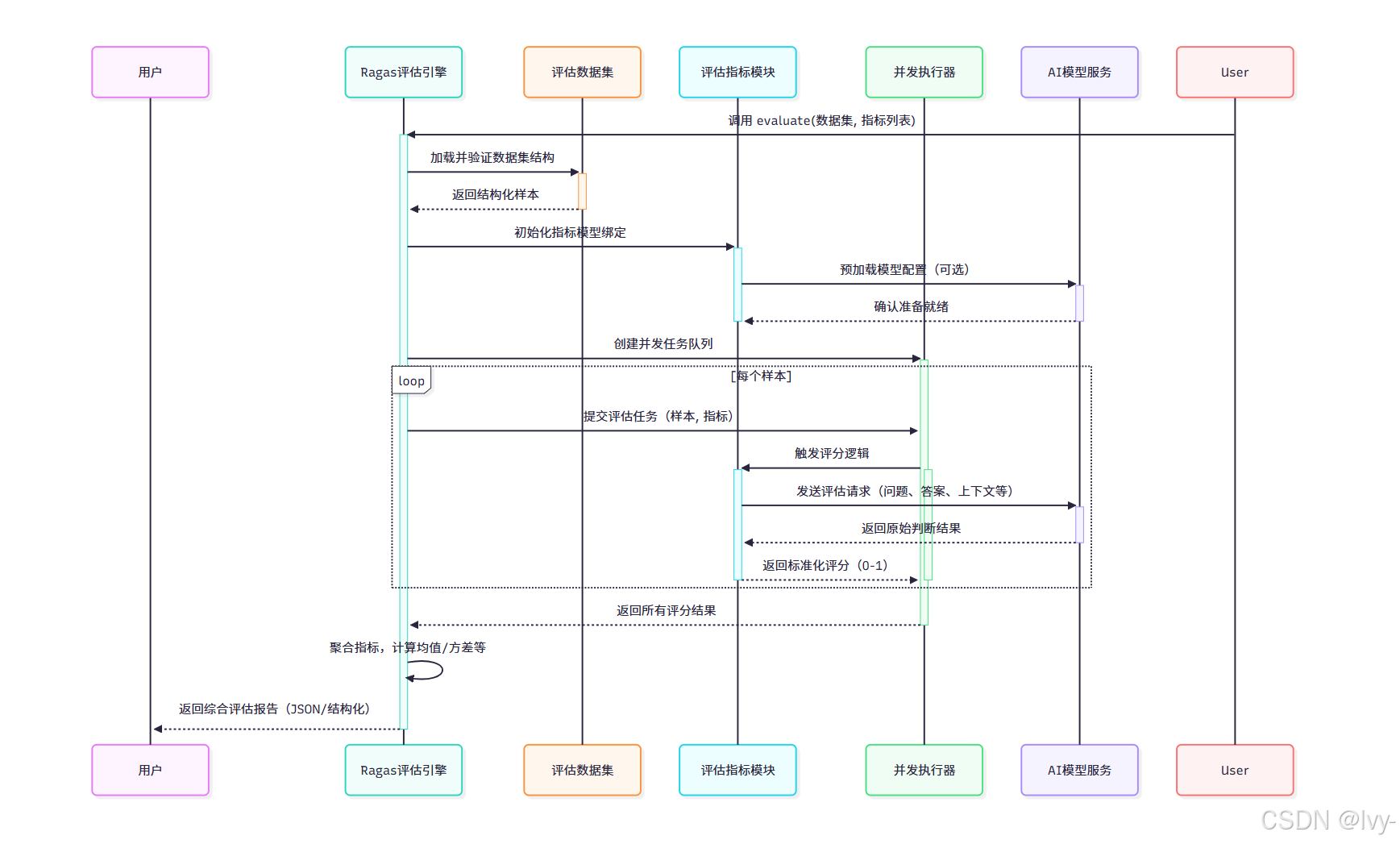
核心代码结构(generate.py)
# 简化自ragas源码
@dataclass
class 测试集生成器:llm: 任意类型 # RagasLLM实例knowledge_graph: KnowledgeGraph = KnowledgeGraph()async def generate_with_langchain_docs(self, 文档集合, 样本数) -> Testset:# 将文档转换为初始节点初始节点 = [Node(properties=文档内容) for 文档 in 文档集合]self.knowledge_graph.nodes = 初始节点# 应用转换器增强图谱await apply_transforms(self.knowledge_graph, 默认转换器列表)# 调用合成器生成测试样本测试样本列表 = []for _ in range(样本数):场景 = 选择合成器.生成场景(self.knowledge_graph)样本 = await 合成器.生成样本(场景, self.llm)测试样本列表.append(样本)return Testset(samples=测试样本列表)
小结
- 知识图谱构建:通过节点与关系实现文档语义结构化
- 智能转换流水线:实体提取、关系挖掘等操作增强数据价值
- 多样化用例生成:支持单跳/多跳/抽象查询等复杂场景
- 自动化测试生产:端到端生成符合评估要求的测试数据集
至此,我们已完成Ragas全组件解析。从数据准备、评估指标到测试生成,Ragas为RAG系统提供了完整的质量保障体系。
END ★,°:.☆( ̄▽ ̄).°★ 。